




 文章详细介绍了如何使用Greenplum的命令进行集群构建,包括初始化从节点、设置SSH免密、建立standby节点。同时,阐述了在主节点故障时如何执行故障切换,以及如何恢复主从结构和删除节点的操作流程。
文章详细介绍了如何使用Greenplum的命令进行集群构建,包括初始化从节点、设置SSH免密、建立standby节点。同时,阐述了在主节点故障时如何执行故障切换,以及如何恢复主从结构和删除节点的操作流程。
背景
greenplum可以通过自带的命令进行集群构建,集群结构可以有效防止数据丢失
初始化从节点
创建与主节点相同用户,并安装greenplum
在从节点创建与主节点相同目录,并修改目录权限为gpadmin用户
注:gpadmin为greenplum使用的用户
将主节点ssh免密-->.ssh/id_rsa.pub内容粘贴到从节点中authorized_keys,修改文件权限:chmod 700 ~/.ssh chmod 600 ~/.ssh/authorized_keys
通过gpssh-exkeys对节点进行免密互通:gpssh-exkeys -e hosts -x new_hosts
注:hosts为原有host,new_hosts为新增host
初始化standby节点: gpinitstandby -s hostname
故障切换
当主节点故障时:gpactivatestandby -d $datapath
注:$datapath为数据路径,如:/data/gpdata/gpmaster/gpseg-1
注:在standby中需要存在数据库相应变量,如端口,数据库名称
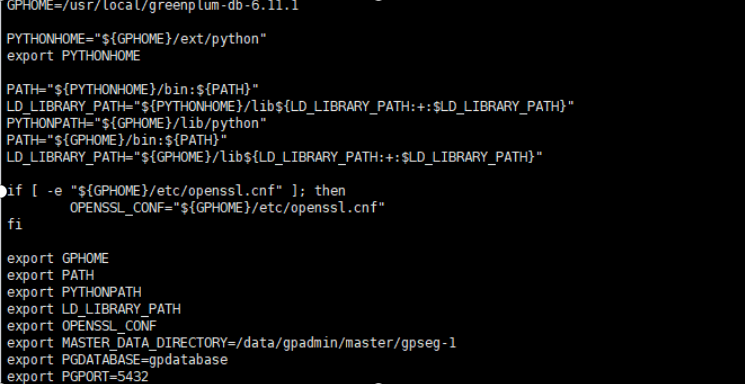
切换后恢复主从结构:
在原主节点(master)上备份数据目录并删除原目录,并清除原目录数据或重新创建
在原standby节点上操作,将master节点初始化为standby节点
在原standby节点上停止master服务:gpstop -m,在master点上进行节点切换,将standby节点切换为主节点
在master节点进行从节点初始化操作
节点删除
删除已存在的standby节点:gpinitstandby -r
重启节点:gpinitstandby -n

















 698
698

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









