





文章导读
AutoMQ 自 2023 年底正式开源以来,凭借其面向云原生场景的创新架构,迅速赢得了全球开发者的关注。目前在 GitHub 上已累计接近 6.5k Star,多次登上 GitHub Trending,受到海外技术社区的高度认可。Kafka 作为流处理领域的核心组件,其在云环境中的演进备受关注。AutoMQ 基于 S3 构建的新一代 Kafka 存储引擎,提供了更低成本、更高弹性的新选择。
我们为大家带来的是一篇来自海外开发者 Vu Trinh 的优质内容翻译。Vu Trinh 是一位专注于数据工程的技术作者,拥有超过 24,000 名读者关注,长期在 Medium 和 Substack 平台分享关于流处理、**OLAP 数据库和云原生架构的深度内容。本文基于 AutoMQ,深入剖析了将 Apache Kafka 构建在对象存储之上所面临的关键挑战与技术解法**。相信这篇内容能为希望理解 Kafka 云原生演进路径的读者提供实用启发。
前言
自从开源以来,Kafka 已成为分布式消息系统的事实标准。它最初仅在 LinkedIn 内部使用,后来逐步扩展以满足日益增长的日志处理需求,如今已在全球众多公司中广泛应用于消息传递、日志聚合和流式处理等多种场景。
然而,Kafka 的设计诞生于本地数据中心仍占主导地位的时期。因此,在云上运行 Kafka 会面临一些挑战,例如计算与存储无法独立扩展,以及由于数据复制产生的跨可用区传输费用等问题。
当你寻找 “Kafka alternative”(Kafka 替代方案)时,很容易就能找到四到五种解决方案,它们都承诺可以降低 Kafka 部署的成本,并减少运维负担。它们可能通过各种手段提升自身吸引力,但你会反复看到的一点是:这些方案几乎都试图将 Kafka 的数据完全存储在对象存储中。
本文不会深入探讨 Kafka 的内部机制,也不会分析它为何如此受欢迎,而是聚焦于:在 S3 上构建 Kafka 时,需要面临的关键挑战。
背景
但在深入探讨之前,不妨先问一个简单的问题:“为什么要把数据转移到 S3 上?”,答案是——为了降低成本。
在 Kafka 中,计算与存储是紧耦合的,也就是说,增加存储能就必须添加更多机器,这常常会导致资源利用效率低下。

Kafka 的设计还依赖数据副本来保证数据的持久性。在存储消息后,Leader 必须将数据复制给多个 Follower。由于体系结构的紧耦合,一旦集群成员发生变动,数据就需要在不同机器之间迁移,从而带来额外的开销。
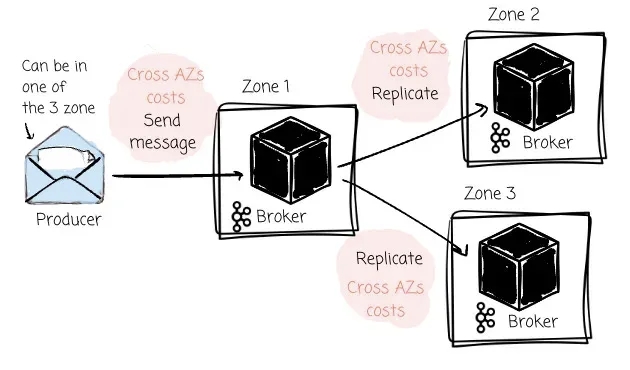
另一个问题是跨可用区(AZ)的传输费用。像 AWS 或 GCP 这样的云服务商会对跨区请求收取额外费用。由于 Producer 只能将消息写入对应的 Partition leader,在云上部署 Kafka 时,如果 Borker 和分区平均分布在三个可用区,Producer 大约有三分之二的时间需要向位于其他可用区的 Leader 写入数据。此外,Kafka 在云上的部署还会产生大量的跨可用区传输费用,因为 Leader 还需要将消息复制给分布在其他可用区的 Follower。
想象一下,如果你将所有数据卸载到像 S3 这样的对象存储上,你可以:
ꔷ 节省存储成本,因为对象存储比磁盘存储更便宜;
ꔷ 实现计算与存储的独立扩展;
ꔷ 避免数据复制,因为对象存储本身具备数据持久性和可用性保障;
ꔷ 让任何 Broker 都可以处理读写请求;
ꔷ ……
基于对象存储构建 Kafka 兼容的解决方案,正成为一股新兴趋势。自 2023 年以来,已有至少五家厂商推出了类似的解决方案。2023 年有 WarpStream 和 AutoMQ,2024 年又有 Confluent Freight Clusters、Bufstream,以及 Redpanda Cloud Topics 等。
抛开这些市场热度不谈,我真正感兴趣的是:构建这样一个基于 S3 的存储层解决方案,究竟会遇到哪些挑战?为此,我选择了 AutoMQ 来进行研究,因为它是目前唯一的开源版本。这使我能够更深入地理解其中的难点与解决方案。
AutoMQ 简介
AutoMQ 是一个 100% 兼容 Kafka 的替代方案。它通过复用 Kafka 的协议栈代码,并重写存储层,利用 Write Ahead Log(预写日志) 技术,实现了在云环境中高效运行 Kafka,并将数据高效卸载到 Object storage(对象存储)中。关于 AutoMQ 的更多介绍,可以参考我之前的文章[1]。
接下来,我们将探讨在 Object storage(对象存储)上构建 Kafka 所面临的潜在挑战,并了解 AutoMQ 是如何逐一应对这些问题的。
01 延迟
第一个也是最直观的挑战是延迟。以下是一些数据,帮助大家更直观地理解:对 Object storage(对象存储)发起 GetObject 请求时,中位延迟大约为 20 毫秒,P90 延迟约为 60 毫秒;而 NVMe SSD 的延迟在 20–100 微秒之间,速度大约快了 1000 倍。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 868
868

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









