




原文链接
 https://vutr.substack.com/p/how-do-we-run-kafka-100-on-the-object
https://vutr.substack.com/p/how-do-we-run-kafka-100-on-the-object
文章导读
AutoMQ 自2023年底正式官宣推出以后,迅速在 Github 上引起广泛的关注并且多次登上 Github Trending. Kafka 近些年俨然已经成为 Streaming 领域的事实标准,在企业的现代化数据基础设施中扮演重要的角色。因此,大家对 Kafka 的成本、弹性、复杂度等问题也表现出越来越多的关切和诉求。AutoMQ 在遵循云优先设计理念的基础上,构建的基于 WAL 和 S3 的新一代 Kafka 流存储引擎一经发布在国际舞台上就收到开发者的高度认可,具备全球竞争力。今天分享的内容翻译自海外开发者的期刊内容,其中对 AutoMQ 的整体架构和技术优势做了图文并茂、由浅入深的详细解读,希望对各位读者有帮助。
“本周,我有幸深入探索 AutoMQ,这是一款由前阿里巴巴工程师打造的云原生,兼容 Kafka 的流处理系统。在这篇文章中,我们将深入解析 AutoMQ 的一项重要技术特性:完全依赖于对象存储运行 Kafka。”
用户评价
部分海外开发者评论和反馈内容截取: 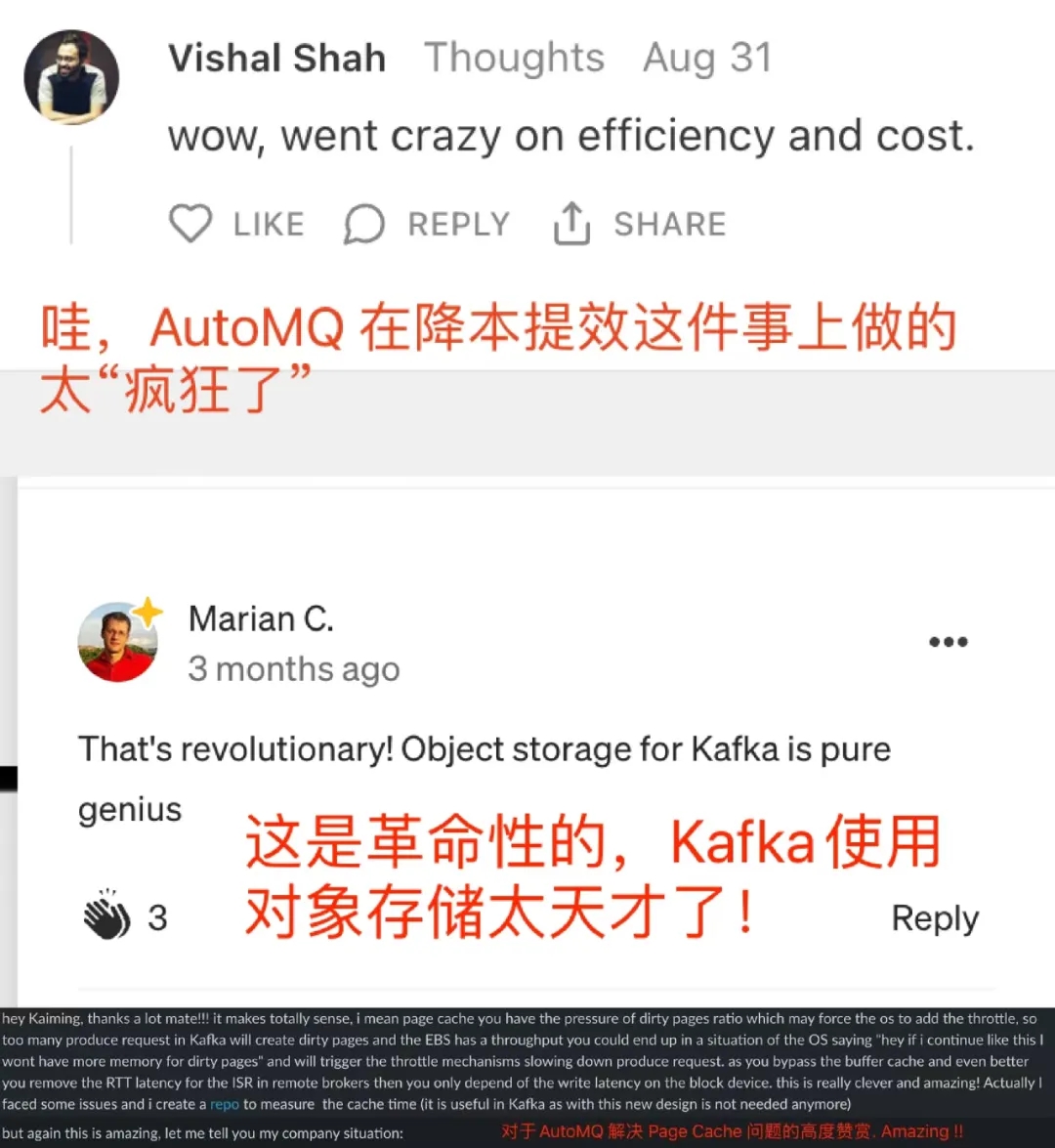
概述
现代操作系统通常会将未被使用的内存(RAM)部分用作页面缓存。频繁使用的磁盘数据会被加载到这个缓存中,避免过度频繁地直接读取磁盘,以此提升性能。
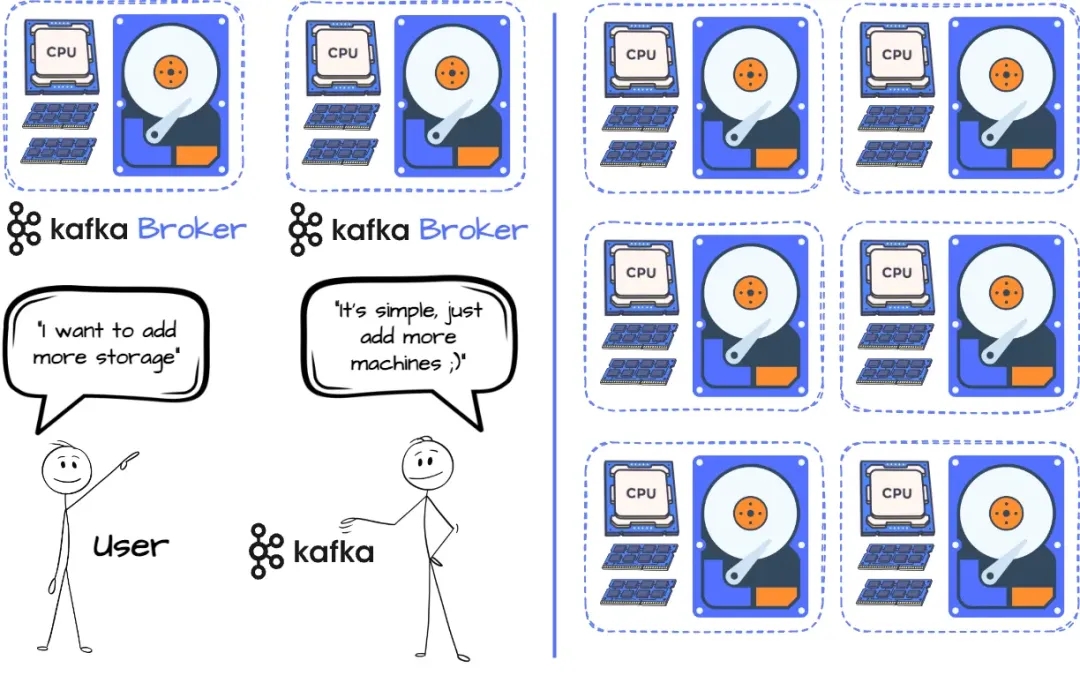
Apache Kakfa 紧密耦合架构
这种设计将计算和存储紧密地结合在一起,这意味着唯一扩展存储的方式就是增加更多的机器。如果你需要更多的磁盘空间,你就必须增加更多的 CPU 和 RAM,这可能会导致资源的浪费。

Apache Kafka分层存储
由于 Kafka 的高度集成的计算存储设计,Uber 在弹性和资源利用率上遇到了问题。为了避免 Kafka 的这种紧密耦合设计,Uber 提出了 Kafka 分层存储方案(KIP-405)。这个方案的主要思路是,一个代理将具备两个层次的存储:本地和远程。本地存储是代理的本地磁盘,用于接收最新的数据,而远程存储则利用像 HDFS/S3/GCS 这样的服务来持久化历史数据。
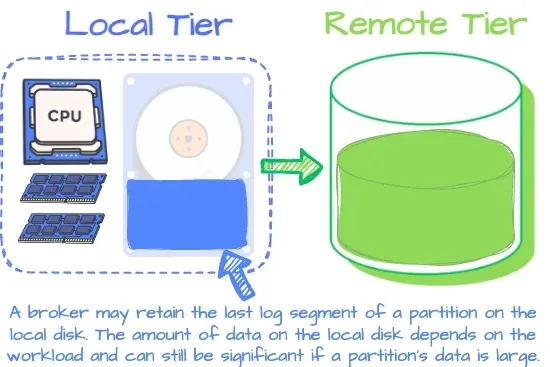
在 Kafka 的分层架构中broker并不是100%无状态 虽然把历史数据转储到远程存储可以减少 Kafka broker 的计算和存储层之间的依赖,但是 broker 并不是完全无状态的。AutoMQ 的工程师们开始思考:“是否存在一种方法,可以将所有的 Kafka 数据存储在对象存储中,同时还能保持像在本地硬盘上一样的高性能?”
存储结构
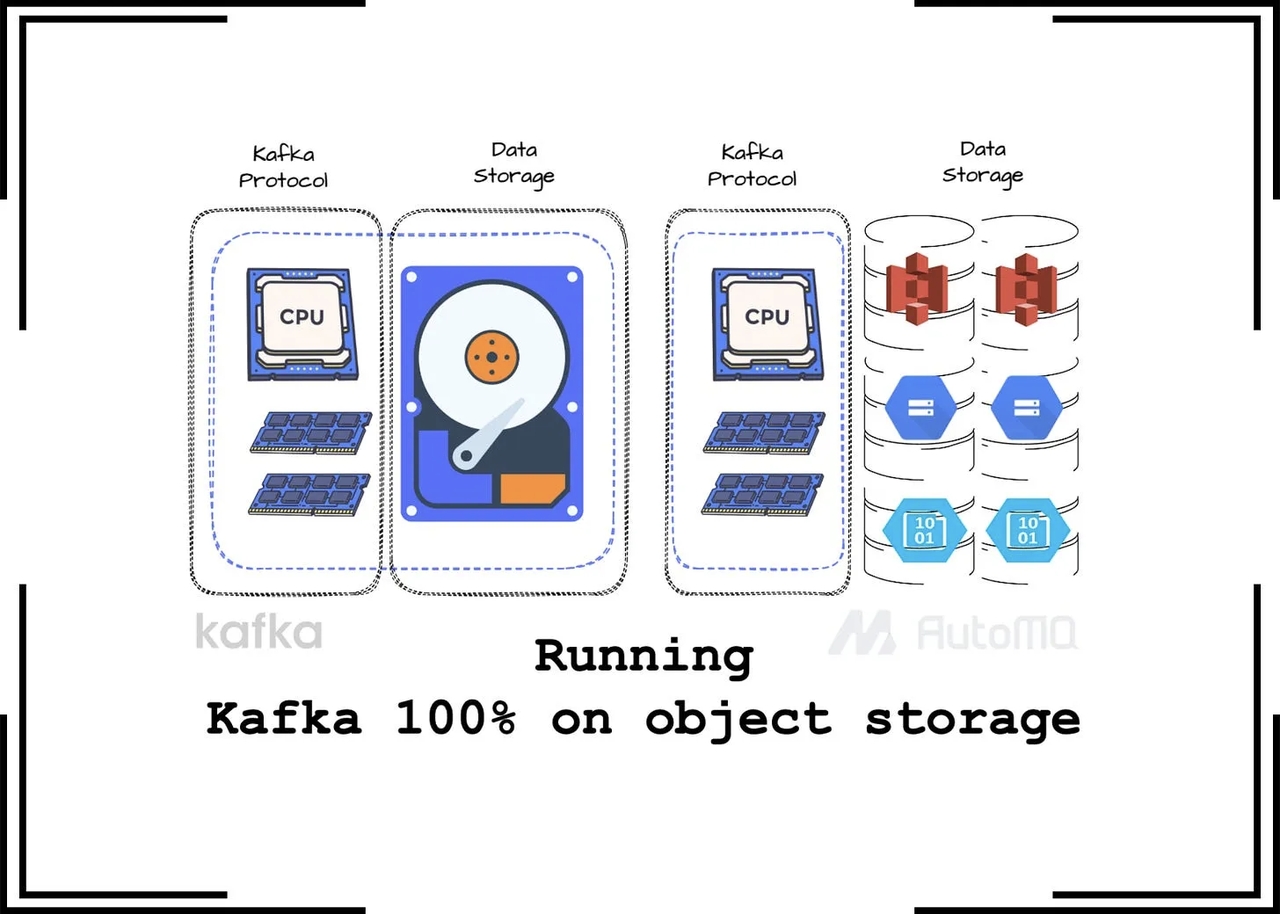
目前,AutoMQ 可以在主流的云服务提供商如 AWS、GCS 和 Azure 上运行,但我将利用我从 AWS 的博客和文档中学习到的知识来描述其架构。AutoMQ 的目标相当直接:通过让 Kafka 将所有消息写入到对象存储,提升 Kafka 的效率和伸缩性,同时不牺牲性能。它实现这个目标的方式是,复用 Apache Kafka 的计算和协议代码,同时引入共享存储架构来替代 Kafka 代理使用的本地磁盘存储。不同于分层存储方法,这种方法需要维护本地和远程
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









