




论文信息
论文标题: STORYTELLER: An Enhanced Plot-planning Framework for Coherent and Cohesive Story Generation - ACL Finding 25
论文作者: Jiaming Li, Yukun Chen1,2 et al. – Shenzhen Institutes of Advanced Technology
论文链接: https://arxiv.org/abs/2506.02347
论文未开源代码
文章领域: 长篇故事生成
研究背景
- 研究问题: 现有故事生成方法(尤其是基于LLM的)在长篇 叙事连贯性 和 逻辑一致性 上存在不足,表现为情节断裂、角色动机突变、主题偏离等。
- 问题根源: 传统方法依赖高层大纲,但章节/事件独立生成,缺乏动态跨章节交互机制。
- 现有故事生成方法: 现有的故事生成方法大致分为三类
- 基于规则的早期方法: 依赖预定义规则和结构化框架生成故事,如 Tale-spin、 Minstrel 等。
- 分层生成方法: 如 Dramatron、DOC 等,先生成高层大纲再扩展为章节,但章节/事件独立生成,缺乏全局协调。
- 知识增强方法: 如 StoRM,引入常识知识或读者模型,但仍难以解决情节碎片化和角色动机突变等问题。
STORYTELLER
本文受人类作家 “检索-评估-生成”认知循环启发,提出动态情节规划框架 STORYTELLER,通过结构化节点和知识图谱实现全局一致性。创新点可总结为三点:
- 基于语言学主谓宾三元组 SVO 的情节结点结构: 通过 “主语 - 动词 - 宾语”(SVO)三元组捕捉核心事件(如<Alex, decide, undergo surgery>),确保每个情节节点的逻辑明确性,为长叙事连贯性奠定基础。
- 动态交互模块 STORYLINE 与 NEKG:
- STORYLINE: 存储所有情节节点并标记时间戳,维持事件的时间顺序和因果关系。
- NEKG (叙事实体知识图谱): 以图结构记录角色、地点等实体关系 (如 Alex - 接受 - 手术),以支持实体交互的逻辑推理。
- 三阶段渐进性生成: 从高层大纲到中层情节节点,再到详细文本,逐步细化故事,确保每一步都受上下文约束。
核心组件
-
NODE (情节节点): 定义为 SVO 三元组 (主语, 谓语, 宾语),若为 SV 结构则转换为 SVS 三元组 (主语, 谓语, 主语),统一表示事件核心要素。
-
STORYLINE: 以列表形式存储所有 NODE (CBN 是章节起始节点, CEN 是章节结束节点, CPN 是章节中间节点),每个节点附带时间戳,确保事件在时间上的有序性,例如:[<Alex, begin, recovery, t0>, <Alex, struggle, recovery, t1>, …]

- NEKG: 基于 Neo4j 构建实体关系图,节点为实体(角色 / 地点 / 物体),边为关系(动作 / 属性)。支持查询实体关联(如 “查询与 Alex 相关的所有医疗事件”),辅助情节合理性判断。
三阶段渐进式生成
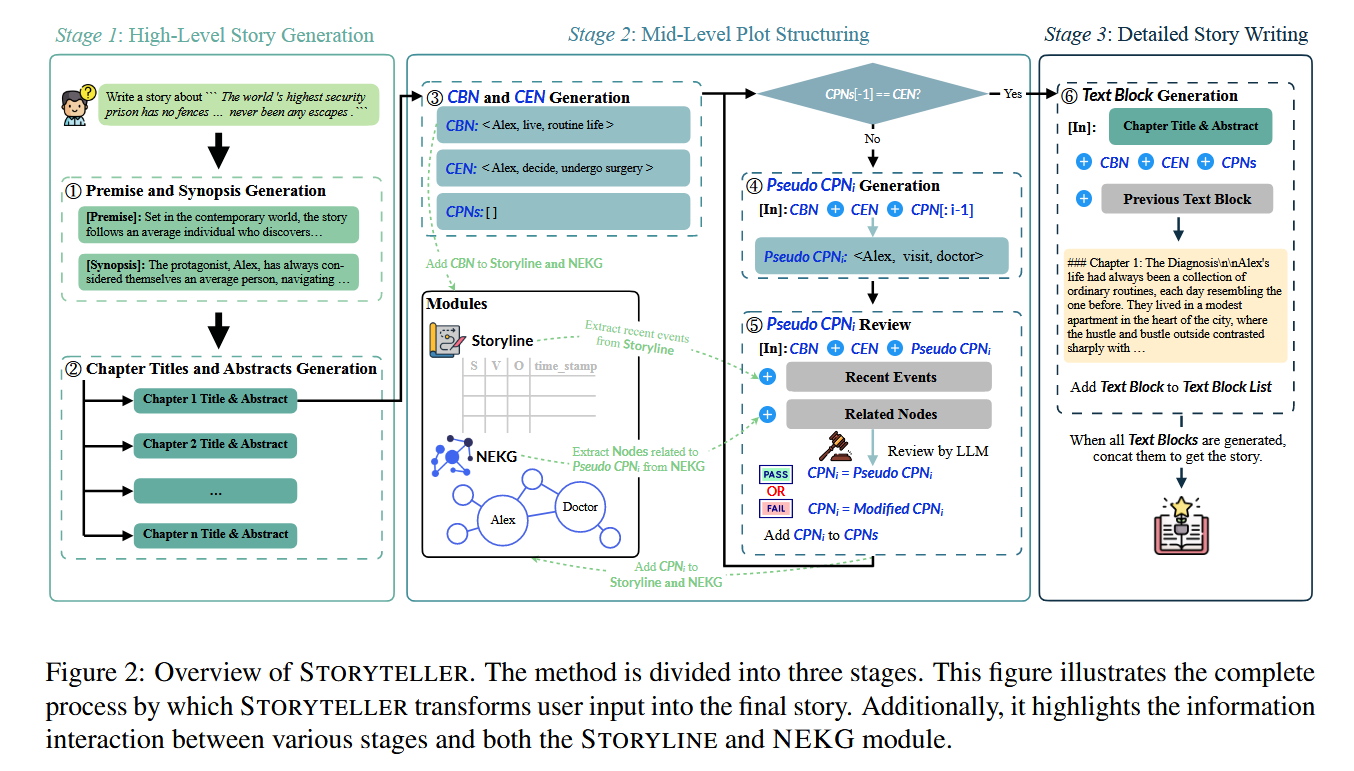
- Stage 1 - 高层故事主线生成: 输入用户提示(如 “世界上最安全的监狱没有围墙……”),生成故事前提(时代、背景)和大纲,划分章节并生成标题与摘要。
- Stage 2 - 中层情节生成: 生成章节起始节点(CBN)和结束节点(CEN),确保章节首尾逻辑衔接;生成伪 CPN(候选中间节点),并通过 STORYLINE 和 NEKG 审查:例如,从 NEKG 检索与伪 CPN 相关的实体关系(如伪 CPN 为<Alex, 拒绝, 治疗>,检索 “Alex - 健康状态” 关系),若伪 CPN 与历史节点冲突(如时间线矛盾),则修正为合理 CPN(如<Alex, 延迟, 治疗>)。
- Stage 3 - 详细故事写作: 基于通过审查的 CPN 序列,生成具体文本块,确保语言风格统一,并复用前文描述维持连贯性。
伪 CPN 的生成与审查
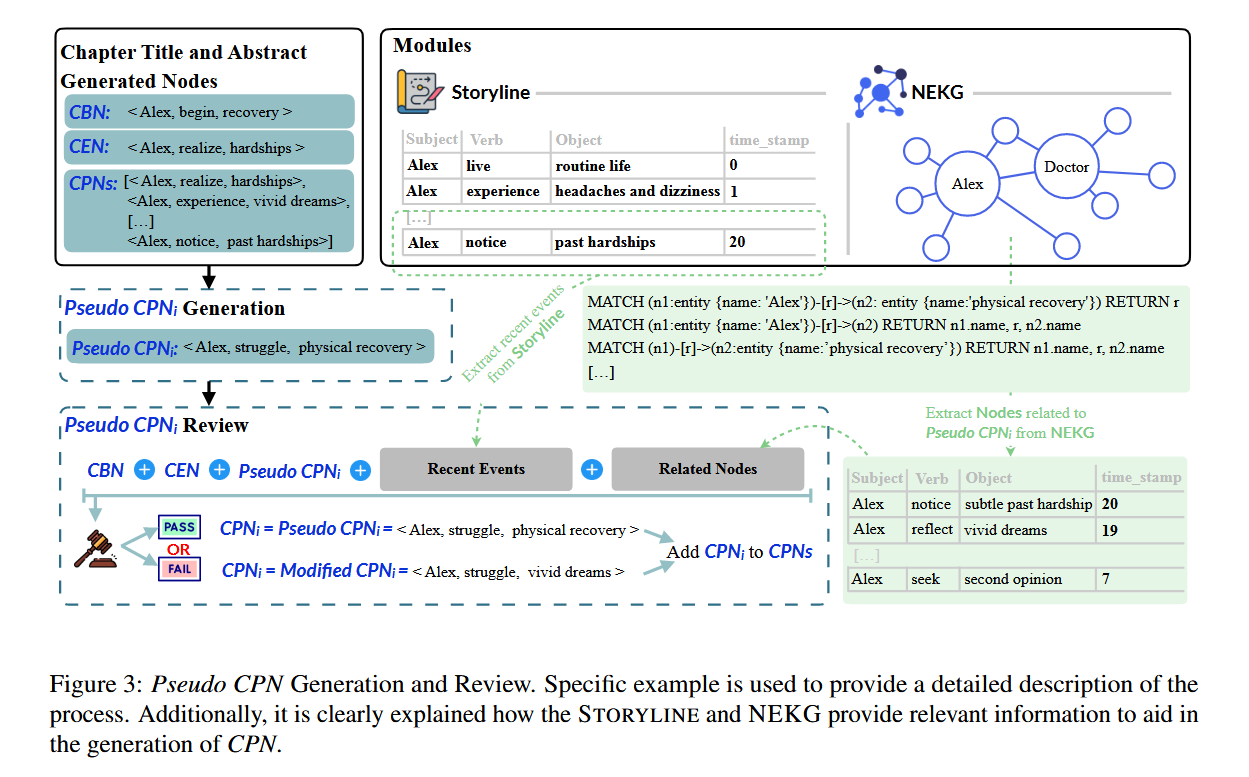
在 STORYTELLER 中保持 故事生成和连贯性的关键为:伪 CPN 生成与审查(Pseudo CPN Generation and Review) 整个流程如下三部分组成:
-
伪 CPN 生成: 基于章节摘要和已有节点,生成候选情节节点(如 “Alex 梦见手术失败”)。
-
CPN 审查: 检查与 STORYLINE 中历史节点的时间顺序(如 “术后康复” 不能早于 “手术”);检查 NEKG 中实体关系合理性(如 “Alex” 若未被诊断疾病,“梦见手术失败” 则需修正),该步骤通过 检索 伪 CPN 中 的 S’ 和 O’ 所对应的所有事件,然后去让 LLM 去判断是否合理。
这里有一个疑问,当 伪 CPN 中的 S’ 和 O’ 所对应的事件足够多的时候,全部检索出来是否会撑爆LLM的上下文窗口,这样的全部检索理论上并不能够完美解决文章中所提到的 “How to extract relevant information from the extensive data?” 这个挑战。 换句话说,这样使用 KG 但是只是 单纯的全部检索出来 可能并不能完美发挥 KG 的特性,只是简单的拼接了一个 KG 在这里。
-
修正策略: 若审查不通过,LLM 基于冲突原因生成修正 CPN(如改为 “Alex 担心手术风险”)。
该流程的终止条件为,生成的 CPN 与 CEN 相同的时候循环结束。我的疑问是如何控制收敛?
实验设置
-
数据集: WRITINGPROMPTS[6](含 27 万训练故事,平均长度 734 词);
-
基线模型: GPT-4o、Qwen2-72B、Llama3.1-70B、DOC v2 、LongWriterModel;
-
评估指标: 人类偏好率、连贯性、创造性、参与度、相关性,以及多样性指标(DistinctL-n、动词多样性);
实验结果
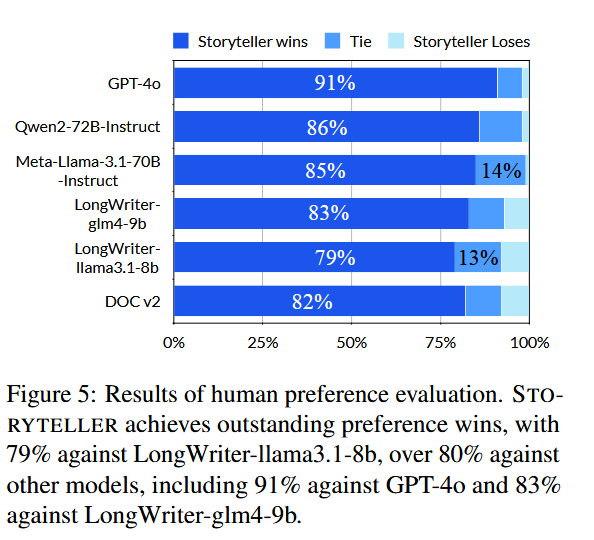
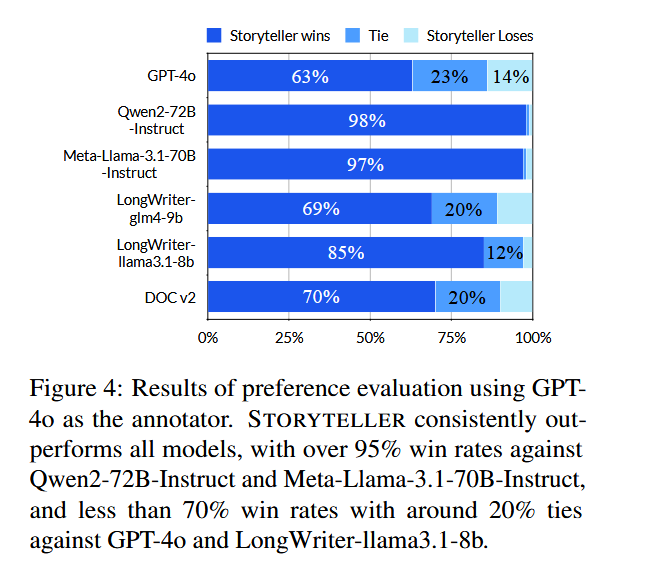
- 人类偏好率: STORYTELLER 以 84.33% 的平均胜率远超 GPT-4o(50%)和 DOC v2(50.9%);
- 多维得分: 连贯性(72.8)、创造性(74.7)、相关性(77.6);
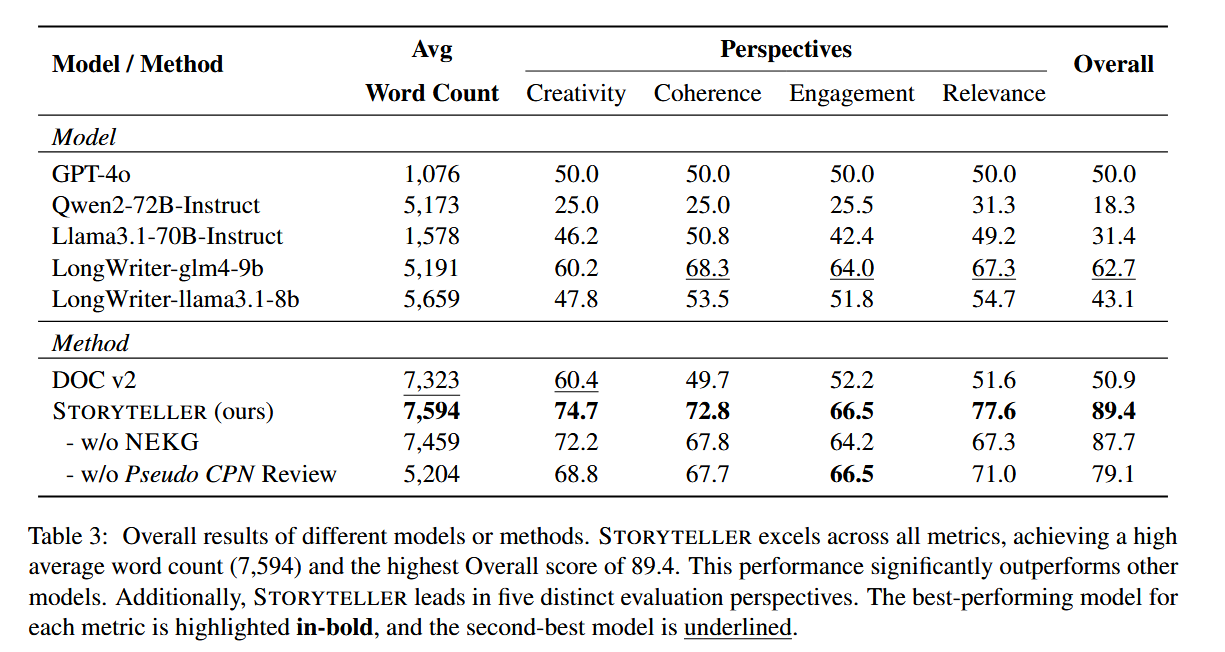
- 消融实验: 移除 NEKG 后相关性下降 10.3 分,移除伪 CPN 审查后整体得分下降 10.3 分,证明核心组件的必要性;
总结
-
与人类写作的差距: 生成内容虽长(平均 7594 词),但深度和复杂度仍不及人类创作的完整小说。更别提网文长度的小说。
-
与长篇小说的差距: 生成内容仍缺乏经典文学作品的深度与复杂性。
-
评估指标不足: 缺乏专业的故事质量评测基准(需结合叙事理论设计新指标)。现有指标(如人类偏好)存在主观性。
-
多体裁泛化: 当前实验集中于一般叙事,需验证在奇幻/科幻等复杂体裁的表现。
这篇文章虽然一直在说 Plan-And-Write 这种模式的模型存在问题,但是在创作中仍然没有跳脱 先做 Plan 再去写作的人类写作思维范式,简单来说像是在 DOC 的基础上 加入了 KG 进行知识增强,但是该论文实现的知识增强并不完美,不能否认这种方法存在参考价值,但仍有拓展空间,即“如何更好的与KG等数据库结合,解决 “How to extract relevant information from the extensive data?” 问题 。

















 1104
1104

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









