




1. 什么是缓存击穿、缓存穿透、缓存雪崩?
Redis单机并发量能达到 万级,MySQL的并发量一般是 千级,它们支持的并发量可能相差十倍,所以要尽量把流量拦截在缓存层。
1.1 缓存击穿:
key过期场景,Redis中的key过期,但MySQL中还有
Redis中的某个key在某个时间过期,导致缓存的作用失效,所有的外界请求直接打在MySQL上。
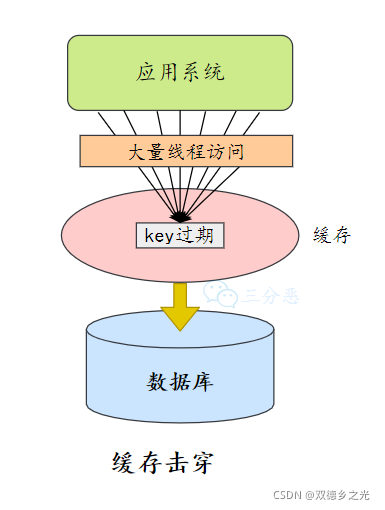
缓存击穿的后果是 增大MySQL数据库的负载:
应用层(数据库代理层)往往采用的是“线程池+连接池”的处理模式,当缓存中的某个key失效,多个线程、多个连接在同一时刻都无法在缓存中查找到这一key值,就会转而去MySQL中查找。
缓存击穿的解决方法是 加锁:当线程发现在缓存中查找不到某个key时,上锁并从MySQL中更新key值到缓存中,其他线程由于无法获得锁而阻塞等待。
TeamTalk中是如何实现的:
Redis中的key永不过期,应用层更新数据时同时更新Redis和MySQL中数据(如 group_member群成员);
1.2 缓存穿透:
缓存Redis和数据库MySQL中不存在的key被访问,则每次都会访问到MySQL中,就好像缓存“不存在”一样,每次都被穿透直接打在DB上,缓存失去了保护后端存储的意义。
造成缓存穿透的可能原因:
- 自身代码问题;
- 恶意攻击,爬虫造成空命中
缓存穿透的解决方法:
- 缓存空值、默认值;
- 布隆过滤器;
什么是布隆过滤器:
1.3 缓存雪崩:
https://mp.weixin.qq.com/s/jMiMtCJ0ItGFKe4pNw-9gw
2. 为什么Redis是单线程的还这么快?
//cloud_desk: tmp_note_0922
- 完全基于内存的操作
- 优秀的数据结构
- 单线程,避免了不必要的线程切换和竞争条件
- 使用多路复用IO模型,epoll
https://blog.youkuaiyun.com/weixin_37356262/article/details/88827688
3. Redis 内存满了怎么办:
redis.conf 配置文件中两个重要的参数:
- maxmemory
- maxmemory-policy
设置配置文件 redis.conf 中的 maxmemory 参数,可以控制其最大可用内存大小(字节)。
当Redis实际所需内存超过了 maxmemory,那么就需要根据 maxmemory-policy 中设置的策略进行处理了。
当内存占满以后,redis提供了一套“缓存淘汰机制”:
Memory Management(内存溢出控制策略)。
Redis支持以下6种策略:
- noeviction(默认值)
旧缓存永不过期,新缓存设置不了,返回错误。 - allkeys-lru
使用LRU算法清除最少用的旧缓存,然后保存新的缓存(推荐使用)。 - allkeys-random
在所有缓存中随机删除(不推荐)。 - volatile-lru
在那些设置了expire过期时间的缓存中,使用LRU算法清除最少用的旧缓存,然后保存新的缓存。 - volatile-random
在哪些设置了expire过期时间的缓存中,随机删除缓存。 - volatile-ttl
在那些设置了expire过期时间的缓存中,删除即将过期的。
LRU算法:
Least Recently Used,最近最少使用算法。
Redis中并不会准确的删除所有键中最近最少使用的键,而是随机抽取5个键,删除这5个键中最近最少使用的键。
https://www.cnblogs.com/gaopengpy/p/12189697.html
4. Redis的两种持久化方法的使用场景?
什么时候应该使用RDB?什么时候应该使用AOF?
https://blog.youkuaiyun.com/weixin_44172800/article/details/106661896

















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









