



 博客主要围绕server1和server4进行高可用配置与测试。包括在两台服务器上配置高可用yum源、安装iscsi,在server2添加磁盘并在server1查看,还涉及分区、格式化、脚本修改等操作。同时进行了moosefs - master异常恢复、fence机制测试,验证了server1接管server4工作等情况。
博客主要围绕server1和server4进行高可用配置与测试。包括在两台服务器上配置高可用yum源、安装iscsi,在server2添加磁盘并在server1查看,还涉及分区、格式化、脚本修改等操作。同时进行了moosefs - master异常恢复、fence机制测试,验证了server1接管server4工作等情况。
在【server1】和【server4】上配置高可用yum源
[root@server1 ~]# vim /etc/yum.repos.d/rhel-source.repo
[rhel-source]
name=Red Hat Enterprise Linux $releasever - $basearch - Source
baseurl=http://172.25.40.250/rhel6.5
enabled=1
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-release
[HighAvailability]
name=HighAvailability
baseurl=http://172.25.40.250/rhel6.5/HighAvailability
gpgcheck=0
[LoadBalancer]
name=LoadBalancer
baseurl=http://172.25.40.250/rhel6.5/LoadBalancer
gpgcheck=0
[ResilientStorage]
name=ResilientStorage
baseurl=http://172.25.40.250/rhel6.5/ResilientStorage
gpgcheck=0[root@server1 ~]# yum install -y crmsh-1.2.6-0.rc2.2.1.x86_64.rpm pssh-2.3.1-2.1.x86_64.rpm moosefs-master-3.0.97-1.rhsysv.x86_64.rpm[root@server1 ~]# cd /etc/corosync/
[root@server1 corosync]# cp corosync.conf.example corosync.conf
[root@server1 corosync]# vim corosync.conf
10 bindnetaddr: 172.25.40.0
11 mcastaddr: 226.94.1.1
12 mcastport: 5959
....
35 service {
36 name: pacemaker
37 ver: 0
38 }
[root@server1 corosync]# /etc/init.d/corosync start
[root@server1 corosync]# scp corosync.conf server4:/etc/corosync以上操作在1和4上同时做
【server4】打开服务
[root@server4 ~]# cd /etc/corosync/
[root@server4 corosync]# ls
corosync.conf corosync.conf.example.udpu uidgid.d
corosync.conf.example service.d
[root@server4 corosync]# /etc/init.d/corosync start在【server1】上查看监控
[root@server1 corosync]# crm_mon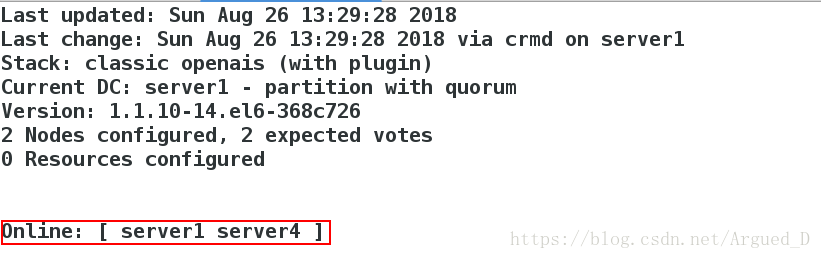
在【server2】添加一个磁盘
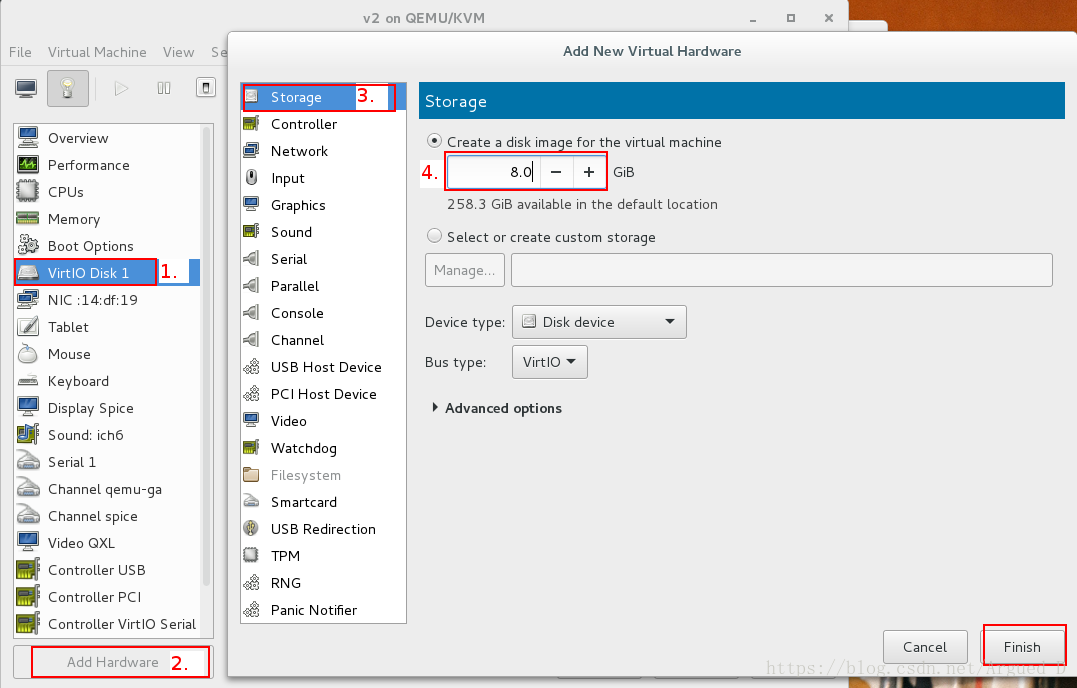
[root@server2 ~]# yum install -y scsi-*
[root@server2 ~]# vim /etc/tgt/targets.conf
38 <target iqn.2018-08.com.example:server.target1>
39 backing-store /dev/vdb
40 </target>
[root@server2 ~]# /etc/init.d/tgtd start在【server1】和【server4】上安装iscsi
[root@server1 corosync]# yum install -y iscsi-*
[root@server4 corosync]# yum install -y iscsi-*【server1】
[root@server1 corosync]# iscsiadm -m discovery -t st -p 172.25.40.2
Starting iscsid: [ OK ]
172.25.40.2:3260,1 iqn.2018-08.com.example:server.target1
[root@server1 corosync]# iscsiadm -m node -l
在【server1】上可以查看到server2添加的磁盘
[root@server1 corosync]# fdisk -l
在【server1】上建立分区
[root@server1 corosync]# fdisk -cu /dev/sda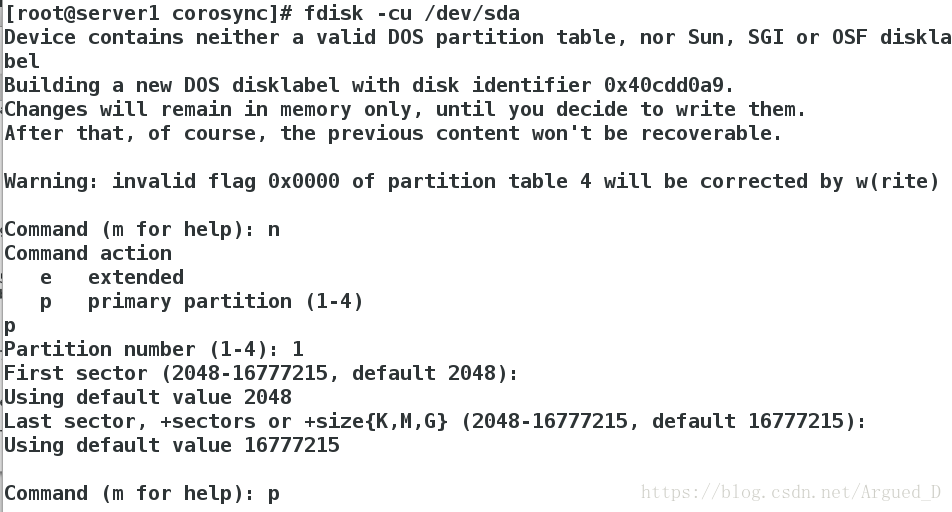
建立完分区要wq保存退出
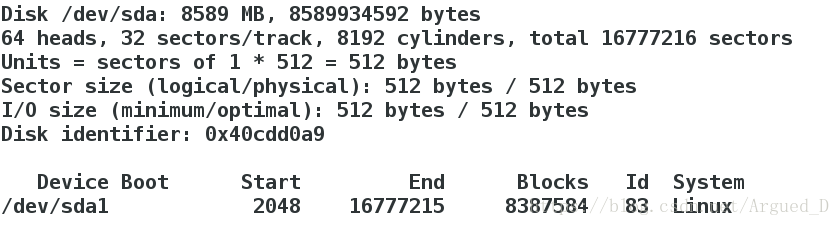
格式化分区
[root@server1 corosync]# mkfs.ext4 /dev/sda1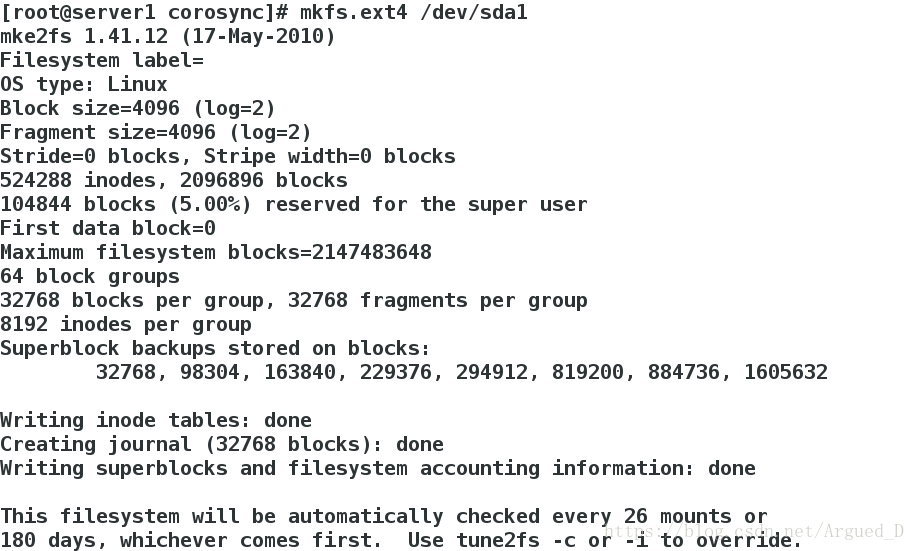
【server4】
[root@server4 corosync]# iscsiadm -m discovery -t st -p 172.25.40.2
[root@server4 corosync]# iscsiadm -m node -l
[root@server4 corosync]# fdisk -l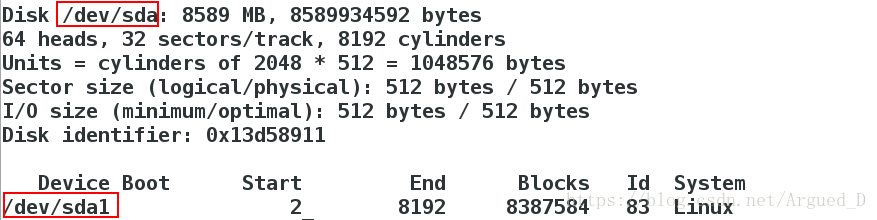
[root@server1 corosync]# /etc/init.d/moosefs-master stop
Stopping mfsmaster: [ OK ]
[root@server1 corosync]# cd /var/lib/mfs/
[root@server1 mfs]# mount /dev/sda1 /mnt/
[root@server1 mfs]# cp -p * /mnt/
[root@server1 mfs]# cd /mnt/
[root@server1 mnt]# cd
[root@server1 ~]# umount /mnt/
[root@server1 ~]# ll -d /var/lib/mfs/
drwxr-xr-x 3 root root 4096 Aug 26 13:57 /var/lib/mfs/
[root@server1 ~]# chown mfs.mfs /var/lib/mfs/
[root@server1 ~]# mount /dev/sda1 /var/lib/mfs
[root@server1 ~]# df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/VolGroup-lv_root 19134332 1032768 17129584 6% /
tmpfs 380140 37152 342988 10% /dev/shm
/dev/vda1 495844 33474 436770 8% /boot
/dev/sda1 8255928 153108 7683444 2% /var/lib/mfs【server4】
[root@server4 ~]# ll -d /var/lib/mfs/
drwxr-xr-x 2 mfs mfs 4096 Aug 26 13:17 /var/lib/mfs/
[root@server4 ~]# /etc/init.d/moosefs-master start
[root@server4 ~]# /etc/init.d/moosefs-master stop自动恢复moosefs-master异常
在【server4】和【server1】上修改脚本
[root@server1 ~]# /etc/init.d/moosefs-master start
[root@server1 ~]# vim /etc/init.d/moosefs-master
31 $prog start >/dev/null 2>&1 || $prog -a >/dev/null 2>&1 && success || f ailure #异常关闭moosefs-master时,脚本会自动恢复正常并且开启master测试:
在不正常情况下关闭moosefs-master
[root@server1 ~]# ps ax
1606 ? S< 0:02 mfsmaster start
[root@server1 ~]# kill -9 1606 #结束进程此时开启moosefs-master时不会报错

Fence机制
在【server1】和【server4】上下载fence
[root@server1 ~]# yum install -y fence-virt
[root@server1 ~]# mkdir /etc/cluster
----------------------------------------------
[root@server4 ~]# yum install -y fence-virt
[root@server4 ~]# stonith_admin -I
[root@server4 ~]# mkdir /etc/cluster[root@foundation40 ~]# systemctl start fence_virtd
[root@foundation40 ~]# systemctl status fence_virtd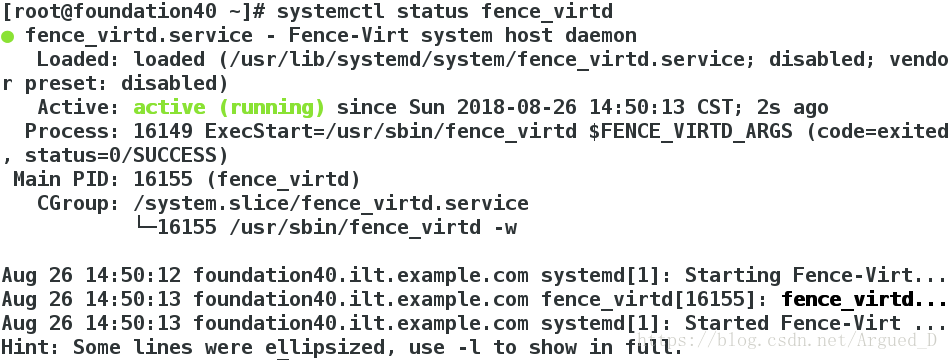
[root@foundation40 cluster]# scp fence_xvm.key root@172.25.40.1:/etc/cluster
[root@foundation40 cluster]# scp fence_xvm.key root@172.25.40.4:/etc/cluster在【server1】上
[root@server1 ~]# /etc/init.d/moosefs-master stop
[root@server1 ~]# crm
crm(live)# configure
crm(live)configure# property no-quorum-policy=ignore
crm(live)configure# commit
crm(live)configure# property stonith-enabled=true
crm(live)configure# commit
crm(live)configure# primitive vmfence stonith:fence_xvm params pcmk_host_map="sever1:v1;server4:v4" op monitor interval=1min
crm(live)configure# commit
crm(live)configure# primitive vip ocf:heartbeat:IPaddr2 params ip=172.25.40.100 cidr_netmask=32 op monitor interval=30s
crm(live)configure# commit
crm(live)configure# primitive mfsdata ocf:heartbeat:Filesystem params device=/dev/sda1 directory=/var/lib/mfs fstype=ext4 op monitor interval=1min
crm(live)configure# primitive mfsmaster lsb:moosefs-master op monitor interval=30s
crm(live)configure# group mfsgroup vip mfsdata mfsmaster
crm(live)configure# commit在【server4】上监控
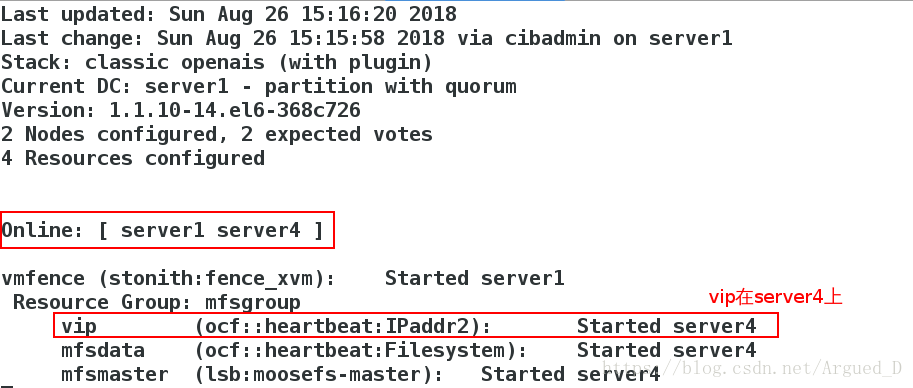
添加解析,集群内所有主机,包括客户机,注意去除原先的解析,这个解析文件会从上往下依次读取
[root@foundation40 cluster]# vim /etc/hosts
172.25.40.250 mfsmaster
[root@server1 cluster]# vim /etc/hosts
172.25.40.100 mfsmaster
[root@server2 ~]# vim /etc/hosts
172.25.40.100 mfsmaster
[root@server3 ~]# vim /etc/hosts
172.25.40.100 mfsmaster
[root@server4 cluster]# vim /etc/hosts
172.25.40.100 mfsmaster[root@server2 ~]# /etc/init.d/moosefs-chunkserver start
[root@server3 ~]# /etc/init.d/moosefs-chunkserver start[root@server4 cluster]# ip addr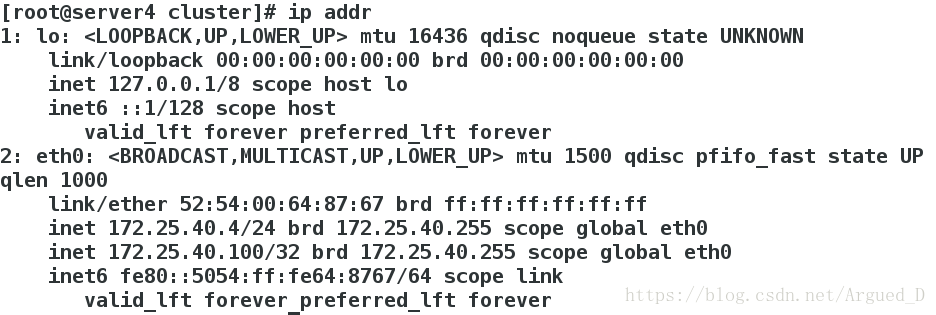
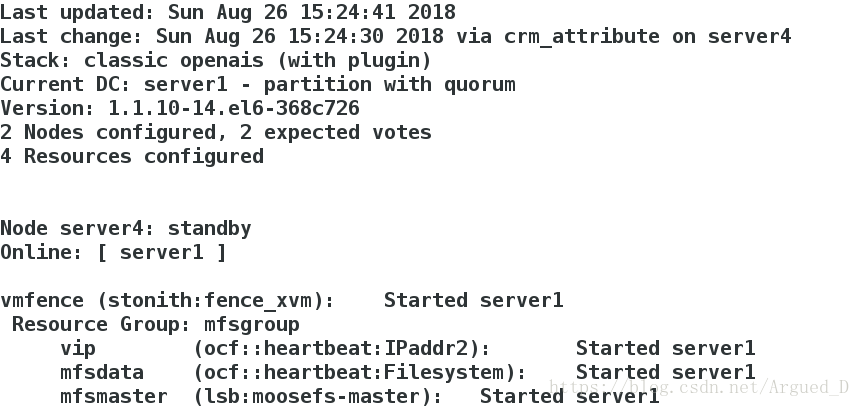
将server4节点关闭
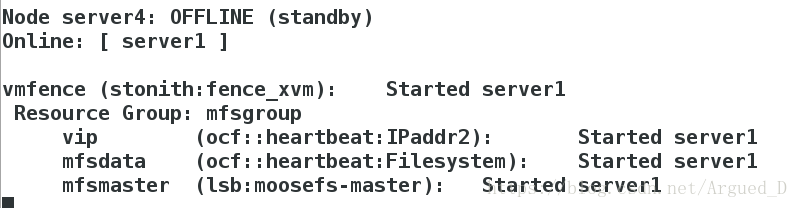
[root@server4 cluster]# crm node standby在server1查看,此时server1接管server4工作
[root@server4 cluster]# crm node online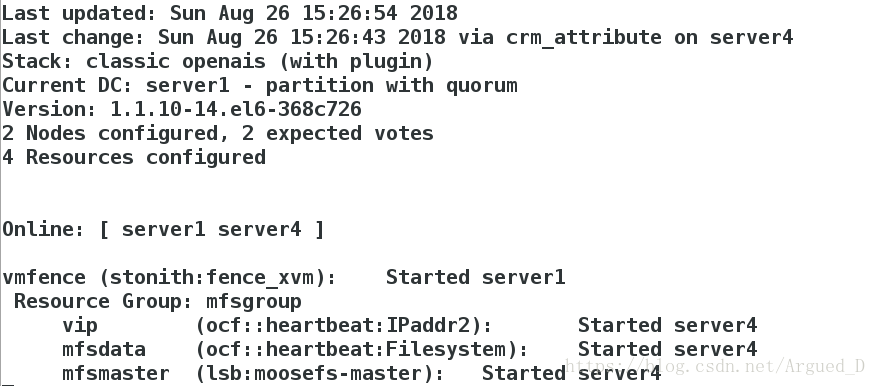
测试:
写入数据时,将master关闭查看数据是否还能正常写入
[root@foundation40 ~]# cd /mnt/mfs/dir1/
[root@foundation40 dir1]# dd if=/dev/zero of=file1 bs=1M count=2000[root@server4 cluster]# crm node standby查看监控
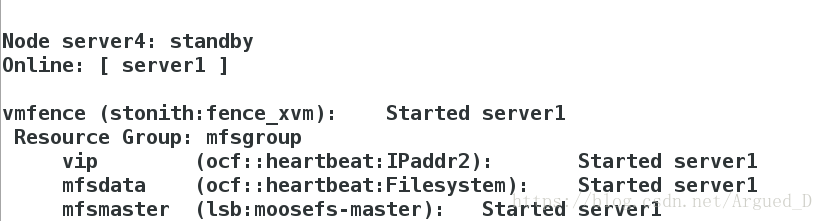
查看结果
[root@foundation40 dir1]# mfsfileinfo file1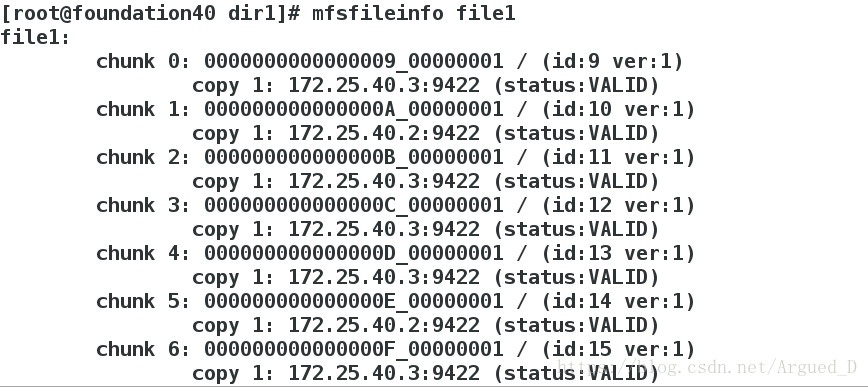
使server4崩溃
[root@server4 cluster]# echo c > /proc/sysrq-trigger 此时server4自动启动
监控上看到server1接管vip

















 420
420

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









