







 该博客详细解析了Non-Local Neural Network论文,探讨了如何在深度学习中引入非局部操作,通过高斯函数、内积和拼接等方法建立不同位置之间的关系。非局部块的使用可以与卷积和循环层结合,并且通过残差连接适应预训练模型。作者还介绍了2D ConvNet和Inflated 3D ConvNet两种基线的实验设置。
该博客详细解析了Non-Local Neural Network论文,探讨了如何在深度学习中引入非局部操作,通过高斯函数、内积和拼接等方法建立不同位置之间的关系。非局部块的使用可以与卷积和循环层结合,并且通过残差连接适应预训练模型。作者还介绍了2D ConvNet和Inflated 3D ConvNet两种基线的实验设置。
论文笔记:Non-Local Neural Network
Abstract
卷积和循环操作都一次只在一个局部neighborhood上操作。
受到传统计算机视觉中非局部中值计算的启发,作者决定使用此方法在深度学习上。
公式
通用公式:
yi=1C(x)∑∀jf(xi,xj)g(xj)
\mathbf{y}_{i}=\frac{1}{\mathcal{C}(\mathbf{x})} \sum_{\forall j} f\left(\mathbf{x}_{i}, \mathbf{x}_{j}\right) g\left(\mathbf{x}_{j}\right)
yi=C(x)1∀j∑f(xi,xj)g(xj)
y\mathbf{y}y is output. xxx 是输入信号。iii是输出的值第i位置的值,j代表所有可能位置。
y\mathbf{y}y 与x\mathbf{x}x 具有相同大小的维度。
C(x)C(x)C(x)是正则化常量
fff代表两处变量的关系
非局部模块十分的灵活,可以放在网络的前面,可以很容易与循环层,卷积层放到一起。
实例
为了简便考虑,g就作为一个简单的线性变换g(xj)=Wgxjg\left(\mathbf{x}_{j}\right)=W_{g} \mathbf{x}_{j}g(xj)=Wgxj, 其中WgW_gWg是作为需要学习的参数。
接下来我们考虑函数fff:
Gaussian
f(xi,xj)=exiTxj f\left(\mathbf{x}_{i}, \mathbf{x}_{j}\right)=e^{\mathbf{x}_{i}^{T} \mathbf{x}_{j}} f(xi,xj)=exiTxj
自然的想法就是使用高斯函数。其中C(x)=∑∀jf(xi,xj).\mathcal{C}(\mathbf{x})=\sum_{\forall j} f\left(\mathbf{x}_{i}, \mathbf{x}_{j}\right).C(x)=∑∀jf(xi,xj).
Embedded Gaussian
f(xi,xj)=eθ(xi)Tϕ(xj) f\left(\mathbf{x}_{i}, \mathbf{x}_{j}\right)=e^{\theta\left(\mathbf{x}_{i}\right)^{T} \phi\left(\mathbf{x}_{j}\right)} f(xi,xj)=eθ(xi)Tϕ(xj)
其中θ(xi)=Wθxi\theta\left(\mathbf{x}_{i}\right)=W_{\theta} \mathbf{x}_{i}θ(xi)=Wθxi and ϕ(xj)=Wϕxj\phi\left(\mathbf{x}_{j}\right)=W_{\phi} \mathbf{x}_{j}ϕ(xj)=Wϕxj, 我们同样可以设置C(x)=∑∀jf(xi,xj).\mathcal{C}(\mathbf{x})=\sum_{\forall j} f\left(\mathbf{x}_{i}, \mathbf{x}_{j}\right).C(x)=∑∀jf(xi,xj).
于是这个计算就变成了softmax: y=softmax(xTWθTWϕx)g(x)\mathbf{y}=\operatorname{softmax}\left(\mathbf{x}^{T} W_{\theta}^{T} W_{\phi} \mathbf{x}\right) g(\mathbf{x})y=softmax(xTWθTWϕx)g(x)
Dot Product
f(xi,xj)=θ(xi)Tϕ(xj) f\left(\mathbf{x}_{i}, \mathbf{x}_{j}\right)=\theta\left(\mathbf{x}_{i}\right)^{T} \phi\left(\mathbf{x}_{j}\right) f(xi,xj)=θ(xi)Tϕ(xj)
设置C(x)=NC(x) = NC(x)=N, 其中N是位置xxx的个数
Concatenation
f(xi,xj)=ReLU(wfT[θ(xi),ϕ(xj)]) f\left(\mathbf{x}_{i}, \mathbf{x}_{j}\right)=\operatorname{ReLU}\left(\mathbf{w}_{f}^{T}\left[\theta\left(\mathbf{x}_{i}\right), \phi\left(\mathbf{x}_{j}\right)\right]\right) f(xi,xj)=ReLU(wfT[θ(xi),ϕ(xj)])
其中WfW_fWf是一个将组合映射到标量的权重向量。 我们设置 C(x)=NC(x)=NC(x)=N.
非局部块
定义:
zi=Wzyi+xi
\mathbf{z}_{i}=W_{z} \mathbf{y}_{i}+\mathbf{x}_{i}
zi=Wzyi+xi
yiy_iyi是式子(1)的结果, +xi+x_i+xi表示残差连接(residual connection)是为了使我们可以添加非局部块到任何提前训练(pre-trained)的模型而不破坏模型结构(比如如果WzW_zWz被初始化为0)。图二是一个例子
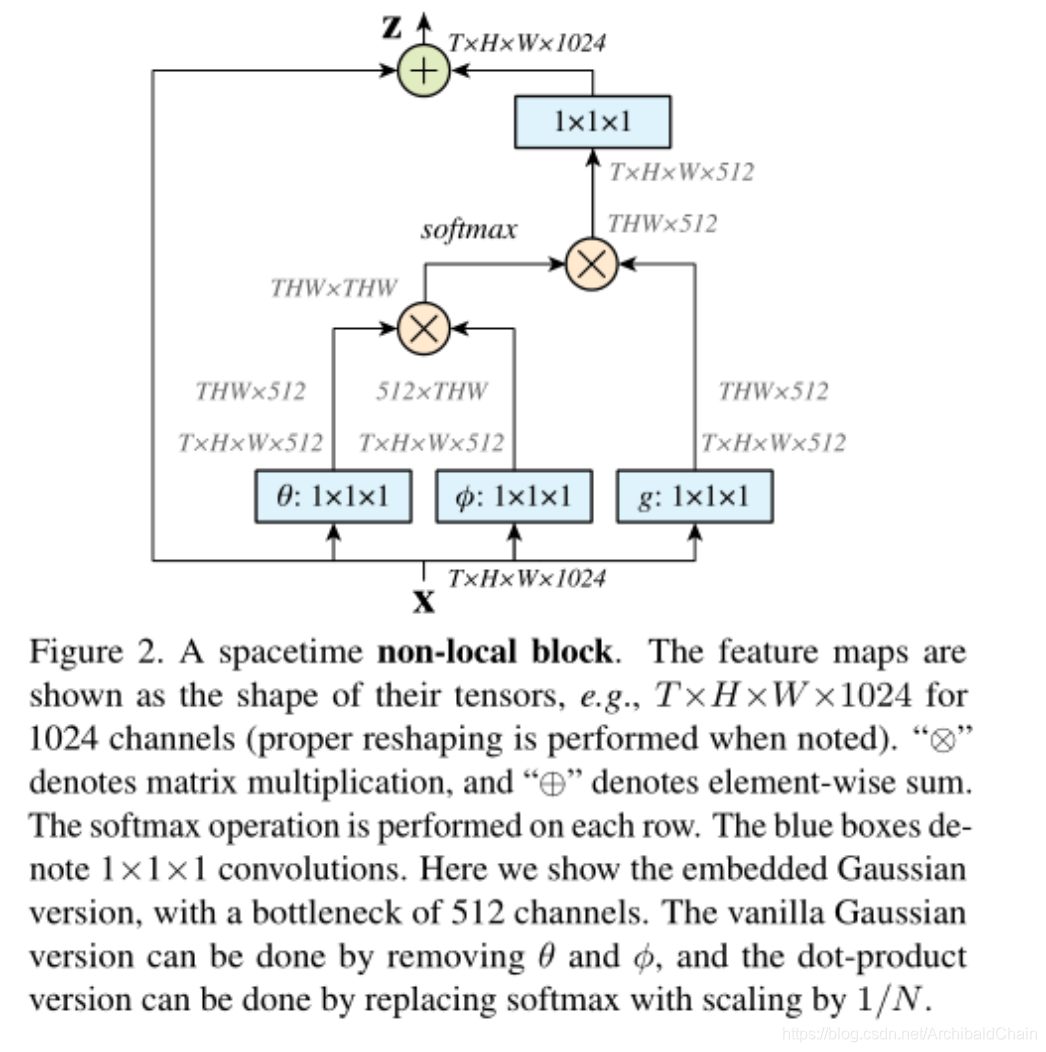
这里可以通过矩阵乘法和加法巧妙的实现非局部变换。
写下来截图的部分便是前文提到的embedding Gaussian的fff
这里θ\thetaθ和ϕ\phiϕ函数都对输入信号进行了降低通道处理。(从T×W×H×1024T\times W \times H \times 1024T×W×H×1024 降到 T×W×H×512T\times W \times H \times 512T×W×H×512)这样可以降低计算,同时也符合瓶颈算法设计。
同时文中说可以将(1)式修改为
1c(x^)∑∀jf(xi,x^j)g(x^j)
\frac{1}{c(\hat{\mathbf{x}})} \sum_{\forall j} f\left(\mathbf{x}_{i}, \hat{\mathbf{x}}_{j}\right) g\left(\hat{\mathbf{x}}_{j}\right)
c(x^)1∀j∑f(xi,x^j)g(x^j)
其中x^\hat{x}x^表示池化后xxx的子采样。 我们通过给θ\thetaθ和ϕ\phiϕ添加赤化层达到这个效果,从而可以使得计算降低1/4.
实现细节
2D ConvNet baseline (C2D)

输入的是32帧的224x224像素视频。整个模型直接使用 ResNet 在ImageNet pre-trained 的权重。只有在赤化层使用了时域。
Inflated 3D ConvNet (I3D)
把卷积核在时域上膨胀开。比如2D上的k×kk\times kk×k 膨胀成 t×k×kt\times k\times kt×k×k
因为3D计算量过于旁大,所以每两个瓶颈只膨胀一个卷积核。要么膨胀3x3成3x3x3;要么膨胀1x1成3x1x1
Non-local Network
作者在两种baseline上分别添加了1,5,10个非局部块做实验
大,所以每两个瓶颈只膨胀一个卷积核。要么膨胀3x3成3x3x3;要么膨胀1x1成3x1x1
Non-local Network
作者在两种baseline上分别添加了1,5,10个非局部块做实验
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-crjZNYL2-1596448249812)(image-20200803174903515.png)]

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









