




大模型的推理和训练
有人问,购买了大模型,怎么训练。日常使用模型,得到越来越精准的结果,以为这是训练大模型。事实上,使用者无法训练大模型,只是通过完善优化提示词,提升了推理。现阶段,训练只能是少数财力雄厚的大厂商可干的。
|
训练 |
推理 | |
|
参与方 |
仅大模型厂商 |
全行业 |
|
开放性 |
封闭 |
开放,通过 API 或私有化部署 |
|
硬件依赖 |
重度依赖英伟达 GPU(算力、生态) |
支持多元化:英伟达 GPU、自研芯片、云端 / 边缘端算力 |
|
技术复杂度 |
极高(模型架构设计、数据处理、大规模并行训练) |
较高(低延迟优化、多模态适配、成本控制) |
|
能耗 |
单轮训练能耗堪比一座小城的年用电量 |
单请求能耗低,可通过硬件优化进一步降低 |
三层模型
大模型按职责可划分为:训练、推理和应用,现有训练,再有推理,后有应用。

第一层:训练阶段 - 能力奠基
核心问题:如何让机器理解世界?
第二层:推理阶段 - 服务化封装
核心问题:如何让智能能力被使用?
第三层:应用阶段 - 价值实现
核心问题:如何用智能解决实际问题?
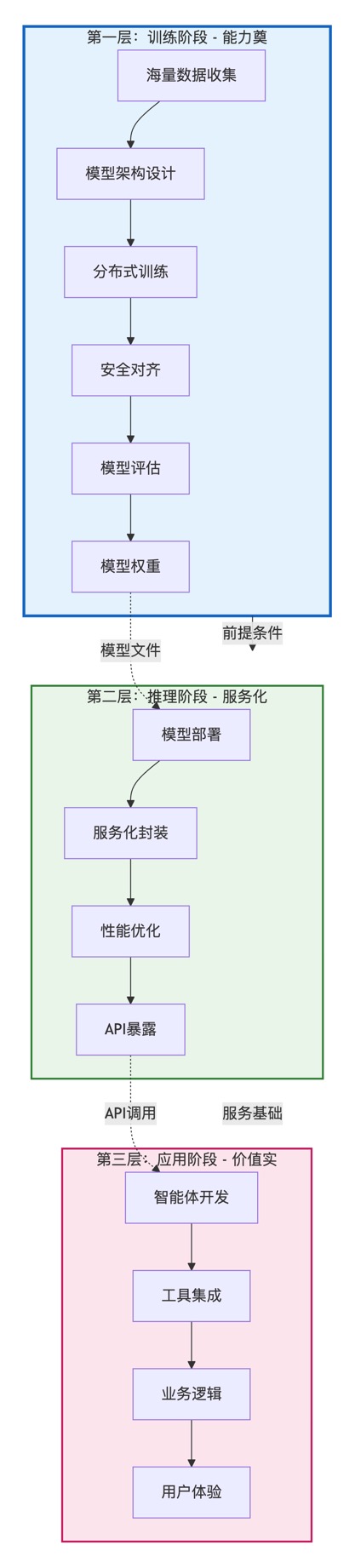
时间顺序依赖
训练(过去完成) → 推理(现在进行) → 应用(未来展望)
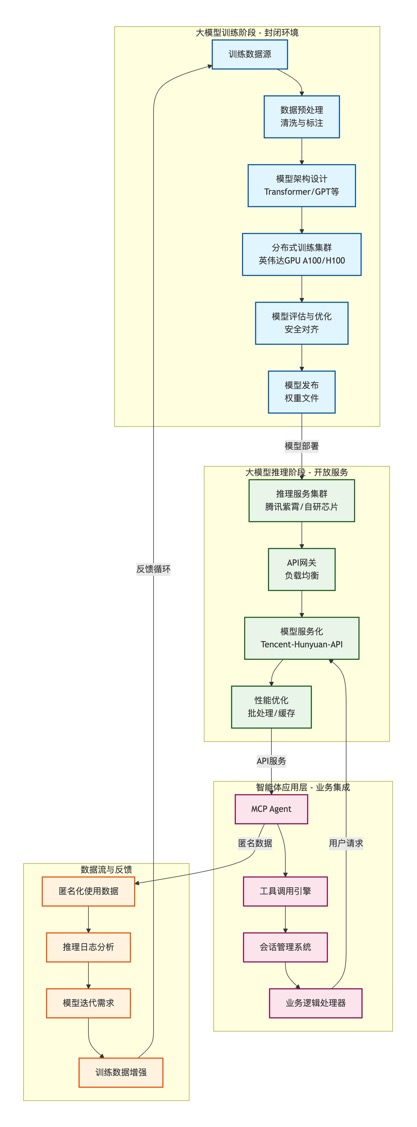
- 训练环节:
-
- 封闭性:核心由大模型厂商(如 OpenAI、字节、腾讯、百度等)掌控,外部企业或个人几乎无法参与。原因不仅是安全保障(防止模型参数泄露、被恶意篡改或用于违规场景),还涉及技术门槛(需要千亿级参数的模型架构设计、超大规模数据清洗与标注能力)、资源门槛(动辄数万张英伟达 A100/H100 芯片的集群,单轮训练成本数千万美元)。
- 技术依赖:目前训练环节高度依赖英伟达 GPU 的算力性能,其 CUDA 生态和芯片架构对大规模并行计算的支持是关键。
- 推理环节:
-
- 开放性:基于大模型的应用(如智能体、各类 AI 工具)均是通过调用大模型的推理能力实现。用户或企业无需拥有大模型,只需通过 API 接口(如 OpenAI 的 GPT API、字节豆包的 API)即可使用其推理功能。
- 硬件创新:大厂为降低推理成本、提升响应速度,普遍布局自研推理芯片,例如腾讯紫霄、阿里含光、百度昆仑等。这些芯片针对推理场景的低延迟、高并发需求做了优化,摆脱了对英伟达芯片的完全依赖。
以之前的图书馆借书为例:
关键结论
- 训练封闭的必要性:
- 保障模型安全和对齐
- 保护知识产权
- 控制技术复杂性
- 推理开放的可行性:
- 通过API安全暴露能力
- 使用自研芯片降低成本
- 支持广泛应用生态
- Agent的定位:
- 基于推理API构建智能应用
- 不涉及模型训练过程
- 通过工具扩展模型能力边界
这种架构既保障了大模型核心技术的安全可控,又通过开放的推理接口支持丰富的应用生态,是当前大模型产业的主流模式。
各个层级的核心差异
1. 控制权与访问权限
|
层级 |
控制方 |
访问权限 |
技术门槛 |
|
训练层 |
大模型厂商 |
完全封闭 |
极高 |
|
推理层 |
云服务商 |
API开放 |
中等 |
|
应用层 |
应用开发者 |
完全开放 |
较低 |
2. 资源需求与成本
|
层级 |
硬件需求 |
能耗水平 |
成本规模 |
|
训练层 |
英伟达H100集群 |
兆瓦级 |
数亿人民币 |
|
推理层 |
自研推理芯片 |
千瓦级 |
千万级 |
|
应用层 |
标准服务器 |
百瓦级 |
百万级 |
3. 技术复杂性
|
层级 |
核心挑战 |
团队要求 |
迭代周期 |
|
训练层 |
分布式训练、收敛性 |
AI研究员、系统专家 |
月/季度 |
|
推理层 |
性能优化、高可用 |
后端工程师、SRE |
周/月 |
|
应用层 |
用户体验、业务集成 |
全栈工程师、产品经理 |
日/周 |
关键架构原则
1. 安全边界
- 训练封闭:保护核心IP和技术秘密
- 推理开放:通过API安全暴露能力
- 数据隔离:用户数据与训练数据严格分离
2. 经济可行性
- 训练重资产:集中投入,规模效应
- 推理可优化:自研芯片降低成本
- 应用轻量级:基于API快速开发
3. 技术演进
- 训练创新:算法突破、架构改进
- 推理优化:芯片定制、服务优化
- 应用丰富:场景拓展、体验提升
这个架构清晰地展示了:
- 训练作为技术基石,封闭但驱动进步
- 推理作为能力桥梁,开放且持续优化
- 应用作为价值载体,创新且用户体验导向
三者形成完整的价值链条,既保障了核心技术安全,又促进了应用生态繁荣。
关键洞察
1. 不可逆的依赖关系
- 没有训练,就没有智能能力
- 没有推理服务化,就无法规模使用
- 没有应用层,就无法创造用户价值
2. 各司其职的产业分工
- 训练层:AI科学家和硬件专家
- 推理层:后端工程师和SRE
- 应用层:产品经理和全栈工程师
3. 不同的创新重点
- 训练:算法突破、架构创新
- 推理:性能优化、成本降低
- 应用:用户体验、场景创新
这个"训练→推理→应用"的三层架构不仅描述了技术依赖关系,也反映了整个大模型产业的生态结构。每一层都有其独特的价值主张、技术挑战和商业模式,共同构成了完整的大模型价值链条。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









