




 本文介绍基于标签传播的社区发现算法,包括非重叠社区发现的LPA算法和重叠社区发现的COPRA算法。LPA算法通过迭代更新节点标签至稳定状态,实现社区划分。COPRA算法在此基础上,引入从属系数,实现重叠社区的识别。
本文介绍基于标签传播的社区发现算法,包括非重叠社区发现的LPA算法和重叠社区发现的COPRA算法。LPA算法通过迭代更新节点标签至稳定状态,实现社区划分。COPRA算法在此基础上,引入从属系数,实现重叠社区的识别。
转自:https://blog.youkuaiyun.com/aspirinvagrant/article/details/46127965
标签传播算法基本思想是通过标记节点的标签信息预测未标记节点的标签情况。节点之间的标签传播主要依照标签相似度进行,在传播过程中,未标记的节点根据邻接点的标签情况来迭代更新自身的标签信息,如果其邻接点与其相似度越相近,则表示对其所标注的影响权值就越大,邻接点的标签就更容易进行传播。
基于标签传播的非重叠社区发现算法LPA
LPA主要思想是起初每个节点拥有独立的标签,那么网络中有n不同标签,每次迭代中对于每个节点将其标签更改为其邻接点中出现次数最多的标签,如果这样的标签有多个,则随机选择一个。通过迭代,直到每个节点的标签与其邻接点中出现次数最多的标签相同,则达到稳定状态,算法结束。此时具有相同标签的节点即属于同一个社区。
LPA算法执行步骤:

利用igraph,给出LPA的R代码
> library('igraph')
> karate <- graph.famous("Zachary")
> community <- label.propagation.community(karate)
> modularity(community)
[1] 0.3717949
> membership(community)
[1] 1 1 1 1 1 1 1 1 2 1 1 1 1 1 2 2 1 1 2 1 2 1 2 2 2 2 2 2 2 2 2 2 2 2
> plot(community,karate)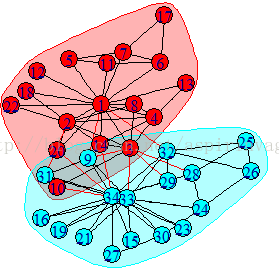
基于标签传播的重叠社区发现算法COPRA
LPA算法虽然有很多优势,但无法发现重叠社区结构。对此,基于LPA算法,引入了新的标签结构(c,b),其中,c表示社区标识符,b表示节点x在社区c中的从属系数,且0≤b≤1。顶点x的所有从属系数之和等于1,通过bt(c,b)表示迭代次数t时的顶点x对于社区c的从属系数,N(x)表示顶点x的邻接顶点集。
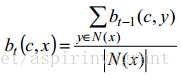
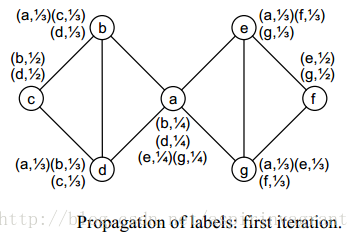
输入:图graph(V,E),K
输出:节点的社区信息partition
1: 为每一个节点设置唯一的社区标签
2: 在没有达到终止条件前,对每一个节点重复执行:
3: 更新节点对其邻居节点所在社区的隶属度bc
4: 如果 bc < 1/K :
5: 排除社区标签
6: 如果所有社区标签 bc < 1/K :
7: 随机选取一个社区标签

















 1163
1163

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









