




 本文详细介绍了Java中的泛型使用,包括集合泛型、泛型通配符的扩展与限制,以及泛型转型。接着讲解了Lambda表达式的概念和优缺点,展示了如何用Lambda简化匿名类的代码。接着探讨了线程的创建方式、同步机制,以及避免死锁的策略。此外,还讨论了线程池的原理和Lock对象在多线程交互中的应用,最后提到了原子访问操作的重要性。文章深入浅出地阐述了Java并发编程的关键概念和技术。
本文详细介绍了Java中的泛型使用,包括集合泛型、泛型通配符的扩展与限制,以及泛型转型。接着讲解了Lambda表达式的概念和优缺点,展示了如何用Lambda简化匿名类的代码。接着探讨了线程的创建方式、同步机制,以及避免死锁的策略。此外,还讨论了线程池的原理和Lock对象在多线程交互中的应用,最后提到了原子访问操作的重要性。文章深入浅出地阐述了Java并发编程的关键概念和技术。
写在前面:教程参考自HOW2J.CN,感谢站主的辛苦付出。
泛型
集合中的泛型
不使用泛型带来的问题是:ArrayList 默认接受Object类型的对象,所有对象都可以放进ArrayList中,所以get取出的对象类型是Object,需要进行强制类型转换。如果记不清就会出现转换异常。
使用泛型,在容器后面加<type>,可以是类、抽象类、接口。这样就限制了容器只能存放对应类型的对象。且泛型类型的子类也可以放进去。
JDK7提供了泛型的简写方式:
ArrayList<Hero> heros2 = new ArrayList<>();支持泛型的类
设计这个类的时候,在类的声明上加一个<T>,表示该类支持泛型。T可以替换成其他合法变量,单约定俗成使用T,代表类型。
import java.util.HashMap;
import java.util.LinkedList;
import charactor.Hero;
import property.Item;
public class MyStack<T> {
LinkedList<T> values = new LinkedList<T>();
public void push(T t) {
values.addLast(t);
}
public T pull() {
return values.removeLast();
}
public T peek() {
return values.getLast();
}
public static void main(String[] args) {
//在声明这个Stack的时候,使用泛型<Hero>就表示该Stack只能放Hero
MyStack<Hero> heroStack = new MyStack<>();
heroStack.push(new Hero());
//不能放Item
heroStack.push(new Item());
//在声明这个Stack的时候,使用泛型<Item>就表示该Stack只能放Item
MyStack<Item> itemStack = new MyStack<>();
itemStack.push(new Item());
//不能放Hero
itemStack.push(new Hero());
}
}泛型通配符 ? extends super的用法
ArrayList heroList<? extends Hero> 表示这是一个Hero泛型或者其子类泛型,可以确凿的是,从heroList取出来的对象,一定是可以转型成Hero的,但是不能放东西进去。
ArrayList heroList<? super Hero> 表示这是一个Hero泛型或者其父类泛型。heroList的泛型可能是Hero,也可能是Object。可以往里面插入Hero以及Hero的子类,但是取出来有风险,因为不确定取出来是Hero还是Object,因此不能取数据。
ArrayList<?> generalList = apHeroList 泛型通配符? 代表任意泛型。既然?代表任意泛型,那么换句话说,这个容器什么泛型都有可能,所以只能以Object的形式取出来,并且不能往里面放对象,因为不知道到底是一个什么泛型的容器。
总结:
- 如果希望只取出,不插入,就使用? extends Hero
- 如果希望只插入,不取出,就使用? super Hero
- 如果希望,又能插入,又能取出,就不要用通配符?
泛型转型
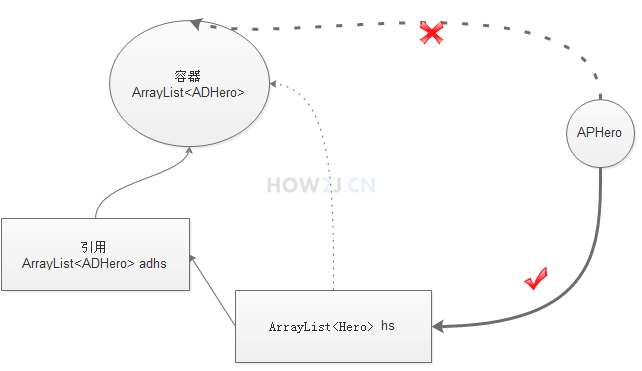
根据对象的相关知识,子类转父类是可以成功的。但是,子类泛型转父类泛型是不行的。
假设可以转型成功,引用hs指向了ADHero泛型的容器。作为Hero泛型的引用hs, 看上去是可以往里面加一个APHero的。但是hs这个引用,实际上是指向的一个ADHero泛型的容器,如果能加进去,就变成了ADHero泛型的容器里放进了APHero,这就矛盾了。
所以子类泛型不可以转换为父类泛型。
Lambda
需求:找出符合条件的对象(Hero)
匿名类方式:首先准备一个接口,提供test方法,再通过匿名类的方式,实现这个接口。
public class TestLambda {
public static void main(String[] args) {
Random r = new Random();
List<Hero> heros = new ArrayList<Hero>();
for (int i = 0; i < 5; i++) {
heros.add(new Hero("hero " + i, r.nextInt(1000), r.nextInt(100)));
}
System.out.println("初始化后的集合:");
System.out.println(heros);
System.out.println("使用匿名类的方式,筛选出 hp>100 && damange<50的英雄");
HeroChecker checker = new HeroChecker() {
@Override
public boolean test(Hero h) {
return (h.hp>100 && h.damage<50);
}
};
filter(heros,checker);
}
private static void filter(List<Hero> heros,HeroChecker checker) {
for (Hero hero : heros) {
if(checker.test(hero))
System.out.print(hero);
}
}
}Lambda方式是从匿名类演变过来的,和匿名类的概念相比较,Lambda实际是匿名方法,是一种把方法作为参数进行传递的编程思想,Java在编译中其实都把这些还原为匿名类方式,引入Lambda使得代码更加紧凑。
public class TestLamdba {
public static void main(String[] args) {
Random r = new Random();
List<Hero> heros = new ArrayList<Hero>();
for (int i = 0; i < 5; i++) {
heros.add(new Hero("hero " + i, r.nextInt(1000), r.nextInt(100)));
}
filter(heros,h->h.hp>100 && h.damage<50);
}
private static void filter(List<Hero> heros,HeroChecker checker) {
for (Hero hero : heros) {
if(checker.test(hero))
System.out.print(hero);
}
}
}弊端:
1. 可读性差,与啰嗦的但是清晰的匿名类代码结构比较起来,Lambda表达式一旦变得比较长,就难以理解
2. 不便于调试,很难在Lambda表达式中增加调试信息,比如日志
3. 版本支持,Lambda表达式在JDK8版本中才开始支持,如果系统使用的是以前的版本,考虑系统的稳定性等原因,而不愿意升级,那么就无法使用。
Lambda比较适合用在简短的业务代码中,并不适合用在复杂的系统中,会加大维护成本。
练习:把比较器-Comparator 章节中的代码,改写为Lambda表达式。

Lambda的方法引用
引用静态方法
public static boolean testHero(Hero h) {
return h.hp>100 && h.damage<50;
}
//在Lambda表达式中调用这个静态方法:
filter(heros, h -> TestLambda.testHero(h) );
//调用静态方法还可以改写为:
filter(heros, TestLambda::testHero);引用对象方法
传递方法的时候,需要一个对象的存在
TestLambda testLambda = new TestLambda();
filter(heros, testLambda::testHero);引用容器中的对象的方法
//在Lambda表达式中调用容器中的对象Hero的方法matched
filter(heros,h-> h.matched() );
//matched恰好就是容器中的对象Hero的方法,那就可以进一步改写为
filter(heros, Hero::matched);引用构造器
List list2 = getList(()->new ArrayList());
List list3 = getList(ArrayList::new);
Lambda 聚合操作
heros
.stream()
.filter(h -> h.hp > 100 && h.damage < 50)
.forEach(h -> System.out.println(h.name));要了解聚合操作,首先要建立Stream和管道的概念
Stream和Collection结构化的数据不一样,Stream是一系列的元素,就像是生产线上的罐头一样,一串串的出来。
管道指的是一系列的聚合操作。
管道又分3个部分
管道源:在这个例子里,源是一个List。

中间操作: 每个中间操作,又会返回一个Stream,比如.filter()又返回一个Stream, 中间操作是“懒”操作,并不会真正进行遍历。

结束操作:当这个操作执行后,流就被使用“光”了,无法再被操作。所以这必定是流的最后一个操作。 结束操作不会返回Stream,但是会返回int、float、String、 Collection或者像forEach,什么都不返回, 结束操作才进行真正的遍历行为,在遍历的时候,才会去进行中间操作的相关判断。

多线程
创建线程的三种方式(要有thread对象,要重写run方法)
1. 创建一个类,继承Thread,并重写run方法,实例化该类对象,通过start启动线程。
public class KillThread extends Thread{
private Hero h1;
private Hero h2;
public KillThread(Hero h1, Hero h2){
this.h1 = h1;
this.h2 = h2;
}
public void run(){
while(!h2.isDead()){
h1.attackHero(h2);
}
}
}
KillThread killThread1 = new KillThread(gareen,teemo);
killThread1.start();2. 创建一个类,实现Runnable接口,创建该类对象,根据该对象创建一个线程对象并启动。
public class Battle implements Runnable{
private Hero h1;
private Hero h2;
public Battle(Hero h1, Hero h2){
this.h1 = h1;
this.h2 = h2;
}
public void run(){
while(!h2.isDead()){
h1.attackHero(h2);
}
}
}
Battle battle1 = new Battle(gareen,teemo);
new Thread(battle1).start();
3. 使用匿名类,继承Thread,重写run方法,好处是可以方便的访问到外部的局部变量。
Thread t1= new Thread(){
public void run(){
//匿名类中用到外部的局部变量teemo,必须把teemo声明为final
//但是在JDK7以后,就不是必须加final的了
while(!teemo.isDead()){
gareen.attackHero(teemo);
}
}
};
t1.start();常见线程方法
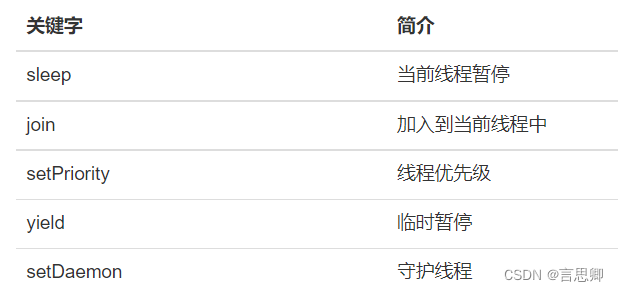
join()
所有进程,至少会有一个线程即主线程,即main方法开始执行,就会有一个看不见的主线程存在。执行t.join,即表明在主线程中加入该线程。主线程会等待该线程结束完毕, 才会往下运行。
setDaemon(True)
守护进程:当一个进程里所有的进程都是守护进程的时候,结束当前进程。守护线程相当于一个公司的支撑部门,通常用来做日志、性能统计等工作。
多线程同步
多线程的同步问题指的是:多个线程同时修改一个数据的时候,可能导致的问题(Concurrency)
Object someObject =new Object();
synchronized (someObject){
//此处的代码只有占有了someObject后才可以执行
}synchronized关键字
synchronized表示当前进程,独占对象someObject,当线程独占了该对象,若有其他线程试图占有对象someObject,就需要等待。someObject又叫做同步对象,所有对象都可以作为同步对象。
释放同步对象的方式: synchronized 块自然结束,或者有异常抛出。
既然任意对象都可以用来作为同步对象,而所有的线程访问的都是同一个hero对象,索性就使用gareen来作为同步对象。

进一步的,对于Hero的hurt方法,加上:synchronized (this) {},表示当前对象为同步对象,即也是gareen为同步对象。

在方法前,加上修饰符synchronized,其所对应的同步对象就是this,和hurt达到的效果一样。

线程安全的类
指的是方法都有synchronized修饰的类。
比如StringBuffer和StringBuilder的区别(前面章节提到)
StringBuffer的方法都是有synchronized修饰的,StringBuffer就叫做线程安全的类
而StringBuilder就不是线程安全的类。
死锁
1. 线程1 首先占有对象1,接着试图占有对象2
2. 线程2 首先占有对象2,接着试图占有对象1
3. 线程1 等待线程2释放对象2
4. 与此同时,线程2等待线程1释放对象1
public class TestThread {
public static void main(String[] args) {
final Hero ahri = new Hero();
ahri.name = "九尾妖狐";
final Hero annie = new Hero();
annie.name = "安妮";
Thread t1 = new Thread(){
public void run(){
//占有九尾妖狐
synchronized (ahri) {
System.out.println("t1 已占有九尾妖狐");
try {
//停顿1000毫秒,另一个线程有足够的时间占有安妮
Thread.sleep(1000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println("t1 试图占有安妮");
System.out.println("t1 等待中 。。。。");
synchronized (annie) {
System.out.println("do something");
}
}
}
};
t1.start();
Thread t2 = new Thread(){
public void run(){
//占有安妮
synchronized (annie) {
System.out.println("t2 已占有安妮");
try {
//停顿1000毫秒,另一个线程有足够的时间占有暂用九尾妖狐
Thread.sleep(1000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println("t2 试图占有九尾妖狐");
System.out.println("t2 等待中 。。。。");
synchronized (ahri) {
System.out.println("do something");
}
}
}
};
t2.start();
}
}交互
线程之间有交互通知的需求,使用wait和notify进行线程交互。
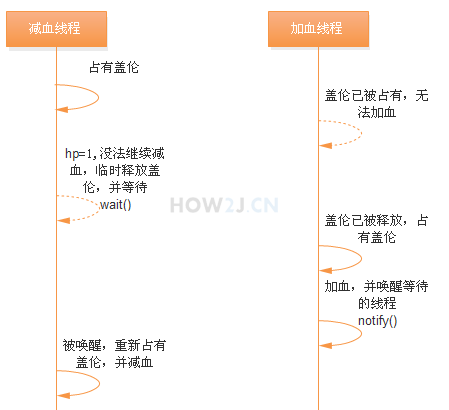
Hero.java
public synchronized void recover() {
hp = hp + 1;
System.out.printf("%s 回血1点,增加血后,%s的血量是%.0f%n", name, name, hp);
// 通知那些等待在this对象上的线程,可以醒过来了,如第20行,等待着的减血线程,苏醒过来
this.notify();
}
public synchronized void hurt() {
if (hp == 1) {
try {
// 让占有this的减血线程,暂时释放对this的占有,并等待
this.wait();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
hp = hp - 1;
System.out.printf("%s 减血1点,减少血后,%s的血量是%.0f%n", name, name, hp);
}TestThread.java
public class TestThread {
public static void main(String[] args) {
final Hero gareen = new Hero();
gareen.name = "盖伦";
gareen.hp = 616;
Thread t1 = new Thread(){
public void run(){
while(true){
//无需循环判断
// while(gareen.hp==1){
// continue;
// }
gareen.hurt();
try {
Thread.sleep(10);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
};
t1.start();
Thread t2 = new Thread(){
public void run(){
while(true){
gareen.recover();
try {
Thread.sleep(100);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
};
t2.start();
}
}wait方法和notify方法,并不是Thread线程上的方法,它们是Object上的方法。因为所有的Object都可以被用来作为同步对象,所以准确的讲,wait和notify是同步对象上的方法。
- wait()的意思是: 让占用了这个同步对象的线程,临时释放当前的占用,并且等待。 所以调用wait是有前提条件的,一定是在synchronized块里,否则就会出错。
- notify() 的意思是,通知一个等待在这个同步对象上的线程,你可以苏醒过来了,有机会重新占用当前对象了。
- notifyAll() 的意思是,通知所有的等待在这个同步对象上的线程,你们可以苏醒过来了,有机会重新占用当前对象了。
线程池
每一个线程的启动和结束都是比较消耗时间和占用资源的。如果在系统中用到了很多的线程,大量的启动和结束动作会导致系统的性能变卡,响应变慢。
为了解决这个问题,引入线程池这种设计思想。
线程池的思路和生产者消费者模型是很接近的。
- 准备一个任务容器
- 一次性启动10个 消费者线程
- 刚开始任务容器是空的,所以线程都wait在上面。
- 直到一个外部线程往这个任务容器中扔了一个“任务”,就会有一个消费者线程被唤醒notify
- 这个消费者线程取出“任务”,并且执行这个任务,执行完毕后,继续等待下一次任务的到来。
- 如果短时间内,有较多的任务加入,那么就会有多个线程被唤醒,去执行这些任务。
在整个过程中,都不需要创建新的线程,而是循环使用这些已经存在的线程。
线程池类ThreadPoolExecutor
ThreadPoolExecutor threadPool= new ThreadPoolExecutor(10, 15, 60, TimeUnit.SECONDS, new LinkedBlockingQueue<Runnable>());第一个参数10 表示这个线程池初始化了10个线程在里面工作
第二个参数15 表示如果10个线程不够用了,就会自动增加到最多15个线程
第三个参数60 结合第四个参数TimeUnit.SECONDS,表示经过60秒,多出来的线程还没有接到活儿,就会回收,最后保持池子里就10个
第四个参数TimeUnit.SECONDS 如上
第五个参数 new LinkedBlockingQueue() 用来放任务的集合
execute方法用于添加新的任务
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class TestThread {
public static void main(String[] args) throws InterruptedException {
ThreadPoolExecutor threadPool= new ThreadPoolExecutor(10, 15, 60, TimeUnit.SECONDS, new LinkedBlockingQueue<Runnable>());
threadPool.execute(new Runnable(){
@Override
public void run() {
// TODO Auto-generated method stub
System.out.println("任务1");
}
});
}
}lock对象实现同步效果
Lock lock = new ReentrantLock();与 synchronized (someObject) 类似的,lock()方法,表示当前线程占用lock对象,一旦占用,其他线程就不能占用了。
与 synchronized 不同的是,一旦synchronized 块结束,就会自动释放对someObject的占用。 lock却必须调用unlock方法进行手动释放,为了保证释放的执行,往往会把unlock() 放在finally中进行。
Thread t1 = new Thread() {
public void run() {
try {
log("线程启动");
log("试图占有对象:lock");
lock.lock();
log("占有对象:lock");
log("进行5秒的业务操作");
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
log("释放对象:lock");
lock.unlock();
}
log("线程结束");
}
};trylock
在指定时间内试图占用,时间到了占用不到就算了。注意: 因为使用trylock有可能成功,有可能失败,所以后面unlock释放锁的时候,需要判断是否占用成功了,如果没占用成功也unlock,就会抛出异常。
try {
log("线程启动");
log("试图占有对象:lock");
locked = lock.tryLock(1,TimeUnit.SECONDS);
if(locked){
log("占有对象:lock");
log("进行5秒的业务操作");
Thread.sleep(5000);
}
else{
log("经过1秒钟的努力,还没有占有对象,放弃占有");
}
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
if(locked){
log("释放对象:lock");
lock.unlock();
}
}
log("线程结束");
}lock的线程交互
Lock也提供了类似的解决办法,首先通过lock对象得到一个Condition对象,然后分别调用这个Condition对象的:await, signal,signalAll 方法。注意: 不是Condition对象的wait,nofity,notifyAll方法,是await,signal,signalAll
Lock lock = new ReentrantLock();
Condition condition = lock.newCondition();
Thread t1 = new Thread() {
public void run() {
try {
log("线程启动");
log("试图占有对象:lock");
lock.lock();
log("占有对象:lock");
log("进行5秒的业务操作");
Thread.sleep(5000);
log("临时释放对象 lock, 并等待");
condition.await();
log("重新占有对象 lock,并进行5秒的业务操作");
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
log("释放对象:lock");
lock.unlock();
}
log("线程结束");
}
};lock和synchronized的区别
- Lock是一个接口,而synchronized是Java中的关键字,synchronized是内置的语言实现,Lock是代码层面的实现。
- Lock可以选择性的获取锁,如果一段时间获取不到,可以放弃。synchronized不行,会一根筋一直获取下去。 借助Lock的这个特性,就能够规避死锁,synchronized必须通过谨慎和良好的设计,才能减少死锁的发生。
- synchronized在发生异常和同步块结束的时候,会自动释放锁。而Lock必须手动释放, 所以如果忘记了释放锁,一样会造成死锁。
原子访问
原子性操作即不可中断的操作,原子性操作本身是线程安全的,如赋值,但i++ i-- 都是非原子性的,它们是由几个原子性操作组成的。
原子类 AtomicInteger
提供的自增自减方法是原子性的,线程安全的。
import java.util.concurrent.atomic.AtomicInteger;
public class TestThread {
public static void main(String[] args) throws InterruptedException {
AtomicInteger atomicI =new AtomicInteger();
int i = atomicI.decrementAndGet();
int j = atomicI.incrementAndGet();
int k = atomicI.addAndGet(3);
}
}
















 1012
1012

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









