






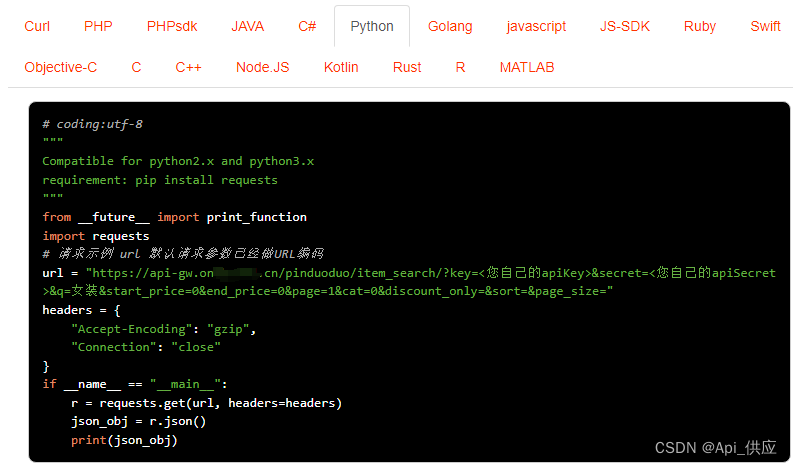
拼多多提供了根据关键词取商品列表的API接口,即item_search API。以下是使用该API的基本步骤:
- 发起API请求:使用拼多多的API密钥,通过HTTP请求向拼多多的API服务器发起请求。您可以使用任何支持HTTP请求的编程语言或工具来完成这一步。
- 设置请求参数:在API请求中,您需要设置关键词以及其他必要的请求参数,如页码、每页数量等。这些参数的具体值可以在拼多多开放平台的官方文档中找到。
- 处理API响应:拼多多的API服务器会对您的请求进行响应,返回包含商品数据的JSON格式数据。您需要编写代码来解析这个JSON数据,提取出所需的商品信息。
- 展示或使用商品数据:将解析出的商品数据展示在前端页面或用于其他业务逻辑。
需要注意的是,拼多多的开放平台API有调用频率限制和权限限制,请务必遵守拼多多开放平台的使用规范和政策。另外,具体的API使用方法和参数设置可能有所不同,建议您查阅拼多多开放平台的官方文档或与拼多多的技术支持团队联系以获取更详细的信息和帮助。
pinduoduo.item_search
| 名称 | 类型 | 必须 | 描述 |
|---|---|---|---|
| key | String | 是 | 调用key(必须以GET方式拼接在URL中) |
| secret | String | 是 | 调用密钥WeChat:18305163218 |
| api_name | String | 是 | API接口名称(包括在请求地址中)[item_search,item_get,item_search_shop等] |
| cache | String | 否 | [yes,no]默认yes,将调用缓存的数据,速度比较快 |
| result_type | String | 否 | [json,jsonu,xml,serialize,var_export]返回数据格式,默认为json,jsonu输出的内容中文可以直接阅读 |
| lang | String | 否 | [cn,en,ru]翻译语言,默认cn简体中文 |
| version | String | 否 | API版本 |
请求参数:q=女装&start_price=0&end_price=0&page=1&cat=0&discount_only=&sort=&page_size=
参数说明:q:关键词, sort:排序[bid,_bid,_sale,sale] (bid:商品价格,sale:销量,加_前缀为从大到小排序)
Version: Date:
| 名称 | 类型 | 必须 | 示例值 | 描述 |
|---|---|---|---|---|
| items | items[] | 0 | 根据关键词取商品列表 | |
| title | String | 0 | 啄木鸟双面穿棉衣女2020冬装加厚宽松韩版棉袄小个子羽绒棉外套冬 | 商品标题 |
| pic_url | String | 0 | https://t00img.yangkeduo.com/goods/images/2020-12-08/1226cd586487b63527d86fdabb8608cc.jpeg | 宝贝图片 |
| price | Float | 0 | 198 | 价格 |
| promotion_price | Float | 0 | 198 | 优惠价格 |
| sales | Int | 0 | 14830 | 销量 |
| num_iid | Bigint | 0 | 203344831134 | 宝贝ID |
| detail_url | String | 0 | http://yangkeduo.com/goods.html?goods_id=203344831134 | 宝贝链接 |

















 1146
1146

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









