




 本文通过kafka manage模拟Kafka集群中节点0宕机,观察故障期间topic的broker分布、ISR变化以及集群写入和消费消息的情况。在恢复节点0后,集群能正常同步数据,重新平均分配leader,并将节点0加入ISR列表,确保数据一致性。
本文通过kafka manage模拟Kafka集群中节点0宕机,观察故障期间topic的broker分布、ISR变化以及集群写入和消费消息的情况。在恢复节点0后,集群能正常同步数据,重新平均分配leader,并将节点0加入ISR列表,确保数据一致性。
这里通过kafka manage来展示节点宕机效果
现在三台主机节点均正常

topic正常识别到三个broker

leader也均匀分配到了三个broker上
现在把节点id为0的主机模拟宕机



可以通过以上两张图片看到每个topic现在只识别到了两个broker节点,broker id为0的节点已经被剔除掉了

isr列表的数据同步节点中也把0节点剔除了,分区也被其它两个broker节点接管了
现在来看一下集群是否还能正常写入消息

可以看到集群正常写入消息没有报错
接下来看一下集群是否能正常消费消息

可以看到集群正常消费了主题中的消息
现在把broker节点0恢复看看是否能正常同步数据,并恢复leader

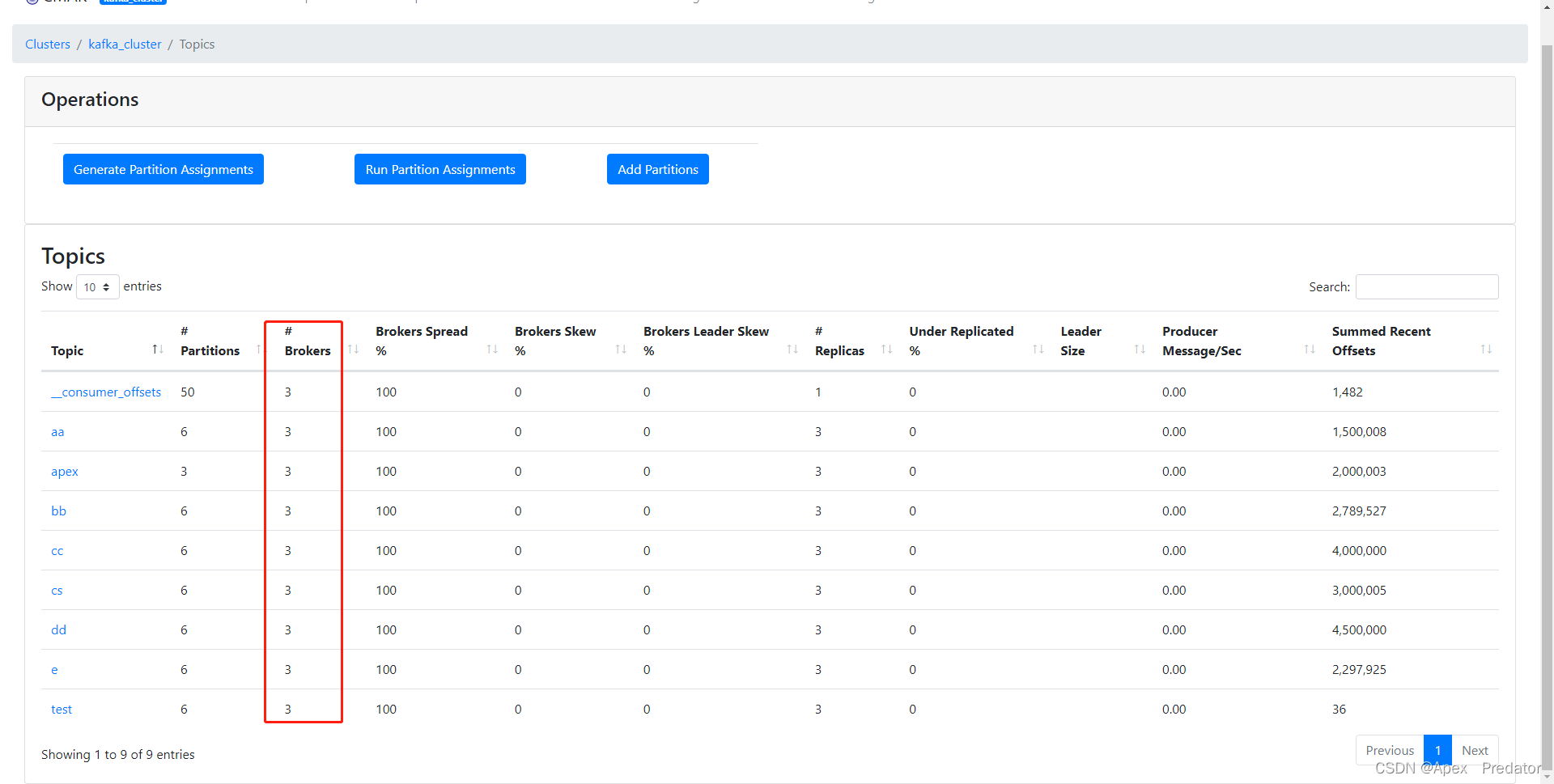
可以看到所有主题重新识别到了三个broker
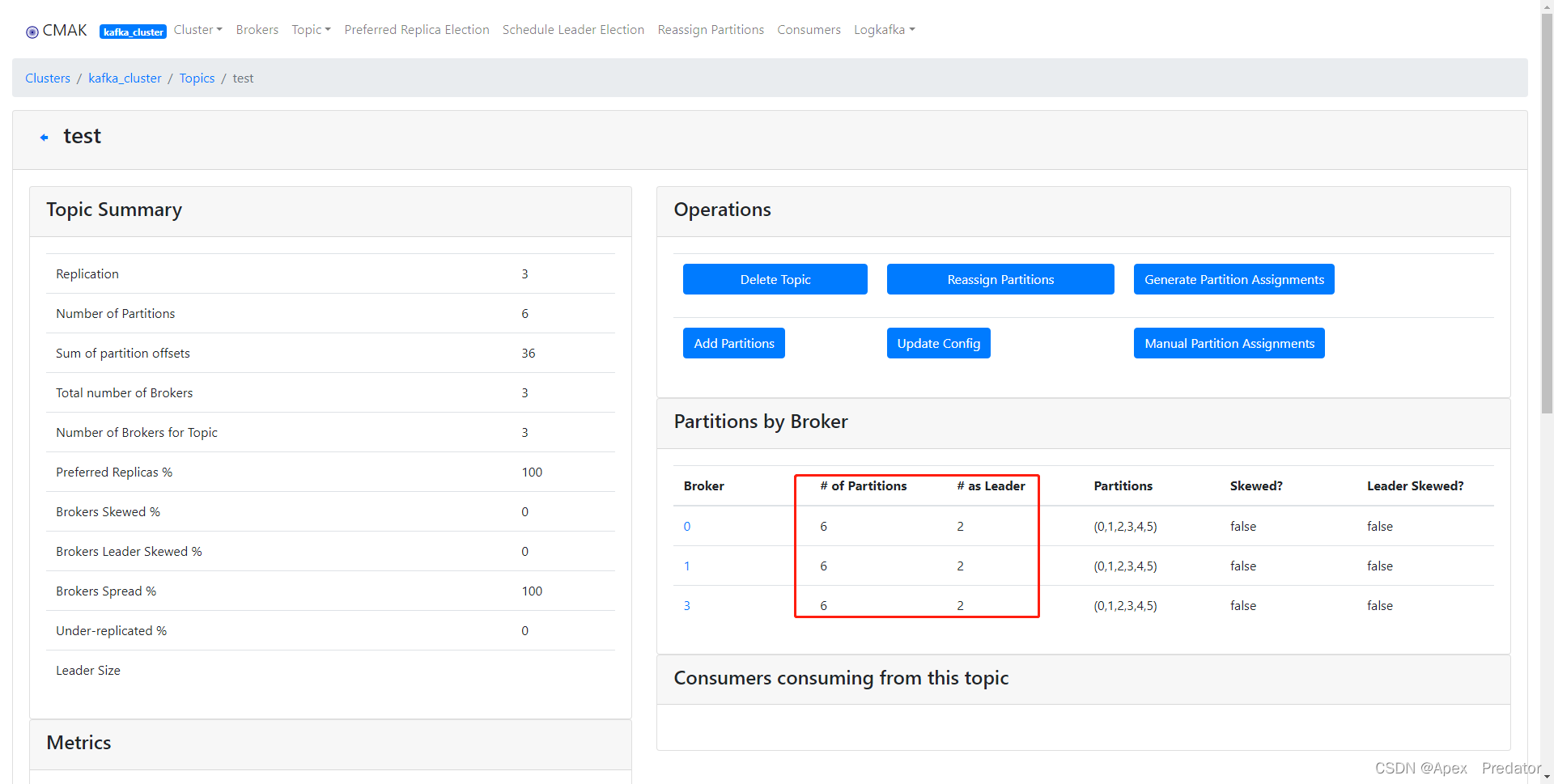
leader也重新平均分配到了所有broker上
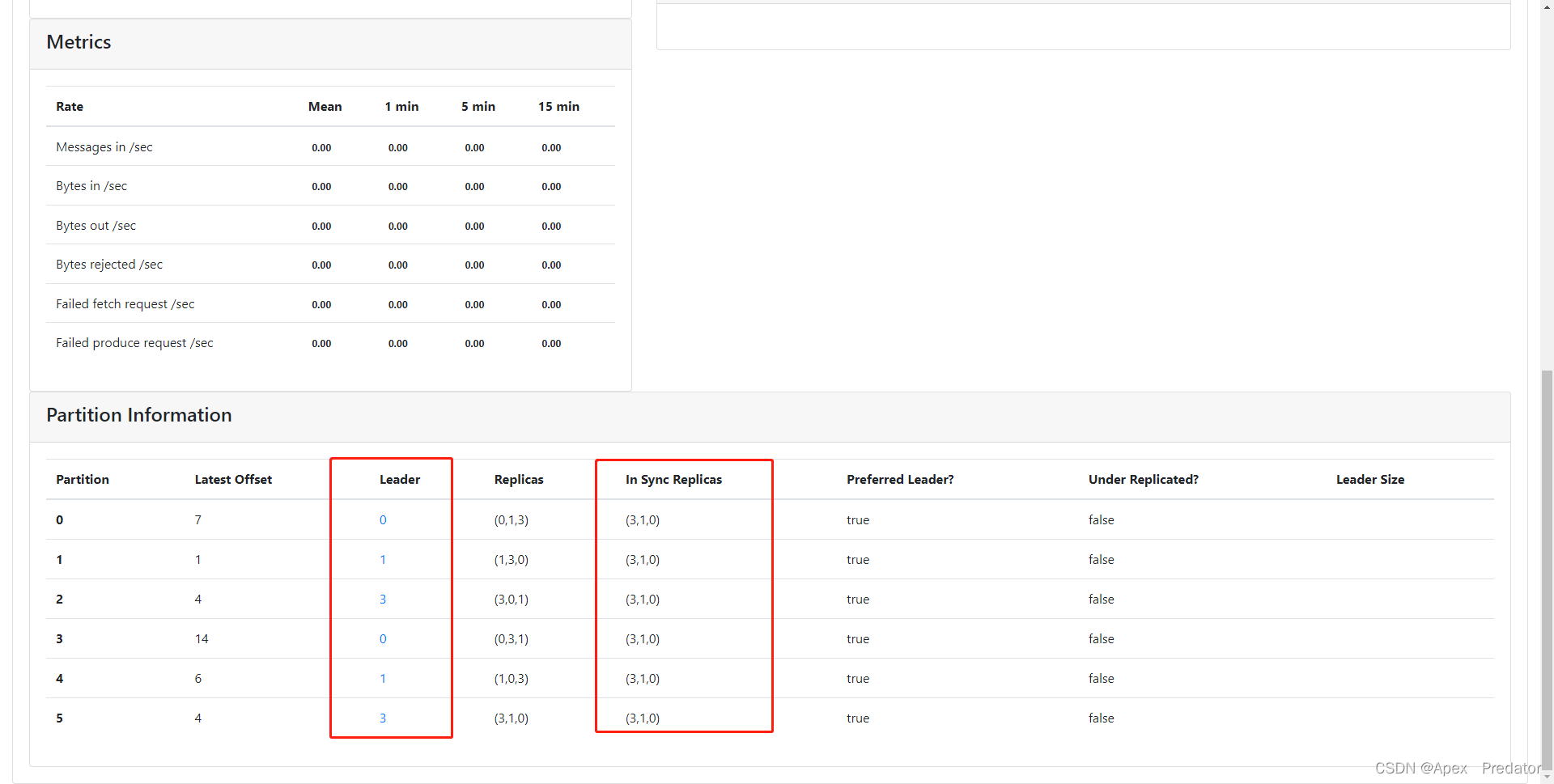
isr列表中也把0节点添加了回来,说明0节点的数据已经与集群数据同步一致了,注意当集群新增数据量比较大时,掉线节点恢复会比较慢 ,因为同步大量的数据比较耗费时间
每个节点的数据是否与集群的一致,就看isr列表就行,只有数据与集群的一致才会添加到isr列表中

















 308
308

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









