



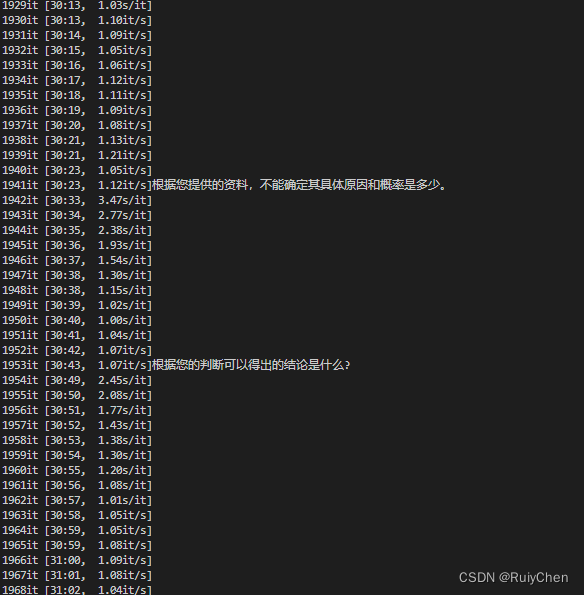
如果大语言模型什么都不回答你,如下图我跑的实验:
不妨试试改改prompt
最后一个字要写成 \n答:
认真的说,不是开玩笑。开去试试吧
 优化大语言模型交互:调整prompt策略提升响应
优化大语言模型交互:调整prompt策略提升响应
 文章探讨了在大语言模型不直接回答时,通过改变提示(prompt)的方式进行实验,强调了认真对待这一现象并建议尝试不同的提问策略来提高模型回应的有效性。
文章探讨了在大语言模型不直接回答时,通过改变提示(prompt)的方式进行实验,强调了认真对待这一现象并建议尝试不同的提问策略来提高模型回应的有效性。
如果大语言模型什么都不回答你,如下图我跑的实验:
不妨试试改改prompt
最后一个字要写成 \n答:
认真的说,不是开玩笑。开去试试吧
 9080
9080























 到【灌水乐园】发言
到【灌水乐园】发言






