



 本文深入探讨了深度神经网络中梯度消失和爆炸问题的成因,特别关注了sigmoid和tanh激活函数的局限,以及Glorot条件如何通过合理的参数初始化来平衡梯度。Xavier方法与Zero-CenteredData在解决这些问题中的核心作用被详细解析。
本文深入探讨了深度神经网络中梯度消失和爆炸问题的成因,特别关注了sigmoid和tanh激活函数的局限,以及Glorot条件如何通过合理的参数初始化来平衡梯度。Xavier方法与Zero-CenteredData在解决这些问题中的核心作用被详细解析。

原文链接:再聊聊梯度消失与梯度爆炸
随着神经网络的层数变多、结构越来越复杂,模型在训练过程中就会遇到梯度消失和梯度爆炸导致模型不能有效收敛。那么你知道该问题是如何解决的吗?
1 梯度消失与梯度爆炸
神经网络在进行反向传播的过程中,各参数层的梯度计算会涉及到激活函数的导函数取值。具体来说,假设现在有一个三层的神经网络,
X
X
X为输入,
w
w
w为神经网络参数,
F
(
x
)
F(x)
F(x)为激活函数
:
y
^
=
F
(
F
(
X
∗
w
1
)
∗
w
2
)
∗
w
3
\hat y = F(F(X * w_1) * w_2) * w_3
y^=F(F(X∗w1)∗w2)∗w3
在对反向传播更新
w
1
w_1
w1时,根据链式法则得:
g
r
a
d
1
=
∂
l
o
s
s
∂
w
1
=
∂
l
o
s
s
∂
y
^
⋅
∂
y
^
∂
w
1
=
∂
l
o
s
s
∂
y
^
⋅
∂
(
F
(
F
(
X
∗
w
1
)
∗
w
2
)
∗
w
3
)
∂
w
1
=
∂
l
o
s
s
∂
y
^
⋅
∂
(
F
(
F
(
X
∗
w
1
)
∗
w
2
)
∗
w
3
)
∂
(
F
(
F
(
X
∗
w
1
)
∗
w
2
)
⋅
∂
F
(
F
(
X
∗
w
1
)
∗
w
2
)
∂
F
(
X
∗
w
1
)
⋅
∂
F
(
X
∗
w
1
)
∂
w
1
=
∂
l
o
s
s
∂
y
^
⋅
w
3
⋅
f
(
F
(
X
∗
w
1
)
∗
w
2
)
⋅
w
2
⋅
f
(
X
∗
w
1
)
⋅
X
\begin{aligned} grad_1 &=\frac{\partial loss}{\partial w_1} \\ &= \frac{\partial loss}{\partial \hat y} \cdot \frac{\partial \hat y}{\partial w_1} \\ &= \frac{\partial loss}{\partial \hat y} \cdot \frac{\partial (F(F(X * w_1) * w_2) * w_3)}{\partial w_1} \\ &= \frac{\partial loss}{\partial \hat y} \cdot \frac{\partial (F(F(X * w_1) * w_2) * w_3)}{\partial (F(F(X * w_1) * w_2)} \cdot \frac{\partial F(F(X * w_1) * w_2)}{\partial F(X * w_1)} \cdot \frac{\partial F(X * w_1)}{\partial w_1}\\ &= \frac{\partial loss}{\partial \hat y} \cdot w_3 \cdot f(F(X * w_1) * w_2) \cdot w_2 \cdot f(X * w_1) \cdot X \\ \end{aligned}
grad1=∂w1∂loss=∂y^∂loss⋅∂w1∂y^=∂y^∂loss⋅∂w1∂(F(F(X∗w1)∗w2)∗w3)=∂y^∂loss⋅∂(F(F(X∗w1)∗w2)∂(F(F(X∗w1)∗w2)∗w3)⋅∂F(X∗w1)∂F(F(X∗w1)∗w2)⋅∂w1∂F(X∗w1)=∂y^∂loss⋅w3⋅f(F(X∗w1)∗w2)⋅w2⋅f(X∗w1)⋅X
第一层参数在计算梯度的过程中需要相乘激活函数的导函数 f ( x ) f(x) f(x),所以当神经网络层数越多时,需要相乘的 f ( x ) f(x) f(x)也越多。
那么当 f ( x ) > 1 f(x) > 1 f(x)>1时,就会出现梯度爆炸的情况;当 f ( x ) 接近 0 f(x)接近0 f(x)接近0时,就会出现梯度消失的情况。
2 sigmoid的梯度更新问题
对于sigmoid激活函数来说,简答的叠加是极容易出现梯度消失的问题。
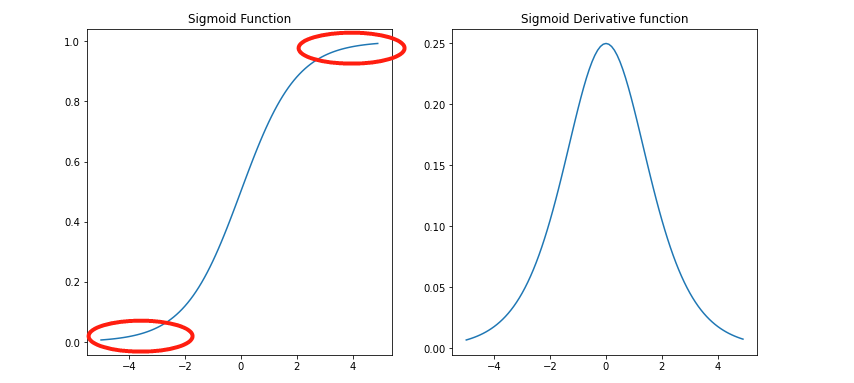
根据上图不难发现:
- sigmoid函数的左右两端的区间为函数的饱和区间
- sigmoid导函数最大值为0.25(在0点处取到),当x较大或者较小时,导函数取值趋于0
3 tanh的梯度更新
首先我们来观察tanh激活函数导函数性质。
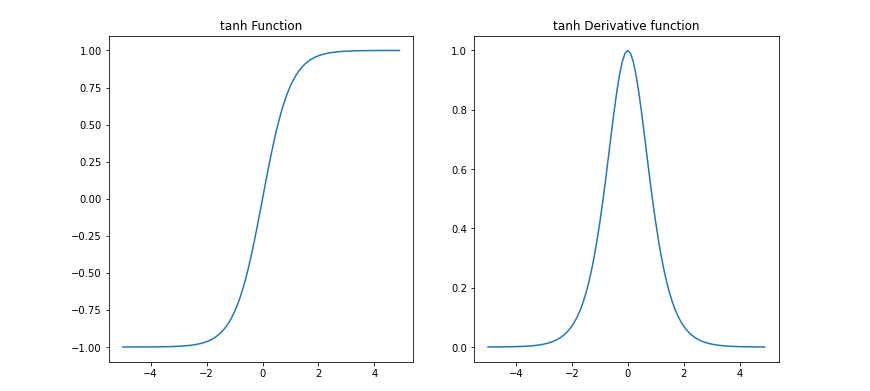
对于tanh函数来说,导函数的取值分布在0-1之间的,一定程度上避免了梯度消失的情况,但当影响前几层梯度的其他变量大于1时,就会造成梯度爆炸。
作为sigmoid激活函数的“升级版”,tanh激活函数除了能够一定程度规避梯度消失问题外,还能够生成Zero-Centered Data零点对称数据,而确保下一层接收到Zero-Centered Data,这种数据分布是解决梯度消失和梯度爆炸问题的关键。
4 Zero-Centered Data与Glorot条件
通过对sigmoid和tanh激活函数叠加后的模型梯度变化情况分析,可以得出对于深层网络,梯度不平稳是影响模型建模效果的核心因素。
针对梯度不平稳的解决方案(优化方法)总共分为五类,分别是:
- 参数初始化方法
- 输入数据的归一化方法
- 衍生激活函数使用方法
- 学习率调度方法
- 梯度下降优化方法
而所有上述优化算法的一个基本理论,是Xavier Glorot在2010年提出的Glorot条件。
5 Zero-centered Data
在介绍Glorot条件之前,我们先讨论关于Zero-Centered Data相关作用,从而帮助我们理解后续Glorot条件。
为了解决梯度消失和梯度爆炸的问题,就需要确保多层神经网络的有效性,即各层梯度不应太大或太小,此时一个最为基本的想法就是,就是让所有的输入数据以及所有层的参数都设置为Zero-Centered Data(零点对称数据)。
由于输入和参数都是零点对称的,因此每一个线性层中的导函数也取值也能更加平稳,进而确保每一层的梯度基本能维持在平稳的状态。
6 Glorot条件
Xavier Glorot条件在2010年发表的论文中提出,为保证模型本身的有效性和稳定性,希望模型正向传播时,每个线性层输入数据的方差等于输出数据的方差,同时我们也希望反向传播时,数据流经某层之前和流经某层之后该层的梯度也具有相同的方差。
虽然二者很难同时满足,但Glorot和Bengio(论文第二作者)表示,如果我们适当修改计算过程、是可以找到一种折中方案去设计初始参数取值,从而同时保证二者条件尽可能得到满足,这种设计参数初始值的方法也被称为Xavier方法。
在Xavier方法中,最核心解决的问题就是在初始化Zero-Centered参数时,参数的方差该取多少。
7 结尾
由于Glorot条件和Xavier方法是在2010年提出的,那时ReLU激活函数还未兴起,因此Xavier方法主要是围绕tanh激活函数可能存在的梯度爆炸或梯度消失进行的优化,sigmoid激活函数效果次之。
不过尽管如此,Glorot条件却是一个通用条件,后续围绕ReLU激活函数、用于解决神经元活性失效的优化方法(如HE初始化方法),也是遵照Glorot条件进行的方法设计。
可以说Glorot条件是所有模型参数初始化的核心指导思想。
原文链接:再聊聊梯度消失与梯度爆炸

















 779
779

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









