




1:运行 ./bin/spark-sql
需要先把hive-site.xml 负责到spark的conf目录下
[jifeng@feng02 spark-1.2.0-bin-2.4.1]$ ./bin/spark-sql
Spark assembly has been built with Hive, including Datanucleus jars on classpath
java.lang.ClassNotFoundException: org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver
at java.net.URLClassLoader$1.run(URLClassLoader.java:366)
at java.net.URLClassLoader$1.run(URLClassLoader.java:355)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:354)
at java.lang.ClassLoader.loadClass(ClassLoader.java:425)
at java.lang.ClassLoader.loadClass(ClassLoader.java:358)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:270)
at org.apache.spark.deploy.SparkSubmit$.launch(SparkSubmit.scala:342)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:75)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Failed to load main class org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.
You need to build Spark with -Phive and -Phive-thriftserver.
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
提示编译的时候要带2个参数
重新编译:./make-distribution.sh --tgz -Phadoop-2.4 -Pyarn -DskipTests -Dhadoop.version=2.4.1 -Phive -Phive-thriftserver
2:再次运行:
[jifeng@feng02 spark-1.2.0-bin-2.4.1]$ ./bin/spark-sql
Spark assembly has been built with Hive, including Datanucleus jars on classpath
log4j:WARN No appenders could be found for logger (org.apache.hadoop.util.Shell).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
Exception in thread "main" java.lang.RuntimeException: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.metastore.HiveMetaStoreClient
at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:346)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver$.main(SparkSQLCLIDriver.scala:101)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.main(SparkSQLCLIDriver.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.spark.deploy.SparkSubmit$.launch(SparkSubmit.scala:358)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:75)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Caused by: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.metastore.HiveMetaStoreClient
at org.apache.hadoop.hive.metastore.MetaStoreUtils.newInstance(MetaStoreUtils.java:1412)
at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.<init>(RetryingMetaStoreClient.java:62)
at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.getProxy(RetryingMetaStoreClient.java:72)
at org.apache.hadoop.hive.ql.metadata.Hive.createMetaStoreClient(Hive.java:2453)
at org.apache.hadoop.hive.ql.metadata.Hive.getMSC(Hive.java:2465)
at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:340)
... 9 more
Caused by: java.lang.reflect.InvocationTargetException
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:526)
at org.apache.hadoop.hive.metastore.MetaStoreUtils.newInstance(MetaStoreUtils.java:1410)
... 14 more
Caused by: javax.jdo.JDOFatalInternalException: Error creating transactional connection factory
NestedThrowables:
java.lang.reflect.InvocationTargetException
at org.datanucleus.api.jdo.NucleusJDOHelper.getJDOExceptionForNucleusException(NucleusJDOHelper.java:587)
at org.datanucleus.api.jdo.JDOPersistenceManagerFactory.freezeConfiguration(JDOPersistenceManagerFactory.java:788)
at org.datanucleus.api.jdo.JDOPersistenceManagerFactory.createPersistenceManagerFactory(JDOPersistenceManagerFactory.java:333)
at org.datanucleus.api.jdo.JDOPersistenceManagerFactory.getPersistenceManagerFactory(JDOPersistenceManagerFactory.java:202)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at javax.jdo.JDOHelper$16.run(JDOHelper.java:1965)
at java.security.AccessController.doPrivileged(Native Method)
at javax.jdo.JDOHelper.invoke(JDOHelper.java:1960)
at javax.jdo.JDOHelper.invokeGetPersistenceManagerFactoryOnImplementation(JDOHelper.java:1166)
at javax.jdo.JDOHelper.getPersistenceManagerFactory(JDOHelper.java:808)
at javax.jdo.JDOHelper.getPersistenceManagerFactory(JDOHelper.java:701)
at org.apache.hadoop.hive.metastore.ObjectStore.getPMF(ObjectStore.java:310)
at org.apache.hadoop.hive.metastore.ObjectStore.getPersistenceManager(ObjectStore.java:339)
at org.apache.hadoop.hive.metastore.ObjectStore.initialize(ObjectStore.java:248)
at org.apache.hadoop.hive.metastore.ObjectStore.setConf(ObjectStore.java:223)
at org.apache.hadoop.util.ReflectionUtils.setConf(ReflectionUtils.java:73)
at org.apache.hadoop.util.ReflectionUtils.newInstance(ReflectionUtils.java:133)
at org.apache.hadoop.hive.metastore.RawStoreProxy.<init>(RawStoreProxy.java:58)
at org.apache.hadoop.hive.metastore.RawStoreProxy.getProxy(RawStoreProxy.java:67)
at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.newRawStore(HiveMetaStore.java:497)
at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.getMS(HiveMetaStore.java:475)
at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.createDefaultDB(HiveMetaStore.java:523)
at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.init(HiveMetaStore.java:397)
at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.<init>(HiveMetaStore.java:356)
at org.apache.hadoop.hive.metastore.RetryingHMSHandler.<init>(RetryingHMSHandler.java:54)
at org.apache.hadoop.hive.metastore.RetryingHMSHandler.getProxy(RetryingHMSHandler.java:59)
at org.apache.hadoop.hive.metastore.HiveMetaStore.newHMSHandler(HiveMetaStore.java:4944)
at org.apache.hadoop.hive.metastore.HiveMetaStoreClient.<init>(HiveMetaStoreClient.java:171)
... 19 more
Caused by: java.lang.reflect.InvocationTargetException
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:526)
at org.datanucleus.plugin.NonManagedPluginRegistry.createExecutableExtension(NonManagedPluginRegistry.java:631)
at org.datanucleus.plugin.PluginManager.createExecutableExtension(PluginManager.java:325)
at org.datanucleus.store.AbstractStoreManager.registerConnectionFactory(AbstractStoreManager.java:282)
at org.datanucleus.store.AbstractStoreManager.<init>(AbstractStoreManager.java:240)
at org.datanucleus.store.rdbms.RDBMSStoreManager.<init>(RDBMSStoreManager.java:286)
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:526)
at org.datanucleus.plugin.NonManagedPluginRegistry.createExecutableExtension(NonManagedPluginRegistry.java:631)
at org.datanucleus.plugin.PluginManager.createExecutableExtension(PluginManager.java:301)
at org.datanucleus.NucleusContext.createStoreManagerForProperties(NucleusContext.java:1187)
at org.datanucleus.NucleusContext.initialise(NucleusContext.java:356)
at org.datanucleus.api.jdo.JDOPersistenceManagerFactory.freezeConfiguration(JDOPersistenceManagerFactory.java:775)
... 48 more
Caused by: org.datanucleus.exceptions.NucleusException: Attempt to invoke the "dbcp-builtin" plugin to create a ConnectionPool gave an error : The specified datastore driver ("com.mysql.jdbc.Driver") was not found in the CLASSPATH. Please check your CLASSPATH specification, and the name of the driver.
at org.datanucleus.store.rdbms.ConnectionFactoryImpl.generateDataSources(ConnectionFactoryImpl.java:259)
at org.datanucleus.store.rdbms.ConnectionFactoryImpl.initialiseDataSources(ConnectionFactoryImpl.java:131)
at org.datanucleus.store.rdbms.ConnectionFactoryImpl.<init>(ConnectionFactoryImpl.java:85)
... 66 more
Caused by: org.datanucleus.store.rdbms.connectionpool.DatastoreDriverNotFoundException: The specified datastore driver ("com.mysql.jdbc.Driver") was not found in the CLASSPATH. Please check your CLASSPATH specification, and the name of the driver.
at org.datanucleus.store.rdbms.connectionpool.AbstractConnectionPoolFactory.loadDriver(AbstractConnectionPoolFactory.java:58)
at org.datanucleus.store.rdbms.connectionpool.DBCPBuiltinConnectionPoolFactory.createConnectionPool(DBCPBuiltinConnectionPoolFactory.java:49)
at org.datanucleus.store.rdbms.ConnectionFactoryImpl.generateDataSources(ConnectionFactoryImpl.java:238)
... 68 more
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
发现找不到mysql的jdbc包
3:加载jdbc运行
[jifeng@feng02 spark-1.2.0-bin-2.4.1]$ ./bin/spark-sql --driver-class-path /home/jifeng/hadoop/spark-1.2.0-bin-2.4.1/lib/mysql-connector-java-5.1.32-bin.jar
Spark assembly has been built with Hive, including Datanucleus jars on classpath
log4j:WARN No appenders could be found for logger (org.apache.hadoop.util.Shell).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
15/03/04 14:30:01 INFO SecurityManager: Changing view acls to: jifeng
15/03/04 14:30:01 INFO SecurityManager: Changing modify acls to: jifeng
15/03/04 14:30:01 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(jifeng); users with modify permissions: Set(jifeng)
15/03/04 14:30:02 INFO Slf4jLogger: Slf4jLogger started
15/03/04 14:30:02 INFO Remoting: Starting remoting
15/03/04 14:30:02 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkDriver@feng02:53897]
15/03/04 14:30:02 INFO Utils: Successfully started service 'sparkDriver' on port 53897.
15/03/04 14:30:02 INFO SparkEnv: Registering MapOutputTracker
15/03/04 14:30:02 INFO SparkEnv: Registering BlockManagerMaster
15/03/04 14:30:02 INFO DiskBlockManager: Created local directory at /tmp/spark-local-20150304143002-0534
15/03/04 14:30:02 INFO MemoryStore: MemoryStore started with capacity 267.3 MB
15/03/04 14:30:02 INFO HttpFileServer: HTTP File server directory is /tmp/spark-5172cadb-24ba-4eaa-b78b-cefb2e0ffb5b
15/03/04 14:30:02 INFO HttpServer: Starting HTTP Server
15/03/04 14:30:02 INFO Utils: Successfully started service 'HTTP file server' on port 55683.
15/03/04 14:30:03 INFO Utils: Successfully started service 'SparkUI' on port 4040.
15/03/04 14:30:03 INFO SparkUI: Started SparkUI at http://feng02:4040
15/03/04 14:30:03 INFO AkkaUtils: Connecting to HeartbeatReceiver: akka.tcp://sparkDriver@feng02:53897/user/HeartbeatReceiver
15/03/04 14:30:03 INFO NettyBlockTransferService: Server created on 39062
15/03/04 14:30:03 INFO BlockManagerMaster: Trying to register BlockManager
15/03/04 14:30:03 INFO BlockManagerMasterActor: Registering block manager localhost:39062 with 267.3 MB RAM, BlockManagerId(<driver>, localhost, 39062)
15/03/04 14:30:03 INFO BlockManagerMaster: Registered BlockManager
SET spark.sql.hive.version=0.13.1
15/03/04 14:30:04 INFO HiveMetaStore: 0: get_all_databases
15/03/04 14:30:04 INFO audit: ugi=jifeng ip=unknown-ip-addr cmd=get_all_databases
15/03/04 14:30:04 INFO HiveMetaStore: 0: get_functions: db=default pat=*
15/03/04 14:30:04 INFO audit: ugi=jifeng ip=unknown-ip-addr cmd=get_functions: db=default pat=*
15/03/04 14:30:04 INFO Datastore: The class "org.apache.hadoop.hive.metastore.model.MResourceUri" is tagged as "embedded-only" so does not have its own datastore table.
spark-sql>
4:操作:
show tables;
spark-sql> show tables;
15/03/04 14:39:23 WARN HiveConf: DEPRECATED: hive.metastore.ds.retry.* no longer has any effect. Use hive.hmshandler.retry.* instead
15/03/04 14:39:23 INFO ParseDriver: Parsing command: show tables
15/03/04 14:39:23 INFO ParseDriver: Parse Completed
15/03/04 14:39:24 INFO PerfLogger: <PERFLOG method=Driver.run from=org.apache.hadoop.hive.ql.Driver>
15/03/04 14:39:24 INFO PerfLogger: <PERFLOG method=TimeToSubmit from=org.apache.hadoop.hive.ql.Driver>
15/03/04 14:39:24 INFO Driver: Concurrency mode is disabled, not creating a lock manager
15/03/04 14:39:24 INFO PerfLogger: <PERFLOG method=compile from=org.apache.hadoop.hive.ql.Driver>
15/03/04 14:39:24 INFO PerfLogger: <PERFLOG method=parse from=org.apache.hadoop.hive.ql.Driver>
15/03/04 14:39:24 INFO ParseDriver: Parsing command: show tables
15/03/04 14:39:24 INFO ParseDriver: Parse Completed
15/03/04 14:39:24 INFO PerfLogger: </PERFLOG method=parse start=1425451164380 end=1425451164381 duration=1 from=org.apache.hadoop.hive.ql.Driver>
15/03/04 14:39:24 INFO PerfLogger: <PERFLOG method=semanticAnalyze from=org.apache.hadoop.hive.ql.Driver>
15/03/04 14:39:24 INFO Driver: Semantic Analysis Completed
15/03/04 14:39:24 INFO PerfLogger: </PERFLOG method=semanticAnalyze start=1425451164381 end=1425451164458 duration=77 from=org.apache.hadoop.hive.ql.Driver>
15/03/04 14:39:24 INFO ListSinkOperator: Initializing Self 0 OP
15/03/04 14:39:24 INFO ListSinkOperator: Operator 0 OP initialized
15/03/04 14:39:24 INFO ListSinkOperator: Initialization Done 0 OP
15/03/04 14:39:24 INFO Driver: Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:tab_name, type:string, comment:from deserializer)], properties:null)
15/03/04 14:39:24 INFO PerfLogger: </PERFLOG method=compile start=1425451164361 end=1425451164622 duration=261 from=org.apache.hadoop.hive.ql.Driver>
15/03/04 14:39:24 INFO PerfLogger: <PERFLOG method=Driver.execute from=org.apache.hadoop.hive.ql.Driver>
15/03/04 14:39:24 INFO Driver: Starting command: show tables
15/03/04 14:39:24 INFO PerfLogger: </PERFLOG method=TimeToSubmit start=1425451164358 end=1425451164625 duration=267 from=org.apache.hadoop.hive.ql.Driver>
15/03/04 14:39:24 INFO PerfLogger: <PERFLOG method=runTasks from=org.apache.hadoop.hive.ql.Driver>
15/03/04 14:39:24 INFO PerfLogger: <PERFLOG method=task.DDL.Stage-0 from=org.apache.hadoop.hive.ql.Driver>
15/03/04 14:39:24 INFO HiveMetaStore: 0: get_database: default
15/03/04 14:39:24 INFO audit: ugi=jifeng ip=unknown-ip-addr cmd=get_database: default
15/03/04 14:39:24 INFO HiveMetaStore: 0: get_tables: db=default pat=.*
15/03/04 14:39:24 INFO audit: ugi=jifeng ip=unknown-ip-addr cmd=get_tables: db=default pat=.*
15/03/04 14:39:24 INFO PerfLogger: </PERFLOG method=runTasks start=1425451164625 end=1425451164660 duration=35 from=org.apache.hadoop.hive.ql.Driver>
15/03/04 14:39:24 INFO PerfLogger: </PERFLOG method=Driver.execute start=1425451164622 end=1425451164660 duration=38 from=org.apache.hadoop.hive.ql.Driver>
OK
15/03/04 14:39:24 INFO Driver: OK
15/03/04 14:39:24 INFO PerfLogger: <PERFLOG method=releaseLocks from=org.apache.hadoop.hive.ql.Driver>
15/03/04 14:39:24 INFO PerfLogger: </PERFLOG method=releaseLocks start=1425451164660 end=1425451164660 duration=0 from=org.apache.hadoop.hive.ql.Driver>
15/03/04 14:39:24 INFO PerfLogger: </PERFLOG method=Driver.run start=1425451164358 end=1425451164660 duration=302 from=org.apache.hadoop.hive.ql.Driver>
15/03/04 14:39:24 INFO deprecation: mapred.input.dir is deprecated. Instead, use mapreduce.input.fileinputformat.inputdir
15/03/04 14:39:24 INFO FileInputFormat: Total input paths to process : 1
15/03/04 14:39:24 INFO ListSinkOperator: 0 finished. closing...
15/03/04 14:39:24 INFO ListSinkOperator: 0 Close done
15/03/04 14:39:24 INFO SparkContext: Starting job: collect at SparkPlan.scala:84
15/03/04 14:39:24 INFO DAGScheduler: Got job 0 (collect at SparkPlan.scala:84) with 1 output partitions (allowLocal=false)
15/03/04 14:39:24 INFO DAGScheduler: Final stage: Stage 0(collect at SparkPlan.scala:84)
15/03/04 14:39:24 INFO DAGScheduler: Parents of final stage: List()
15/03/04 14:39:24 INFO DAGScheduler: Missing parents: List()
15/03/04 14:39:24 INFO DAGScheduler: Submitting Stage 0 (MappedRDD[2] at map at SparkPlan.scala:84), which has no missing parents
15/03/04 14:39:25 INFO MemoryStore: ensureFreeSpace(2560) called with curMem=0, maxMem=280248975
15/03/04 14:39:25 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 2.5 KB, free 267.3 MB)
15/03/04 14:39:25 INFO MemoryStore: ensureFreeSpace(1561) called with curMem=2560, maxMem=280248975
15/03/04 14:39:25 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 1561.0 B, free 267.3 MB)
15/03/04 14:39:25 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on localhost:39062 (size: 1561.0 B, free: 267.3 MB)
15/03/04 14:39:25 INFO BlockManagerMaster: Updated info of block broadcast_0_piece0
15/03/04 14:39:25 INFO SparkContext: Created broadcast 0 from broadcast at DAGScheduler.scala:838
15/03/04 14:39:25 INFO DAGScheduler: Submitting 1 missing tasks from Stage 0 (MappedRDD[2] at map at SparkPlan.scala:84)
15/03/04 14:39:25 INFO TaskSchedulerImpl: Adding task set 0.0 with 1 tasks
15/03/04 14:39:25 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, PROCESS_LOCAL, 1378 bytes)
15/03/04 14:39:25 INFO Executor: Running task 0.0 in stage 0.0 (TID 0)
15/03/04 14:39:25 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 744 bytes result sent to driver
15/03/04 14:39:25 INFO DAGScheduler: Stage 0 (collect at SparkPlan.scala:84) finished in 0.202 s
15/03/04 14:39:25 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 191 ms on localhost (1/1)
15/03/04 14:39:25 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
15/03/04 14:39:25 INFO DAGScheduler: Job 0 finished: collect at SparkPlan.scala:84, took 0.625512 s
15/03/04 14:39:25 INFO StatsReportListener: Finished stage: org.apache.spark.scheduler.StageInfo@a440292
15/03/04 14:39:25 INFO StatsReportListener: task runtime:(count: 1, mean: 191.000000, stdev: 0.000000, max: 191.000000, min: 191.000000)
course
hbase_table_1
pokes
student
Time taken: 2.535 seconds
15/03/04 14:39:25 INFO CliDriver: Time taken: 2.535 seconds
15/03/04 14:39:25 INFO PerfLogger: <PERFLOG method=releaseLocks from=org.apache.hadoop.hive.ql.Driver>
15/03/04 14:39:25 INFO PerfLogger: </PERFLOG method=releaseLocks start=1425451165520 end=1425451165520 duration=0 from=org.apache.hadoop.hive.ql.Driver>
spark-sql> 15/03/04 14:39:25 INFO StatsReportListener: 0% 5% 10% 25% 50% 75% 90% 95% 100%
15/03/04 14:39:25 INFO StatsReportListener: 191.0 ms 191.0 ms 191.0 ms 191.0 ms 191.0 ms191.0 ms 191.0 ms 191.0 ms 191.0 ms
15/03/04 14:39:25 INFO StatsReportListener: task result size:(count: 1, mean: 744.000000, stdev: 0.000000, max: 744.000000, min: 744.000000)
15/03/04 14:39:25 INFO StatsReportListener: 0% 5% 10% 25% 50% 75% 90% 95% 100%
15/03/04 14:39:25 INFO StatsReportListener: 744.0 B 744.0 B 744.0 B 744.0 B 744.0 B 744.0 B 744.0 B 744.0 B 744.0 B
15/03/04 14:39:25 INFO StatsReportListener: executor (non-fetch) time pct: (count: 1, mean: 8.900524, stdev: 0.000000, max: 8.900524, min: 8.900524)
15/03/04 14:39:25 INFO StatsReportListener: 0% 5% 10% 25% 50% 75% 90% 95% 100%
15/03/04 14:39:25 INFO StatsReportListener: 9 % 9 % 9 % 9 % 9 % 9 % 9 % 9 % 9 %
15/03/04 14:39:25 INFO StatsReportListener: other time pct: (count: 1, mean: 91.099476, stdev: 0.000000, max: 91.099476, min: 91.099476)
15/03/04 14:39:25 INFO StatsReportListener: 0% 5% 10% 25% 50% 75% 90% 95% 100%
15/03/04 14:39:25 INFO StatsReportListener: 91 % 91 % 91 % 91 % 91 % 91 % 91 % 91 % 91 %
select * from student;
> select * from student;
15/03/04 14:42:05 WARN HiveConf: DEPRECATED: hive.metastore.ds.retry.* no longer has any effect. Use hive.hmshandler.retry.* instead
15/03/04 14:42:05 INFO ParseDriver: Parsing command: select * from student
15/03/04 14:42:05 INFO ParseDriver: Parse Completed
15/03/04 14:42:05 INFO HiveMetaStore: 0: get_table : db=default tbl=student
15/03/04 14:42:05 INFO audit: ugi=jifeng ip=unknown-ip-addr cmd=get_table : db=default tbl=student
15/03/04 14:42:05 INFO deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
15/03/04 14:42:05 INFO MemoryStore: ensureFreeSpace(444571) called with curMem=4121, maxMem=280248975
15/03/04 14:42:05 INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 434.2 KB, free 266.8 MB)
15/03/04 14:42:05 INFO MemoryStore: ensureFreeSpace(47070) called with curMem=448692, maxMem=280248975
15/03/04 14:42:05 INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 46.0 KB, free 266.8 MB)
15/03/04 14:42:05 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on localhost:39062 (size: 46.0 KB, free: 267.2 MB)
15/03/04 14:42:05 INFO BlockManagerMaster: Updated info of block broadcast_1_piece0
15/03/04 14:42:05 INFO SparkContext: Created broadcast 1 from broadcast at TableReader.scala:68
15/03/04 14:42:06 INFO BlockManager: Removing broadcast 0
15/03/04 14:42:06 INFO BlockManager: Removing block broadcast_0
15/03/04 14:42:06 INFO MemoryStore: Block broadcast_0 of size 2560 dropped from memory (free 279755773)
15/03/04 14:42:06 INFO BlockManager: Removing block broadcast_0_piece0
15/03/04 14:42:06 INFO MemoryStore: Block broadcast_0_piece0 of size 1561 dropped from memory (free 279757334)
15/03/04 14:42:06 INFO BlockManagerInfo: Removed broadcast_0_piece0 on localhost:39062 in memory (size: 1561.0 B, free: 267.2 MB)
15/03/04 14:42:06 INFO BlockManagerMaster: Updated info of block broadcast_0_piece0
15/03/04 14:42:06 INFO ContextCleaner: Cleaned broadcast 0
15/03/04 14:42:06 INFO FileInputFormat: Total input paths to process : 1
15/03/04 14:42:06 INFO SparkContext: Starting job: collect at SparkPlan.scala:84
15/03/04 14:42:06 INFO DAGScheduler: Got job 1 (collect at SparkPlan.scala:84) with 2 output partitions (allowLocal=false)
15/03/04 14:42:06 INFO DAGScheduler: Final stage: Stage 1(collect at SparkPlan.scala:84)
15/03/04 14:42:06 INFO DAGScheduler: Parents of final stage: List()
15/03/04 14:42:06 INFO DAGScheduler: Missing parents: List()
15/03/04 14:42:06 INFO DAGScheduler: Submitting Stage 1 (MappedRDD[7] at map at SparkPlan.scala:84), which has no missing parents
15/03/04 14:42:06 INFO MemoryStore: ensureFreeSpace(8616) called with curMem=491641, maxMem=280248975
15/03/04 14:42:06 INFO MemoryStore: Block broadcast_2 stored as values in memory (estimated size 8.4 KB, free 266.8 MB)
15/03/04 14:42:06 INFO MemoryStore: ensureFreeSpace(5184) called with curMem=500257, maxMem=280248975
15/03/04 14:42:06 INFO MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 5.1 KB, free 266.8 MB)
15/03/04 14:42:06 INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on localhost:39062 (size: 5.1 KB, free: 267.2 MB)
15/03/04 14:42:06 INFO BlockManagerMaster: Updated info of block broadcast_2_piece0
15/03/04 14:42:06 INFO SparkContext: Created broadcast 2 from broadcast at DAGScheduler.scala:838
15/03/04 14:42:06 INFO DAGScheduler: Submitting 2 missing tasks from Stage 1 (MappedRDD[7] at map at SparkPlan.scala:84)
15/03/04 14:42:06 INFO TaskSchedulerImpl: Adding task set 1.0 with 2 tasks
15/03/04 14:42:06 INFO TaskSetManager: Starting task 0.0 in stage 1.0 (TID 1, localhost, ANY, 1318 bytes)
15/03/04 14:42:06 INFO Executor: Running task 0.0 in stage 1.0 (TID 1)
15/03/04 14:42:06 INFO HadoopRDD: Input split: hdfs://feng01:9000/user/hive/warehouse/student/stu.txt:0+28
15/03/04 14:42:06 INFO deprecation: mapred.tip.id is deprecated. Instead, use mapreduce.task.id
15/03/04 14:42:06 INFO deprecation: mapred.task.id is deprecated. Instead, use mapreduce.task.attempt.id
15/03/04 14:42:06 INFO deprecation: mapred.task.is.map is deprecated. Instead, use mapreduce.task.ismap
15/03/04 14:42:06 INFO deprecation: mapred.task.partition is deprecated. Instead, use mapreduce.task.partition
15/03/04 14:42:06 INFO deprecation: mapred.job.id is deprecated. Instead, use mapreduce.job.id
15/03/04 14:42:06 INFO Executor: Finished task 0.0 in stage 1.0 (TID 1). 1843 bytes result sent to driver
15/03/04 14:42:06 INFO TaskSetManager: Starting task 1.0 in stage 1.0 (TID 2, localhost, ANY, 1318 bytes)
15/03/04 14:42:06 INFO Executor: Running task 1.0 in stage 1.0 (TID 2)
15/03/04 14:42:06 INFO HadoopRDD: Input split: hdfs://feng01:9000/user/hive/warehouse/student/stu.txt:28+29
15/03/04 14:42:06 INFO TaskSetManager: Finished task 0.0 in stage 1.0 (TID 1) in 267 ms on localhost (1/2)
15/03/04 14:42:06 INFO Executor: Finished task 1.0 in stage 1.0 (TID 2). 1828 bytes result sent to driver
15/03/04 14:42:06 INFO DAGScheduler: Stage 1 (collect at SparkPlan.scala:84) finished in 0.313 s
15/03/04 14:42:06 INFO StatsReportListener: Finished stage: org.apache.spark.scheduler.StageInfo@61f0612d
15/03/04 14:42:06 INFO DAGScheduler: Job 1 finished: collect at SparkPlan.scala:84, took 0.338182 s
15/03/04 14:42:06 INFO StatsReportListener: task runtime:(count: 2, mean: 165.000000, stdev: 102.000000, max: 267.000000, min: 63.000000)
15/03/04 14:42:06 INFO StatsReportListener: 0% 5% 10% 25% 50% 75% 90% 95% 100%
15/03/04 14:42:06 INFO StatsReportListener: 63.0 ms 63.0 ms 63.0 ms 63.0 ms 267.0 ms 267.0 ms 267.0 ms267.0 ms 267.0 ms
1 nick 24
2 doping 25
3 caizhi 26
4 liaozhi 27
5 wind 30
Time taken: 1.442 seconds
15/03/04 14:42:06 INFO CliDriver: Time taken: 1.442 seconds
spark-sql> 15/03/04 14:42:06 INFO StatsReportListener: task result size:(count: 2, mean: 1835.500000, stdev: 7.500000, max: 1843.000000, min: 1828.000000)
15/03/04 14:42:06 INFO StatsReportListener: 0% 5% 10% 25% 50% 75% 90% 95% 100%
15/03/04 14:42:06 INFO StatsReportListener: 1828.0 B 1828.0 B 1828.0 B 1828.0 B 1843.0 B1843.0 B 1843.0 B 1843.0 B 1843.0 B
15/03/04 14:42:06 INFO TaskSetManager: Finished task 1.0 in stage 1.0 (TID 2) in 63 ms on localhost (2/2)
15/03/04 14:42:06 INFO TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool
15/03/04 14:42:06 INFO StatsReportListener: executor (non-fetch) time pct: (count: 2, mean: 73.640093, stdev: 5.386124, max: 79.026217, min: 68.253968)
15/03/04 14:42:06 INFO StatsReportListener: 0% 5% 10% 25% 50% 75% 90% 95% 100%
15/03/04 14:42:06 INFO StatsReportListener: 68 % 68 % 68 % 68 % 79 % 79 % 79 % 79 % 79 %
15/03/04 14:42:06 INFO StatsReportListener: other time pct: (count: 2, mean: 26.359907, stdev: 5.386124, max: 31.746032, min: 20.973783)
15/03/04 14:42:06 INFO StatsReportListener: 0% 5% 10% 25% 50% 75% 90% 95% 100%
15/03/04 14:42:06 INFO StatsReportListener: 21 % 21 % 21 % 21 % 32 % 32 % 32 % 32 % 32 %
JOIN操作
select a.*,b.* from student a join course b where a.id=b.id ;
select a.*,b.* from student a join course b where a.id=b.id ;
15/03/04 14:45:18 WARN HiveConf: DEPRECATED: hive.metastore.ds.retry.* no longer has any effect. Use hive.hmshandler.retry.* instead
15/03/04 14:45:18 INFO ParseDriver: Parsing command: select a.*,b.* from student a join course b where a.id=b.id
15/03/04 14:45:18 INFO ParseDriver: Parse Completed
15/03/04 14:45:18 INFO HiveMetaStore: 0: get_table : db=default tbl=student
15/03/04 14:45:18 INFO audit: ugi=jifeng ip=unknown-ip-addr cmd=get_table : db=default tbl=student
15/03/04 14:45:18 INFO HiveMetaStore: 0: get_table : db=default tbl=course
15/03/04 14:45:18 INFO audit: ugi=jifeng ip=unknown-ip-addr cmd=get_table : db=default tbl=course
15/03/04 14:45:19 INFO MemoryStore: ensureFreeSpace(444571) called with curMem=1014900, maxMem=280248975
15/03/04 14:45:19 INFO MemoryStore: Block broadcast_8 stored as values in memory (estimated size 434.2 KB, free 265.9 MB)
15/03/04 14:45:19 INFO MemoryStore: ensureFreeSpace(47070) called with curMem=1459471, maxMem=280248975
15/03/04 14:45:19 INFO MemoryStore: Block broadcast_8_piece0 stored as bytes in memory (estimated size 46.0 KB, free 265.8 MB)
15/03/04 14:45:19 INFO BlockManagerInfo: Added broadcast_8_piece0 in memory on localhost:39062 (size: 46.0 KB, free: 267.1 MB)
15/03/04 14:45:19 INFO BlockManagerMaster: Updated info of block broadcast_8_piece0
15/03/04 14:45:19 INFO SparkContext: Created broadcast 8 from broadcast at TableReader.scala:68
15/03/04 14:45:19 INFO MemoryStore: ensureFreeSpace(444627) called with curMem=1506541, maxMem=280248975
15/03/04 14:45:19 INFO MemoryStore: Block broadcast_9 stored as values in memory (estimated size 434.2 KB, free 265.4 MB)
15/03/04 14:45:19 INFO MemoryStore: ensureFreeSpace(47091) called with curMem=1951168, maxMem=280248975
15/03/04 14:45:19 INFO MemoryStore: Block broadcast_9_piece0 stored as bytes in memory (estimated size 46.0 KB, free 265.4 MB)
15/03/04 14:45:19 INFO BlockManagerInfo: Added broadcast_9_piece0 in memory on localhost:39062 (size: 46.0 KB, free: 267.1 MB)
15/03/04 14:45:19 INFO BlockManagerMaster: Updated info of block broadcast_9_piece0
15/03/04 14:45:19 INFO SparkContext: Created broadcast 9 from broadcast at TableReader.scala:68
15/03/04 14:45:19 INFO FileInputFormat: Total input paths to process : 1
15/03/04 14:45:19 INFO SparkContext: Starting job: collect at BroadcastHashJoin.scala:53
15/03/04 14:45:19 INFO DAGScheduler: Got job 4 (collect at BroadcastHashJoin.scala:53) with 2 output partitions (allowLocal=false)
15/03/04 14:45:19 INFO DAGScheduler: Final stage: Stage 4(collect at BroadcastHashJoin.scala:53)
15/03/04 14:45:19 INFO DAGScheduler: Parents of final stage: List()
15/03/04 14:45:19 INFO DAGScheduler: Missing parents: List()
15/03/04 14:45:19 INFO DAGScheduler: Submitting Stage 4 (MappedRDD[23] at map at BroadcastHashJoin.scala:53), which has no missing parents
15/03/04 14:45:19 INFO MemoryStore: ensureFreeSpace(6552) called with curMem=1998259, maxMem=280248975
15/03/04 14:45:19 INFO MemoryStore: Block broadcast_10 stored as values in memory (estimated size 6.4 KB, free 265.4 MB)
15/03/04 14:45:19 INFO MemoryStore: ensureFreeSpace(3857) called with curMem=2004811, maxMem=280248975
15/03/04 14:45:19 INFO MemoryStore: Block broadcast_10_piece0 stored as bytes in memory (estimated size 3.8 KB, free 265.4 MB)
15/03/04 14:45:19 INFO BlockManagerInfo: Added broadcast_10_piece0 in memory on localhost:39062 (size: 3.8 KB, free: 267.1 MB)
15/03/04 14:45:19 INFO BlockManagerMaster: Updated info of block broadcast_10_piece0
15/03/04 14:45:19 INFO SparkContext: Created broadcast 10 from broadcast at DAGScheduler.scala:838
15/03/04 14:45:19 INFO DAGScheduler: Submitting 2 missing tasks from Stage 4 (MappedRDD[23] at map at BroadcastHashJoin.scala:53)
15/03/04 14:45:19 INFO TaskSchedulerImpl: Adding task set 4.0 with 2 tasks
15/03/04 14:45:19 INFO TaskSetManager: Starting task 0.0 in stage 4.0 (TID 7, localhost, ANY, 1320 bytes)
15/03/04 14:45:19 INFO Executor: Running task 0.0 in stage 4.0 (TID 7)
15/03/04 14:45:19 INFO HadoopRDD: Input split: hdfs://feng01:9000/user/hive/warehouse/course/course.txt:0+60
15/03/04 14:45:19 WARN LazyStruct: Extra bytes detected at the end of the row! Ignoring similar problems.
15/03/04 14:45:19 INFO Executor: Finished task 0.0 in stage 4.0 (TID 7). 2091 bytes result sent to driver
15/03/04 14:45:19 INFO TaskSetManager: Starting task 1.0 in stage 4.0 (TID 8, localhost, ANY, 1320 bytes)
15/03/04 14:45:19 INFO Executor: Running task 1.0 in stage 4.0 (TID 8)
15/03/04 14:45:19 INFO HadoopRDD: Input split: hdfs://feng01:9000/user/hive/warehouse/course/course.txt:60+61
15/03/04 14:45:19 INFO TaskSetManager: Finished task 0.0 in stage 4.0 (TID 7) in 26 ms on localhost (1/2)
15/03/04 14:45:19 INFO Executor: Finished task 1.0 in stage 4.0 (TID 8). 2044 bytes result sent to driver
15/03/04 14:45:19 INFO DAGScheduler: Stage 4 (collect at BroadcastHashJoin.scala:53) finished in 0.042 s
15/03/04 14:45:19 INFO StatsReportListener: Finished stage: org.apache.spark.scheduler.StageInfo@40fa4929
15/03/04 14:45:19 INFO StatsReportListener: task runtime:(count: 2, mean: 25.500000, stdev: 0.500000, max: 26.000000, min: 25.000000)
15/03/04 14:45:19 INFO StatsReportListener: 0% 5% 10% 25% 50% 75% 90% 95% 100%
15/03/04 14:45:19 INFO StatsReportListener: 25.0 ms 25.0 ms 25.0 ms 25.0 ms 26.0 ms 26.0 ms 26.0 ms 26.0 ms 26.0 ms
15/03/04 14:45:19 INFO DAGScheduler: Job 4 finished: collect at BroadcastHashJoin.scala:53, took 0.075328 s
15/03/04 14:45:19 INFO MemoryStore: ensureFreeSpace(2264) called with curMem=2008668, maxMem=280248975
15/03/04 14:45:19 INFO MemoryStore: Block broadcast_11 stored as values in memory (estimated size 2.2 KB, free 265.3 MB)
15/03/04 14:45:19 INFO StatsReportListener: task result size:(count: 2, mean: 2067.500000, stdev: 23.500000, max: 2091.000000, min: 2044.000000)
15/03/04 14:45:19 INFO StatsReportListener: 0% 5% 10% 25% 50% 75% 90% 95% 100%
15/03/04 14:45:19 INFO StatsReportListener: 2044.0 B 2044.0 B 2044.0 B 2044.0 B 2.0 KB 2.0 KB 2.0 KB 2.0 KB 2.0 KB
15/03/04 14:45:19 INFO TaskSetManager: Finished task 1.0 in stage 4.0 (TID 8) in 25 ms on localhost (2/2)
15/03/04 14:45:19 INFO TaskSchedulerImpl: Removed TaskSet 4.0, whose tasks have all completed, from pool
15/03/04 14:45:19 INFO StatsReportListener: executor (non-fetch) time pct: (count: 2, mean: 51.153846, stdev: 8.846154, max: 60.000000, min: 42.307692)
15/03/04 14:45:19 INFO StatsReportListener: 0% 5% 10% 25% 50% 75% 90% 95% 100%
15/03/04 14:45:19 INFO StatsReportListener: 42 % 42 % 42 % 42 % 60 % 60 % 60 % 60 % 60 %
15/03/04 14:45:19 INFO StatsReportListener: other time pct: (count: 2, mean: 48.846154, stdev: 8.846154, max: 57.692308, min: 40.000000)
15/03/04 14:45:19 INFO StatsReportListener: 0% 5% 10% 25% 50% 75% 90% 95% 100%
15/03/04 14:45:19 INFO StatsReportListener: 40 % 40 % 40 % 40 % 58 % 58 % 58 % 58 % 58 %
15/03/04 14:45:19 INFO MemoryStore: ensureFreeSpace(350) called with curMem=2010932, maxMem=280248975
15/03/04 14:45:19 INFO MemoryStore: Block broadcast_11_piece0 stored as bytes in memory (estimated size 350.0 B, free 265.3 MB)
15/03/04 14:45:19 INFO BlockManagerInfo: Added broadcast_11_piece0 in memory on localhost:39062 (size: 350.0 B, free: 267.1 MB)
15/03/04 14:45:19 INFO BlockManagerMaster: Updated info of block broadcast_11_piece0
15/03/04 14:45:19 INFO SparkContext: Created broadcast 11 from broadcast at BroadcastHashJoin.scala:55
15/03/04 14:45:19 INFO FileInputFormat: Total input paths to process : 1
15/03/04 14:45:19 INFO SparkContext: Starting job: collect at SparkPlan.scala:84
15/03/04 14:45:19 INFO DAGScheduler: Got job 5 (collect at SparkPlan.scala:84) with 2 output partitions (allowLocal=false)
15/03/04 14:45:19 INFO DAGScheduler: Final stage: Stage 5(collect at SparkPlan.scala:84)
15/03/04 14:45:19 INFO DAGScheduler: Parents of final stage: List()
15/03/04 14:45:19 INFO DAGScheduler: Missing parents: List()
15/03/04 14:45:19 INFO DAGScheduler: Submitting Stage 5 (MappedRDD[29] at map at SparkPlan.scala:84), which has no missing parents
15/03/04 14:45:19 INFO MemoryStore: ensureFreeSpace(11896) called with curMem=2011282, maxMem=280248975
15/03/04 14:45:19 INFO MemoryStore: Block broadcast_12 stored as values in memory (estimated size 11.6 KB, free 265.3 MB)
15/03/04 14:45:19 INFO MemoryStore: ensureFreeSpace(6623) called with curMem=2023178, maxMem=280248975
15/03/04 14:45:19 INFO MemoryStore: Block broadcast_12_piece0 stored as bytes in memory (estimated size 6.5 KB, free 265.3 MB)
15/03/04 14:45:19 INFO BlockManagerInfo: Added broadcast_12_piece0 in memory on localhost:39062 (size: 6.5 KB, free: 267.1 MB)
15/03/04 14:45:19 INFO BlockManagerMaster: Updated info of block broadcast_12_piece0
15/03/04 14:45:19 INFO SparkContext: Created broadcast 12 from broadcast at DAGScheduler.scala:838
15/03/04 14:45:19 INFO DAGScheduler: Submitting 2 missing tasks from Stage 5 (MappedRDD[29] at map at SparkPlan.scala:84)
15/03/04 14:45:19 INFO TaskSchedulerImpl: Adding task set 5.0 with 2 tasks
15/03/04 14:45:19 INFO TaskSetManager: Starting task 0.0 in stage 5.0 (TID 9, localhost, ANY, 1318 bytes)
15/03/04 14:45:19 INFO Executor: Running task 0.0 in stage 5.0 (TID 9)
15/03/04 14:45:19 INFO HadoopRDD: Input split: hdfs://feng01:9000/user/hive/warehouse/student/stu.txt:0+28
15/03/04 14:45:19 INFO Executor: Finished task 0.0 in stage 5.0 (TID 9). 1930 bytes result sent to driver
15/03/04 14:45:19 INFO TaskSetManager: Starting task 1.0 in stage 5.0 (TID 10, localhost, ANY, 1318 bytes)
15/03/04 14:45:19 INFO Executor: Running task 1.0 in stage 5.0 (TID 10)
15/03/04 14:45:19 INFO TaskSetManager: Finished task 0.0 in stage 5.0 (TID 9) in 27 ms on localhost (1/2)
15/03/04 14:45:19 INFO HadoopRDD: Input split: hdfs://feng01:9000/user/hive/warehouse/student/stu.txt:28+29
15/03/04 14:45:19 INFO Executor: Finished task 1.0 in stage 5.0 (TID 10). 1884 bytes result sent to driver
15/03/04 14:45:19 INFO DAGScheduler: Stage 5 (collect at SparkPlan.scala:84) finished in 0.066 s
15/03/04 14:45:19 INFO StatsReportListener: Finished stage: org.apache.spark.scheduler.StageInfo@4942722a
15/03/04 14:45:19 INFO DAGScheduler: Job 5 finished: collect at SparkPlan.scala:84, took 0.094749 s
1 nick 24 1 英语 中文 法文 日文
2 doping 25 2 中文 法文
3 caizhi 26 3 中文 法文 日文
4 liaozhi 27 4 中文 法文 拉丁
5 wind 30 5 中文 法文 德文
Time taken: 0.612 seconds
15/03/04 14:45:19 INFO CliDriver: Time taken: 0.612 seconds
spark-sql> 15/03/04 14:45:19 INFO StatsReportListener: task runtime:(count: 2, mean: 34.000000, stdev: 7.000000, max: 41.000000, min: 27.000000)
15/03/04 14:45:19 INFO StatsReportListener: 0% 5% 10% 25% 50% 75% 90% 95% 100%
15/03/04 14:45:19 INFO StatsReportListener: 27.0 ms 27.0 ms 27.0 ms 27.0 ms 41.0 ms 41.0 ms 41.0 ms 41.0 ms 41.0 ms
15/03/04 14:45:19 INFO StatsReportListener: task result size:(count: 2, mean: 1907.000000, stdev: 23.000000, max: 1930.000000, min: 1884.000000)
15/03/04 14:45:19 INFO StatsReportListener: 0% 5% 10% 25% 50% 75% 90% 95% 100%
15/03/04 14:45:19 INFO StatsReportListener: 1884.0 B 1884.0 B 1884.0 B 1884.0 B 1930.0 B1930.0 B 1930.0 B 1930.0 B 1930.0 B
15/03/04 14:45:19 INFO StatsReportListener: executor (non-fetch) time pct: (count: 2, mean: 71.725384, stdev: 8.762421, max: 80.487805, min: 62.962963)
15/03/04 14:45:19 INFO TaskSetManager: Finished task 1.0 in stage 5.0 (TID 10) in 41 ms on localhost (2/2)
15/03/04 14:45:19 INFO TaskSchedulerImpl: Removed TaskSet 5.0, whose tasks have all completed, from pool
15/03/04 14:45:19 INFO StatsReportListener: 0% 5% 10% 25% 50% 75% 90% 95% 100%
15/03/04 14:45:19 INFO StatsReportListener: 63 % 63 % 63 % 63 % 80 % 80 % 80 % 80 % 80 %
15/03/04 14:45:19 INFO StatsReportListener: other time pct: (count: 2, mean: 28.274616, stdev: 8.762421, max: 37.037037, min: 19.512195)
15/03/04 14:45:19 INFO StatsReportListener: 0% 5% 10% 25% 50% 75% 90% 95% 100%
15/03/04 14:45:19 INFO StatsReportListener: 20 % 20 % 20 % 20 % 37 % 37 % 37 % 37 % 37 %
5:集群运行
是CLI启动一个SparkSQL应用程序的参数,如果不设置--master的话,将在启动spark-sql的机器以local方式运行,只能通过http://机器名:4040进行监控
./bin/spark-sql --master spark://feng02:7077 --driver-class-path /home/jifeng/hadoop/spark-1.2.0-bin-2.4.1/lib/mysql-connector-java-5.1.32-bin.jar
[jifeng@feng02 spark-1.2.0-bin-2.4.1]$ ./bin/spark-sql --master spark://feng02:7077 --driver-class-path /home/jifeng/hadoop/spark-1.2.0-bin-2.4.1/lib/mysql-connector-java-5.1.32-bin.jar
Spark assembly has been built with Hive, including Datanucleus jars on classpath
log4j:WARN No appenders could be found for logger (org.apache.hadoop.util.Shell).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
15/03/04 15:36:50 INFO SecurityManager: Changing view acls to: jifeng
15/03/04 15:36:50 INFO SecurityManager: Changing modify acls to: jifeng
15/03/04 15:36:50 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(jifeng); users with modify permissions: Set(jifeng)
15/03/04 15:36:50 INFO Slf4jLogger: Slf4jLogger started
15/03/04 15:36:50 INFO Remoting: Starting remoting
15/03/04 15:36:51 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkDriver@feng02:51996]
15/03/04 15:36:51 INFO Utils: Successfully started service 'sparkDriver' on port 51996.
15/03/04 15:36:51 INFO SparkEnv: Registering MapOutputTracker
15/03/04 15:36:51 INFO SparkEnv: Registering BlockManagerMaster
15/03/04 15:36:51 INFO DiskBlockManager: Created local directory at /tmp/spark-local-20150304153651-d089
15/03/04 15:36:51 INFO MemoryStore: MemoryStore started with capacity 267.3 MB
15/03/04 15:36:51 INFO HttpFileServer: HTTP File server directory is /tmp/spark-f3705b9a-d878-441f-8128-042e0363b2d3
15/03/04 15:36:51 INFO HttpServer: Starting HTTP Server
15/03/04 15:36:51 INFO Utils: Successfully started service 'HTTP file server' on port 47583.
15/03/04 15:36:51 INFO Utils: Successfully started service 'SparkUI' on port 4040.
15/03/04 15:36:51 INFO SparkUI: Started SparkUI at http://feng02:4040
15/03/04 15:36:51 INFO AppClient$ClientActor: Connecting to master spark://feng02:7077...
15/03/04 15:36:52 INFO SparkDeploySchedulerBackend: Connected to Spark cluster with app ID app-20150304153652-0001
15/03/04 15:36:52 INFO AppClient$ClientActor: Executor added: app-20150304153652-0001/0 on worker-20150304143413-feng03-41090 (feng03:41090) with 4 cores
15/03/04 15:36:52 INFO SparkDeploySchedulerBackend: Granted executor ID app-20150304153652-0001/0 on hostPort feng03:41090 with 4 cores, 512.0 MB RAM
15/03/04 15:36:52 INFO AppClient$ClientActor: Executor added: app-20150304153652-0001/1 on worker-20150304143413-feng01-51840 (feng01:51840) with 4 cores
15/03/04 15:36:52 INFO SparkDeploySchedulerBackend: Granted executor ID app-20150304153652-0001/1 on hostPort feng01:51840 with 4 cores, 512.0 MB RAM
15/03/04 15:36:52 INFO AppClient$ClientActor: Executor added: app-20150304153652-0001/2 on worker-20150304142824-feng02-56719 (feng02:56719) with 1 cores
15/03/04 15:36:52 INFO SparkDeploySchedulerBackend: Granted executor ID app-20150304153652-0001/2 on hostPort feng02:56719 with 1 cores, 512.0 MB RAM
15/03/04 15:36:52 INFO AppClient$ClientActor: Executor updated: app-20150304153652-0001/1 is now LOADING
15/03/04 15:36:52 INFO AppClient$ClientActor: Executor updated: app-20150304153652-0001/0 is now LOADING
15/03/04 15:36:52 INFO AppClient$ClientActor: Executor updated: app-20150304153652-0001/0 is now RUNNING
15/03/04 15:36:52 INFO AppClient$ClientActor: Executor updated: app-20150304153652-0001/2 is now LOADING
15/03/04 15:36:52 INFO AppClient$ClientActor: Executor updated: app-20150304153652-0001/1 is now RUNNING
15/03/04 15:36:52 INFO AppClient$ClientActor: Executor updated: app-20150304153652-0001/2 is now RUNNING
15/03/04 15:36:52 INFO NettyBlockTransferService: Server created on 44473
15/03/04 15:36:52 INFO BlockManagerMaster: Trying to register BlockManager
15/03/04 15:36:52 INFO BlockManagerMasterActor: Registering block manager feng02:44473 with 267.3 MB RAM, BlockManagerId(<driver>, feng02, 44473)
15/03/04 15:36:52 INFO BlockManagerMaster: Registered BlockManager
15/03/04 15:36:53 INFO SparkDeploySchedulerBackend: SchedulerBackend is ready for scheduling beginning after reached minRegisteredResourcesRatio: 0.0
SET spark.sql.hive.version=0.13.1
15/03/04 15:36:55 INFO SparkDeploySchedulerBackend: Registered executor: Actor[akka.tcp://sparkExecutor@feng03:41011/user/Executor#987795855] with ID 0
15/03/04 15:36:55 INFO SparkDeploySchedulerBackend: Registered executor: Actor[akka.tcp://sparkExecutor@feng01:34997/user/Executor#-664106945] with ID 1
15/03/04 15:36:55 INFO HiveMetaStore: 0: get_all_databases
15/03/04 15:36:55 INFO audit: ugi=jifeng ip=unknown-ip-addr cmd=get_all_databases
15/03/04 15:36:55 INFO BlockManagerMasterActor: Registering block manager feng03:42326 with 265.4 MB RAM, BlockManagerId(0, feng03, 42326)
15/03/04 15:36:55 INFO BlockManagerMasterActor: Registering block manager feng01:60774 with 265.4 MB RAM, BlockManagerId(1, feng01, 60774)
15/03/04 15:36:55 INFO HiveMetaStore: 0: get_functions: db=default pat=*
15/03/04 15:36:55 INFO audit: ugi=jifeng ip=unknown-ip-addr cmd=get_functions: db=default pat=*
15/03/04 15:36:55 INFO Datastore: The class "org.apache.hadoop.hive.metastore.model.MResourceUri" is tagged as "embedded-only" so does not have its own datastore table.
spark-sql> 15/03/04 15:36:58 INFO SparkDeploySchedulerBackend: Registered executor: Actor[akka.tcp://sparkExecutor@feng02:45328/user/Executor#-2134631037] with ID 2
15/03/04 15:36:58 INFO BlockManagerMasterActor: Registering block manager feng02:60870 with 267.3 MB RAM, BlockManagerId(2, feng02, 60870)
>
在集群监控页面可以看到启动了SparkSQL应用程序:
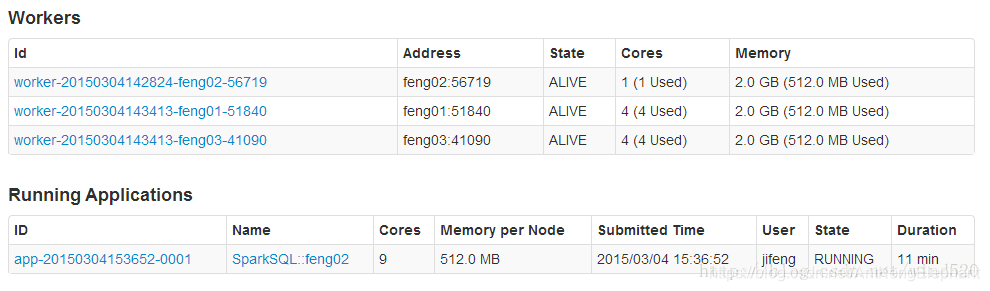
数据量少的时候慢好多
> select a.*,b.* from student a join course b where a.id=b.id ;
15/03/04 15:44:53 WARN HiveConf: DEPRECATED: hive.metastore.ds.retry.* no longer has any effect. Use hive.hmshandler.retry.* instead
15/03/04 15:44:53 INFO ParseDriver: Parsing command: select a.*,b.* from student a join course b where a.id=b.id
15/03/04 15:44:53 INFO ParseDriver: Parse Completed
15/03/04 15:44:55 INFO HiveMetaStore: 0: get_table : db=default tbl=student
15/03/04 15:44:55 INFO audit: ugi=jifeng ip=unknown-ip-addr cmd=get_table : db=default tbl=student
15/03/04 15:44:55 INFO HiveMetaStore: 0: get_table : db=default tbl=course
15/03/04 15:44:55 INFO audit: ugi=jifeng ip=unknown-ip-addr cmd=get_table : db=default tbl=course
15/03/04 15:44:55 INFO deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
15/03/04 15:44:56 INFO MemoryStore: ensureFreeSpace(436469) called with curMem=0, maxMem=280248975
15/03/04 15:44:56 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 426.2 KB, free 266.9 MB)
15/03/04 15:44:56 INFO MemoryStore: ensureFreeSpace(46914) called with curMem=436469, maxMem=280248975
15/03/04 15:44:56 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 45.8 KB, free 266.8 MB)
15/03/04 15:44:56 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on feng02:44473 (size: 45.8 KB, free: 267.2 MB)
15/03/04 15:44:56 INFO BlockManagerMaster: Updated info of block broadcast_0_piece0
15/03/04 15:44:56 INFO SparkContext: Created broadcast 0 from broadcast at TableReader.scala:68
15/03/04 15:44:56 INFO MemoryStore: ensureFreeSpace(436525) called with curMem=483383, maxMem=280248975
15/03/04 15:44:56 INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 426.3 KB, free 266.4 MB)
15/03/04 15:44:56 INFO MemoryStore: ensureFreeSpace(46946) called with curMem=919908, maxMem=280248975
15/03/04 15:44:56 INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 45.8 KB, free 266.3 MB)
15/03/04 15:44:56 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on feng02:44473 (size: 45.8 KB, free: 267.2 MB)
15/03/04 15:44:56 INFO BlockManagerMaster: Updated info of block broadcast_1_piece0
15/03/04 15:44:56 INFO SparkContext: Created broadcast 1 from broadcast at TableReader.scala:68
15/03/04 15:44:57 WARN HiveConf: DEPRECATED: hive.metastore.ds.retry.* no longer has any effect. Use hive.hmshandler.retry.* instead
15/03/04 15:44:58 INFO FileInputFormat: Total input paths to process : 1
15/03/04 15:44:58 INFO SparkContext: Starting job: collect at BroadcastHashJoin.scala:53
15/03/04 15:44:58 INFO DAGScheduler: Got job 0 (collect at BroadcastHashJoin.scala:53) with 2 output partitions (allowLocal=false)
15/03/04 15:44:58 INFO DAGScheduler: Final stage: Stage 0(collect at BroadcastHashJoin.scala:53)
15/03/04 15:44:58 INFO DAGScheduler: Parents of final stage: List()
15/03/04 15:44:58 INFO DAGScheduler: Missing parents: List()
15/03/04 15:44:58 INFO DAGScheduler: Submitting Stage 0 (MappedRDD[4] at map at BroadcastHashJoin.scala:53), which has no missing parents
15/03/04 15:44:58 INFO MemoryStore: ensureFreeSpace(6544) called with curMem=966854, maxMem=280248975
15/03/04 15:44:58 INFO MemoryStore: Block broadcast_2 stored as values in memory (estimated size 6.4 KB, free 266.3 MB)
15/03/04 15:44:58 INFO MemoryStore: ensureFreeSpace(3848) called with curMem=973398, maxMem=280248975
15/03/04 15:44:58 INFO MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 3.8 KB, free 266.3 MB)
15/03/04 15:44:58 INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on feng02:44473 (size: 3.8 KB, free: 267.2 MB)
15/03/04 15:44:58 INFO BlockManagerMaster: Updated info of block broadcast_2_piece0
15/03/04 15:44:58 INFO SparkContext: Created broadcast 2 from broadcast at DAGScheduler.scala:838
15/03/04 15:44:58 INFO DAGScheduler: Submitting 2 missing tasks from Stage 0 (MappedRDD[4] at map at BroadcastHashJoin.scala:53)
15/03/04 15:44:58 INFO TaskSchedulerImpl: Adding task set 0.0 with 2 tasks
15/03/04 15:44:58 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, feng02, NODE_LOCAL, 1320 bytes)
15/03/04 15:44:59 INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on feng02:60870 (size: 3.8 KB, free: 267.3 MB)
15/03/04 15:45:01 INFO TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, feng01, ANY, 1320 bytes)
15/03/04 15:45:02 INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on feng01:60774 (size: 3.8 KB, free: 265.4 MB)
15/03/04 15:45:02 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on feng02:60870 (size: 45.8 KB, free: 267.2 MB)
15/03/04 15:45:03 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on feng01:60774 (size: 45.8 KB, free: 265.4 MB)
15/03/04 15:45:06 INFO TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 4445 ms on feng01 (1/2)
15/03/04 15:45:07 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 9432 ms on feng02 (2/2)
15/03/04 15:45:07 INFO DAGScheduler: Stage 0 (collect at BroadcastHashJoin.scala:53) finished in 9.436 s
15/03/04 15:45:07 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
15/03/04 15:45:07 INFO StatsReportListener: Finished stage: org.apache.spark.scheduler.StageInfo@4ba4074f
15/03/04 15:45:07 INFO DAGScheduler: Job 0 finished: collect at BroadcastHashJoin.scala:53, took 9.687128 s
15/03/04 15:45:08 INFO MemoryStore: ensureFreeSpace(2264) called with curMem=977246, maxMem=280248975
15/03/04 15:45:08 INFO MemoryStore: Block broadcast_3 stored as values in memory (estimated size 2.2 KB, free 266.3 MB)
15/03/04 15:45:08 INFO MemoryStore: ensureFreeSpace(350) called with curMem=979510, maxMem=280248975
15/03/04 15:45:08 INFO MemoryStore: Block broadcast_3_piece0 stored as bytes in memory (estimated size 350.0 B, free 266.3 MB)
15/03/04 15:45:08 INFO BlockManager: Removing broadcast 2
15/03/04 15:45:08 INFO BlockManagerInfo: Added broadcast_3_piece0 in memory on feng02:44473 (size: 350.0 B, free: 267.2 MB)
15/03/04 15:45:08 INFO BlockManager: Removing block broadcast_2
15/03/04 15:45:08 INFO BlockManagerMaster: Updated info of block broadcast_3_piece0
15/03/04 15:45:08 INFO SparkContext: Created broadcast 3 from broadcast at BroadcastHashJoin.scala:55
15/03/04 15:45:08 INFO MemoryStore: Block broadcast_2 of size 6544 dropped from memory (free 279275659)
15/03/04 15:45:08 INFO BlockManager: Removing block broadcast_2_piece0
15/03/04 15:45:08 INFO MemoryStore: Block broadcast_2_piece0 of size 3848 dropped from memory (free 279279507)
15/03/04 15:45:08 INFO StatsReportListener: task runtime:(count: 2, mean: 6938.500000, stdev: 2493.500000, max: 9432.000000, min: 4445.000000)
15/03/04 15:45:08 INFO BlockManagerInfo: Removed broadcast_2_piece0 on feng02:44473 in memory (size: 3.8 KB, free: 267.2 MB)
15/03/04 15:45:08 INFO StatsReportListener: 0% 5% 10% 25% 50% 75% 90% 95% 100%
15/03/04 15:45:08 INFO BlockManagerMaster: Updated info of block broadcast_2_piece0
15/03/04 15:45:08 INFO BlockManagerInfo: Removed broadcast_2_piece0 on feng01:60774 in memory (size: 3.8 KB, free: 265.4 MB)
15/03/04 15:45:08 INFO StatsReportListener: 4.4 s 4.4 s 4.4 s 4.4 s 9.4 s 9.4 s 9.4 s 9.4 s 9.4 s
15/03/04 15:45:08 INFO StatsReportListener: fetch wait time:(count: 1, mean: 0.000000, stdev: 0.000000, max: 0.000000, min: 0.000000)
15/03/04 15:45:08 INFO StatsReportListener: 0% 5% 10% 25% 50% 75% 90% 95% 100%
15/03/04 15:45:08 INFO StatsReportListener: 0.0 ms 0.0 ms 0.0 ms 0.0 ms 0.0 ms 0.0 ms 0.0 ms 0.0 ms 0.0 ms
15/03/04 15:45:08 INFO StatsReportListener: remote bytes read:(count: 1, mean: 0.000000, stdev: 0.000000, max: 0.000000, min: 0.000000)
15/03/04 15:45:08 INFO StatsReportListener: 0% 5% 10% 25% 50% 75% 90% 95% 100%
15/03/04 15:45:08 INFO StatsReportListener: 0.0 B 0.0 B 0.0 B 0.0 B 0.0 B 0.0 B 0.0 B 0.0 B 0.0 B
15/03/04 15:45:08 INFO BlockManagerInfo: Removed broadcast_2_piece0 on feng02:60870 in memory (size: 3.8 KB, free: 267.2 MB)
15/03/04 15:45:08 INFO ContextCleaner: Cleaned broadcast 2
15/03/04 15:45:08 INFO StatsReportListener: task result size:(count: 2, mean: 2146.000000, stdev: 105.000000, max: 2251.000000, min: 2041.000000)
15/03/04 15:45:08 INFO StatsReportListener: 0% 5% 10% 25% 50% 75% 90% 95% 100%
15/03/04 15:45:08 INFO StatsReportListener: 2041.0 B 2041.0 B 2041.0 B 2041.0 B 2.2 KB 2.2 KB 2.2 KB 2.2 KB 2.2 KB
15/03/04 15:45:08 INFO StatsReportListener: executor (non-fetch) time pct: (count: 2, mean: 96.539434, stdev: 1.668793, max: 98.208227, min: 94.870641)
15/03/04 15:45:08 INFO StatsReportListener: 0% 5% 10% 25% 50% 75% 90% 95% 100%
15/03/04 15:45:08 INFO StatsReportListener: 95 % 95 % 95 % 95 % 98 % 98 % 98 % 98 % 98 %
15/03/04 15:45:08 INFO StatsReportListener: fetch wait time pct: (count: 1, mean: 0.000000, stdev: 0.000000, max: 0.000000, min: 0.000000)
15/03/04 15:45:08 INFO StatsReportListener: 0% 5% 10% 25% 50% 75% 90% 95% 100%
15/03/04 15:45:08 INFO StatsReportListener: 0 % 0 % 0 % 0 % 0 % 0 % 0 % 0 % 0 %
15/03/04 15:45:08 INFO StatsReportListener: other time pct: (count: 2, mean: 3.460566, stdev: 1.668793, max: 5.129359, min: 1.791773)
15/03/04 15:45:08 INFO StatsReportListener: 0% 5% 10% 25% 50% 75% 90% 95% 100%
15/03/04 15:45:08 INFO StatsReportListener: 2 % 2 % 2 % 2 % 5 % 5 % 5 % 5 % 5 %
15/03/04 15:45:09 INFO FileInputFormat: Total input paths to process : 1
15/03/04 15:45:09 INFO SparkContext: Starting job: collect at SparkPlan.scala:84
15/03/04 15:45:09 INFO DAGScheduler: Got job 1 (collect at SparkPlan.scala:84) with 2 output partitions (allowLocal=false)
15/03/04 15:45:09 INFO DAGScheduler: Final stage: Stage 1(collect at SparkPlan.scala:84)
15/03/04 15:45:09 INFO DAGScheduler: Parents of final stage: List()
15/03/04 15:45:09 INFO DAGScheduler: Missing parents: List()
15/03/04 15:45:09 INFO DAGScheduler: Submitting Stage 1 (MappedRDD[10] at map at SparkPlan.scala:84), which has no missing parents
15/03/04 15:45:09 INFO MemoryStore: ensureFreeSpace(11896) called with curMem=969468, maxMem=280248975
15/03/04 15:45:09 INFO MemoryStore: Block broadcast_4 stored as values in memory (estimated size 11.6 KB, free 266.3 MB)
15/03/04 15:45:09 INFO MemoryStore: ensureFreeSpace(6628) called with curMem=981364, maxMem=280248975
15/03/04 15:45:09 INFO MemoryStore: Block broadcast_4_piece0 stored as bytes in memory (estimated size 6.5 KB, free 266.3 MB)
15/03/04 15:45:09 INFO BlockManagerInfo: Added broadcast_4_piece0 in memory on feng02:44473 (size: 6.5 KB, free: 267.2 MB)
15/03/04 15:45:09 INFO BlockManagerMaster: Updated info of block broadcast_4_piece0
15/03/04 15:45:09 INFO SparkContext: Created broadcast 4 from broadcast at DAGScheduler.scala:838
15/03/04 15:45:09 INFO DAGScheduler: Submitting 2 missing tasks from Stage 1 (MappedRDD[10] at map at SparkPlan.scala:84)
15/03/04 15:45:09 INFO TaskSchedulerImpl: Adding task set 1.0 with 2 tasks
15/03/04 15:45:09 INFO TaskSetManager: Starting task 0.0 in stage 1.0 (TID 2, feng02, NODE_LOCAL, 1318 bytes)
15/03/04 15:45:09 INFO BlockManagerInfo: Added broadcast_4_piece0 in memory on feng02:60870 (size: 6.5 KB, free: 267.2 MB)
15/03/04 15:45:09 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on feng02:60870 (size: 45.8 KB, free: 267.2 MB)
15/03/04 15:45:09 INFO BlockManagerInfo: Added broadcast_3_piece0 in memory on feng02:60870 (size: 350.0 B, free: 267.2 MB)
15/03/04 15:45:09 INFO TaskSetManager: Starting task 1.0 in stage 1.0 (TID 3, feng02, NODE_LOCAL, 1318 bytes)
15/03/04 15:45:09 INFO TaskSetManager: Finished task 0.0 in stage 1.0 (TID 2) in 788 ms on feng02 (1/2)
15/03/04 15:45:09 INFO DAGScheduler: Stage 1 (collect at SparkPlan.scala:84) finished in 0.847 s
15/03/04 15:45:09 INFO StatsReportListener: Finished stage: org.apache.spark.scheduler.StageInfo@4379057
15/03/04 15:45:09 INFO StatsReportListener: task runtime:(count: 2, mean: 432.000000, stdev: 356.000000, max: 788.000000, min: 76.000000)
15/03/04 15:45:09 INFO StatsReportListener: 0% 5% 10% 25% 50% 75% 90% 95% 100%
15/03/04 15:45:09 INFO StatsReportListener: 76.0 ms 76.0 ms 76.0 ms 76.0 ms 788.0 ms 788.0 ms 788.0 ms788.0 ms 788.0 ms
15/03/04 15:45:09 INFO DAGScheduler: Job 1 finished: collect at SparkPlan.scala:84, took 0.898729 s
15/03/04 15:45:09 INFO StatsReportListener: task result size:(count: 2, mean: 1904.000000, stdev: 23.000000, max: 1927.000000, min: 1881.000000)
15/03/04 15:45:09 INFO StatsReportListener: 0% 5% 10% 25% 50% 75% 90% 95% 100%
15/03/04 15:45:09 INFO StatsReportListener: 1881.0 B 1881.0 B 1881.0 B 1881.0 B 1927.0 B1927.0 B 1927.0 B 1927.0 B 1927.0 B
15/03/04 15:45:09 INFO TaskSetManager: Finished task 1.0 in stage 1.0 (TID 3) in 76 ms on feng02 (2/2)
15/03/04 15:45:09 INFO TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool
15/03/04 15:45:09 INFO StatsReportListener: executor (non-fetch) time pct: (count: 2, mean: 79.889126, stdev: 15.415442, max: 95.304569, min: 64.473684)
15/03/04 15:45:09 INFO StatsReportListener: 0% 5% 10% 25% 50% 75% 90% 95% 100%
15/03/04 15:45:09 INFO StatsReportListener: 64 % 64 % 64 % 64 % 95 % 95 % 95 % 95 % 95 %
15/03/04 15:45:09 INFO StatsReportListener: other time pct: (count: 2, mean: 20.110874, stdev: 15.415442, max: 35.526316, min: 4.695431)
15/03/04 15:45:09 INFO StatsReportListener: 0% 5% 10% 25% 50% 75% 90% 95% 100%
15/03/04 15:45:09 INFO StatsReportListener: 5 % 5 % 5 % 5 % 36 % 36 % 36 % 36 % 36 %
1 nick 24 1 英语 中文 法文 日文
2 doping 25 2 中文 法文
3 caizhi 26 3 中文 法文 日文
4 liaozhi 27 4 中文 法文 拉丁
5 wind 30 5 中文 法文 德文
Time taken: 16.941 seconds
15/03/04 15:45:10 INFO CliDriver: Time taken: 16.941 seconds
---------------------
作者:wind520
来源:优快云
原文:https://blog.youkuaiyun.com/wind520/article/details/44059709
版权声明:本文为博主原创文章,转载请附上博文链接!

















 370
370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









