




什么是向量数据库
向量是数据在高维空间中的数学表示。在这个空间中,每个维度对应数据的一个特征,维度的数量从几百到几万不等,具体取决于所表示数据的复杂性。向量在该空间中的位置代表其特征。单词、短语或整篇文档,以及图像、音频和其他类型的数据,都可以被向量化
向量数据库(Vector database)、向量存储或向量搜索引擎是一种能够存储向量(固定长度的数值列表)及其他数据项的数据库。向量数据库通常实现一种或多种近似最近邻(Approximate Nearest Neighbor,ANN)算法,使用户可以使用查询向量搜索数据库,以检索最匹配的数据库记录(来自维基百科)
为什么选择milvus
官网
Milvus 是一款云原生向量数据库,它具备高可用、高性能、易拓展的特点,用于海量向量数据的实时召回。
Milvus 提供强大的数据建模功能,使您能够将非结构化或多模式数据组织成结构化的 Collections。它支持多种数据类型,适用于不同的属性模型,包括常见的数字和字符类型、各种向量类型、数组、集合和 JSON,为您节省了维护多个数据库系统的精力。
milvus单机部署
linux部署
curl -sfL https://raw.githubusercontent.com/milvus-io/milvus/master/scripts/standalone_embed.sh -o standalone_embed.sh
bash standalone_embed.sh start
windows部署
前提条件
安装 Docker Desktop。
安装 Windows Subsystem for Linux 2 (WSL 2)。
安装 Python 3.8+。
1.在管理员模式下右击并选择以管理员身份运行,打开 Docker Desktop。
2.下载安装脚本并将其保存为standalone.bat 。
Invoke-WebRequest https://raw.githubusercontent.com/milvus-io/milvus/refs/heads/master/scripts/standalone_embed.bat -OutFile standalone.bat
3.运行下载的脚本,将 Milvus 作为 Docker 容器启动。
standalone.bat start
Wait for Milvus starting...
Start successfully.
To change the default Milvus configuration, edit user.yaml and restart the service.
使用python连接milvus
安装pymilvus
pip install pymilvus
连接milvus
from pymilvus import MilvusClient
client = MilvusClient(
uri="http://localhost:19530",
token="root:Milvus"
)
milvus数据库操作
# 删除数据库
client.drop_database(
db_name="teachRag"
)
# 创建数据库
client.create_database(
db_name="teachRag"
)
# 使用数据库
client.use_database(
db_name="teachRag"
)
milvus创建合集(Collection)
Collection可以理解为关系型数据库里面的表
Collection 是一个二维表,具有固定的列和变化的行。每列代表一个字段,每行代表一个实体。

client.create_collection(
collection_name="teach",
dimension=1024,
)
生成文本向量
RAG的构建流程如下:
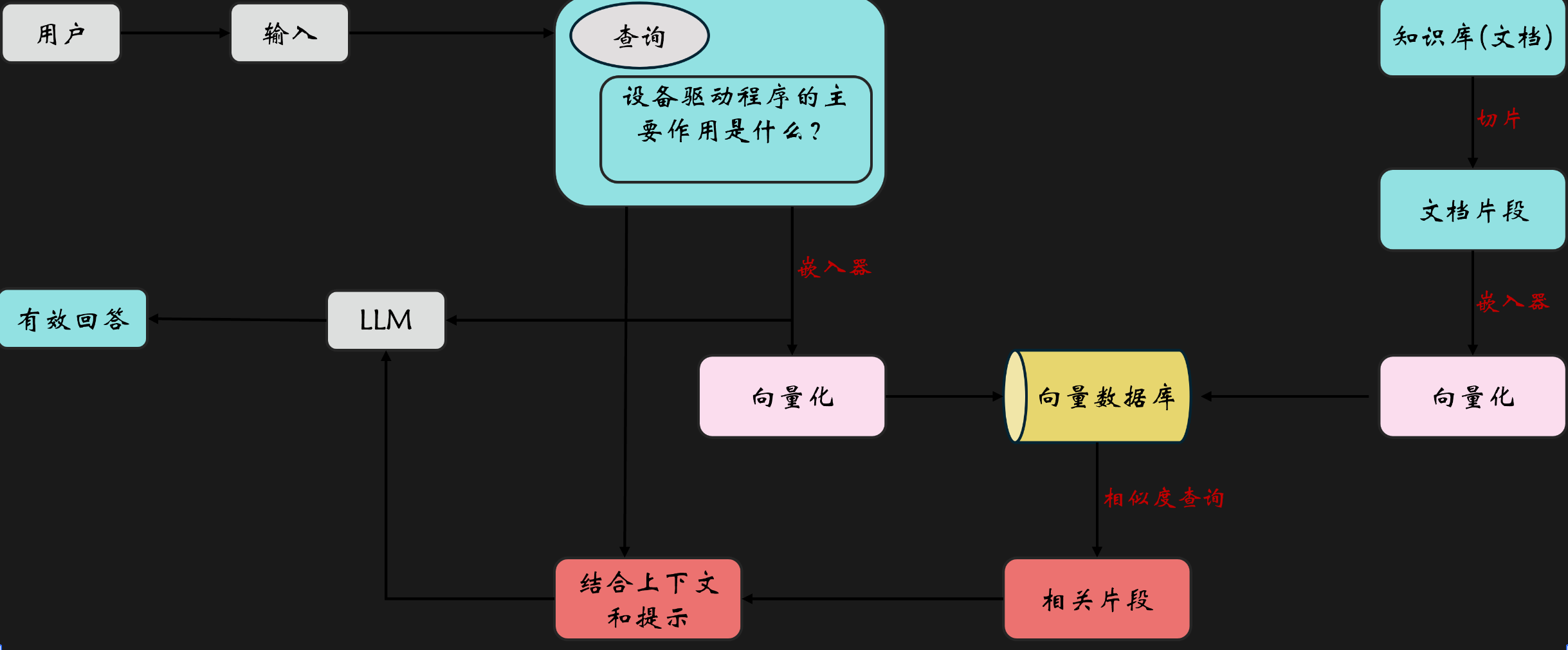
这其中最重要的就是文本向量化的过程
async def get_embedding(text: str):
completion = embedding_client.embeddings.create(
model="text-embedding-v3",
input=text,
dimensions=1024,
encoding_format="float"
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 905
905

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











