






 本文记录了在配置和使用xxl-job过程中遇到的问题,包括启动调度失败的No classes defined错误和登录调度中心后的前端缓存问题。解决方案分别涉及版本匹配和浏览器强制刷新。此外,还介绍了创建执行器项目的步骤,如maven依赖、配置文件设置以及任务管理的各个参数,如路由策略、运行模式、阻塞处理策略等。
本文记录了在配置和使用xxl-job过程中遇到的问题,包括启动调度失败的No classes defined错误和登录调度中心后的前端缓存问题。解决方案分别涉及版本匹配和浏览器强制刷新。此外,还介绍了创建执行器项目的步骤,如maven依赖、配置文件设置以及任务管理的各个参数,如路由策略、运行模式、阻塞处理策略等。
1.:配置完成,启动一次直接调度失败, 报错 No classes defined at reference ‘62’
触发调度<<<<<<<<<<<
触发调度:
address:http://10.24.24.12:9395
code:500
msg:xxl-rpc remoting (url=http://10.24.24.12:9395/run) response content invalid(C0.com.xxl.rpc.remoting.net.params.XxlRpcResponse� requestId�errorMsg�result`NS��com.xxl.rpc.util.XxlRpcException: com.caucho.hessian.io.HessianProtocolException: No classes defined at reference '62' at com.xxl.rpc.serialize.impl.HessianSerializer.deserialize(HessianSerializer.java:52) at com.xxl.rpc.remoting.net.impl.netty_http.server.NettyHttpServerHandler.process(NettyHttpServerHandler.java:81) at com.xxl.rpc.remoting.net.impl.netty_http.server.NettyHttpServerHandler.access$000(NettyHttpServerHandler.java:26) at com.xxl.rpc.remoting.net.impl.netty_http.server.NettyHttpServerHandler$1.run(NettyHttpServerHandler.java:50) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748)Caused by: com.caucho.hessian.io.HessianProtocolException: No classes defined at reference '62' at com.caucho.hessian.io.Hessian2Input.error(Hessian2Input.java:2926) at com.caucho.hessian.io.Hessian2Input.readObject(Hessian2Input.java:2118) at com.caucho.hessian.io.CollectionDeserializer.readLengthList(CollectionDeserializer.java:93) at com.caucho.hessian.io.Hessian2Input.readObject(Hessian2Input.java:2088) at com.xxl.rpc.serialize.impl.HessianSerializer.deserialize(HessianSerializer.java:49) ... 6 moreN).
原因:版本号不一致。。。
解决:请换个版本
2.登录调度中心报错,某些功能变得无法使用
原因:版本号不一致导致的js之类的前端缓存未清理
解决:换个浏览器或者Ctrl+F5强制刷新
其他问题一般只要对照这三个步骤即可判断:
创建执行器项目
在源码中,作者提供了各个版本的 执行器项目,此处以xxl-job-executor-sample-springboot项目为例。也可以自己创建项目,然后按照demo或文档进行改造。
1 maven依赖
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
<version>${project.parent.version}</version>
</dependency>
2配置文件
#日志文件
# log config
logging.config=classpath:logback.xml
#调度中心部署跟地址:如调度中心集群部署存在多个地址则用逗号分隔。
#执行器将会使用该地址进行"执行器心跳注册"和"任务结果回调"。
### xxl-job admin address list, such as "http://address" or "http://address01,http://address02"
xxl.job.admin.addresses=http://127.0.0.1:8080/xxl-job-admin
#执行器的名称、ip地址、端口号
### xxl-job executor address
xxl.job.executor.appname=xxl-job-executor-sample
xxl.job.executor.ip=
xxl.job.executor.port=9999
#执行器通讯TOKEN:非空时启用
### xxl-job, access token
xxl.job.accessToken=
#执行器运行日志文件存储的磁盘位置,需要对该路径拥有读写权限
### xxl-job log path
xxl.job.executor.logpath=/data/applogs/xxl-job/jobhandler
#执行器Log文件定期清理功能,指定日志保存天数,日志文件过期自动删除。限制至少保持3天,否则功能不生效
#-1表示永不删除
### xxl-job log retention days
xxl.job.executor.logretentiondays=-1
##yml格式 有说不能用域名或127.0.0.1的,但我没测出来为什么不能用
xxl:
job:
enabled: true
accessToken:
admin:
addresses: http://127.0.0.1:9102/xxl-job-admin
executor:
appname: hospital-ninth-xxljob
ip: 127.0.0.1
logpath: /opt/project/xxl-job/log
logretentiondays: 30
port: 9999
注意:配置执行器的名称、IP地址、端口号,后面如果配置多个执行器时,要防止端口冲突
3.
package com.xxl.job.executor.core.config;
import com.xxl.job.core.executor.impl.XxlJobSpringExecutor;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* xxl-job config
*
* @author xuxueli 2017-04-28
*/
@Configuration
public class XxlJobConfig {
private Logger logger = LoggerFactory.getLogger(XxlJobConfig.class);
@Value("${xxl.job.admin.addresses}")
private String adminAddresses;
@Value("${xxl.job.executor.appname}")
private String appName;
@Value("${xxl.job.executor.ip}")
private String ip;
@Value("${xxl.job.executor.port}")
private int port;
@Value("${xxl.job.accessToken}")
private String accessToken;
@Value("${xxl.job.executor.logpath}")
private String logPath;
@Value("${xxl.job.executor.logretentiondays}")
private int logRetentionDays;
@Bean(initMethod = "start", destroyMethod = "destroy")
public XxlJobSpringExecutor xxlJobExecutor() {
logger.info(">>>>>>>>>>> xxl-job config init.");
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(adminAddresses);
xxlJobSpringExecutor.setAppName(appName);
xxlJobSpringExecutor.setIp(ip);
xxlJobSpringExecutor.setPort(port);
xxlJobSpringExecutor.setAccessToken(accessToken);
xxlJobSpringExecutor.setLogPath(logPath);
xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);
return xxlJobSpringExecutor;
}
/**
* 针对多网卡、容器内部署等情况,可借助 "spring-cloud-commons" 提供的 "InetUtils" 组件灵活定制注册IP;
*
* 1、引入依赖:
* <dependency>
* <groupId>org.springframework.cloud</groupId>
* <artifactId>spring-cloud-commons</artifactId>
* <version>${version}</version>
* </dependency>
*
* 2、配置文件,或者容器启动变量
* spring.cloud.inetutils.preferred-networks: 'xxx.xxx.xxx.'
*
* 3、获取IP
* String ip_ = inetUtils.findFirstNonLoopbackHostInfo().getIpAddress();
*/
}
参数说明:
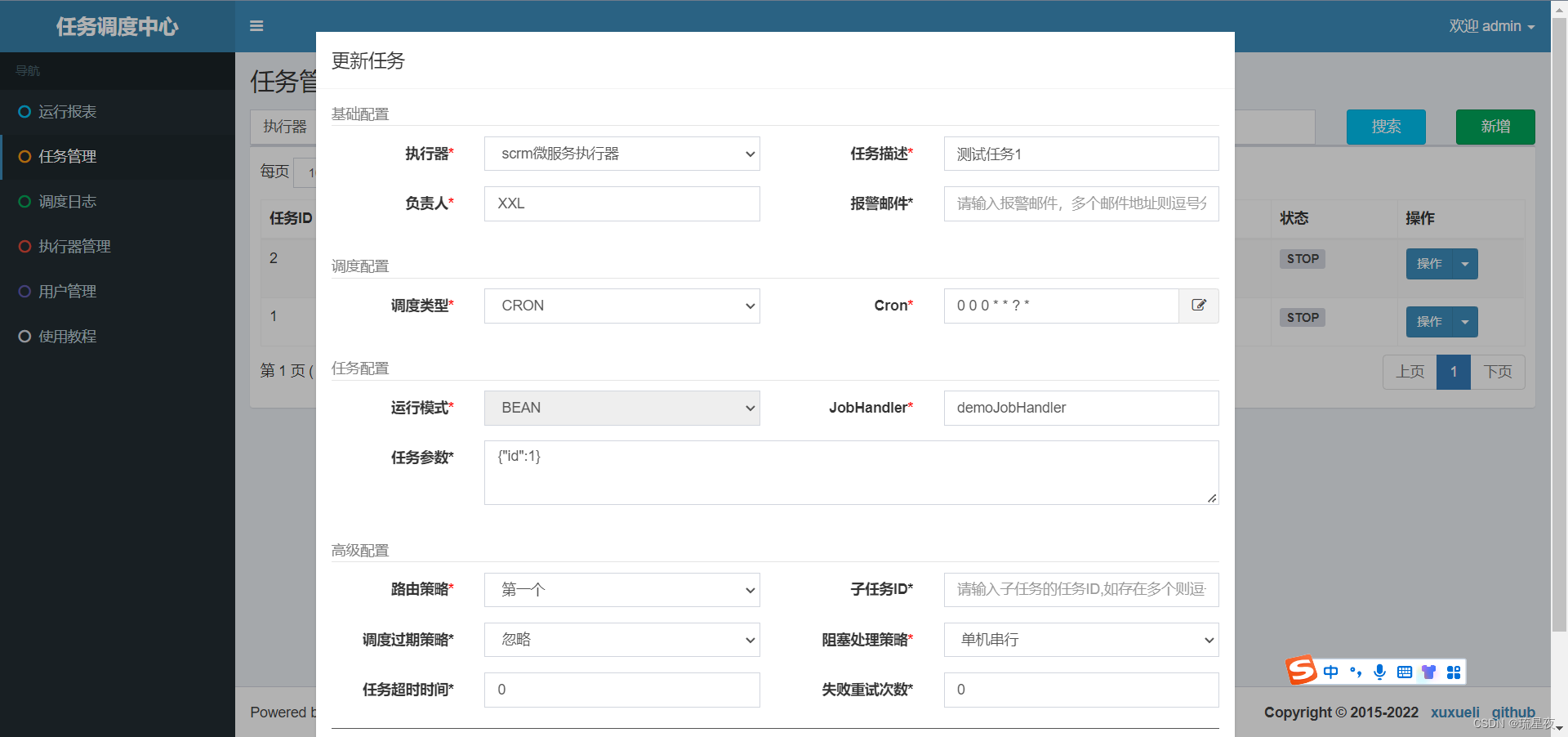
任务管理
新增任务页面字段释义
1.1、路由策略
路由策略指一个任务选择使用哪个执行器去执行。这个参数只有当执行器做集群部署的时候才有意义。
| 策略 | 参数值 | 说明 |
|---|---|---|
| 第一个 | FIRST | 固定选择第一个机器 |
| 最后一个 | LAST | 固定选择最后一个机器 |
| 轮询 | ROUND | 依次选择执行 |
| 随机 | RANDOM | 随机选择在线的机器 |
| 一致性HASH | CONSISTENT_HASH | 每个人物按照Hash算法固定选择某一台机器,且所有任务均匀散列在不同机器上 |
| 最不经常使用 | LEAST_FREQUENTLY_USED | 使用频率最低的机器优先被选择 |
| 最近最久未使用 | LEAST_RECENTLY_USED | 最久未使用的机器优先被选择 |
| 故障转义 | FAILOVER | 按照顺序依次进行心跳检测,第一个心跳检测成功的机器选定为目标执行器并发起调度 |
| 忙碌转义 | BUSYOVER | 按照顺序依次进行空闲检测,第一个空闲检测成功的机器选定位目标执行器并发起调度 |
| 分片广播 | SHARDING_BROADCAST | 广播触发对应集群中所有机器执行一次任务,同事系统自动传递分片参数,可根据分片参数开发分片任务 |
1.2、运行模式
xxl-job中,不仅支持运行预先编写好的任务类,还可以直接输入代码或脚本运行
BEAN模式
需要指定任务类,通常是Spring中的Bean,这个任务叫做JobHandler,是在执行器端编写的
GLUE模式
运行代码或脚本,支持Java、Shell、Python、PHP等,代码是直接维护在调度器的
1.3、阻塞处理策略
指任务的一次运行还没有结束的时候,下一次调度的时间又到了,要怎么处理
| 策略 | 参数值 | 说明 |
|---|---|---|
| 单机串行,默认 | SERIAL_EXECUTION | 调度请求进入单机执行器后,调度请求进入FIFO队列并以串行方式运行 |
| 丢弃后续调度 | DISCARD_LATER | 调度请求进入单机执行器后,发现执行器存在运行的调度任务,本次请求将会被丢弃并标记为失败 |
| 覆盖之前调度 | COVER_EARLY | 调度请求进入单机执行器后,发现执行器存在运行的调度任务,将会终止运行中的调度任务并清空队列,然后运行本次调度任务 |
1.4、子任务ID
当有任务需要相互依赖时使用,比如在对账业务里,下载对账文件任务成功之后,才开始对账。那么,可以把这几个任务当成一个大任务来串行处理,即在一个任务的末尾触发另一个任务。
如果我们需要在本任务执行结束并且执行成功的时候触发另外一个任务,那么就可以把另外的任务作为本任务的子任务运行,就只需要在本任务里填入另外一个任务的jobId即可(可以在任务列表查看JobId)
1.5、JobHandler
如果是Bean模式的任务,这里需要填入在程序中指定的JobHandler的value值
如果是GLUE模式,该项不需要填
1.6、Cron
任务定时处理的规则
1.7、任务超时时间
如果任务执行的时间超过了设置的超时时间,那么任务会被打断,停止执行
任务操作
执行一次是指点击此按钮会理解执行一次该任务,不管这个任务是不是启动了定时执行,可用于调试定时任务
查询日志 可以查询该任务的执行日志,也可以在调度日志菜单下查看日志
注册节点 可以查看这个任务是运行在哪些执行器上
GLUE IDE 是GLUE模式下的集成开发环境,可以直接在里面书写一些代码
启动 新建的任务只有启动了之后才会定时周期性的执行
原文链接:
参考:
https://www.cnblogs.com/lwcode6/p/11340296.html
https://blog.youkuaiyun.com/zyxwvuuvwxyz/article/details/110233098

















 3万+
3万+





 到【灌水乐园】发言
到【灌水乐园】发言







