




 本文介绍如何使用Docker快速部署单机版Hadoop,包括下载镜像、运行容器及配置环境变量等步骤,并验证MapReduce程序是否能正常运行。
本文介绍如何使用Docker快速部署单机版Hadoop,包括下载镜像、运行容器及配置环境变量等步骤,并验证MapReduce程序是否能正常运行。
docker安装单机hadoop
#下载hadoop镜像
docker pull sequenceiq/hadoop-docker:2.6.0
#查看镜像
docker images
#运行hadoop
docker run -i -t -p 50070:50070 -p 9000:9000 -p 8088:8088 -p 8040:8040 -p 8042:8042 -p 49707:49707 -p 50010:50010 -p 50075:50075 -p 50090:50090 sequenceiq/hadoop-docker:2.6.0 /etc/bootstrap.sh -bash
先进入hadoop容器
docker exec -it ${CONTAINER ID} /bin/bash
执行完成docker run 也就是上一步,该步骤可以省略
cd /usr/local/hadoop-2.6.0
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar grep input output 'dfs[a-z.]+'
如果执行mapreduce程序说明安装成功
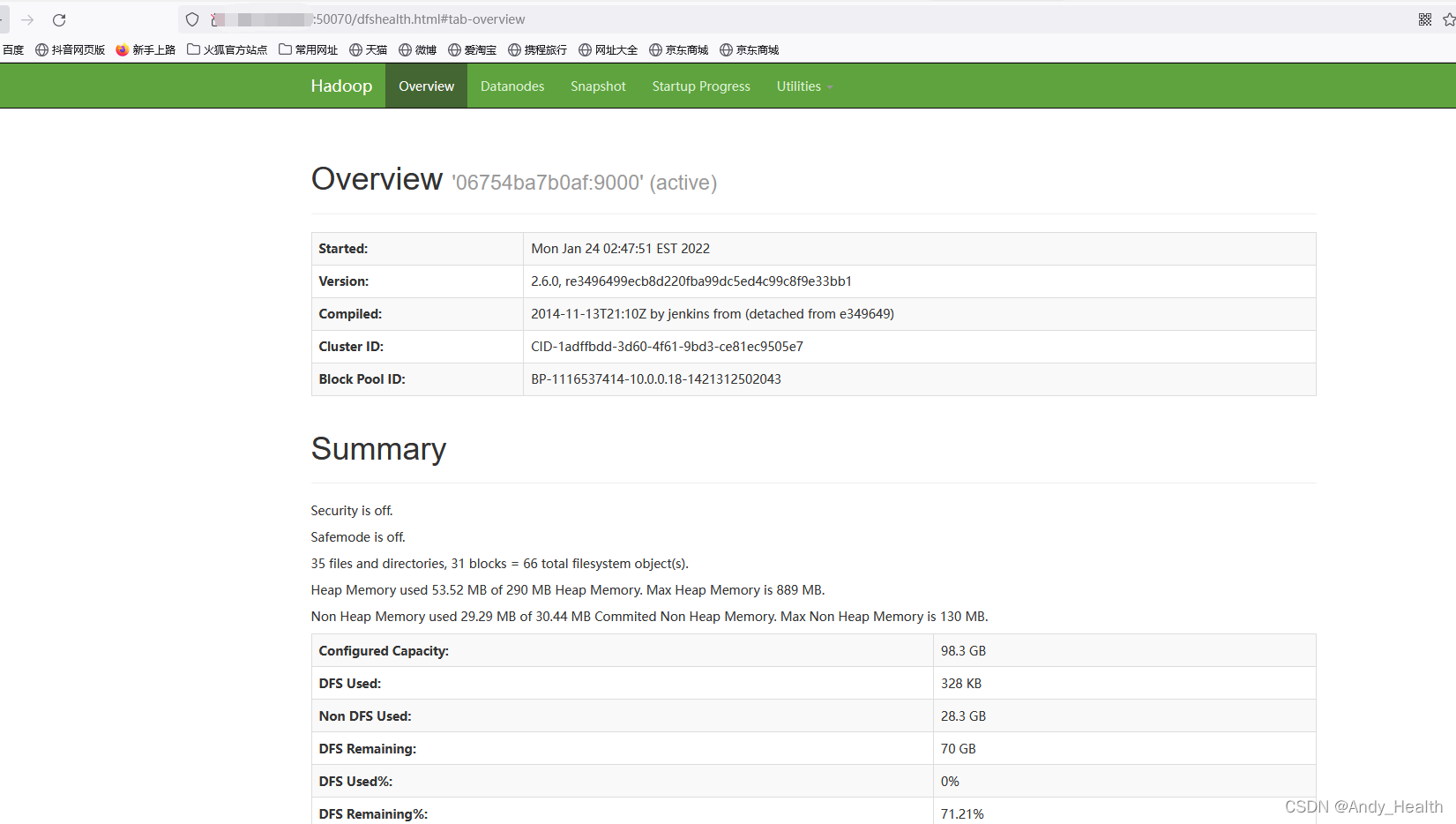
可以打开浏览器查看
宿主机IP:50070
docker安装完毕
为了正常使用还需安装以下东西
vi /etc/profile
在最底部加入下面内容
export HADOOP_HOME="/usr/local/hadoop"
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
保存:wq
使得配置生效
source /etc/profile
hadoop version
再次启动:
docker ps -a
docker start ${CONTAINER ID}

















 715
715

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









