







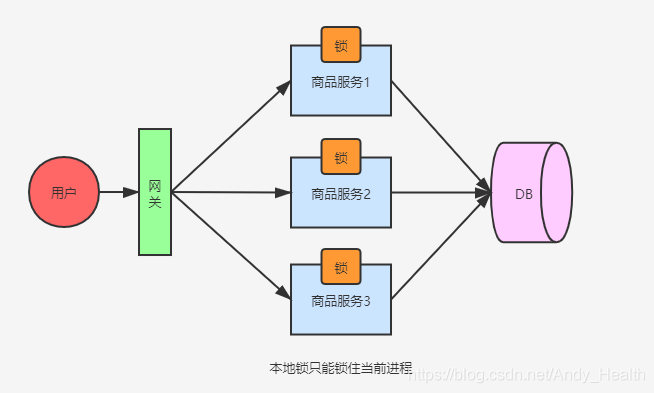
Synchronized、ReentrantLock,在单进程情况下,多个线程访问同一资源,可以用它们来保证线程的安全性。
本地锁
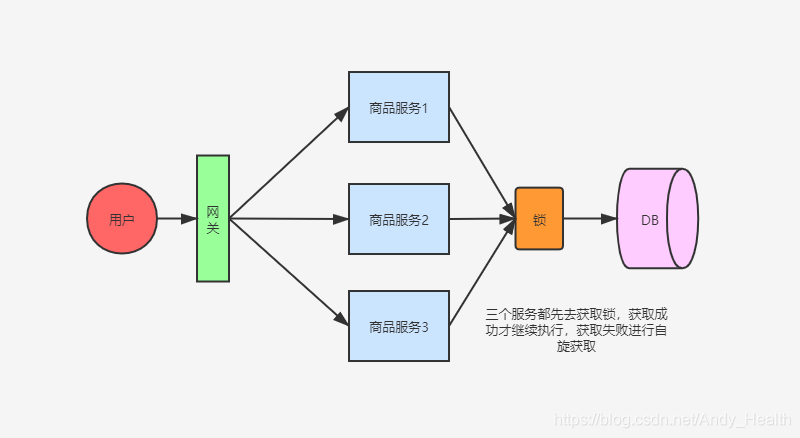
分布式锁
一、Redis 实现
为实现分布式锁,在 Redis 中存在 SETNX key value 命令,意为 set if not exists(如果不存在该 key,才去 set 值),就比如说是张三去上厕所,看厕所门锁着,他就不进去了,厕所门开着他才去。
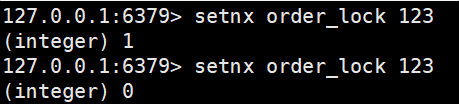
可以看到,第一次 set 返回了 1,表示成功,但是第二次返回 0,表示 set 失败,因为已经存在这个 key 了。
当然只靠 setnx 这个命令可以吗?当然是不行的,试想一种情况,张三在厕所里,但他在里面一直没有释放,一直在里面蹲着,那外面人想去厕所全部都去不了,都想锤死他了。
Redis 同理,假设已经进行了加锁,但是因为宕机或者出现异常未释放锁,就造成了所谓的“死锁”。
聪明的你们肯定早都想到了,为它设置过期时间不就好了,可以 SETEX key seconds value 命令,为指定 key 设置过期时间,单位为秒。
但这样又有另一个问题,我刚加锁成功,还没设置过期时间,Redis 宕机了不就又死锁了,所以说要保证原子性吖,要么一起成功,要么一起失败。
当然我们能想到的 Redis 肯定早都为你实现好了,在 Redis 2.8 的版本后,Redis 就为我们提供了一条组合命令 SET key value ex seconds nx,加锁的同时设置过期时间。
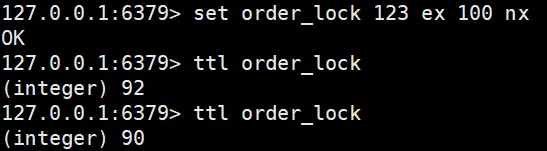
就好比是公司规定每人最多只能在厕所呆 2 分钟,不管释放没释放完都得出来,这样就解决了“死锁”问题。
但这样就没有问题了吗?怎么可能。
试想又一种情况,厕所门肯定只能从里面开啊,张三上完厕所后张四进去锁上门,但是外面人以为还是张三在里面,而且已经过了 3 分钟了,就直接把门给撬开了,一看里面却是张四,这就很尴尬啊。
换成 Redis 就是说比如一个业务执行时间很长,锁已经自己过期了,别人已经设置了新的锁,但是当业务执行完之后直接释放锁,就有可能是删除了别人加的锁,这不是乱套了吗。
所以在加锁时候,要设一个随机值,在删除锁时进行比对,如果是自己的锁,才删除。
//基于jedis和lua脚本来实现
privatestaticfinal String LOCK_SUCCESS = "OK";
privatestaticfinal Long RELEASE_SUCCESS = 1L;
privatestaticfinal String SET_IF_NOT_EXIST = "NX";
privatestaticfinal String SET_WITH_EXPIRE_TIME = "PX";
@Override
public String acquire() {
try {
// 获取锁的超时时间,超过这个时间则放弃获取锁
long end = System.currentTimeMillis() + acquireTimeout;
// 随机生成一个 value
String requireToken = UUID.randomUUID().toString();
while (System.currentTimeMillis() < end) {
String result = jedis
.set(lockKey, requireToken, SET_IF_NOT_EXIST, SET_WITH_EXPIRE_TIME, expireTime);
if (LOCK_SUCCESS.equals(result)) {
return requireToken;
}
try {
Thread.sleep(100);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
} catch (Exception e) {
log.error("acquire lock due to error", e);
}
returnnull;
}
@Override
public boolean release(String identify) {
if (identify == null) {
returnfalse;
}
//通过lua脚本进行比对删除操作,保证原子性
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
Object result = new Object();
try {
result = jedis.eval(script, Collections.singletonList(lockKey),
Collections.singletonList(identify));
if (RELEASE_SUCCESS.equals(result)) {
log.info("release lock success, requestToken:{}", identify);
returntrue;
}
} catch (Exception e) {
log.error("release lock due to error", e);
} finally {
if (jedis != null) {
jedis.close();
}
}
log.info("release lock failed, requestToken:{}, result:{}", identify, result);
returnfalse;
}
思考:加锁和释放锁的原子性可以用 lua 脚本来保证,那锁的自动续期改如何实现呢?
二、Redisson 实现
Redisson 顾名思义,Redis 的儿子,本质上还是 Redis 加锁,不过是对 Redis 做了很多封装,它不仅提供了一系列的分布式的 Java 常用对象,还提供了许多分布式服务。
在引入 Redisson 的依赖后,就可以直接进行调用:
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.13.4</version>
</dependency>
private void test() {
//分布式锁名 锁的粒度越细,性能越好
RLock lock = redissonClient.getLock("test_lock");
lock.lock();
try {
//具体业务......
} finally {
lock.unlock();
}
}
就是这么简单,使用方法 jdk 的 ReentrantLock 差不多,并且也支持 ReadWriteLock(读写锁)、Reentrant Lock(可重入锁)、Fair Lock(公平锁)、RedLock(红锁)等各种锁,详细可以参照redisson官方文档来查看。
那么 Redisson 到底有哪些优势呢? 锁的自动续期(默认都是 30 秒),如果业务超长,运行期间会自动给锁续上新的 30s,不用担心业务执行时间超长而锁被自动删掉。
加锁的业务只要运行完成,就不会给当前续期,即便不手动解锁,锁默认在 30s 后删除,不会造成死锁问题。
前面也提到了锁的自动续期,我们来看看 Redisson 是如何来实现的。
先说明一下,这里主要讲的是 Redisson 中的 RLock,也就是可重入锁,有两种实现方法:
// 最常见的使用方法
lock.lock();
// 加锁以后10秒钟自动解锁
// 无需调用unlock方法手动解锁
lock.lock(10, TimeUnit.SECONDS);
而只有无参的方法是提供锁的自动续期操作的,内部使用的是“看门狗”机制,我们来看一看源码。
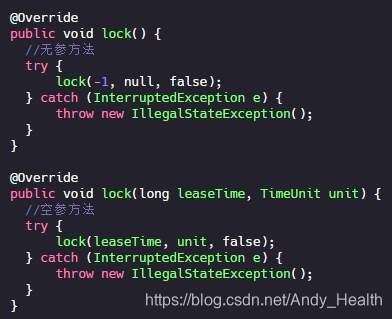
不管是空参还是带参方法,它们都调用的是同一个 lock 方法,未传参的话时间传了一个 -1,而带参的方法传过去的就是实际传入的时间。
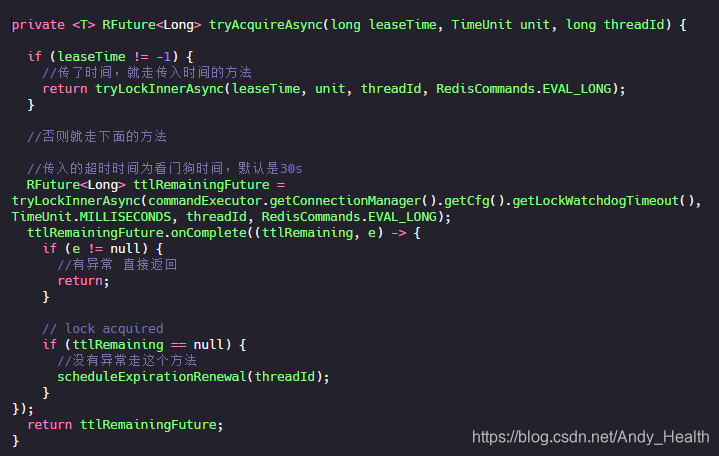
继续点进 scheduleExpirationRenewal 方法:
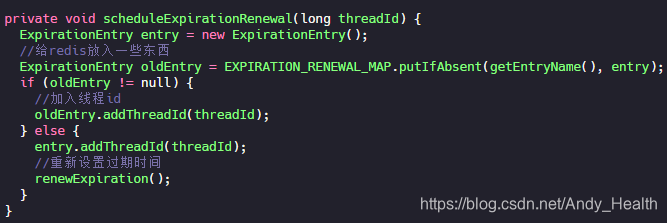
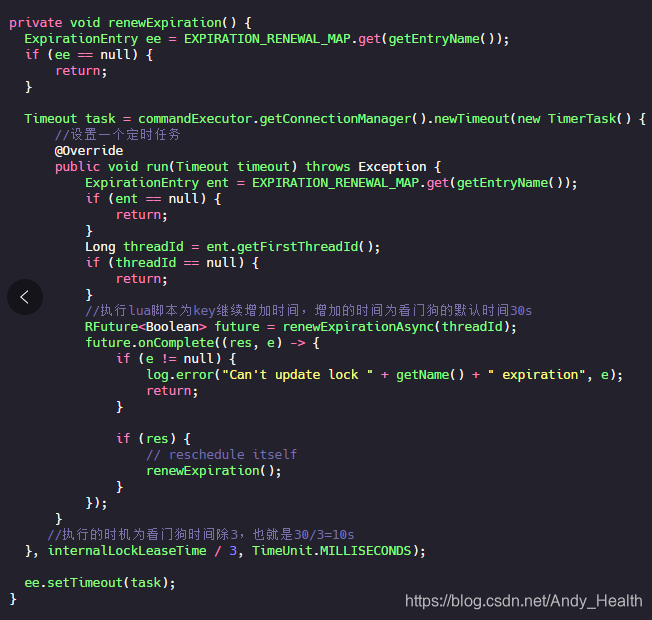
总结一下,就是当我们指定锁过期时间,那么锁到时间就会自动释放。如果没有指定锁过期时间,就使用看门狗的默认时间 30s,只要占锁成功,就会启动一个定时任务,每隔 10s 给锁设置新的过期时间,时间为看门狗的默认时间,直到锁释放。
小结: 虽然 lock() 有自动续锁机制,但是开发中还是推荐使用 lock(time,timeUnit),因为它省掉了整个续期带来的性能损,可以设置过期时间长一点,搭配 unlock()。
若业务执行完成,会手动释放锁,若是业务执行超时,那一般我们服务也都会设置业务超时时间,就直接报错了,报错后就会通过设置的过期时间来释放锁。
public void test() {
RLock lock = redissonClient.getLock("test_lock");
lock.lock(30, TimeUnit.SECONDS);
try {
//.......具体业务
} finally {
//手动释放锁
lock.unlock();
}
}
三、基于 Zookeeper 来实现分布式锁
很多小伙伴都知道在分布式系统中,可以用 ZK 来做注册中心,但其实在除了做祖册中心以外,用 ZK 来做分布式锁也是很常见的一种方案。
先来看一下 ZK 中是如何创建一个节点的?ZK 中存在 create [-s] [-e] path [data] 命令,-s 为创建有序节点,-e 创建临时节点。

这样就创建了一个父节点并为父节点创建了一个子节点,组合命令意为创建一个临时的有序节点。
而 ZK 中分布式锁主要就是靠创建临时的顺序节点来实现的。至于为什么要用顺序节点和为什么用临时节点不用持久节点?先考虑一下,下文将作出说明。
同时还有 ZK 中如何查看节点?ZK 中 ls [-w] path 为查看节点命令,-w 为添加一个 watch(监视器),/ 为查看根节点所有节点,可以看到我们刚才所创建的节点,同时如果是跟着指定节点名字的话为查看指定节点下的子节点。

后面的 00000000 为 ZK 为顺序节点增加的顺序。注册监听器也是 ZK 实现分布式锁中比较重要的一个东西。
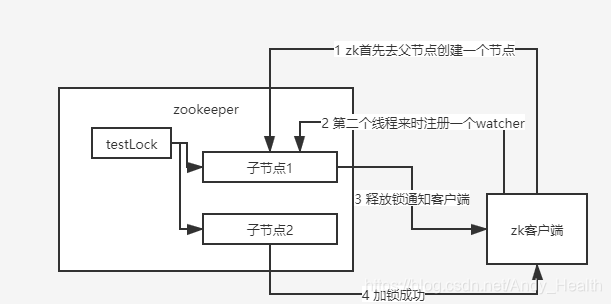
下面来看一下 ZK 实现分布式锁的主要流程:
- 当第一个线程进来时会去父节点上创建一个临时的顺序节点。
- 第二个线程进来发现锁已经被持有了,就会为当前持有锁的节点注册一个 watcher 监听器。
- 第三个线程进来发现锁已经被持有了,因为是顺序节点的缘故,就会为上一个节点去创建一个 watcher 监听器。
- 当第一个线程释放锁后,删除节点,由它的下一个节点去占有锁。
看到这里,聪明的小伙伴们都已经看出来顺序节点的好处了。非顺序节点的话,每进来一个线程进来都会去持有锁的节点上注册一个监听器,容易引发“羊群效应”。

这么大一群羊一起向你飞奔而来,不管你顶不顶得住,反正 ZK 服务器是会增大宕机的风险。
而顺序节点的话就不会,顺序节点当发现已经有线程持有锁后,会向它的上一个节点注册一个监听器,这样当持有锁的节点释放后,也只有持有锁的下一个节点可以抢到锁,相当于是排好队来执行的,降低服务器宕机风险。
至于为什么使用临时节点,和 Redis 的过期时间一个道理,就算 ZK 服务器宕机,临时节点会随着服务器的宕机而消失,避免了死锁的情况。
下面来上一段代码的实现:
public class ZooKeeperDistributedLock implements Watcher {
private ZooKeeper zk;
private String locksRoot = "/locks";
private String productId;
private String waitNode;
private String lockNode;
private CountDownLatch latch;
private CountDownLatch connectedLatch = new CountDownLatch(1);
private int sessionTimeout = 30000;
public ZooKeeperDistributedLock(String productId) {
this.productId = productId;
try {
String address = "192.168.189.131:2181,192.168.189.132:2181";
zk = new ZooKeeper(address, sessionTimeout, this);
connectedLatch.await();
} catch (IOException e) {
throw new LockException(e);
} catch (KeeperException e) {
throw new LockException(e);
} catch (InterruptedException e) {
throw new LockException(e);
}
}
public void process(WatchedEvent event) {
if (event.getState() == KeeperState.SyncConnected) {
connectedLatch.countDown();
return;
}
if (this.latch != null) {
this.latch.countDown();
}
}
public void acquireDistributedLock() {
try {
if (this.tryLock()) {
return;
} else {
waitForLock(waitNode, sessionTimeout);
}
} catch (KeeperException e) {
throw new LockException(e);
} catch (InterruptedException e) {
throw new LockException(e);
}
}
//获取锁
public boolean tryLock() {
try {
// 传入进去的locksRoot + “/” + productId
// 假设productId代表了一个商品id,比如说1
// locksRoot = locks
// /locks/10000000000,/locks/10000000001,/locks/10000000002
lockNode = zk.create(locksRoot + "/" + productId, new byte[0], ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
// 看看刚创建的节点是不是最小的节点
// locks:10000000000,10000000001,10000000002
List<String> locks = zk.getChildren(locksRoot, false);
Collections.sort(locks);
if(lockNode.equals(locksRoot+"/"+ locks.get(0))){
//如果是最小的节点,则表示取得锁
return true;
}
//如果不是最小的节点,找到比自己小1的节点
int previousLockIndex = -1;
for(int i = 0; i < locks.size(); i++) {
if(lockNode.equals(locksRoot + “/” + locks.get(i))) {
previousLockIndex = i - 1;
break;
}
}
this.waitNode = locks.get(previousLockIndex);
} catch (KeeperException e) {
throw new LockException(e);
} catch (InterruptedException e) {
throw new LockException(e);
}
return false;
}
private boolean waitForLock(String waitNode, long waitTime) throws InterruptedException, KeeperException {
Stat stat = zk.exists(locksRoot + "/" + waitNode, true);
if (stat != null) {
this.latch = new CountDownLatch(1);
this.latch.await(waitTime, TimeUnit.MILLISECONDS);
this.latch = null;
}
return true;
}
//释放锁
public void unlock() {
try {
System.out.println("unlock " + lockNode);
zk.delete(lockNode, -1);
lockNode = null;
zk.close();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (KeeperException e) {
e.printStackTrace();
}
}
//异常
public class LockException extends RuntimeException {
private static final long serialVersionUID = 1L;
public LockException(String e) {
super(e);
}
public LockException(Exception e) {
super(e);
}
}
}
四、总结
既然明白了 Redis 和 ZK 分别对分布式锁的实现,那么总该有所不同的吧。没错,我都帮大家整理好了:
- 实现方式的不同,Redis 实现为去插入一条占位数据,而 ZK 实现为去注册一个临时节点。
- 遇到宕机情况时,Redis 需要等到过期时间到了后自动释放锁,而 ZK 因为是临时节点,在宕机时候已经是删除了节点去释放锁。
- Redis 在没抢占到锁的情况下一般会去自旋获取锁,比较浪费性能,而 ZK 是通过注册监听器的方式获取锁,性能而言优于 Redis。
五、MySQL分布式锁,基于唯一索引(insert)实现
实现方式
- 获取锁时在数据库中insert一条数据,包括id、方法名(唯一索引)、线程名(用于重入)、重入计数
- 获取锁如果成功则返回true
- 获取锁的动作放在while循环中,周期性尝试获取锁直到结束或者可以定义方法来限定时间内获取锁
- 释放锁的时候,delete对应的数据
优点:
- 实现简单、易于理解
缺点
- 没有线程唤醒,获取失败就被丢掉了;
- 没有超时保护,一旦解锁操作失败,就会导致锁记录一直在数据库中,其他线程无法再获得到锁;
- 这把锁强依赖数据库的可用性,数据库是一个单点,一旦数据库挂掉,会导致业务系统不可用;
- 并发量大的时候请求量大,获取锁的间隔,如果较小会给系统和数据库造成压力;
- 这把锁只能是非阻塞的,因为数据的insert操作,一旦插入失败就会直接报错,没有获得锁的线程并不会进入排队队列,要想再次获得锁就要再次触发获得锁操作;
- 这把锁是非重入的,同一个线程在没有释放锁之前无法再次获得该锁,因为数据中数据已经存在了;
- 这把锁是非公平锁,所有等待锁的线程凭运气去争夺锁。
简单实现方案
新建一张最简单的表
CREATE TABLE `t_lock` (
`lock_key` varchar(64) NOT NULL COMMENT '锁的标识',
PRIMARY KEY (`lock_key`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='分布式锁'
根据插入sql返回受影响的行数,大于0表示成功占有锁
insert ignore into t_lock(lock_key) values(:lockKey)
释放锁的时候就删除记录
delete from t_lock where lock_key = :lockKey
基于排他锁(for update)实现
乐观锁实现
原文:https://segmentfault.com/a/1190000023045815

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









