






使用 import 语句导入其它包中的声明或定义
在仓颉编程语言中,可以通过 import fullPackageName.itemName 的语法导入其他包中的一个顶层声明或定义,fullPackageName 为完整路径包名,itemName 为声明的名字。导入语句在源文件中的位置必须在包声明之后,其他声明或定义之前。例如:
package a
import std.math.*
import package1.foo
import {package1.foo, package2.bar}如果要导入的多个 itemName 同属于一个 fullPackageName,可以使用 import fullPackageName.{itemName[, itemName]*} 语法,例如:
import package1.{foo, bar, fuzz}这等价于:
import package1.foo
import package1.bar
import package1.fuzz除了通过 import fullPackagename.itemName 语法导入一个特定的顶层声明或定义外,还可以使用 import packageName.* 语法将 packageName 包中所有可见的顶层声明或定义全部导入。例如:
import package1.*
import {package1.*, package2.*}需要注意:
- import 可以被 private、internal、protected、public 访问修饰符修饰。不写访问修饰符的 import 等价于 private import。
- 导入的成员的作用域级别低于当前包声明的成员。
- 当已导出的包的模块名或者包名被篡改,使其与导出时指定的模块名或包名不一致,在导入时会报错。
- 只允许导入当前文件可见的顶层声明或定义,导入不可见的声明或定义将会在导入处报错。
- 禁止通过 import 导入当前源文件所在包的声明或定义。
- 禁止包间的循环依赖导入,如果包之间存在循环依赖,编译器会报错。
示例如下:
// pkga/a.cj
package pkga // Error, packages pkga pkgb are in circular dependencies.
import pkgb.*
class C {}
public struct R {}
// pkgb/b.cj
package pkgb
import pkga.*
// pkgc/c1.cj
package pkgc
import pkga.C // Error, 'C' is not accessible in package 'pkga'.
import pkga.R // OK, R is an external top-level declaration of package pkga.
import pkgc.f1 // Error, package 'pkgc' should not import itself.
public func f1() {}
// pkgc/c2.cj
package pkgc
func f2() {
/* OK, the imported declaration is visible to all source files of the same package
* and accessing import declaration by its name is supported.
*/
R()
// OK, accessing imported declaration by fully qualified name is supported.
pkga.R()
// OK, the declaration of current package can be accessed directly.
f1()
// OK, accessing declaration of current package by fully qualified name is supported.
pkgc.f1()
}在仓颉编程语言中,导入的声明或定义如果和当前包中的顶层声明或定义重名且不构成函数重载,则导入的声明和定义会被遮盖;导入的声明或定义如果和当前包中的顶层声明或定义重名且构成函数重载,函数调用时将会根据函数重载的规则进行函数决议。
// pkga/a.cj
package pkga
public struct R {} // R1
public func f(a: Int32) {} // f1
public func f(a: Bool) {} // f2
// pkgb/b.cj
package pkgb
import pkga.*
func f(a: Int32) {} // f3
struct R {} // R2
func bar() {
R() // OK, R2 shadows R1.
f(1) // OK, invoke f3 in current package.
f(true) // OK, invoke f2 in the imported package
}隐式导入 core 包
诸如 String、Range 等类型能直接使用,并不是因为这些类型是内置类型,而是因为编译器会自动为源码隐式的导入 core 包中所有的 public 修饰的声明。
使用 import as 对导入的名字重命名
不同包的名字空间是分隔的,因此在不同的包之间可能存在同名的顶层声明。在导入不同包的同名顶层声明时,我们支持使用 import packageName.name as newName 的方式进行重命名来避免冲突。没有名字冲突的情况下仍然可以通过 import as 来重命名导入的内容。import as 具有如下规则:
-
使用 import as 对导入的声明进行重命名后,当前包只能使用重命名后的新名字,原名无法使用。
-
如果重命名后的名字与当前包顶层作用域的其它名字存在冲突,且这些名字对应的声明均为函数类型,则参与函数重载,否则报重定义的错误。
-
支持 import pkg as newPkgName 的形式对包名进行重命名,以解决不同模块中同名包的命名冲突问题。
// a.cj package p1 public func f1() {} // d.cj package p2 public func f3() {} // b.cj package p1 public func f2() {} // c.cj package pkgc public func f1() {} // main.cj import p1 as A import p1 as B import p2.f3 as f // OK import pkgc.f1 as a import pkgc.f1 as b // OK func f(a: Int32) {} main() { A.f1() // OK, package name conflict is resolved by renaming package name. B.f2() // OK, package name conflict is resolved by renaming package name. p1.f1() // Error, the original package name cannot be used. a() // Ok. b() // Ok. pkgc.f1() // Error, the original name cannot be used. } -
如果没有对导入的存在冲突的名字进行重命名,在 import 语句处不报错;在使用处,会因为无法导入唯一的名字而报错。这种情况可以通过 import as 定义别名或者 import fullPackageName 导入包作为命名空间。
// a.cj package p1 public class C {} // b.cj package p2 public class C {} // main1.cj package pkga import p1.C import p2.C main() { let _ = C() // Error } // main2.cj package pkgb import p1.C as C1 import p2.C as C2 main() { let _ = C1() // ok let _ = C2() // ok } // main3.cj package pkgc import p1 import p2 main() { let _ = p1.C() // ok let _ = p2.C() // ok }
重导出一个导入的名字
在功能繁多的大型项目的开发过程中,这样的场景是非常常见的:包 p2 大量地使用从包 p1 中导入的声明,当包 p3 导入包 p2 并使用其中的功能时,p1 中的声明同样需要对包 p3 可见。如果要求包 p3 自行导入 p2 中使用到的 p1 中的声明,这个过程将过于繁琐。因此希望能够在 p2 被导入时一并导入 p2 使用到的 p1 中的声明。
在仓颉编程语言中,import 可以被 private、internal、protected、public 访问修饰符修饰。其中,被 public、protected 或者 internal 修饰的 import 可以把导入的成员重导出(如果这些导入的成员没有因为名称冲突或者被遮盖导致在本包中不可用)。其它包可以根据可见性直接导入并使用本包中用重导出的内容,无需从原包中导入这些内容。
- private import 表示导入的内容仅当前文件内可访问,private 是 import 的默认修饰符,不写访问修饰符的 import 等价于 private import。
- internal import 表示导入的内容在当前包及其子包(包括子包的子包)均可访问。非当前包访问需要显式 import。
- protected import 表示导入的内容在当前 module 内都可访问。非当前包访问需要显式 import。
- public import 表示导入的内容外部都可访问。非当前包访问需要显式 import。
在下面的例子中,b 是 a 的子包,在 a 中通过 public import 重导出了 b 中定义的函数 f。
package a
public let x = 0
public import a.b.finternal package a.b
public func f() { 0 }import a.f // ok
let _ = f() // ok需要注意的是,包不可以被重导出:如果被 import 导入的是包,那么该 import 不允许被 public、protected 或者 internal 修饰。
public import a.b // Error, cannot re-export package最后
有很多小伙伴不知道学习哪些鸿蒙开发技术?不知道需要重点掌握哪些鸿蒙应用开发知识点?而且学习时频繁踩坑,最终浪费大量时间。所以有一份实用的鸿蒙(HarmonyOS NEXT)资料用来跟着学习是非常有必要的。
这份鸿蒙(HarmonyOS NEXT)资料包含了鸿蒙开发必掌握的核心知识要点,
内容包含了:(ArkTS、ArkUI开发组件、Stage模型、多端部署、分布式应用开发、音频、视频、WebGL、OpenHarmony多媒体技术、Napi组件、OpenHarmony内核、OpenHarmony南向开发、鸿蒙项目实战等等)鸿蒙(HarmonyOS NEXT)技术知识点。
希望这一份鸿蒙学习资料能够给大家带来帮助,有需要的小伙伴自行领取,限时开源,先到先得~无套路领取!!
如果你是一名有经验的资深Android移动开发、Java开发、前端开发、对鸿蒙感兴趣以及转行人员,可以直接领取这份资料
获取这份完整版高清学习路线,请点击关注 → 公众皓 :【蜀道衫】即可领取
鸿蒙(HarmonyOS NEXT)最新学习路线

-
HarmonOS基础技能

- HarmonOS就业必备技能

- HarmonOS多媒体技术

- 鸿蒙NaPi组件进阶

- HarmonOS高级技能
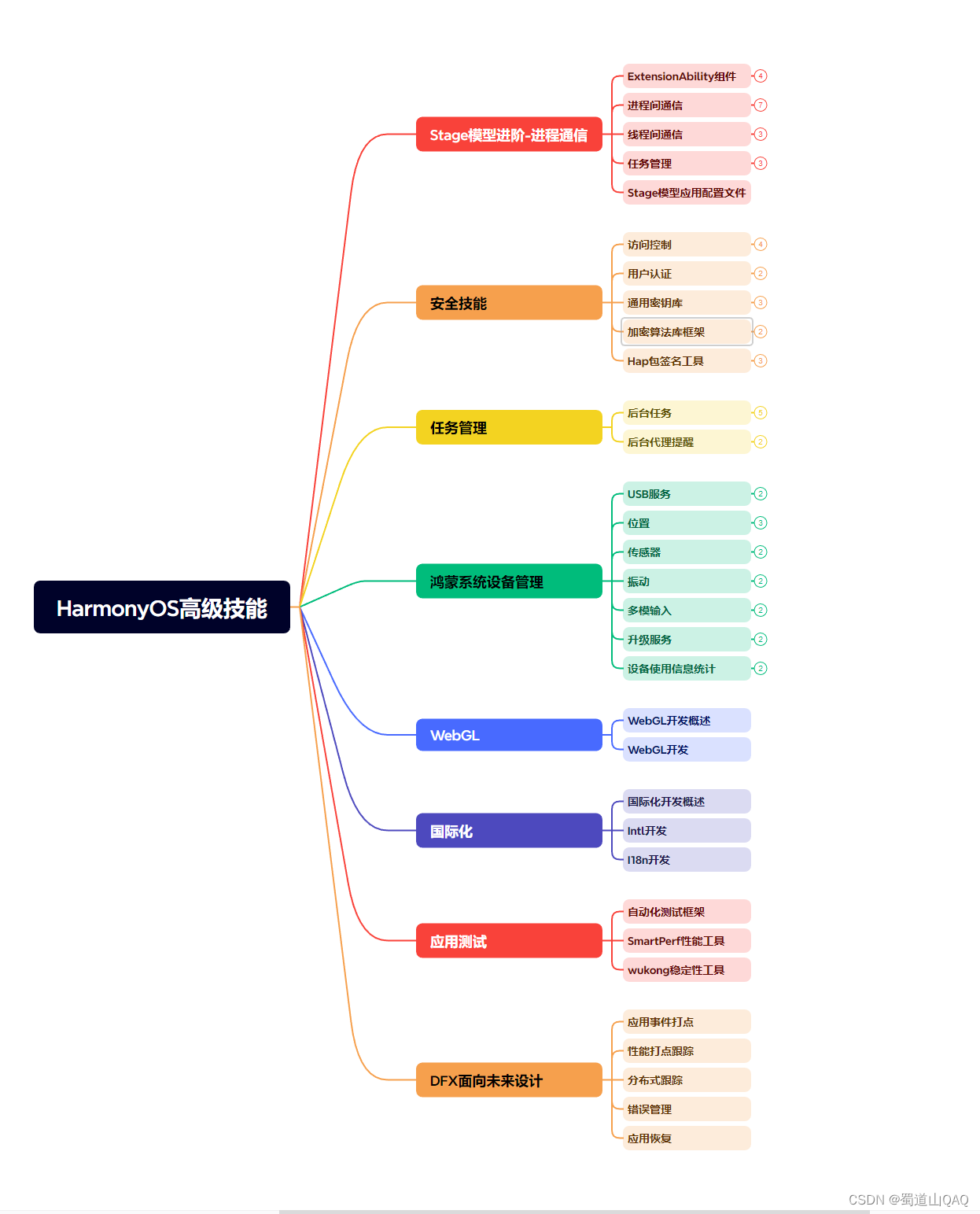
- 初识HarmonOS内核

- 实战就业级设备开发

有了路线图,怎么能没有学习资料呢,小编也准备了一份联合鸿蒙官方发布笔记整理收纳的一套系统性的鸿蒙(OpenHarmony )学习手册(共计1236页)与鸿蒙(OpenHarmony )开发入门教学视频,内容包含:ArkTS、ArkUI、Web开发、应用模型、资源分类…等知识点。
获取以上完整版高清学习路线, 请点击关注 → 公众皓 :【蜀道衫】即可领取
《鸿蒙 (OpenHarmony)开发入门教学视频》

《鸿蒙生态应用开发V2.0白皮书》

《鸿蒙 (OpenHarmony)开发基础到实战手册》
OpenHarmony北向、南向开发环境搭建

《鸿蒙开发基础》
- ArkTS语言
- 安装DevEco Studio
- 运用你的第一个ArkTS应用
- ArkUI声明式UI开发
- .……

《鸿蒙开发进阶》
- Stage模型入门
- 网络管理
- 数据管理
- 电话服务
- 分布式应用开发
- 通知与窗口管理
- 多媒体技术
- 安全技能
- 任务管理
- WebGL
- 国际化开发
- 应用测试
- DFX面向未来设计
- 鸿蒙系统移植和裁剪定制
- ……

《鸿蒙进阶实战》
- ArkTS实践
- UIAbility应用
- 网络案例
- ……

总结
总的来说,华为鸿蒙不再兼容安卓,对中年程序员来说是一个挑战,也是一个机会。只有积极应对变化,不断学习和提升自己,他们才能在这个变革的时代中立于不败之地。
看完三件事❤️
- 如果你觉得这篇内容对你还蛮有帮助,我想邀请你帮我三个小忙:
- 点赞,转发,有你们的 『点赞和评论』,才是我创造的动力。
- 关注作者公众皓 『 蜀道衫 』,不定期分享原创知识。
- 关注后回复【666】扫码即可获取学习资料包。
- 同时可以期待后续文章ing🚀。


















 2979
2979

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









