



在大型语言模型(LLM)的浪潮中,我们惊叹于其强大的生成能力。然而,LLM也面临着知识截止、幻觉(Hallucination)和缺乏领域专业知识等固有挑战。为了克服这些问题,检索增强生成(Retrieval-Augmented Generation, RAG) 技术应运而生,并迅速成为构建知识密集型、可靠且可信的AI应用的核心技术。
RAG通过在LLM生成答案之前,先从外部知识库中检索相关信息,从而将LLM的参数化知识与实时的、动态的非参数化知识相结合。这不仅显著减少了模型的“幻觉”,还使其能够提供更准确、更具上下文、可溯源的答案。RAG系统的性能高度依赖于其“检索(Retrieval)”环节的质量。检索越精准,生成越可靠。
第一部分:RAG的基础与演进——从Naive RAG到Advanced RAG
1. 朴素RAG (Naive RAG) 的工作流程
一个基础的RAG系统通常包含三个核心步骤:
-
• 索引 (Indexing): 将知识源(如文档、网页、数据库)进行预处理。
-
• 加载 (Loading): 读取原始数据。
-
• 切分 (Splitting): 将长文档切分成更小的、易于检索的文本块(Chunks)。
-
• 编码 (Embedding): 使用一个编码模型(如BERT, Sentence-BERT)将每个文本块转换成高维向量(Vector)。
-
• 存储 (Storing): 将文本块及其对应的向量存储在专门的向量数据库(Vector Database)中,如FAISS, Milvus, Pinecone。
-
• 检索 (Retrieval): 当用户提出问题时,执行以下操作。
-
• 查询编码: 将用户的问题(Query)同样用编码模型转换成向量。
-
• 向量搜索: 在向量数据库中,使用相似性搜索算法(如余弦相似度)找出与查询向量最相似的Top-K个文本块向量。
-
• 获取上下文: 提取这Top-K个文本块的原始内容作为LLM的上下文。
-
• 生成 (Generation):
-
• 构建Prompt: 将用户原始问题和检索到的上下文信息整合成一个精心设计的提示(Prompt)。
-
• LLM生成: 将该提示输入给LLM,由LLM基于提供的上下文生成最终答案。
朴素RAG的局限性:
虽然简单有效,但Naive RAG在面对复杂查询和庞大知识库时,其检索性能往往会遇到瓶颈,导致以下问题:
- • 低精度 (Low Precision): 检索到的文本块虽然相关,但不包含具体答案。
- • 低召回率 (Low Recall): 相关的文本块未能被成功检索出来。
- • 信息过时: 知识库更新不及时。
- • 上下文整合不佳: 多个检索结果之间可能存在矛盾或冗余。
为了解决这些问题,高级RAG (Advanced RAG) 和 模块化RAG (Modular RAG) 的概念应运而生。它们的核心思想是在朴素RAG的流程中引入更复杂的策略和模块,以优化检索质量。
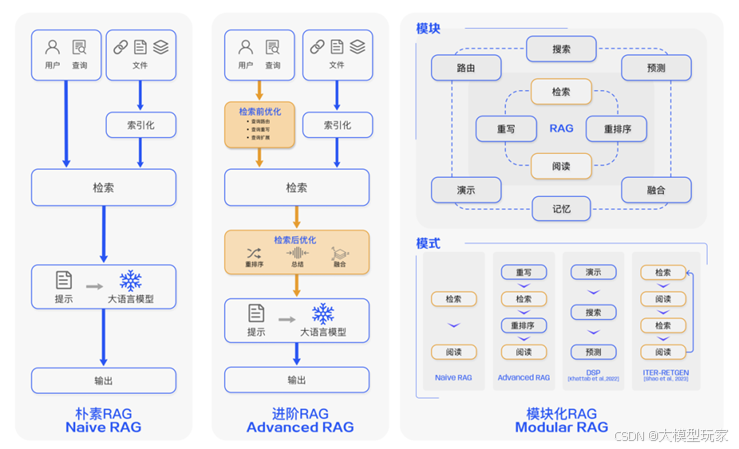

第二部分:揭秘检索性能巅峰——当前最强的RAG技术
当前,提升RAG检索性能的研究主要集中在三个方向:优化索引、改进检索过程和后处理检索结果。以下是目前被验证为效果最好的几种前沿技术。
1. 混合搜索 (Hybrid Search): 融合词法与语义的力量
理论核心:
向量搜索(语义搜索)擅长理解查询的“意图”,但有时会忽略关键词的精确匹配。例如,对于查询“Apple Vision Pro的价格”,向量搜索可能会找到关于“Apple Watch功能”的文档,因为它们在语义上相关。而传统的关键词搜索(词法搜索),如BM25算法,则能精确匹配“Apple Vision Pro”和“价格”这两个关键词。
混合搜索 结合了这两种方法的优点:
- • 词法搜索 (Lexical Search): 基于关键词频率和文档频率,如
BM25或TF-IDF。它擅长精确匹配术语、名称、缩写等。 - • 语义搜索 (Semantic Search): 基于向量嵌入的相似度计算。它擅长理解同义词、近义词和上下文语境。
通过一个加权融合策略(如Reciprocal Rank Fusion, RRF),将两种搜索的排序结果合并,能够显著提升检索的准确性和鲁棒性。
应用实例与代码(以LlamaIndex为例):
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.core.retrievers import BM25Retriever
from llama_index.core.retrievers import VectorIndexRetriever
from llama_index.core.retrievers import QueryFusionRetriever
from llama_index.core import Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.llms.openai import OpenAI
# 1. 配置模型
Settings.llm = OpenAI(model="gpt-4-turbo")
Settings.embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-large-en-v1.5") # 使用一个强大的嵌入模型
# 2. 加载和索引文档
documents = SimpleDirectoryReader("./data").load_data()
index = VectorStoreIndex.from_documents(documents)
# 3. 创建不同的检索器
vector_retriever = VectorIndexRetriever(index=index, similarity_top_k=5)
bm25_retriever = BM25Retriever.from_defaults(docstore=index.docstore, similarity_top_k=5)
# 4. 创建混合搜索检索器 (Fusion Retriever)
# num_queries=1 表示不对原始查询进行变体,直接融合
retriever = QueryFusionRetriever(
[vector_retriever, bm25_retriever],
similarity_top_k=5,
num_queries=1,
mode="RRF", # 使用Reciprocal Rank Fusion进行结果融合
)
# 5. 执行查询
query = "What is the price of the Apple Vision Pro?"
nodes = retriever.retrieve(query)
# 打印检索结果
for node in nodes:
print(f"Score: {node.score:.4f}")
print(f"Content: {node.get_content()}")
2. 重排模型 (Re-Ranking): 精炼检索结果的最后一道防线
理论核心:
第一阶段的检索(无论是向量搜索还是混合搜索)旨在快速、广泛地从海量数据中召回一个候选集(例如Top-20或Top-50的文档)。这个阶段追求的是“召回率”,可能会包含一些噪声。
重排模型(Re-Ranker) 则扮演了“精炼者”的角色。它是一个更小、更专业的模型,其唯一任务是对第一阶段检索出的文档候选集进行重新排序。它通常使用更复杂的交叉编码器(Cross-Encoder)架构,同时处理查询(Query)和每个候选文档(Document),从而更精确地计算它们之间的相关性得分。
与使用单一编码器(Bi-Encoder)分别编码查询和文档的嵌入模型相比,交叉编码器由于能同时看到两者,其相关性判断能力要强大得多,但计算成本也更高。因此,它非常适合用于小规模候选集的精排阶段。
应用实例与代码(使用Cohere Re-rank或开源模型):
from llama_index.core.postprocessor import CohereRerank # 使用Cohere的API
# 或者使用开源模型
# from llama_index.core.postprocessor import SentenceTransformerRerank
# ... 接上文的检索器 ...
# 假设我们使用vector_retriever作为基础检索器
base_retriever = VectorIndexRetriever(index=index, similarity_top_k=10) # 初始召回10个
retrieved_nodes = base_retriever.retrieve(query)
# 1. 初始化重排模型
# reranker = SentenceTransformerRerank(model="cross-encoder/ms-marco-MiniLM-L-12-v2", top_n=3)
reranker = CohereRerank(api_key="YOUR_COHERE_API_KEY", top_n=3) # 精排后只保留最好的3个
# 2. 对检索结果进行重排
reranked_nodes = reranker.postprocess_nodes(retrieved_nodes, query_str=query)
# 打印重排后的结果
print("--- Reranked Results ---")
for node in reranked_nodes:
print(f"Score: {node.score:.4f}")
print(f"Content: {node.get_content()}")
3. 查询转换 (Query Transformations): 理解用户的真实意图
理论核心:
用户的原始查询往往是模糊、简单或者充满口语化的。直接用这样的查询去检索,效果可能不佳。查询转换 是一系列旨在优化、扩展和重写用户查询的技术,以更好地匹配知识库中的文档。
目前效果最好的几种查询转换技术包括:
- • 多查询生成 (Multi-Query Generation): 使用LLM将一个复杂的用户查询分解成多个独立的、更具体的子查询。例如,将“对比RAG和Finetuning的优缺点”分解为“RAG的优点是什么?”、“RAG的缺点是什么?”、“Finetuning的优点是什么?”等。分别对这些子查询进行检索,然后合并结果,可以极大地提高召回率。
- • 假设性文档嵌入 (HyDE - Hypothetical Document Embeddings): 这是一种非常巧妙的技术。它首先让LLM根据用户的查询,生成一个“假设性”的、理想的答案文档。然后,将这个生成的假文档进行编码,用其向量去检索真实的文档。其背后的逻辑是,一个理想答案的向量表示,会比原始问题的向量表示更接近知识库中真实答案文档的向量。
- • 步退提示 (Step-Back Prompting): 同样利用LLM,引导它从具体的问题“后退一步”,生成一个更宽泛、更高层次的抽象问题。例如,用户问“如何修复我的Python代码中的KeyError?”,LLM可以生成一个更高层次的问题:“Python字典中KeyError的常见原因是什么?”。用这个抽象问题去检索,可以找到更具普适性和原理性的知识,为最终答案提供更好的背景信息。
应用实例与代码(以LlamaIndex的Multi-Query为例):
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.response_synthesizers import get_response_synthesizer
from llama_index.core.retrievers import MultiQueryRetriever
# ... 接上文的索引设置 ...
# 1. 创建基础检索器
base_retriever = VectorIndexRetriever(index=index, similarity_top_k=3)
# 2. 创建MultiQueryRetriever
# LLM会被用来生成多个查询变体
retriever = MultiQueryRetriever.from_defaults(
retriever=base_retriever,
llm=Settings.llm,
)
# 3. 构建查询引擎
response_synthesizer = get_response_synthesizer()
query_engine = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=response_synthesizer,
)
# 4. 执行查询
response = query_engine.query("What are the pros and cons of RAG vs Finetuning?")
print(response)
4. 自适应检索 (Self-Corrective / Adaptive RAG): 让RAG系统学会反思
理论核心:
传统的RAG流程是线性的、一次性的。而自适应RAG引入了一个“反思-修正”的循环,让系统能够自我评估检索到的文档质量,并根据评估结果决定下一步的行动。这使得RAG系统更加智能和动态。
Self-RAG 和 Corrective-RAG (CRAG) 是该领域的代表性框架。其核心思想是:
-
- 评估检索结果: 在检索到一批文档后,引入一个轻量级的“评估器”模型(或使用LLM本身),对每个文档与查询的相关性进行打分。常见的评估维度包括:
- • 相关性 (Relevance): 文档是否与查询直接相关?
- • 支持性 (Support): 文档内容是否能支持生成一个具体的答案?
- • 无用性 (Irrelevance): 文档是否完全不相关?
-
- 决策与行动: 根据评估结果,系统可以做出不同的决策:
- • 如果文档质量高: 直接将这些文档送入LLM生成答案(就像标准RAG)。
- • 如果文档模棱两可或不完全相关: 触发一个修正步骤,例如进行Web搜索来获取最新的、更全面的信息,或者对查询进行重写,然后再次进行检索。
- • 如果文档完全不相关: 忽略这些文档,或者直接告诉用户无法回答,而不是生成一个基于错误信息的“幻觉”答案。
这种自我修正的能力,极大地提升了RAG系统在面对复杂、开放域问题时的鲁棒性和准确性。
应用流程图(伪代码):
function Adaptive_RAG(query):
# 1. 初始检索
retrieved_docs = retrieve(query)
# 2. 评估每个文档
evaluations = []
for doc in retrieved_docs:
score = evaluate_relevance(query, doc)
evaluations.append((doc, score))
# 3. 决策
high_quality_docs = [doc for doc, score in evaluations if score == "highly_relevant"]
ambiguous_docs = [doc for doc, score in evaluations if score == "ambiguous"]
final_context = []
if len(high_quality_docs) > 0:
final_context.extend(high_quality_docs)
# 如果高质量文档不足,或者存在模棱两可的文档,进行修正
if len(high_quality_docs) < THRESHOLD or len(ambiguous_docs) > 0:
# 修正策略1:重写查询并再次检索
new_query = rewrite_query(query, ambiguous_docs)
corrected_docs = retrieve(new_query)
final_context.extend(corrected_docs)
# 修正策略2:进行Web搜索
web_results = web_search(query)
final_context.extend(web_results)
# 4. 去重并整合最终上下文
final_context = deduplicate(final_context)
# 5. 生成答案
answer = generate_with_llm(query, final_context)
return answer
第三部分:构建高性能RAG系统的工程实践与最佳策略
掌握了上述前沿技术后,如何将它们系统性地应用到实际项目中?
-
- 从一个强大的基线开始:
- • 高质量的文本切分 (Chunking): 优先选择基于语义的切分策略(如Sentence-Window),而不是简单的固定大小切分。确保每个Chunk都包含完整的语义单元。
- • 顶级的嵌入模型: 选择在MTEB (Massive Text Embedding Benchmark) 排行榜上表现优异的模型,如
BAAI/bge-large-en-v1.5或最新的Cohere、VoyageAI提供的商业模型。对领域数据进行嵌入模型的微调(Finetuning)能带来巨大提升。
-
- 分阶段引入高级策略(A/B测试验证效果):
- • 第一步:引入混合搜索。 这是性价比最高的提升,能立刻改善关键词匹配问题。
- • 第二步:加入重排模型。 在召回候选集后进行精排,是提升最终上下文质量的关键一步。
- • 第三步:实现查询转换。 对于用户查询意图复杂的场景,Multi-Query或HyDE能显著提高召回率。
- • 第四步:探索自适应检索。 如果你的应用需要极高的可靠性,并且允许稍高的延迟,实现一个简单的评估-修正循环将是质的飞跃。
-
- 构建评估框架 (Evaluation Framework):
-
• 没有评估,就没有优化。 使用Ragas、ARES等开源框架,建立一个自动化的评估流水线。
-
• 核心评估指标:
-
• Context Precision & Recall: 检索到的上下文有多准?有多全?
-
• Faithfulness: 生成的答案是否忠于提供的上下文?
-
• Answer Relevancy: 答案是否切题?
-
- 模块化与可组合性:
- • 使用如LlamaIndex、LangChain这样的框架,它们将各种RAG技术模块化,你可以像搭乐高一样,轻松地组合和试验不同的策略,例如将混合搜索、查询转换和重排模型串联起来。
结论与展望
RAG技术正从一个简单的“检索-生成”流水线,演变为一个复杂、动态、能够自我反思和修正的智能系统。当前检索性能最好的RAG技术,无一不是通过多阶段、多策略的组合来实现的。
对于AI工程师而言,成功的关键在于深刻理解每种技术的适用场景和优缺点,并建立一套科学的评估体系来指导优化方向。从混合搜索和重排模型这两个最成熟、效果最显著的技术入手,再逐步探索查询转换和自适应检索等更前沿的领域,你将能够构建出真正健壮、可靠且智能的下一代AI应用。
未来,我们可以预见RAG将与Agent技术更紧密地结合,模型不仅会决定检索什么,还会决定何时检索、如何检索、以及如何利用检索结果,甚至会主动更新知识库。RAG的演进之路,才刚刚开始。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:

04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)

05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!

06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

















 1027
1027

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









