



关键词:后训练(Post-training)、大型语言模型(Large Language Model)、微调(Fine-Tuning)、对齐(Alignment)、推理(Reasoning)、效率(Efficiency)
Title:《A SURVEY ON POST-TRAINING OF LARGE LANGUAGE MODELS》
摘要
大型语言模型(Large Language Models, LLMs)的出现从根本上改变了自然语言处理领域,使其在从对话系统到科学探索的多个领域中变得不可或缺。然而,其预训练架构在特定场景下往往存在局限性,例如推理能力受限、伦理不确定性以及领域专属性能欠佳等问题。这些挑战使得我们亟需先进的后训练语言模型(Post-training Language Models, PoLMs)来解决这些缺陷,例如 OpenAI-o1/o3 和 DeepSeek-R1(这类模型统称为大型推理模型,Large Reasoning Models, LRMs)。
本文首次对后训练语言模型(PoLMs)进行了全面综述,系统梳理了其在五大核心范式下的演进历程:
-
微调(Fine-tuning)
:提升任务专属准确性;
-
对齐(Alignment)
:确保伦理一致性及与人类偏好的契合;
-
推理(Reasoning)
:尽管奖励设计存在挑战,但仍实现了多步推理能力的提升;
-
效率(Efficiency)
:在复杂度不断增加的情况下优化资源利用率;
-
集成与适配(Integration and Adaptation)
:扩展模型在多模态场景下的能力,同时解决一致性问题。
从 ChatGPT 开创性的对齐策略,到 DeepSeek-R1 在推理领域的创新性突破,本文通过梳理这一发展脉络,阐明了后训练语言模型(PoLMs)如何利用数据集减轻偏见、深化推理能力并提升领域适配性。
本文的贡献包括:对后训练语言模型(PoLMs)的演进历程进行了开创性梳理;构建了用于对技术与数据集进行分类的结构化体系;提出了强调大型推理模型(LRMs)在提升推理熟练度与领域灵活性中核心作用的研究议程。作为该领域首篇此规模的综述,本文整合了后训练语言模型(PoLMs)近期的研究进展,为未来研究建立了严谨的理论框架,旨在推动大型语言模型(LLMs)的发展 —— 使其在精度、伦理稳健性及跨科学与社会应用的通用性上均能达到卓越水平。
项目 GitHub 地址:https://github.com/Mr-Tieguigui/LLM-Post-Training
1. 引言
人们普遍认为,真正的智能赋予我们推理能力、检验假设的能力以及为未来可能发生的情况做准备的能力。—— 让・哈勒法(Jean Khalfa)——《何为智能?》(1994 年)
语言模型(LMs)[1, 2] 是用于建模和生成人类语言的复杂计算框架。这类模型极大地革新了自然语言处理(NLP)[3] 领域,使机器能够以接近人类认知的方式理解、生成人类语言并与之交互。与人类通过环境交互和情境接触自然习得语言能力不同 [4],机器必须经过大规模数据驱动的训练才能获得类似能力。这一过程构成了重大的研究挑战:要让机器理解和生成人类语言,同时进行自然且符合语境的对话,不仅需要庞大的计算资源,还需要完善的模型开发方法 [5, 6]。
随着 GPT-3 [7]、InstructGPT [8]、GPT-4 [9] 等大型语言模型(LLMs)的出现,语言模型的发展进入了变革性阶段。这类模型凭借庞大的参数规模和先进的学习能力,能够捕捉海量数据中的复杂语言结构、语境关系和细微模式。这使得大型语言模型不仅能预测后续词语,还能在翻译、问答、摘要等各类任务中生成连贯且符合语境的文本。大型语言模型的发展引发了学术界的广泛关注 [5, 6, 10],其研究过程主要分为两个阶段:预训练与后训练。
1.1 预训练
预训练的概念源于计算机视觉(CV)任务中的迁移学习 [10],其核心目标是利用大规模数据集训练一个通用模型,以便轻松微调适配各类下游应用。预训练的一大显著优势是可利用任意无标签文本语料,从而获得丰富的训练数据来源。然而,早期的静态预训练方法(如神经网络语言模型(NNLM)[11]、Word2vec [12])难以适应不同的文本语义环境,这推动了 BERT [2]、XLNet [13] 等动态预训练技术的发展。BERT 通过采用 Transformer 架构,并在大规模无标签数据集上运用自注意力机制,有效解决了静态方法的局限性。这项研究确立了 “预训练 - 微调” 的学习范式,启发了后续众多研究,催生出 GPT-2 [14]、BART [15] 等多种不同架构的模型。
1.2 后训练
后训练指模型完成预训练后,为适配特定任务或满足用户需求而采用的技术与方法。随着拥有 1750 亿参数的 GPT-3 [7] 发布,后训练领域的关注度与创新成果显著增长。为提升模型性能,研究者提出了多种方法:包括利用带标签数据集或特定任务数据调整模型参数的微调技术 [16, 17];优化模型以更好契合用户偏好的对齐策略 [18, 19, 20];使模型融入领域专属知识的知识适配技术 [21, 22];以及增强模型逻辑推理与决策能力的推理改进方法 [23, 24]。这些技术统称为后训练语言模型(PoLMs),催生出 GPT-4 [9]、LLaMA-3 [25]、Gemini-2.0 [26]、Claude-3.5 [27] 等模型,推动大型语言模型能力实现重大突破。然而,后训练模型往往需要重新训练或大幅调整参数才能适配新任务,因此后训练语言模型的开发仍是当前的活跃研究方向。
如前所述,预训练语言模型(PLMs)的核心目标是提供通用知识与能力,而后训练语言模型(PoLMs)则专注于将这些模型适配到特定任务与需求中。最新的大型语言模型 DeepSeek-R1 [28] 便是这种适配的典型案例,它体现了后训练语言模型在增强推理能力、契合用户偏好、提升跨领域适配性等方面的演进 [29]。此外,开源大型语言模型(如 LLaMA [30]、Gemma [31]、Nemotron [32])和领域专属大规模数据集(如 PromptSource [33]、Flan [34])的日益普及,正推动学术界研究者与产业界从业者纷纷投入后训练语言模型的开发。这一趋势也凸显了 “定制化适配” 在后训练语言模型领域的重要性日益提升。
在现有文献中,预训练语言模型已得到广泛讨论与综述 [10, 35, 36, 37],而后训练语言模型的系统性综述却较为匮乏。为推动后训练技术发展,有必要深入梳理现有研究成果,明确核心挑战、研究空白与改进方向。本综述旨在通过构建后训练研究的结构化框架填补这一空白。如图 1 所示,综述涵盖后训练的多个阶段,重点关注从 ChatGPT 到 DeepSeek 所采用的后训练技术,包括微调、大型语言模型对齐、推理增强、效率优化等多种方法。图中蓝色部分特别突出了 DeepSeek 所采用的后训练方法组合,彰显了其在适配用户偏好与领域需求方面的创新策略。
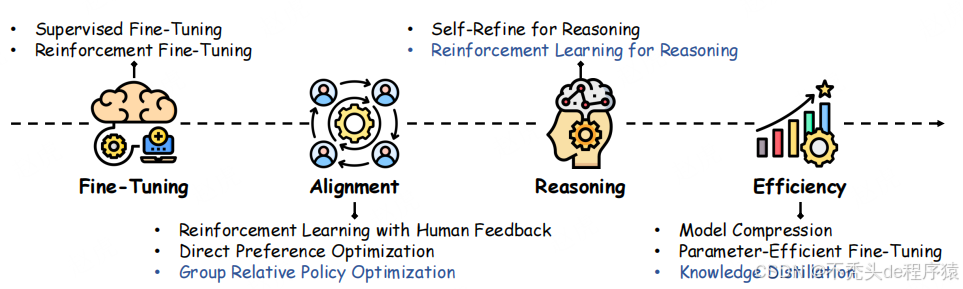
图 1:大型语言模型后训练技术演进图,展示了从早期方法到先进方法的发展历程,重点标注了 DeepSeek 模型的贡献(蓝色突出显示)。

1.3 主要贡献
本综述是首篇关于后训练语言模型(PoLMs)的全面综述,对该领域的最新进展进行了系统、结构化的梳理。以往综述多聚焦大型语言模型发展的特定方面(如偏好对齐 [38]、参数高效微调 [39]、大型语言模型基础技术 [40]),且多局限于狭窄的子主题;而本综述采用整体视角,全面回顾后训练中常用的核心技术并进行系统分类。此外,综述还研究了这些技术所依赖的数据集与实际应用场景(如图 2 所示),并指出当前存在的开放问题与未来研究方向。主要贡献如下:
- 全面的历史梳理:首次深入梳理后训练语言模型的发展历程,从 ChatGPT 最初采用的人类反馈强化学习(RLHF),到 DeepSeek-R1 创新的冷启动强化学习(cold-start RL)方法。梳理内容涵盖微调、对齐、推理、效率、集成与适配等关键技术,分析了这些技术的发展过程及面临的计算复杂度、伦理考量等挑战。通过连贯的叙事结合关键文献,为研究者提供了近年来后训练技术发展的全景视图,为该领域奠定基础参考。
- 结构化分类体系与框架:提出如图 2 所示的结构化分类体系,将后训练方法分为五大类,数据集分为七类,并将应用场景划分为专业领域、技术逻辑推理、交互理解三大领域。该框架明确了各类方法的内在关联与实际应用价值,为后训练技术发展提供系统性视角。通过清晰的分类与分析视角,降低了领域入门门槛,帮助新手与专家更好地理解相关内容,为后训练研究的复杂性梳理提供了全面指南。
- 未来研究方向:重点关注新兴趋势,尤其是 o1 [41]、DeepSeek-R1 [28] 等大型推理模型(LRMs)的崛起 —— 这类模型利用大规模强化学习突破推理能力边界。强调持续创新对进一步提升推理能力与领域适配性的关键作用。分析指出当前存在的核心挑战(如可扩展性限制、伦理对齐风险、多模态集成障碍),并提出自适应强化学习框架、公平感知优化等研究方向。这些方向旨在推动后训练技术发展,确保大型语言模型在精度与可信度上达到更高水平,以满足未来需求。
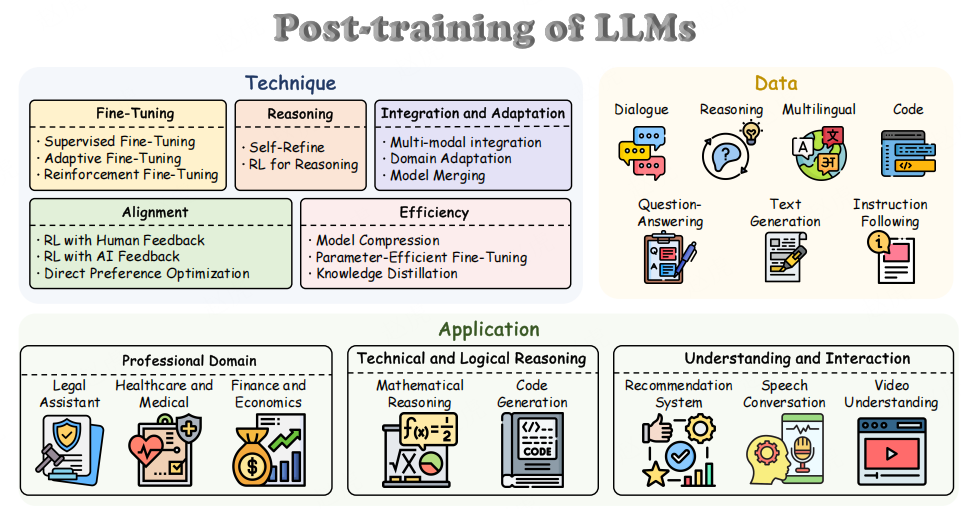
图 2:本综述涵盖的后训练技术结构概览图,展示了方法、数据集与应用场景的分类逻辑。
1.4 结构安排
本综述围绕后训练语言模型(PoLMs)展开,系统涵盖其历史演进、方法体系、数据集、应用场景与未来方向,结构安排如下:
- 第 2 章:概述后训练语言模型的发展历程;
- 第 3 章:探讨微调技术,包括 3.1 节的监督微调(SFT)与 3.3 节的强化微调(RFT);
- 第 4 章:分析对齐技术,包括 4.1 节的人类反馈强化学习(RLHF)、4.2 节的 AI 反馈强化学习(RLAIF)与 4.3 节的直接偏好优化(DPO);
- 第 5 章:聚焦推理能力增强,包括 5.1 节的自优化推理方法与 5.2 节的推理强化学习;
- 第 6 章:综述效率优化方法,包括 6.1 节的模型压缩、6.2 节的参数高效微调(PEFT)与 6.3 节的知识蒸馏;
- 第 7 章:研究集成与适配技术,涉及多模态集成、领域适配与模型融合;
- 第 8 章:回顾后训练中使用的数据集;
- 第 9 章:探索大型语言模型的应用场景;
- 第 10 章:评估当前存在的开放问题与未来研究方向;
- 第 11 章:总结全文并展望未来研究。
2. 概述
2.1 后训练语言模型的发展历程
大型语言模型的发展是自然语言处理领域的关键篇章,而后训练方法则是推动其从通用预训练架构向专用任务适配系统演进的核心动力。本节梳理后训练语言模型(PoLMs)的发展脉络,从 BERT [2]、GPT [1] 等预训练里程碑,到 o1 [41]、DeepSeek-R1 [28] 等现代模型所采用的复杂后训练范式。如图 3 所示,这一演进过程体现了从 “构建广泛语言能力” 到 “增强任务适配性、伦理对齐性、推理复杂性与多模态集成能力” 的转变,标志着大型语言模型能力的革命性提升。
现代后训练语言模型的发展起点可追溯至 2018 年的预训练革命 ——BERT [2] 与 GPT [1] 的发布重新定义了自然语言处理的基准。BERT 采用双向自编码框架,结合 Transformer 架构与自注意力机制,在问答等任务中精准捕捉语境依赖关系;而 GPT 的自回归设计则注重生成连贯性,为文本生成奠定基础。这些模型确立了 “预训练 - 微调” 范式,2019 年 T5 [42] 进一步完善该范式,通过 “文本到文本” 框架统一各类任务,推动多任务学习发展,为后训练技术进步奠定坚实基础。
2020 年起,后训练语言模型领域开始发生显著变革,核心驱动力是 “利用有限数据高效适配预训练模型到多任务” 的需求。早期创新如前缀微调(prefix-tuning)[43]、提示微调(prompt-tuning)[44] 引入了轻量化适配策略 —— 通过修改模型输入而非重新训练整个架构,在节省计算资源的同时扩大了应用范围。同一时期,领域还出现了向 “以用户为中心优化” 的关键转变:2021 年提出的人类反馈强化学习(RLHF)[45] 利用人类评估使模型输出契合主观偏好,提升了对话场景中的实用价值。2022 年,RLHF 技术因采用近端策略优化(PPO)[46] 进一步成熟,提升了对齐稳定性并减少了对噪声反馈的过拟合。2022 年末 ChatGPT [9] 的发布集中体现了这些进展,展现了 RLHF 在打造 “响应用户需求、与用户对齐” 的大型语言模型方面的变革潜力,也引发了后训练语言模型研究的热潮。与此同时,思维链(CoT)提示 [47] 作为推理增强策略应运而生,促使模型在复杂任务中明确中间推理步骤,尤其在逻辑推理与问题解决领域提升了结果的透明度与准确性。
2022 至 2024 年间,后训练语言模型朝着 “领域专用化、伦理稳健性、多模态集成” 的方向多元化发展,体现了对大型语言模型优化的精细化思路。领域适配技术(如检索增强生成(RAG)[48])通过集成外部知识库,无需全量重新训练即可为专业领域生成富含语境的输出 —— 这对需要最新信息的专业应用而言至关重要。伦理对齐方面的研究力度也不断加大,2023 年提出的直接偏好优化(DPO)[49] 通过直接优化模型输出以契合人类偏好,省去中间奖励建模环节,提升了效率与稳健性。同时,多模态能力的探索也取得进展:PaLM-E [50]、Flamingo [51] 率先实现视觉 - 语言集成,BLIP-2 [52]、LLaVA [53] 则将这类能力拓展到医学影像等更广泛领域。效率优化创新与上述发展并行,尤其体现在混合专家(MoE)架构中:谷歌 2022 年发布的 Switch-C Transformer [54] 实现了 2048 个专家间的稀疏激活,参数规模达 1.6 万亿;Mixtral [55] 进一步优化该范式,在可扩展性与性能间取得平衡。这一时期的推理增强技术(如自对弈 [56]、结合思维链的蒙特卡洛树搜索(MCTS)[57])通过模拟迭代推理路径,进一步提升了大型语言模型的决策能力,为专注高级推理的模型奠定基础。
混合专家(MoE)模型的兴起带来了重大架构突破 —— 这类模型不同于传统密集型架构,通过动态激活部分参数子集,在支持庞大参数规模的同时优化计算效率。2022 年谷歌 Switch-C Transformer [54] 率先采用该范式,将 1.6 万亿参数分布在 2048 个专家中,在平衡资源需求与性能提升方面实现了突破。后续模型(如 Mixtral [55]、DeepSeek V2.5 [58])进一步优化该框架 ——DeepSeek V2.5 总参数达 2360 亿,160 个专家中仅激活 210 亿参数 —— 在 LMSYS 基准测试中取得当前最优结果,证明稀疏 MoE 架构在可扩展性与有效性上均可与密集型模型媲美。这些进展凸显了后训练语言模型向 “效率导向” 的转变,使大型语言模型能以更低计算开销处理复杂任务,为扩大其实际应用范围奠定关键基础。
2025 年,DeepSeek-R1 [28] 成为后训练语言模型创新的里程碑 —— 它摆脱了对传统监督微调(SFT)的依赖,采用思维链(CoT)推理与探索性强化学习策略。以 DeepSeek-R1-Zero 为例,该模型集成自验证、反思与扩展思维链生成功能,在开放研究范式中验证了强化学习驱动的推理激励机制,并引入蒸馏技术 [28] 将复杂推理模式从大型架构迁移到小型架构。这种方法不仅在性能上优于单独的强化学习训练,还开创了大型语言模型 “推理中心化” 的可扩展范式,有望解决后训练方法中长期存在的计算效率与任务适配性挑战。
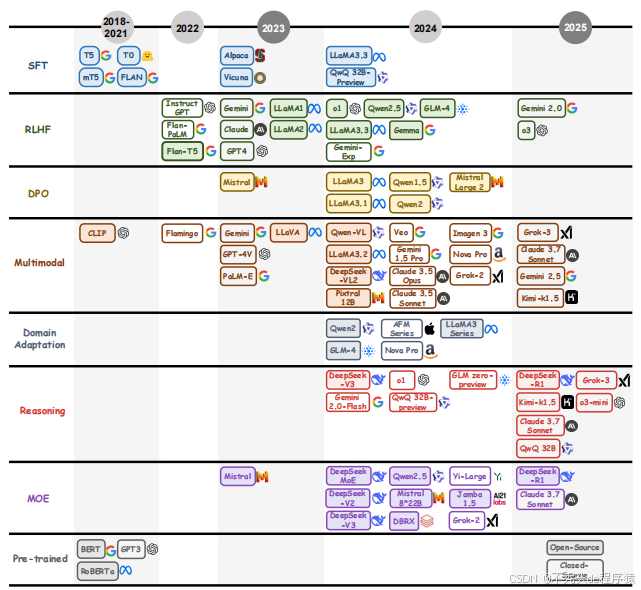
图 3:大型语言模型后训练技术发展时间线(2018-2025),展示了发展历程中的关键里程碑。
2.2 后训练语言模型的公式基础
2.2.1 策略优化原理
近端策略优化(PPO)算法 [46] 是强化学习的核心技术,尤其适用于人类反馈强化学习(RLHF)[45] 等场景 —— 在这类场景中,维持稳定性与效率至关重要。PPO 通过限制策略更新幅度,确保模型行为变化平缓可控,避免性能出现灾难性下降。这一点在大型语言模型微调中尤为关键,因为剧烈的策略更新可能导致模型输出出现不良或不可预测的情况。
定义:在 PPO 框架中,状态st ∈ S
表示t时刻的环境状态,包含模型决策所需的所有相关信息;动作at ∈ A(st)
表示模型在状态st下做出的选择,是模型决策序列的一部分。执行动作后,智能体获得奖励rt ∈ R —— 这是环境给出的反馈,用于标识动作的成功或失败。优势函数Aπ(s, a)用于衡量在当前策略π
下,在状态s中选择动作a相较于该状态下平均动作期望价值的优势程度,其形式化定义为动作价值函数Qπ(s, a)与状态价值函数Vπ(s)的差值:

其中,Qπ(s, a)
表示在状态s下选择动作a并遵循策略π
时的期望累积奖励;
Vπ(s)表示从状态s开始遵循策略π
时的期望累积奖励。两个函数均考虑了未来奖励,并通过折扣因子γ
进行折扣计算。
策略更新:PPO 算法基于优势函数对策略πθ
进行增量更新,更新过程采用裁剪目标函数:
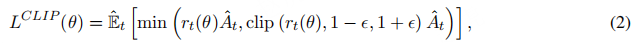
其中,rt(θ)
表示当前策略πθ
与旧策略πθold
下选择动作at的概率比值,定义为:
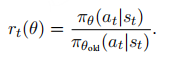
Aˆt表示t时刻的估计优势值;裁剪函数clip(rt(θ), 1−ϵ, 1+ϵ)将策略更新限制在由超参数ϵ
控制的安全范围内。这种裁剪机制确保更新不会与先前策略偏差过大,从而维持训练稳定性。
价值函数更新:价值函数Vϕ
用于估计在策略πθ
下,从给定状态st出发的期望累积奖励。为确保价值函数估计准确,需通过最小化预测值与实际奖励的均方误差进行优化:
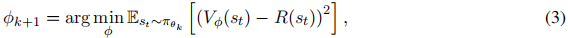
其中,R(st)
表示从状态st获得的实际累积奖励;Vϕ(st)
表示当前策略下的估计价值。优化目标是调整参数ϕ
,最小化预测奖励与实际奖励的差异,提升价值函数的准确性。
2.2.2 人类反馈强化学习(RLHF)原理
人类反馈强化学习(RLHF)是通过在学习过程中融入人类生成的反馈,使模型与人类偏好对齐的关键方法。该方法引入明确捕捉人类输入的奖励函数,帮助模型更好地适配用户偏好与实际应用场景。
定义:在 RLHF 中,语言模型ρ
对词汇表Σ
中的 token 序列生成概率分布。模型ρ
从输入空间X = Σ≤m
中生成 token 序列x0, x1, . . . , xn−1
,其中每个 token 的生成均依赖于前序 token。模型输出由以下条件概率分布定义:
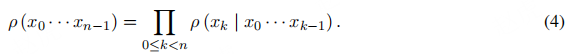
模型ρ的训练任务由输入空间X、输入空间上的数据分布D以及输出空间Y = Σ≤n 定义。例如,在文本摘要任务中 [16],研究人员使用 RLHF 训练 GPT-2 模型 [14],任务目标是基于 CNN/DailyMail [59]、TL;DR [60] 等数据集预测文本摘要。
目标函数:策略π
是与原始模型ρ
结构相同的语言模型,初始时策略π
与ρ
一致。训练目标是通过优化策略,最大化输入 - 输出对(x, y)的期望奖励R(x, y)。奖励函数R(x, y): X乘以Y → R
为每个输入 - 输出对分配一个标量值,最优策略π∗通过求解以下最大化问题获得:
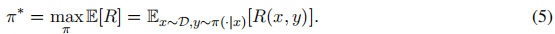
该目标函数对应标准强化学习问题:模型通过与环境交互,在人类反馈引导下学习最大化期望奖励。
2.2.3 直接偏好优化(DPO)原理
直接偏好优化(DPO)在 RLHF 基础上发展而来,通过人类偏好(通常以成对比较形式呈现)直接优化模型输出。DPO 无需传统奖励函数,转而通过最大化基于偏好的奖励来优化模型行为。
目标函数:首先采用与先前方法 [61, 62, 63] 相同的强化学习目标,引入通用奖励函数r。KL 约束奖励最大化目标的最优解形式为玻尔兹曼分布 [61, 62, 63]:
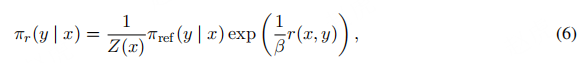
其中,Z(x)为配分函数,确保输出在所有可能动作上满足概率归一化;即使采用真实奖励r∗的最大似然估计rϕ
,也可通过近似配分函数Z(x)简化优化过程。这种形式使模型能基于人类反馈直接调整策略,提升偏好优化效率。
偏好模型:采用布拉德利 - 特里模型(Bradley-Terry model)建模两个输出y1与y2之间的偏好关系,最优策略π*满足以下偏好模型:
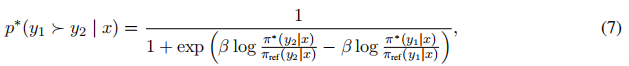
其中,p∗(y1 ≻ y2 | x)表示给定输入x时,人类偏好输出y1而非y2的概率。该方法将人类偏好有效融入模型优化过程。
2.2.4 组相对策略优化(GRPO)原理
组相对策略优化(GRPO)算法是强化学习中近端策略优化(PPO)的变体,首次在 DeepSeek 此前的研究《DeepSeekMath:突破开源语言模型的数学推理极限》[64] 中提出。GRPO 省去了评论者模型(critic model),转而通过组得分估计基线,与 PPO 相比显著降低了训练资源消耗。
定义:GRPO 与 PPO 的核心差异在于优势函数的计算方式。如 2.2.1 节公式(1)所示,PPO 中优势函数Aπ(s, a)的值由 Q 值与 V 值的差值推导得出。
目标函数:具体而言,对于每个问题q,GRPO 从旧策略πθold
中采样一组输出{o1, o2, . . . , oG}
,随后通过最大化以下目标优化策略模型:
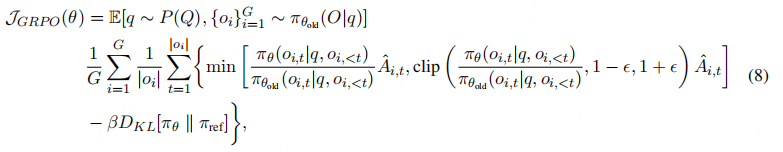
其中,ϵ与β为超参数;Aˆi,t为仅基于每组内输出的相对奖励计算得出的优势值,具体计算方式将在 5.2 节详细说明。
3. 用于微调的后训练语言模型
微调是将预训练大型语言模型适配到专用任务的核心技术,通过针对性调整参数优化模型能力。该过程利用带标签或任务专属数据集提升性能,填补通用预训练与领域特定需求之间的差距。本章将探讨三种主要微调范式:3.1 节的监督微调(通过带注释数据集提升任务专属准确性)、3.2 节的自适应微调(通过指令微调与基于提示的方法定制模型行为)、3.3 节的强化微调(融合强化学习,基于奖励信号迭代优化输出,通过动态交互实现持续改进)。
3.1 监督微调
监督微调(SFT)[45] 利用任务专属带标签数据集,将预训练大型语言模型适配到特定任务。与依赖指令提示的指令微调不同,监督微调通过带注释数据直接调整模型参数,在保持广泛泛化能力的同时,使模型兼具精准性与语境适配性。监督微调填补了预训练阶段所习得的广泛语言知识与目标应用场景精细需求之间的差距 [36]。预训练大型语言模型通过接触海量语料习得通用语言模式,减少了微调对大规模领域专属数据的依赖。模型选择至关重要:T5 [42] 等小型模型在数据有限、资源受限的场景中表现出色;而 GPT-4 [9] 等大型模型则凭借更强的容量,在数据丰富的复杂任务中展现优势。
3.1.1 监督微调数据集制备
构建高质量监督微调数据集是确保微调成功的关键,这一过程涉及多个方面。
监督微调数据集构建:监督微调数据集通常采用D = {(Ik, Xk)} k=1到N的结构,其中Ik为指令,Xk为对应实例。这种配对方式使大型语言模型能够识别任务专属模式并生成相关输出。Self-Instruct [86] 等方法通过合成新的指令 - 输出对丰富数据集多样性,并利用 ROUGE-L [87] 等指标过滤重复内容,维持数据多样性。
监督微调数据集筛选:筛选操作确保最终数据集中仅保留高质量的指令 - 实例对。通过筛选函数r(·)
评估每个配对(Ik, Xk)的质量,得到精选子集D’:
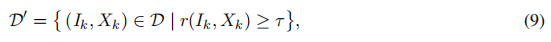
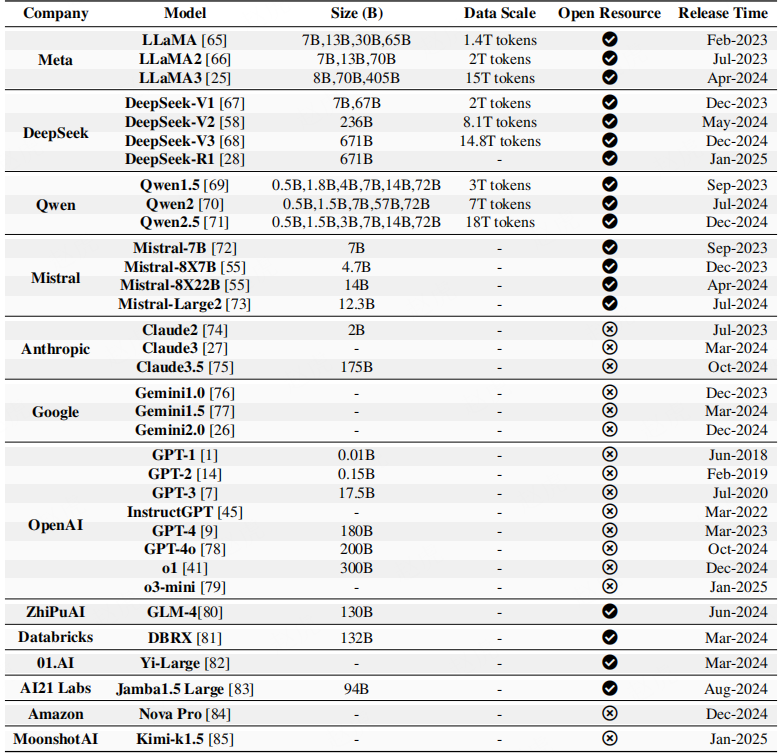
表 1:各机构发布的预训练大型语言模型汇总(2018–2025 年)
本表详细列出了来自 Meta、深度求索(DeepSeek)、OpenAI 等机构的核心模型信息,包括模型的参数规模、训练数据量(已公开数据)、开源状态及发布时间。其中,开源状态标注规则如下:“¥” 表示该模型对研究社区公开可获取(开源模型),“q” 表示该模型为闭源专有模型。
其中τ 是用户定义的质量阈值。例如,指令遵循难度(Instruction Following Difficulty, IFD)指标 [88] 可量化给定指令引导模型生成预期响应的有效性。IFD 函数的表达式如下:
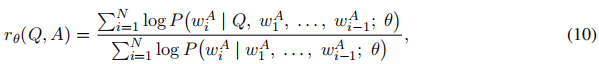
式中,Q表示指令,A表示预期响应,θ
表示模型的可学习参数。该指标通过对比 “存在指令” 与 “不存在指令” 两种情况下模型生成响应的概率,为 “指令对响应生成的促进效果” 提供了归一化度量。未达到所选 IFD 阈值的 “指令 - 实例” 对会被剔除,最终得到精炼后的数据集D’。
监督微调(SFT)数据集评估
监督微调数据集的评估过程需选取高质量子集Deval
作为模型性能的基准。该子集可从已筛选的数据集D’中采样获得,也可从独立数据部分中提取,以确保评估的公正性。传统监督微调评估方法(如 Few-Shot GPT [7]、微调策略 [89])资源消耗较大,而指令挖掘(Instruction Mining)[90] 则提供了一种更高效的替代方案。指令挖掘利用线性质量规则与一组度量指标(如响应长度、奖励模型平均得分 [65])来衡量数据集质量,并评估这些指标与数据集整体质量之间的相关性。
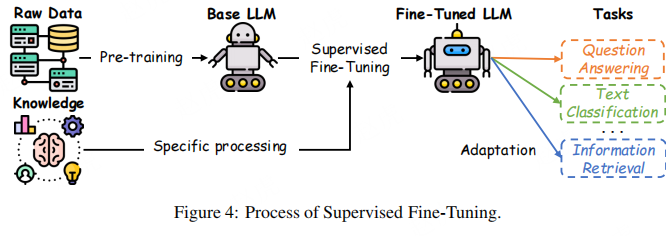
图 4:监督微调流程
3.1.2 监督微调(SFT)流程
如图 4 所示,数据集准备完成后,微调流程以预训练大型语言模型(LLM)为起点 —— 该模型通常通过在大规模原始数据集上进行无监督或自监督预训练得到。预训练阶段的目标是学习适用于多种任务的通用特征表示 [36]。
随后进入微调阶段:利用任务专属的带注释数据调整模型参数,使模型与特定应用需求对齐。此阶段常用的目标函数为交叉熵损失。对于包含N个样本、C个类别的分类任务,其交叉熵损失函数表达式如下:
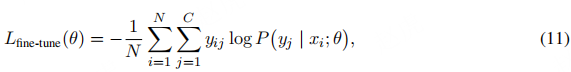
式中,yij表示第i个样本在第j类别的真实标签,P(yj|xi;θ
)表示模型预测第i个样本属于第j类别的概率。最小化该损失函数可使模型更好地与真实标签对齐,从而提升在目标任务上的性能。
典型案例为 BERT 模型 [2]:其先在 BooksCorpus、Wikipedia 等大规模通用语言语料库上进行充分预训练;微调阶段则利用任务专属数据(如用于情感分析的 IMDB 数据集 [91])优化通用特征表示,最终使 BERT 能够专精于情感分类、问答等特定任务。
3.1.3 全参数微调
全参数微调指调整预训练模型所有参数的过程,与 LoRA [92]、前缀微调(Prefix-tuning)[43] 等 “仅修改部分参数” 的参数高效方法形成对比。全参数微调通常适用于医疗、法律等对精度要求极高的领域 [93],但会产生巨大的计算开销。例如,微调一个 650 亿参数的模型可能需要超过 100GB 的 GPU 内存,这对资源受限的环境构成挑战。
为缓解此类限制,研究者提出了 LOMO [93] 等内存优化技术,可减少梯度计算与优化器状态的内存占用。模型参数的更新遵循以下规则:

式中,θt
表示第t次迭代时的模型参数,η
表示学习率,∇θL(θt)
表示损失函数的梯度。混合精度训练(Mixed Precision Training)[94]、激活检查点(Activation Checkpointing)[95] 等内存优化技术可进一步降低内存需求,使大型模型能在硬件资源有限的系统上完成微调。
GPT-3 到 InstructGPT 的微调案例
全参数微调的典型案例是从 GPT-3 到 InstructGPT 的演进 [45]:研究人员使用专为 “指令遵循任务” 设计的数据集,对 GPT-3 的全部参数进行微调。这种方法虽能实现最优性能,但因需更新所有参数,计算成本极高。
3.2 自适应微调
自适应微调通过调整预训练模型的行为,更好地满足用户特定需求并处理更广泛的任务。该方法引入额外引导信息以指导模型生成输出,为定制模型响应提供了灵活框架。自适应微调的主要方法包括指令微调(Instruction Tuning)与基于提示的微调(Prompt-based Tuning)—— 两者均通过引入任务专属引导信息,显著提升大型语言模型(LLMs)的适配能力。
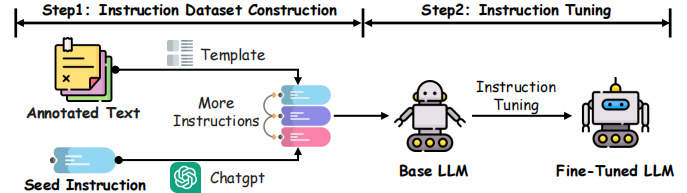
图 5:指令微调工作流程,展示大型语言模型中 “指令数据集构建” 与 “指令微调” 的通用流程
3.2.1 指令微调
指令微调 [96] 是通过在 “专门构建的指令数据集” 上微调基础大型语言模型,实现模型性能优化的技术。该方法能显著提升模型在多任务、多领域场景下的泛化能力,增强其灵活性与准确性。
如图 5 所示,指令微调的流程始于 “将现有自然语言处理(NLP)数据集(如文本分类、翻译、摘要数据集)转换为自然语言指令”—— 这些指令包含任务描述、输入示例、预期输出及演示样例。Self-Instruct [86] 等技术通过自动生成额外的 “指令 - 输出” 对,进一步丰富数据集多样性,扩大模型对不同任务的接触范围。微调过程通过调整模型参数以适配这些任务专属指令,最终得到在 “已知任务” 与 “未见过的任务” 上均能稳定发挥的大型语言模型。例如,InstructGPT [45] 与 GPT-4 [7] 通过指令微调,在各类应用场景中均显著提升了指令遵循能力。
指令微调的效果很大程度上取决于指令数据集的质量与覆盖范围:
- 高质量数据集需涵盖多种语言、多个领域及不同复杂度的任务,以确保模型具备广泛适用性 [96];
- 指令的清晰度与结构化程度对模型理解和执行任务至关重要;
- 集成演示样例(如引入思维链(Chain-of-Thought)提示 [47])可显著提升模型在复杂推理任务上的性能;
- 微调阶段需保证任务分布均衡,避免因任务覆盖失衡导致模型过拟合或性能下降 —— 可通过 “按比例采样任务”“加权损失函数” 等技术实现,确保每个任务对微调过程的贡献均衡。
因此,通过精心构建和管理指令数据集,研究者可大幅提升微调后大型语言模型的泛化能力,使其在各类任务与领域中均能表现优异 [97]。
3.2.2 前缀微调
前缀微调(Prefix-tuning)[98] 是一种参数高效的微调方法:在语言模型的每个 Transformer 层中添加一串可训练的前缀令牌(连续向量),同时固定模型核心参数。如图 6(a)所示,这些前缀向量是任务专属的,起到 “虚拟令牌嵌入” 的作用。
为优化前缀向量,研究采用了重参数化技巧:不直接优化前缀向量,而是学习一个小型多层感知机(MLP)函数,将一个较小的矩阵映射为前缀参数 —— 该方法已被证明能稳定训练过程。前缀向量优化完成后,映射函数会被丢弃,仅保留推导得到的前缀向量用于提升任务专属性能。
通过在输入序列前添加 “已学习的连续提示” 并利用分层提示,可在无需全模型微调的情况下引导模型生成任务专属输出。由于仅调整前缀参数,该方法具备更高的参数效率。在此基础上,P-Tuning v2 [99] 将分层提示向量融入 Transformer 架构,专门用于自然语言理解任务;同时结合多任务学习优化跨任务共享提示,在不同参数规模的模型上均提升了性能 [43]。显然,前缀微调在 “快速高效适配大型语言模型到特定任务” 方面潜力显著,是对灵活性与效率有要求的应用场景中的理想策略。

图 6:前缀微调与提示微调对比,展示两种方法在参数微调上的不同思路:(a)前缀微调;(b)提示微调
3.2.3 提示微调
提示微调(Prompt-tuning)[44, 100] 是一种高效适配大型语言模型的方法:通过优化输入层的可训练向量实现,无需修改模型内部参数。如图 6(b)所示,该技术在离散提示方法 [101, 102] 的基础上引入 “软提示令牌”—— 其结构既可以是无限制格式 [44],也可以是前缀格式 [100]。这些已学习的提示嵌入在输入模型前与文本输入嵌入结合,从而在固定预训练权重的同时引导模型输出。
提示微调的两种典型实现方案如下:
- P-tuning [44]:采用灵活方式组合上下文、提示与目标令牌,适用于理解类与生成类任务;通过双向 LSTM 架构增强软提示表示的学习效果。
- 标准提示微调 [100]:设计更简洁,将前缀提示添加到输入前,训练过程中仅基于任务专属监督信号更新提示嵌入。
研究表明,在许多任务上,提示微调的性能可与全参数微调媲美,且所需训练参数显著更少。但需注意,提示微调的效果与基础语言模型的容量密切相关 —— 因为它仅修改输入层的少量参数 [44]。随着技术发展,P-Tuning v2 [99] 等新方法已证明:提示微调策略可有效适配不同规模的模型,甚至能处理此前认为 “必须全微调” 的复杂任务。这些发现确立了提示微调作为传统微调 “高效替代方案” 的地位 —— 在保证性能相当的同时,降低了计算与内存成本。
3.3 强化微调
强化微调(Reinforcement Fine-Tuning, ReFT)[103] 是一种先进技术:将强化学习(RL)与监督微调(SFT)结合,提升模型解决复杂动态问题的能力。与传统监督微调(通常为每个问题提供单个思维链(CoT)标注)不同,强化微调允许模型探索多条有效推理路径,从而提升泛化能力与问题解决能力。
强化微调流程分为两个阶段:
-
监督微调预热阶段
:利用带标签数据训练模型,通过监督标注让模型掌握基础任务解决能力;
-
强化学习精炼阶段
:采用近端策略优化(PPO)[46] 等强化学习算法进一步优化模型。在此阶段,模型为每个问题生成多个思维链标注,探索不同潜在推理路径;通过对比 “模型预测答案” 与 “真实答案” 进行评估 —— 正确输出获得奖励,错误输出受到惩罚。这种迭代过程推动模型调整策略,最终优化推理方法。
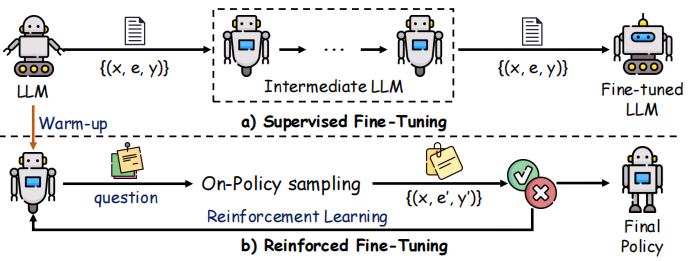
图 7:强化微调流程,展示 “监督微调预热” 与 “基于相同数据集的强化学习训练” 两个迭代阶段
如图 7 所示,强化微调流程分两阶段执行:
- 上图为监督微调阶段:模型在多个轮次内迭代训练数据,学习每个问题的正确思维链标注;
- 下图为强化微调阶段:以监督微调后的模型为起点,基于当前策略生成替代思维链e’,并将预测答案y’与真实答案y对比 —— 正确答案获正奖励,错误答案获负奖励,推动模型性能提升。随后,这些奖励信号通过强化学习用于更新模型策略,增强模型生成 “准确且多样的思维链标注” 的能力。
近期研究表明,强化微调的性能显著优于传统监督微调方法 [103];此外,结合推理时策略(如多数投票、重排序)可进一步提升性能,使模型在训练后仍能优化输出。值得注意的是,强化微调无需额外或增强训练数据,仅依赖监督微调阶段使用的现有数据集即可实现性能提升 —— 这凸显了该模型更优的泛化能力,能更高效、更充分地从可用数据中学习。
4 用于对齐的后训练语言模型
大型语言模型(LLMs)的对齐指 “引导模型输出符合人类预期与偏好”,在安全关键型或面向用户的应用场景中尤为重要。本章将探讨实现对齐的三大核心范式:
- 人类反馈强化学习(4.1 节):以人类标注数据作为奖励信号;
- AI 反馈强化学习(4.2 节):利用 AI 生成的反馈解决可扩展性问题;
- 直接偏好优化(4.3 节):直接从人类成对偏好数据中学习,无需显式奖励模型。
每种范式在追求稳健对齐的过程中,均具备独特优势、面临特定挑战并需权衡不同因素。相关方法及同类方法的简要对比总结于表 2。
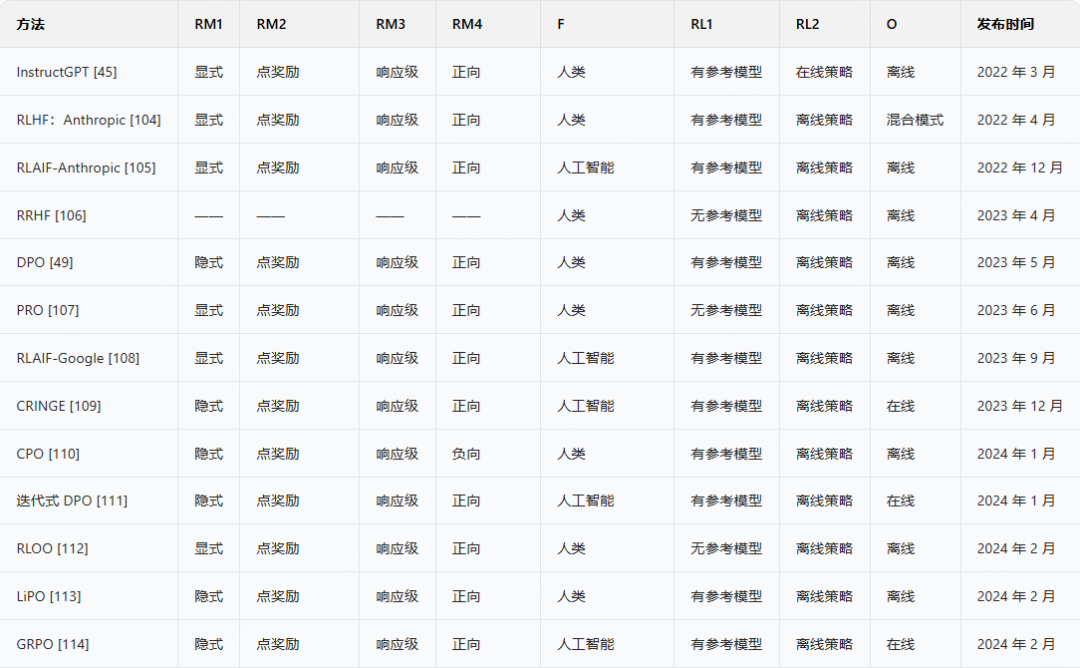
表 2:大型语言模型对齐方法对比概述(2022-2024 年)
本表从 8 个指标维度对主流对齐技术进行评估,具体指标说明如下:
- RM1(奖励模型类型:显式或隐式)
- RM2(奖励形式:点奖励或偏好概率模型)
- RM3(奖励粒度:响应级或令牌级)
- RM4(奖励极性:正向或负向)
- F(反馈类型:人类或人工智能)
- RL1(强化学习类型:有参考模型或无参考模型)
- RL2(策略更新方式:在线策略或离线策略)
- O(优化模式:在线 / 迭代式或离线 / 非迭代式)

4.1 人类反馈强化学习
监督微调(Supervised Fine-Tuning, SFT)[45] 是引导大型语言模型遵循人类指令的基础技术。然而,在纯监督场景中,标注数据的多样性与质量往往参差不齐,且监督模型捕捉 “更细微或适应性更强的人类偏好” 的能力通常有限。为解决这些不足,研究者提出了基于强化学习(RL)的微调方法。在各类强化学习方法中,人类反馈强化学习(Reinforcement Learning from Human Feedback, RLHF)[104] 是最早且最具影响力的 “基于强化学习的对齐后训练方法” 之一。
如图 8 所示,RLHF 的流程分为两步:首先,以偏好标签或奖励信号的形式收集人类反馈,并利用这些信息训练奖励模型;随后,在该奖励模型的引导下,迭代调整策略,使其更符合人类偏好。与监督微调相比,RLHF 融入了 “由偏好驱动的持续更新”,从而实现更优的对齐效果。值得注意的是,GPT-4 [9]、Claude [27]、Gemini [76] 等现代大型语言模型均受益于该机制,在指令遵循、事实一致性与用户相关性等方面均有显著提升。下文将详细探讨 RLHF 的核心组成部分,包括反馈机制、奖励建模与策略学习策略。
4.1.1 RLHF 的反馈机制
人类反馈是 RLHF 的核心,它为奖励模型提供用户偏好信息,并指导策略更新。本节采用 [124] 提出的分类体系,对常见人类反馈形式进行分类。表 3 从 “粒度(范围:片段级、段级、步级)”“参与度(参与方式:观察式、主动式、协同生成式)”“数量(实例数量:单个、多个、三元)”“抽象层次(目标:特征级、实例级)”“意图(目的:评估性、描述性、字面性)”“显式度(直接性:显式、隐式)”6 个维度,概述了各类反馈及其定义属性。每种反馈形式均对模型优化的不同方面有贡献,在可解释性、可扩展性与抗噪性上各具特点。
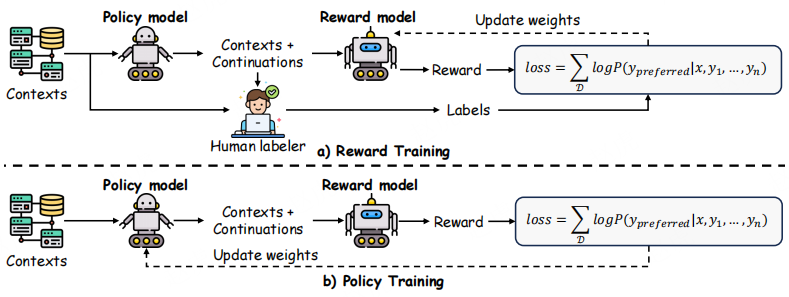
图 8:人类反馈强化学习(RLHF)工作流程,展示大型语言模型与人类偏好对齐的整体训练过程
表 3:大型语言模型后训练方法中的反馈类型分类
本表从 6 个指标维度概述了常见反馈类别及其定义属性:
- 粒度(范围:片段级、段级、步级)
- 参与度(参与方式:观察式、主动式、协同生成式)
- 数量(实例数量:单个、多个、三元)
- 抽象层次(目标:特征级、实例级)
- 意图(目的:评估性、描述性、字面性)
- 显式度(直接性:显式、隐式)
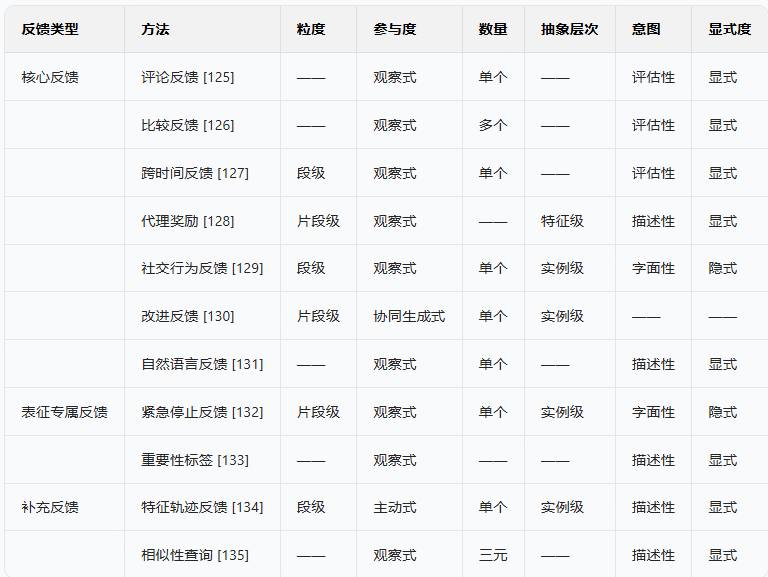
核心反馈(Primary Feedback)
此类反馈是直接塑造 RLHF 中奖励模型的关键类型,具体包括:
-
评论反馈(Critique)[125]
:聚焦人类对智能体行为的显式评估,通常通过二分类或多标签标注减少噪声干扰;
-
比较反馈(Comparisons)[126]
:允许评估者对比多个输出或轨迹 —— 选择范围越大,可获取的信号越丰富,但也可能引发因果混淆;
-
跨时间反馈(Inter-Temporal Feedback)[127]
:通过在不同时间步提供评估,优化对轨迹的评估效果;
-
代理奖励(Proxy Rewards)[128]
:融入近似奖励函数,引导模型朝向用户定义的目标优化;
-
社交行为反馈(Social Behavior)[129]
:利用面部表情等隐式线索,使智能体目标与用户情绪对齐;
-
改进反馈(Improvements)[130]
:强调人类通过实时干预实现策略的增量优化;
-
自然语言反馈(Natural Language Feedback)[131]
:借助文本信息传递偏好与改进建议。
补充反馈(Supplementary Feedback)
除核心反馈外,两类补充反馈可进一步强化奖励建模过程:
-
紧急停止反馈(Emergency Stops, E-Stops)[132]
:人类可中断智能体的轨迹以干预其行为,但无需提供替代方案。此类反馈的特点是 “参与方式隐式”,且仅聚焦于 “阻止不良行为”;
-
重要性标签(Importance Labels)[133]
:标识特定观测对实现目标的重要性,提供 “不直接改变行为” 的显式反馈。这类反馈会随场景变化,作为补充输入强化奖励模型的学习过程。
表征专属反馈(Representation-Specific Feedback)
部分反馈类型主要用于增强表征学习,而非直接塑造奖励函数:
-
特征轨迹反馈(Feature Traces)[134]
:引导人类操作者演示特定特征的单调变化,从而实现特征集的动态扩展;
-
相似性查询(Similarity Queries)[135]
:对比三组轨迹,通过轨迹空间中的成对距离指导表征学习。
通过利用这些表征专属反馈形式,RLHF 能实现对新任务与新场景更稳健的泛化。
4.1.2 RLHF 的奖励模型
真实奖励函数r(x, y)通常是未知的,因此需基于人类提供的偏好构建可学习的奖励模型rθ(x, y)
。该模型用于预测 “给定输入x时,候选输出y与人类预期的对齐程度”。为获取奖励模型rθ(x, y)
的训练数据,人类评估者会根据 “相对适用性” 对输出对进行比较或标注,模型通常通过 “基于这些比较结果的交叉熵损失” 进行训练。
为避免策略π
与初始模型ρ
偏差过大,在奖励函数中引入由超参数β
控制的惩罚项:
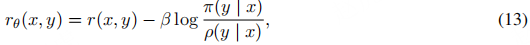
其中,π(y | x)
表示微调后策略π
在输入x下生成输出y的概率,ρ(y | x)
表示原始模型ρ
在相同输入下生成该输出的概率。这一惩罚项确保策略π
在适配人类反馈的同时,仍受限于模型ρ
所捕捉的先验知识。
奖励函数rθ(x, y)
的评估至关重要,因其直接影响学习效果与策略性能 —— 准确评估该函数有助于确定 “使模型输出与人类偏好对齐的合适奖励结构”。然而,在安全敏感领域,标准滚动方法(rollout methods)[136, 137] 与离线策略评估(off-policy evaluations)[138, 139] 可能因 “在线交互风险”“偏差”“需真实奖励” 等问题而难以实施。为应对这些挑战,常用以下两种核心方法:
距离函数(Distance Functions)
近期研究聚焦于 “考虑潜在变换(如势能塑造)的奖励评估距离函数”:
- EPIC [140]:测量不同变换下奖励函数的等价性;
- DARD [141]:优化规范化过程,确保评估基于可行的状态转移;
- 类 EPIC 距离(EPIC-like distances)[142]:通过允许 “规范化、归一化、度量函数” 的灵活性,泛化 EPIC 的方法;
- STARC [143]:保留 EPIC 的理论特性,同时提供更高的灵活性。
可视化与人类检查(Visual and Human Inspection)
另一些方法依赖 “可解释性” 与 “精选数据集” 评估学习到的奖励函数有效性:
- PRFI [144]:通过预处理步骤简化奖励函数,同时保留其等价性,提升透明度;
- CONVEXDA 与 REWARDFUSION [145]:提出专用数据集,测试奖励模型对 “提示语义变化” 的响应一致性。
这些技术共同提升了奖励函数评估的可靠性,进一步强化了大型语言模型与人类偏好的对齐效果。
4.1.3 RLHF 的策略学习
如图 9 所示,RLHF 的策略学习需在 “在线” 与 “离线” 两种场景下,通过人类反馈优化策略。
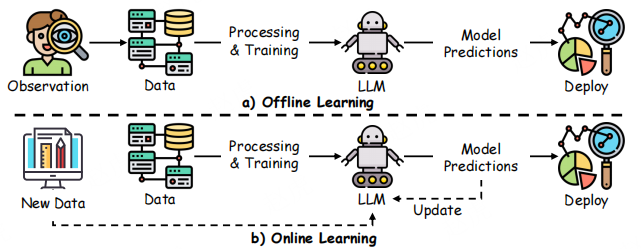
图 9:在线与离线 RLHF 对比,展示在线 RLHF 在策略执行过程中持续收集反馈,而离线 RLHF 利用已收集的轨迹数据
在线学习(Online Learning)
在在线 RLHF 中,系统会收集 “模型新生成轨迹” 的实时人类偏好:
- DPS [146]:采用贝叶斯更新管理对抗过程;
- PPS 与 PEPS [147]:融合动态规划与多臂老虎机思想,优化策略行为;
- LPbRL [148]:通过特征嵌入捕捉动态变化的奖励结构;
- PbOP [149]:融合 “转移动态” 与 “偏好信号” 的最小二乘估计;
- PARL [150]:将反馈获取视为策略优化的有机组成部分,以提升数据收集效率。
离线学习(Offline Learning)
在离线 RLHF 中,利用 “已收集的带偏好标签轨迹” 学习或优化策略:
- [151]:研究 “基于成对比较数据的策略学习中的负数极大似然估计”,确立性能边界;
- FREEHAND [152] 与 DCPPO [153]:泛化至 “未知偏好模型”,探索离线数据覆盖范围与策略泛化能力的关联;
- [154]:解决 “成对比较的玻尔兹曼模型” 中的过拟合问题;
- DCPPO [153]:进一步研究 “动态离散选择模型”,以提升反馈效率。
在线与离线学习融合(Blending Online and Offline Learning)
混合方法结合 “离线预训练” 与 “在线偏好聚合”,既利用已收集数据,又融入实时更新:
- PFERL [155]:采用两阶段方法减少人类查询次数;
- PERL [156]:探索 “乐观最小二乘策略” 以实现主动探索;
- 对抗强化学习(Dueling RL)[148] 及其扩展(如 PRPRL 中的 REGIME [152]):通过清晰划分 “数据获取” 与 “反馈收集”,减少人类标注需求,从而优化 “样本效率、标注成本、策略性能” 三者间的权衡。
4.2 人工智能反馈强化学习
人工智能反馈强化学习(Reinforcement Learning with AI Feedback, RLAIF)是对 RLHF 范式的扩展,它利用大型语言模型生成反馈信号。这种方法可补充或替代人类反馈,在 “人类标注稀缺、成本高或不一致” 的任务中,提供 “更具可扩展性、更低成本” 的偏好数据。
4.2.1 RLAIF 与 RLHF 的对比
RLHF 在大规模应用中面临的核心挑战是 “依赖人类生成的偏好标签”—— 收集、整理与标注这些标签需消耗大量资源。数据标注过程不仅耗时且成本高昂,人类评估者还可能引入不一致性,导致难以对所有模型输出进行 “大规模、一致性” 标注。这些限制严重制约了 RLHF 的可扩展性与效率。
为解决这些挑战,[105] 提出了 RLAIF 方法:通过强化学习训练模型时,结合人类反馈与人工智能生成的反馈。借助大型语言模型作为反馈来源,RLAIF 减少了对人类标注者的依赖,为传统 RLHF 提供了可行替代方案。该方法支持 “持续生成反馈”,在保留 “人类引导模型优化灵活性” 的同时,显著提升了可扩展性。
如图 10 所示,RLHF 与 RLAIF 的核心区别在于反馈来源:RLHF 依赖人类生成的偏好,而 RLAIF 利用人工智能生成的反馈指导策略更新。[157] 等实证研究表明,经人类评估者评估,RLAIF 的性能可与 RLHF 相当,甚至更优。值得注意的是,RLAIF 不仅优于传统监督微调基线,且所用的 “人工智能偏好标注模型” 与 “策略模型” 规模相当,这凸显了该方法的效率优势。
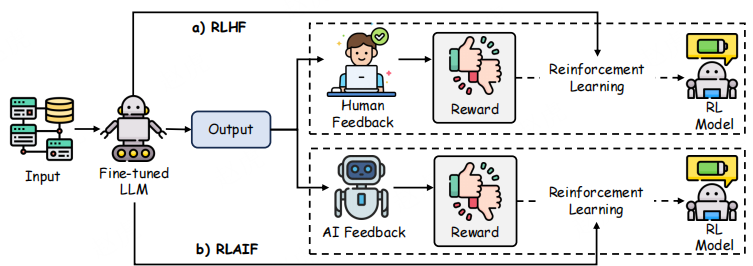
图 10:RLHF 与 RLAIF 方法对比,展示两种方法在大型语言模型偏好对齐中的不同方法论
4.2.2 RLAIF 的训练流程
RLAIF 训练流程包含多个关键阶段,通过人工智能生成的反馈迭代优化模型行为。如 [108] 所述,该流程能以 “跨任务可扩展” 的方式,实现大型语言模型输出与人类预期的对齐,具体阶段如下:
人工智能反馈收集(AI Feedback Collection)
在此阶段,人工智能系统基于预设标准生成反馈,标准可包括 “任务专属指标”“响应正确性”“模型输出适当性” 等。与需人工解读和标注的人类反馈不同,人工智能反馈可在 “广泛的模型输出范围内” 保持一致性生成 —— 这一特性使反馈循环能够持续运行,显著提升可扩展性。
奖励模型训练(Reward Model Training)
人工智能生成的反馈随后用于训练或优化奖励模型。该模型将 “输入 - 输出对” 映射为对应奖励,使模型输出与反馈所指示的预期结果对齐。与传统 RLHF “依赖人类直接反馈评估输出” 不同,RLAIF 采用人工智能生成的标签 —— 尽管这可能引入 “一致性” 与 “偏差” 相关问题,但在可扩展性与 “摆脱对人类资源依赖” 方面具有显著优势。
策略更新(Policy Update)
最后阶段基于上一步训练的奖励模型更新模型策略:采用强化学习算法调整模型参数,优化策略以最大化 “跨多任务的累积奖励”。这一过程具有迭代性,奖励模型会引导模型输出向 “更符合预期目标” 的方向优化。
RLAIF 的核心优势在于 “无需持续人类干预即可扩展反馈循环”。通过用人工智能生成的反馈替代人类反馈,RLAIF 推动大型语言模型在多任务中实现持续改进,缓解了 “人类标注瓶颈” 带来的限制。
4.3 直接偏好优化
如前文所述,RLHF [45] 通常包含三个阶段:监督微调 [17, 86]、奖励建模、强化学习(通常通过近端策略优化(PPO)[46] 实现)。尽管 RLHF 效果显著,但流程复杂且易受不稳定性影响,尤其在 “拟合奖励模型” 与 “利用奖励模型微调大型语言模型” 两个阶段 —— 难点在于 “构建能准确反映人类偏好的奖励模型”,以及 “在微调语言模型以优化估计奖励时,确保模型与原始模型偏差不过大”。
为解决这些问题,研究者提出了直接偏好优化(Direct Preference Optimization, DPO)[49]—— 一种更稳定、计算效率更高的替代方法。DPO 通过 “将奖励函数与最优策略直接关联”,简化奖励优化过程;它将 “基于人类偏好数据的奖励最大化问题” 视为 “单阶段策略训练问题”,从而避免了 “奖励模型拟合的复杂性” 与 “对布拉德利 - 特里模型(Bradley-Terry model)[158] 的依赖”。
4.3.1 DPO 的基础
RLHF 需训练奖励模型(RM)并通过强化学习微调语言模型(LM);而 DPO 通过 “直接利用人类偏好数据训练语言模型”,将奖励模型隐式融入策略本身,简化了训练流程。
KL 正则化奖励最大化目标(KL-Regularized Reward Maximization Objective)
DPO 以成熟的 KL 正则化奖励最大化框架为起点,目标函数如下:
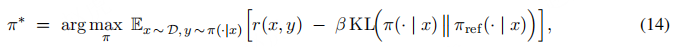
其中,r(x, y)表示奖励函数,β > 0
是控制 “与参考策略πref
接近程度” 的系数,KL(·∥·)表示 KL 散度(Kullback-Leibler divergence)。x ∼ D
表示从数据分布中采样的输入,y ∼ π(· | x)
表示从策略中采样的输出。
最优策略推导(Deriving the Optimal Policy)
在适当假设下,公式(14)的解可表示为玻尔兹曼分布形式 [61, 62, 63]:
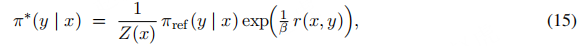
其中,配分函数(partition function)为:
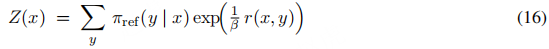
配分函数作为归一化项,确保π∗是有效的概率分布(即所有概率之和为 1)。
奖励重参数化(Reparameterizing the Reward)
对公式(15)两侧取自然对数,可建立奖励r(x, y)与最优策略π∗的关联:
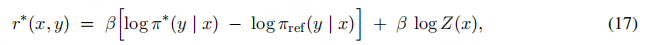
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:

04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)

05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!

06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

















 1238
1238

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









