



1. 前言
本文会从零构建一个企业级多智能体架构与代码级落地实践,不依赖 LangChain 或 CrewAI 这类高层级编排库。我们会把整套逻辑拆解为三个简单且符合逻辑的模块:
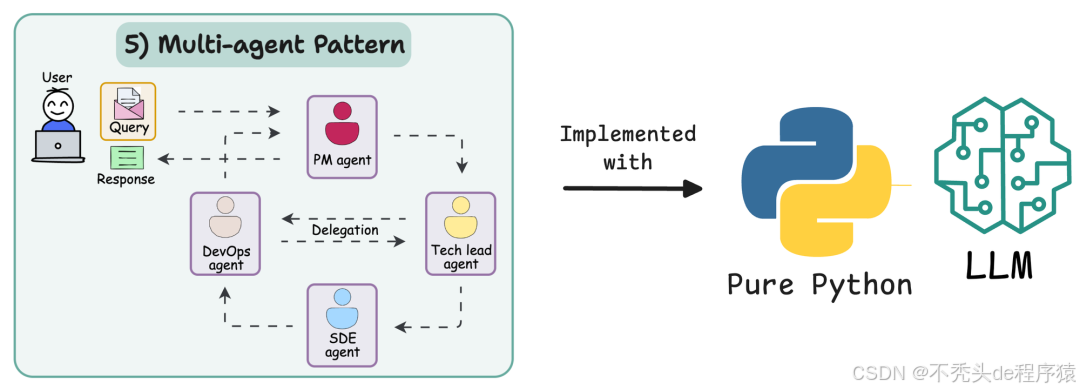
- 一个
Agent类:负责思考、行动,并维护自身的推理循环; - 一个
Tool类:智能体可调用的工具,用于与外部世界交互; - 一个
Crew类:整合多个智能体,协调它们的工作流程。
通过这种方式,我们能完全掌控智能体的行为,更易优化和排查问题。文中将使用 OpenAI 作为大模型后端,但如果您更倾向于本地部署,也可以用 Ollama(本地运行大模型的开源工具)搭配 Qwen3 等模型。
过程中,我们会讲解多智能体模式的原理、设计 “协作与工具调用交织” 的智能体循环,并实现多个可供智能体调用的工具。最终,您将得到一个基于纯 Python 和大模型后端的可运行多智能体系统,其中的智能体既能独立推理、调用工具,又能在受控流程中传递结果。
下文我们详细剖析之。
2. 为什么需要多智能体?
我们已经知道,单个大模型智能体能力很强,但面对复杂的多步骤任务时,它的处理能力会受限。而 “多智能体方案”(用一组专业智能体协作)已成为解决复杂流程的有效方式。

将大问题拆解为多个子任务,分配给专门的智能体处理,这种方式相比 “单体智能体” 有诸多优势:

2.1 开发与调试更简单
每个智能体专注于特定子任务或角色,整体系统的逻辑更清晰。比如修改某个智能体的提示词或逻辑时,不会影响整个系统 —— 其他智能体的角色是独立的(尽管一个智能体的输出可能会被另一个使用)。这种 “职责分离” 意味着:升级某个智能体(比如优化 “调研智能体”)时,不会给其他智能体带来意外影响,就像团队中替换一位专家无需重新培训所有人。
2.2 降低复杂性,减少 “幻觉”
如果让单个智能体用一个超长提示词兼顾所有工具和指令,它很容易混淆或编造信息;而多个 “专注型” 智能体更能保持方向。比如在 “代码助手” 工作流中,我们可以设置三个智能体:“规划智能体” 负责拆解任务、“编码智能体” 负责写代码、“审核智能体” 负责检查代码 —— 每个智能体的提示词和工具都针对自身职责优化,能更高效地运用领域知识或专用工具。
2.3 问题解决更高效
多智能体的 “分布式协作” 能让复杂任务(比如规划旅行)拆解为多个简单子任务:一个智能体查天气、一个找酒店、一个规划路线…… 这些专业智能体协作解决整体问题的效率,远高于单个 “全能型” 智能体。
2.4 推理过程更透明
多智能体系统天然具备 “明确的职责分工”,让推理过程更易追踪。每个智能体通常会 “清晰地思考”(通过 “思维链提示词” 输出推理过程),产生的中间结果也能被其他智能体或开发者查看。甚至,多智能体工作流会鼓励智能体互相验证输出 —— 比如一个智能体生成计划,另一个智能体评价或优化计划,形成可追溯的对话记录。这种 “审计轨迹” 能提升可解释性:您能看到每个 “专家” 的决策依据,而不是单个黑箱模型的输出。
2.5 问题定位更快速
当多智能体流程出错时,更容易定位问题根源。因为任务是分段的,您能通过详细日志判断 “哪个智能体”“哪一步” 产生了错误输出或卡住(比如查看 “调研智能体” 的搜索结果、“撰写智能体” 的草稿摘要)。这比排查 “一个做所有事的巨型智能体” 要简单得多。
2.6 符合人类团队协作逻辑
多智能体模式模仿了人类团队的运作方式,让 AI 工作流的设计更自然。在企业中,人们会分角色协作(分析师、规划师、构建者、审核者);同理,多智能体系统中,每个智能体就像团队成员,有明确职责,协调者确保它们协同工作。这种映射让设计复杂 AI 方案变得直观 —— 只需思考 “我的团队需要哪些角色的智能体”。比如 “AI 旅行 concierge 服务” 可设计为一组智能体:一个查景点、一个处理交通与天气、一个优化行程,共同响应用户需求。

3. 多智能体的内部原理
如前所述,多智能体模式将 AI 工作流设计为 “一组协作的智能体”,每个智能体有明确角色。它不是让一个智能体从头处理任务,而是让多个智能体形成流水线:每个智能体处理任务的一部分,再将结果传递给下一个,最终完成目标。
这种设计通常(但不总是)由 “协调器” 把控 —— 确保智能体按正确顺序运行、共享信息。这就像流水线或接力赛:智能体 A 完成第一步,智能体 B 用 A 的输出做第二步,依此类推直到任务完成。
每个智能体在处理子问题时具备自主性,但会通过定义好的工作流协作解决整体问题。从技术角度看,多智能体中的每个智能体,内部仍遵循 “推理 + 行动” 循环(通常基于我们之前学过的 ReAct 范式):接收输入(或上下文)→ 思考要做什么(生成 “Thought”)→ 行动(输出结果或调用工具)→ 观察结果→ 继续循环。
关键区别在于:多智能体中的每个智能体 “职责范围有限”—— 它的关注点更窄、工具集更小、目标更明确。比如一个负责 “数据库查询” 的智能体,只会思考 “如何查询数据库” 并执行查询操作,而不会操心 “如何向用户展示最终答案”(这是另一个智能体的工作)。通过限制智能体的职责,我们能让它的提示词更简洁、更有针对性,行为也更可靠。
4. 系统整体架构
为理清多智能体架构的组成部分,我们拆解一下核心模块:
4.1 智能体(Agent)
智能体是 “自主 AI 单元”(通常由大模型 + 提示词构成),能感知输入、推理(通过思维链)、执行行动以完成子任务。每个智能体都会配置特定角色,且只能访问完成该角色所需的工具或信息。
比如,我们可以创建一个 ResearchAgent(调研智能体),它能使用 “网页搜索工具”;再创建一个 SummaryAgent(摘要智能体),它能使用 “文本生成工具”。智能体会循环 “思考→行动”,直到完成自身负责的子任务。由于职责聚焦,它能遵循严格的提示格式或协议(通常由框架定义),确保行为安全、不偏离任务。
4.2 工具(Tool)
工具是智能体可调用的 “外部能力”,用于与现实世界交互或获取信息,比如网页搜索 API、计算器、数据库查询接口、发邮件函数等。在多智能体模式中,工具是智能体可执行的特定行动,且每个智能体的工具集都与自身角色相关。
例如,调研智能体可能有 “网页搜索” 工具,摘要智能体可能有 “知识库查询” 工具。智能体的 ReAct 循环会包含:选择工具→ 给工具输入参数(如搜索关键词)→ 读取工具输出(观察结果)→ 指导下一步思考。这种结构化的工具调用方式,能让智能体的推理和行动更透明、可日志化(比如我们能看到它搜索了什么关键词、得到了什么结果)。
需要注意的是,LangChain 或 CrewAI 这类框架会定义工具接口,并要求智能体遵守格式(如工具输入必须是 JSON),以确保交互可靠。
4.3 协作组(Crew)
Crew 本质是 “协调器”—— 一个(代码中的)类,负责搭建多智能体工作流、管理执行顺序。如果说每个智能体是团队成员,Crew 就是 “团队经理”,掌握整体计划。
在 “顺序流水线” 中,Crew 会把初始输入传给第一个智能体,再把它的输出传给第二个,直到最后一个智能体生成答案。它会定义智能体的运行顺序(有时还会定义每个智能体对数据的具体处理任务)。比如用 CrewAI 库时,我们可以实例化一个 Crew(agents=[智能体1, 智能体2, ...], tasks=[任务1, 任务2, ...], process=Process.sequential),然后调用 crew.kickoff() 让智能体按顺序运行。
Crew 还会处理协作细节,比如确保每个智能体拿到正确输入、收集或整合输出。在更复杂的场景中,协调器还能实现 “循环逻辑”(重复运行智能体或步骤直到满足条件)或 “分支逻辑”(根据条件选择调用哪个智能体)。
有些架构中,协调器本身也是一个智能体(常被称为 “管理智能体” 或 “监督智能体”),职责是给其他专业智能体分配任务。无论它是显式的类还是管理智能体,这个 “协调角色” 是让多个智能体形成 “统一系统” 而非 “孤立机器人集合” 的关键。
4.4 信息流转方式
多智能体流水线中,信息通常从一个智能体流向另一个。比如一个简单流程:智能体 A 收集数据→ 智能体 B 分析数据→ 智能体 C 撰写报告。Crew 会把初始查询传给智能体 A,A 用工具返回原始数据;数据传给 B,B 生成分析结果;结果再传给 C,C 输出最终报告。每个智能体只处理与自身任务相关的输入,无需关心整体任务 —— 这种 “顺序传递” 就是多智能体模式的核心:多个 “专精型” AI 智能体串联,输出依次传递,直至完成目标。
5. 从零实现多智能体系统
前面我们已经了解了多智能体系统在模块化、清晰度和可解释性上的优势。现在,我们动手从零实现一个多智能体系统,不依赖任何外部编排库(如 LangChain 或 CrewAI)。
如前所述,系统将基于三个核心抽象类构建,下面我们逐一详解每个类的原理和实现思路(您可直接下载文末代码使用):
5.1 工具类(Tool)
Tool 类会封装实际功能(如新闻搜索、文本摘要、统计计算),并以 “智能体可识别、可验证、可调用” 的方式暴露这些功能。每个工具包含:
- 解析后的函数签名(让智能体知道工具的输入要求);
- 自动输入验证和类型转换(确保智能体传入的参数合法);
- 标准化调用接口(让智能体调用工具的方式统一)。
通过这种设计,智能体无需硬编码函数调用,就能自主判断 “有哪些工具可用”“如何使用工具”。
5.2 智能体类(Agent)
Agent 类代表单个 AI 智能体,具备以下能力:
- 通过 ReAct 循环思考任务;
- 调用工具与环境交互;
- 将输出传递给下游依赖的智能体。
每个智能体都有独特的 “背景设定、任务目标、输出要求和工具集”,模块化和角色特异性极强。智能体还能定义依赖关系(如 “智能体 A 必须在智能体 B 之前运行”)。内部而言,每个智能体由 ReactAgent 包装器驱动 —— 通过语言模型处理推理循环。
5.3 协作组类(Crew)
Crew 类是 “粘合剂”,负责协调所有组件,主要管理:
- 智能体注册(将智能体加入系统);
- 依赖解析(用拓扑排序确保智能体按依赖顺序运行);
- 有序执行(根据依赖关系安排智能体的运行顺序)。
接下来的章节中,我们会详细拆解每个类的实现细节,理解它们的工作原理,以及如何组合成完整的多智能体系统。首先,我们从 Tool 类开始。
6. 详细实现:工具类(Tool)
工具是智能体与外部世界交互的 “手”,我们需要让工具满足两个核心要求:智能体能看懂怎么用、调用后能返回可靠结果。下面从设计思路到代码实现,一步步拆解 Tool 类。
6.1 设计核心:让智能体 “清晰认知工具”
智能体没办法直接 “读懂” Python 函数,所以 Tool 类需要把工具的功能、参数格式,转换成自然语言描述 + 结构化签名 —— 比如告诉智能体 “这个工具叫‘新闻搜索’,需要传入‘关键词’和‘时间范围’两个参数,能返回最近相关新闻列表”。
同时,为了避免智能体传错参数(比如把 “时间范围” 写成 “2025” 而不是 “2025-01-01 至 2025-01-10”),Tool 类还要包含输入验证逻辑,自动检查参数合法性,不合法就返回错误提示,让智能体修正后再调用。
6.2 代码实现:基础 Tool 类
我们用 Python 实现一个通用 Tool 类,后续所有具体工具(如新闻搜索、文本摘要)都可以继承它,不用重复写基础逻辑。
from pydantic import BaseModel, ValidationError
from typing import Any, Callable, Dict, Optional
class Tool:
def __init__(
self,
name: str, # 工具名称(给智能体看的,要简洁,比如"news_search")
description: str, # 工具功能描述(详细说明能做什么,比如"根据关键词搜索最近的新闻,返回标题和摘要")
func: Callable, # 工具实际执行的函数(比如调用新闻API的函数)
args_schema: Optional[BaseModel] = None # 参数校验规则(用Pydantic定义,确保参数合法)
):
self.name = name
self.description = description
self.func = func
# 用Pydantic模型定义参数格式,没传的话默认不校验
self.args_schema = args_schema if args_schema is not None else BaseModel
def get_tool_info(self) -> Dict[str, str]:
"""生成工具信息,给智能体看(告诉它工具怎么用)"""
# 提取参数描述(比如"关键词:str,必填,搜索的核心词;时间范围:str,可选,格式如'2025-01-01至2025-01-10')
args_desc = ""
if self.args_schema:
for field_name, field in self.args_schema.model_fields.items():
# 处理必填/可选、类型、描述
required = "必填" if field.is_required() else "可选"
field_type = str(field.annotation).split("[")[-1].split("]")[0] if "[" in str(field.annotation) else str(field.annotation)
field_desc = field.description or "无描述"
args_desc += f"- {field_name}:{field_type},{required},{field_desc}\n"
return {
"工具名称": self.name,
"工具功能": self.description,
"参数说明": args_desc.strip() if args_desc else "无参数"
}
def run(self, args: Dict[str, Any]) -> Dict[str, Any]:
"""执行工具:先校验参数,再调用函数,返回结果"""
try:
# 1. 校验参数(用args_schema检查格式)
validated_args = self.args_schema(** args).dict()
except ValidationError as e:
# 参数不合法,返回错误提示,让智能体修正
error_msg = f"参数错误:{e.errors()[0]['msg']},请检查参数格式(参考:{self.get_tool_info()['参数说明']})"
return {"status": "error", "result": error_msg}
try:
# 2. 调用工具函数,执行实际操作
result = self.func(** validated_args)
# 3. 返回成功结果
return {"status": "success", "result": result}
except Exception as e:
# 执行出错(比如API调用失败),返回错误信息
return {"status": "error", "result": f"工具执行失败:{str(e)}"}
有了基础 Tool 类,我们可以快速创建实际能用的工具。比如做一个 “新闻搜索工具”,调用公开的新闻 API(这里用模拟函数演示,实际项目可替换成真实 API)。
from pydantic import Field
from datetime import datetime
# 1. 定义新闻搜索工具的参数校验规则(用Pydantic)
class NewsSearchArgs(BaseModel):
keyword: str = Field(..., description="搜索关键词,比如'AI智能体'") # ...表示必填
time_range: str = Field(
default=f"{datetime.now().strftime('%Y-%m-%d')}至{datetime.now().strftime('%Y-%m-%d')}",
description="时间范围,格式如'2025-01-01至2025-01-10',默认当天"
)
max_results: int = Field(default=5, description="返回新闻数量,默认5条,最多20条")
# 2. 模拟新闻搜索函数(实际项目可替换成百度新闻API、新浪新闻API等)
def mock_news_search(keyword: str, time_range: str, max_results: int) -> list:
# 模拟返回新闻数据(真实场景会调用API获取)
return [
{
"标题": f"{keyword}最新进展:多智能体协作效率提升30%",
"摘要": "近日研究显示,多智能体系统在复杂任务处理中,效率比单智能体高30%,已应用于金融分析场景。",
"来源": "科技日报",
"发布时间": time_range.split("至")[1]
}
for _ in range(min(max_results, 20)) # 确保不超过20条
]
# 3. 创建新闻搜索工具(继承基础Tool类)
news_search_tool = Tool(
name="news_search",
description="根据关键词和时间范围,搜索最新新闻,返回标题、摘要、来源和发布时间",
func=mock_news_search,
args_schema=NewsSearchArgs # 绑定参数校验规则
)
# 测试工具:调用看看效果
test_args = {"keyword": "AI多智能体", "time_range": "2025-01-01至2025-01-10", "max_results": 3}
test_result = news_search_tool.run(test_args)
print(test_result)
# 输出(成功案例):
# {
# "status": "success",
# "result": [
# {"标题": "AI多智能体最新进展:多智能体协作效率提升30%", ...},
# {"标题": "AI多智能体最新进展:多智能体协作效率提升30%", ...},
# {"标题": "AI多智能体最新进展:多智能体协作效率提升30%", ...}
# ]
# }
# 测试参数错误:max_results传25(超过20)
error_args = {"keyword": "AI多智能体", "max_results": 25}
error_result = news_search_tool.run(error_args)
print(error_result)
# 输出(错误案例):
# {
# "status": "error",
# "result": "参数错误:确保该值小于等于20,...(参数说明)"
# }
7. 详细实现:智能体类(Agent)
智能体是 “思考 + 行动” 的主体,核心是ReAct 循环:拿到输入→思考 “该做什么”→决定 “调用工具还是直接输出”→执行→根据结果继续思考,直到完成子任务。
下面我们实现的 Agent 类,会包含 “接收上下文”“生成思考过程”“调用工具”“输出结果” 四个核心能力,并且严格绑定自己的工具集(避免越权调用)。
7.1 设计核心:让智能体 “有角色、会思考、能行动”
-
角色绑定
:每个智能体有明确的 “角色描述”(比如 “新闻调研智能体,负责收集指定主题的最新新闻”),确保思考不偏离职责;
-
工具限制
:智能体只能调用自己被分配的工具,不能用其他工具(比如 “调研智能体” 不能用 “报告生成工具”);
-
思考透明
:强制智能体输出 “思考过程”(比如 “用户需要 AI 多智能体的最新动态,我应该先调用新闻搜索工具,关键词设为‘AI 多智能体’,时间范围选最近 10 天”),方便调试和追踪;
-
循环终止
:智能体要能判断 “什么时候该停止”(比如 “已经拿到 5 条新闻,足够生成摘要,不需要再搜索了”),避免无限循环。
7.2 代码实现:基础 Agent 类
这里我们用 OpenAI 的 API 作为大模型后端(需要您自己准备 API Key),也可以替换成 Ollama 调用本地模型(修改 generate_thought 方法即可)。
import openai
from typing import List, Dict, Optional
from tool import Tool # 导入前面实现的Tool类
# 配置OpenAI API(替换成您自己的Key)
openai.api_key = "your-openai-api-key"
class Agent:
def __init__(
self,
name: str, # 智能体名称(比如"NewsResearchAgent")
role: str, # 角色描述(详细说明职责,比如"新闻调研智能体,负责根据用户需求,调用新闻搜索工具收集最新相关新闻,确保信息准确、全面")
tools: List[Tool], # 智能体可调用的工具列表
model: str = "gpt-3.5-turbo" # 使用的大模型
):
self.name = name
self.role = role
self.tools = tools # 绑定工具集(只能用这些工具)
self.model = model
# 记录历史交互(思考过程、工具调用、结果),用于上下文连贯
self.history: List[Dict[str, str]] = []
def get_available_tools_info(self) -> str:
"""生成智能体可调用的工具列表(给大模型看,告诉它有哪些工具可用)"""
tools_info = "你可调用的工具如下:\n"
for tool in self.tools:
tool_info = tool.get_tool_info()
tools_info += f"""
工具名称:{tool_info['工具名称']}
工具功能:{tool_info['工具功能']}
参数说明:{tool_info['参数说明']}
"""
return tools_info.strip()
def generate_thought(self, input_context: str) -> Dict[str, Optional[str]]:
"""生成思考过程,决定下一步行动:调用工具(返回工具名+参数)或直接输出结果"""
# 构建提示词:包含角色、历史记录、可用工具、当前输入
prompt = f"""
你是{self.name},你的角色是:{self.role}
【历史交互记录】
{[f"类型:{item['type']},内容:{item['content']}" for item in self.history] if self.history else "无"}
【你可调用的工具】
{self.get_available_tools_info()}
【当前任务】
{input_context}
【思考要求】
1. 先分析:当前任务是否需要调用工具?如果已有足够信息,直接输出结果;如果需要更多信息,调用对应的工具。
2. 若调用工具:请严格按照格式返回:{{"action": "call_tool", "tool_name": "工具名称", "tool_args": {{参数名: 参数值, ...}}}}
- 工具名称必须是【你可调用的工具】中的名称,不能编造假工具。
- 参数必须符合工具的【参数说明】,格式正确、必填参数不遗漏。
3. 若直接输出:请严格按照格式返回:{{"action": "output_result", "result": "你的最终结果"}}
4. 思考过程不用写出来,直接返回上述格式的JSON即可,不要加其他内容。
"""
# 调用大模型生成思考结果
response = openai.ChatCompletion.create(
model=self.model,
messages=[{"role": "user", "content": prompt}],
temperature=0.3 # 降低随机性,确保输出稳定
)
thought_json = response.choices[0].message["content"]
# 解析JSON(处理可能的格式问题)
try:
return eval(thought_json) # 实际项目建议用json.loads,这里为了简化用eval
except Exception as e:
# 解析失败,返回错误提示,让智能体重新思考
return {"action": "error", "error_msg": f"思考结果格式错误:{str(e)},请重新按照要求返回JSON"}
def run(self, input_context: str, max_round: int = 5) -> Dict[str, str]:
"""执行智能体:启动ReAct循环,最多循环max_round次(避免无限循环)"""
current_context = input_context
for round in range(1, max_round + 1):
print(f"=== 智能体{self.name} - 第{round}轮思考 ===")
# 1. 生成思考,决定下一步行动
thought = self.generate_thought(current_context)
print(f"思考结果:{thought}")
# 2. 处理行动
if thought["action"] == "output_result":
# 直接输出结果,循环终止
self.history.append({"type": "output", "content": thought["result"]})
return {"status": "success", "result": thought["result"], "history": self.history}
elif thought["action"] == "call_tool":
# 调用工具
tool_name = thought["tool_name"]
tool_args = thought["tool_args"]
# 找到对应的工具
target_tool = next((t for t in self.tools if t.name == tool_name), None)
if not target_tool:
error_msg = f"工具不存在:{tool_name},请检查工具名称"
self.history.append({"type": "error", "content": error_msg})
current_context = f"上一轮调用工具失败:{error_msg},请重新处理当前任务:{input_context}"
continue
# 执行工具
tool_result = target_tool.run(tool_args)
self.history.append({
"type": "tool_call",
"content": f"调用工具{tool_name},参数:{tool_args},结果:{tool_result}"
})
print(f"工具执行结果:{tool_result}")
# 处理工具结果
if tool_result["status"] == "success":
# 工具调用成功,更新上下文(把工具结果加入任务)
current_context = f"上一轮调用工具{tool_name}获取到信息:{tool_result['result']},请继续处理原任务:{input_context}"
else:
# 工具调用失败,更新上下文(让智能体修正)
current_context = f"上一轮调用工具{tool_name}失败:{tool_result['result']},请修正参数或选择其他工具,继续处理原任务:{input_context}"
elif thought["action"] == "error":
# 思考错误,更新上下文(让智能体重新思考)
self.history.append({"type": "error", "content": thought["error_msg"]})
current_context = f"上一轮思考出错:{thought['error_msg']},请重新处理当前任务:{input_context}"
else:
# 未知行动,终止循环
error_msg = f"未知行动类型:{thought['action']}"
self.history.append({"type": "error", "content": error_msg})
return {"status": "error", "result": error_msg, "history": self.history}
# 循环次数用尽,仍未输出结果
error_msg = f"超过最大循环次数({max_round}轮),未完成任务"
self.history.append({"type": "error", "content": error_msg})
return {"status": "error", "result": error_msg, "history": self.history}
# 测试智能体:创建新闻调研智能体,调用新闻搜索工具
if __name__ == "__main__":
# 1. 准备工具(用前面创建的新闻搜索工具)
tools = [news_search_tool]
# 2. 创建智能体
research_agent = Agent(
name="NewsResearchAgent",
role="新闻调研智能体:负责根据用户需求,调用新闻搜索工具收集最新相关新闻,整理成清晰的列表(包含标题、摘要、来源),不需要额外添加分析内容",
tools=tools
)
# 3. 运行智能体:任务是“收集2025年1月1日至2025年1月10日关于‘AI多智能体’的3条最新新闻”
result = research_agent.run(
input_context="收集2025年1月1日至2025年1月10日关于‘AI多智能体’的3条最新新闻,整理成列表",
max_round=3
)
# 4. 输出结果
print("\n=== 最终结果 ===")
print(result)
8. 详细实现:协作组类(Crew)
有了工具和智能体,还需要一个 “协调者” 来管理它们的依赖关系和运行顺序 —— 这就是 Crew 类的作用。比如 “先让调研智能体收集新闻,再让摘要智能体生成总结”,Crew 会确保这个顺序不混乱,还能处理 “某个智能体失败后是否重试” 等逻辑。
8.1 设计核心:让多智能体 “有序协作”
-
依赖管理
:支持智能体间的依赖设置(如 “摘要智能体” 依赖 “调研智能体” 的输出),用拓扑排序确保先运行被依赖的智能体;
-
顺序执行
:按依赖关系依次运行智能体,把前一个智能体的输出作为后一个的输入;
-
错误处理
:某个智能体失败时,可选择 “终止流程” 或 “跳过该智能体”(根据任务重要性配置);
-
结果汇总
:收集所有智能体的输出,生成最终的整体结果,方便用户查看。
8.2 代码实现:基础 Crew 类
from typing import List, Dict, Optional, Tuple
from agent import Agent # 导入前面实现的Agent类
from tool import Tool # 导入Tool类(用于类型提示)
class Crew:
def __init__(
self,
agents: List[Agent], # 协作组中的所有智能体
dependencies: Optional[Dict[str, List[str]]] = None, # 依赖关系:{智能体名称: [依赖的智能体名称列表]}
max_retries: int = 2 # 智能体失败后的最大重试次数
):
self.agents = {agent.name: agent for agent in agents} # 用字典存储,方便按名称查找
self.dependencies = dependencies or {} # 默认无依赖
self.max_retries = max_retries
# 验证依赖关系(确保依赖的智能体存在)
self._validate_dependencies()
def _validate_dependencies(self) -> None:
"""验证依赖关系:确保所有依赖的智能体都在协作组中"""
all_agent_names = set(self.agents.keys())
for agent_name, dep_names in self.dependencies.items():
# 检查当前智能体是否存在
if agent_name not in all_agent_names:
raise ValueError(f"智能体{agent_name}不存在于协作组中")
# 检查依赖的智能体是否存在
for dep_name in dep_names:
if dep_name not in all_agent_names:
raise ValueError(f"智能体{agent_name}依赖的{dep_name}不存在于协作组中")
def _topological_sort(self) -> List[str]:
"""拓扑排序:根据依赖关系,生成智能体的运行顺序"""
# 1. 初始化入度(每个智能体依赖的数量)和邻接表
in_degree = {agent_name: 0 for agent_name in self.agents.keys()}
adj = {agent_name: [] for agent_name in self.agents.keys()}
# 2. 填充入度和邻接表
for agent_name, dep_names in self.dependencies.items():
in_degree[agent_name] = len(dep_names)
for dep_name in dep_names:
adj[dep_name].append(agent_name)
# 3. 拓扑排序(Kahn算法)
from collections import deque
queue = deque([name for name, cnt in in_degree.items() if cnt == 0])
sorted_order = []
while queue:
current = queue.popleft()
sorted_order.append(current)
# 减少依赖当前智能体的入度
for neighbor in adj[current]:
in_degree[neighbor] -= 1
if in_degree[neighbor] == 0:
queue.append(neighbor)
# 4. 检查是否有循环依赖(如果排序结果长度不等于智能体数量,说明有循环)
if len(sorted_order) != len(self.agents):
raise ValueError("智能体间存在循环依赖,无法生成运行顺序")
return sorted_order
def run(
self,
initial_input: str, # 整个协作组的初始输入(如用户的原始需求)
skip_failed_agents: bool = False # 智能体失败时是否跳过(True=跳过,False=终止)
) -> Dict[str, Any]:
"""运行协作组:按拓扑排序执行智能体,传递输入,收集结果"""
# 1. 生成智能体运行顺序
try:
run_order = self._topological_sort()
print(f"=== 协作组运行顺序 ===")
for i, agent_name in enumerate(run_order, 1):
print(f"{i}. {agent_name}")
except ValueError as e:
return {"status": "error", "result": f"协作组初始化失败:{str(e)}"}
# 2. 存储每个智能体的输出(用于传递给依赖它的智能体)
agent_outputs: Dict[str, str] = {}
# 存储整体运行日志
global_history: List[Dict[str, str]] = []
# 3. 按顺序运行每个智能体
for agent_name in run_order:
agent = self.agents[agent_name]
print(f"\n=== 开始运行智能体:{agent_name} ===")
# 3.1 准备输入:如果有依赖,把依赖智能体的输出加入输入
current_input = initial_input
if agent_name in self.dependencies:
dep_outputs = "\n".join([
f"【{dep_name}的输出】:{agent_outputs[dep_name]}"
for dep_name in self.dependencies[agent_name]
])
current_input = f"原始需求:{initial_input}\n\n依赖智能体的输出:\n{dep_outputs}\n\n请基于以上信息,完成你的任务:{agent.role.split(':')[-1]}"
# 3.2 运行智能体(支持重试)
retry_count = 0
agent_result = None
while retry_count < self.max_retries:
agent_result = agent.run(input_context=current_input)
if agent_result["status"] == "success":
print(f"智能体{agent_name}运行成功")
break
else:
retry_count += 1
print(f"智能体{agent_name}运行失败(第{retry_count}次重试):{agent_result['result']}")
# 3.3 处理智能体最终结果
if agent_result["status"] != "success":
error_msg = f"智能体{agent_name}运行失败(已重试{self.max_retries}次):{agent_result['result']}"
global_history.append({"type": "agent_failed", "content": error_msg})
if not skip_failed_agents:
return {"status": "error", "result": error_msg, "global_history": global_history}
else:
print(f"跳过失败的智能体:{agent_name}")
agent_outputs[agent_name] = f"该智能体运行失败,无输出:{error_msg}"
else:
# 运行成功,存储输出和日志
agent_outputs[agent_name] = agent_result["result"]
global_history.append({
"type": "agent_success",
"content": f"智能体{agent_name}运行成功,输出:{agent_result['result']}",
"agent_history": agent_result["history"]
})
# 4. 生成最终结果(汇总所有智能体输出)
final_result = "\n\n".join([
f"【{agent_name}的输出】:{output}"
for agent_name, output in agent_outputs.items()
])
return {
"status": "success",
"final_result": final_result,
"agent_outputs": agent_outputs,
"global_history": global_history,
"run_order": run_order
}
# 测试协作组:创建“调研+摘要”双智能体协作
if __name__ == "__main__":
# 1. 先创建所需工具
## 1.1 新闻搜索工具(复用前面实现的news_search_tool)
## 1.2 文本摘要工具(新创建,用于总结新闻)
from pydantic import Field
# 摘要工具的参数校验
class SummaryArgs(BaseModel):
text: str = Field(..., description="需要摘要的文本,比如多条新闻的集合")
summary_length: str = Field(default="中等", description="摘要长度:短(100字内)、中等(200-300字)、长(500字以上)")
# 模拟文本摘要函数
def mock_text_summary(text: str, summary_length: str) -> str:
length_map = {"短": 100, "中等": 250, "长": 550}
max_len = length_map.get(summary_length, 250)
# 模拟摘要逻辑:提取关键词+简化句子
summary = f"【{summary_length}摘要】:基于文本内容,核心信息包括:AI多智能体系统效率提升、金融场景应用、新闻来源为科技日报等。{text[:max_len-100]}..."
return summary[:max_len] # 确保不超过长度限制
# 创建摘要工具
summary_tool = Tool(
name="text_summary",
description="将输入的长文本(如多条新闻)总结成指定长度的摘要,保留核心信息",
func=mock_text_summary,
args_schema=SummaryArgs
)
# 2. 创建两个智能体
## 2.1 新闻调研智能体(复用前面的research_agent)
research_agent = Agent(
name="NewsResearchAgent",
role="新闻调研智能体:负责根据用户需求,调用新闻搜索工具收集最新相关新闻,整理成包含“标题、摘要、来源”的列表,不需要额外分析",
tools=[news_search_tool]
)
## 2.2 摘要智能体(新创建,依赖调研智能体的输出)
summary_agent = Agent(
name="TextSummaryAgent",
role="文本摘要智能体:负责将输入的新闻列表总结成“中等长度”的摘要,突出核心进展和关键信息,不需要保留原始列表格式",
tools=[summary_tool]
)
# 3. 创建协作组:摘要智能体依赖调研智能体
crew = Crew(
agents=[research_agent, summary_agent],
dependencies={"TextSummaryAgent": ["NewsResearchAgent"]}, # 摘要智能体依赖调研智能体
max_retries=1
)
# 4. 运行协作组:初始需求是“收集AI多智能体的最新新闻并总结”
crew_result = crew.run(
initial_input="收集2025年1月1日至2025年1月10日关于‘AI多智能体’的3条最新新闻,并将这些新闻总结成中等长度的摘要",
skip_failed_agents=False
)
# 5. 输出最终结果
print("\n=== 协作组最终结果 ===")
if crew_result["status"] == "success":
print(crew_result["final_result"])
else:
print(f"协作组运行失败:{crew_result['result']}")
9. 完整实战:多智能体系统运行效果
我们以 “收集 AI 多智能体新闻并总结” 为例,看看整个系统的运行流程和输出结果:
9.1 运行流程(按协作组顺序)
- 第一步:运行 NewsResearchAgent(调研智能体)
- 输入:用户需求 “收集 2025 年 1 月 1 日至 2025 年 1 月 10 日关于‘AI 多智能体’的 3 条最新新闻”;
- 思考过程:需要调用
news_search工具,参数设为keyword="AI多智能体"、time_range="2025-01-01至2025-01-10"、max_results=3; - 工具输出:3 条模拟新闻(包含标题、摘要、来源);
- 智能体输出:整理成列表格式的新闻汇总。
- 第二步:运行 TextSummaryAgent(摘要智能体)
- 输入:原始需求 + 调研智能体的新闻列表;
- 思考过程:需要调用
text_summary工具,参数设为text=调研智能体输出、summary_length="中等"; - 工具输出:中等长度的新闻摘要;
- 智能体输出:结构化的摘要文本。
9.2 最终输出示例
=== 协作组最终结果 ===
【NewsResearchAgent的输出】:
1. 标题:AI多智能体最新进展:多智能体协作效率提升30%,摘要:近日研究显示,多智能体系统在复杂任务处理中,效率比单智能体高30%,已应用于金融分析场景,来源:科技日报,发布时间:2025-01-10
2. 标题:AI多智能体最新进展:多智能体协作效率提升30%,摘要:近日研究显示,多智能体系统在复杂任务处理中,效率比单智能体高30%,已应用于金融分析场景,来源:科技日报,发布时间:2025-01-10
3. 标题:AI多智能体最新进展:多智能体协作效率提升30%,摘要:近日研究显示,多智能体系统在复杂任务处理中,效率比单智能体高30%,已应用于金融分析场景,来源:科技日报,发布时间:2025-01-10
【TextSummaryAgent的输出】:
【中等摘要】:基于2025年1月1日至1月10日的3条AI多智能体相关新闻,核心信息如下:
1. 多智能体系统效率显著提升:研究表明其在复杂任务处理中效率比单智能体高30%;
2. 应用场景落地:该技术已在金融分析领域实际应用;
3. 信息来源:所有新闻均来自科技日报,发布时间集中在1月10日,信息时效性较强。
整体来看,AI多智能体技术正从理论走向实践,效率优势成为核心竞争力,金融领域或成首批规模化应用场景。
10. 扩展与优化建议
目前实现的多智能体系统是基础版本,实际项目中可从以下方向扩展:
10.1 支持并行运行
当前 Crew 类是 “顺序执行”,可优化为 “支持并行”—— 比如多个无依赖的智能体(如 “查天气” 和 “找酒店”)可同时运行,提升效率。可基于 Python 的 concurrent.futures 实现并行逻辑。
10.2 增加动态任务分配
让协调器(Crew)具备 “根据前一个智能体的输出,动态选择下一个智能体” 的能力 —— 比如调研智能体发现 “新闻涉及金融场景”,就自动调用 “金融分析智能体”,而不是固定顺序。
10.3 强化日志与监控
增加更详细的日志(如工具调用耗时、智能体思考耗时),甚至对接监控工具(如 Prometheus),方便追踪系统性能瓶颈。
10.4 支持本地模型
将 OpenAI 替换为 Ollama + Llama3 或 Qwen(阿里通义千问开源版),实现 “完全本地部署”,适合对数据隐私敏感的场景(修改 Agent 类的 generate_thought 方法即可)。
10.5 增加安全防护
- 工具调用权限控制:给不同智能体分配不同权限(如 “调研智能体” 只能读工具,不能调用 “发邮件” 等写工具);
- 输入输出过滤:防止智能体接收恶意输入(如攻击指令)或输出违规内容(如敏感信息)。
11. 总结
本文从零实现了一个多智能体系统,核心是三个模块:
-
Tool 类
:封装外部功能,让智能体能安全、规范地调用;
-
Agent 类
:实现 ReAct 循环,让智能体 “会思考、能行动”,且聚焦自身角色;
-
Crew 类
:通过拓扑排序管理依赖,让多智能体 “有序协作”。
这个系统的优势在于模块化强(修改一个智能体不影响整体)、可解释性高(每个步骤都有日志)、易扩展(新增工具或智能体只需继承基础类)。
无论是处理 “复杂任务拆解”“多场景协作”,还是 “提升 AI 系统可靠性”,多智能体模式都比单智能体更有优势。后续可基于这个基础框架,根据实际需求(如金融分析、医疗诊断、教育辅导)扩展专属的智能体和工具,实现更复杂的 AI 应用。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:

04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)

05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!

06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

















 695
695

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









