



每次跟 ChatGPT 聊天,都得重新自我介绍一遍。明明昨天刚聊过我喜欢看科幻片,今天问它推荐电影,它又问"您喜欢什么类型的?"——这种体验真让人抓狂。Mem0 就是来解决这个问题的。
它到底是什么?
简单说,Mem0 是个记忆层。想象一下,你的 AI 助手终于有了个笔记本,能记住你们之间的对话。更厉害的是,这个笔记本还能跨应用共享——你在 Claude 里说的话,Cursor 编辑器里的 AI 也能记得。
最近他们发了篇论文,数据挺唬人的:比 OpenAI 的记忆方案快 10 倍,准确率还高 26%。不过我更在意的是,它完全开源,数据存在本地。
核心概念
Mem0 支持多级记忆架构,包括:
- 用户级记忆:跨会话持久化保存用户偏好和历史行为
- 会话级记忆:记录当前交互的上下文信息
- 智能体级记忆:存储 AI 系统自身的知识和学习成果
理论框架
记忆层架构
记忆层的核心工作流程包括:
- 信息提取:LLM 对对话内容进行深度分析,自动识别并提取出具有长期价值的关键信息点。
- 向量化:将提取出的信息通过嵌入模型转化为向量表示,便于后续的高效检索。
- 存储:将向量化后的记忆单元存储到向量数据库中,支持大规模、低延迟的语义检索。
- 检索:根据当前用户查询,系统在向量空间中检索出最相关的历史记忆。
- 整合:将检索到的记忆与当前对话上下文进行整合,辅助智能体生成更具针对性和连贯性的响应。
这种架构设计,使 Mem0 能够在保证高效率的同时,提供精准且可扩展的记忆检索服务。
Mem0 如何实现长期记忆
Mem0 的长期记忆系统基于以下核心机制:
- 采用向量嵌入技术,将语义信息高效存储与检索,确保记忆内容的可扩展性与相关性。
- 内置高效的检索机制,能够快速定位并返回与当前查询最相关的历史互动内容。
核心操作接口
Mem0 对外提供了两大核心 API 接口,便于开发者与记忆层进行交互:
- add:用于提取对话内容并将其存储为结构化记忆单元。
- search:根据用户查询,检索并返回最相关的历史记忆内容。
添加记忆流程
添加记忆的操作流程如下图所示:
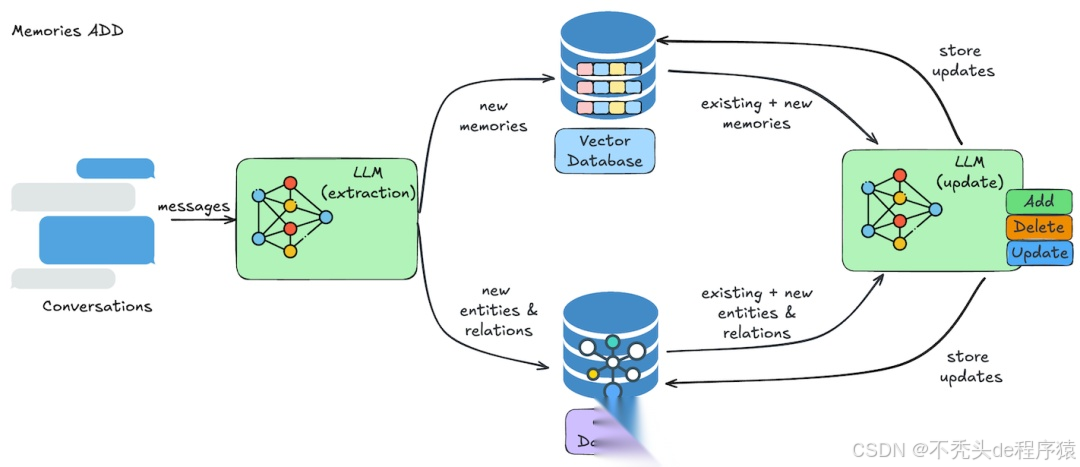
image.png
- 信息提取:LLM 从对话中自动提取出相关记忆,识别重要实体及其关系。
- 冲突解决:系统会将新提取的信息与现有记忆进行比对,自动识别并解决潜在的矛盾或重复内容,确保记忆的准确性。
- 记忆存储:最终的记忆内容会被存储到向量数据库中,同时相关的实体关系会同步到图数据库中。每次用户与智能体的互动,都会不断丰富和完善记忆库。

检索记忆流程
记忆检索的操作流程如下图所示:
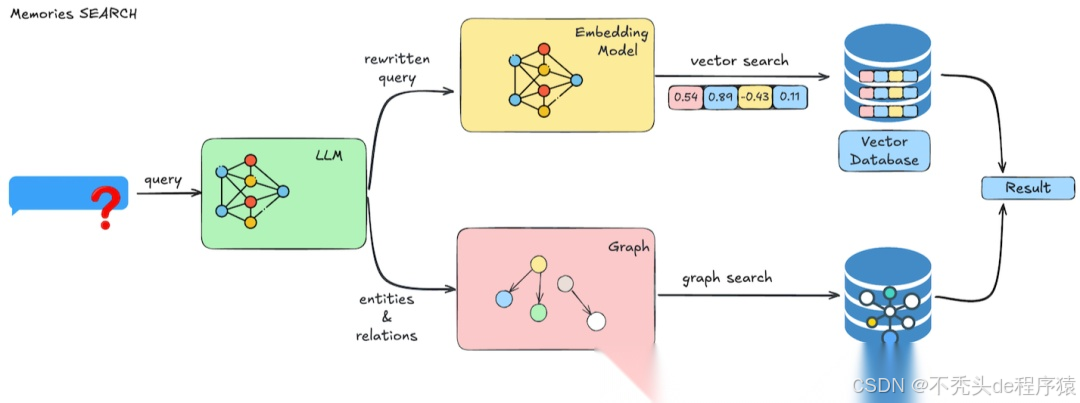
image.png
- 查询处理:LLM 首先对用户的查询进行理解和优化,系统自动生成针对性的检索过滤条件。
- 向量搜索:系统在向量数据库中执行高效的语义搜索,根据与查询的相关性对结果进行排序,并可按用户、代理、元数据等多维度进行过滤。
- 结果处理:系统将检索到的结果进行合并和排序,最终返回带有相关性分数、元数据和时间戳的记忆内容,供智能体进一步使用。
Mem0 图记忆
Mem0 现已支持图形记忆(Graph Memory),通过引入图数据库,用户可以创建和利用信息片段之间的复杂关系,实现更细致入微且具备情境感知的响应。这种集成让用户能够同时发挥基于向量和基于图结构的优势,提升信息检索的准确性和全面性。
示例用法
以下示例展示了如何使用 Mem0 的图形操作:
- 首先,为名为 Alice 的用户添加一些记忆。
- 随着记忆的不断添加,图结构会自动演化,实体和关系被自动提取和连接。
- 用户可以直观地看到记忆网络的变化。
添加记忆
(1)添加记忆"我喜欢去远足"
Python 代码: m.add("I like going to hikes", user_id="alice123")
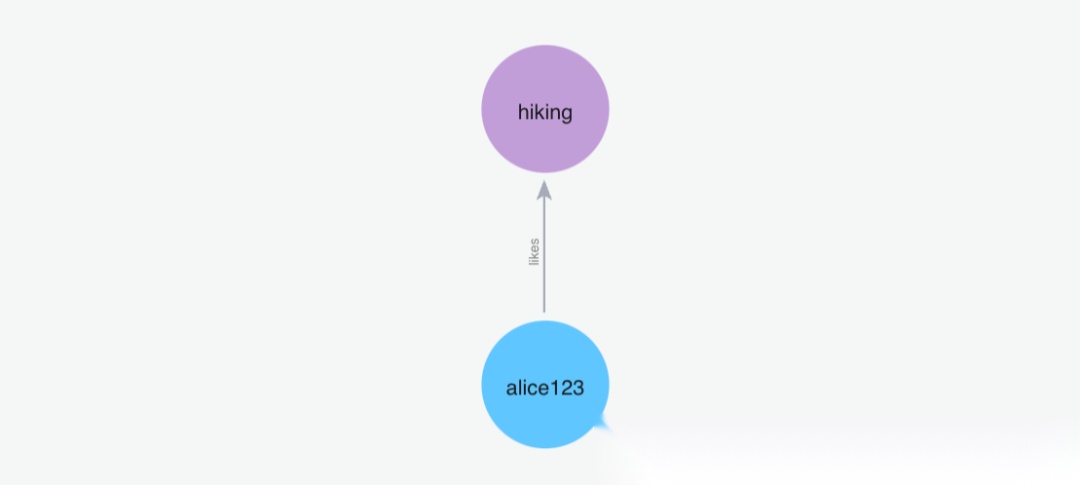
image.png
(2)添加记忆"我喜欢打羽毛球"
Python 代码: m.add("I love to play badminton", user_id="alice123")
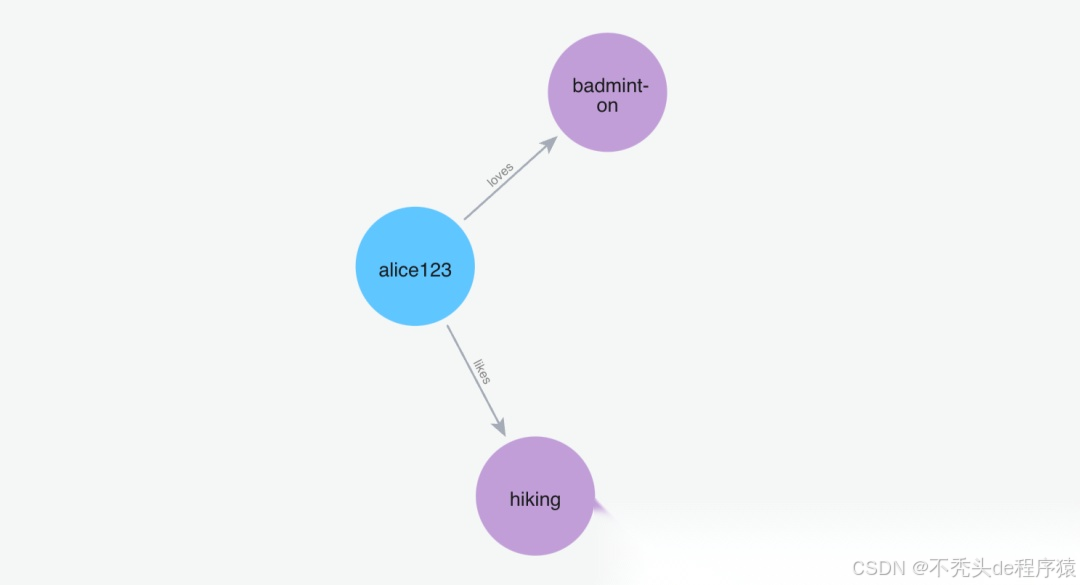
image.png
(3)添加记忆"我讨厌打羽毛球"
Python 代码: m.add("I hate playing badminton", user_id="alice123")
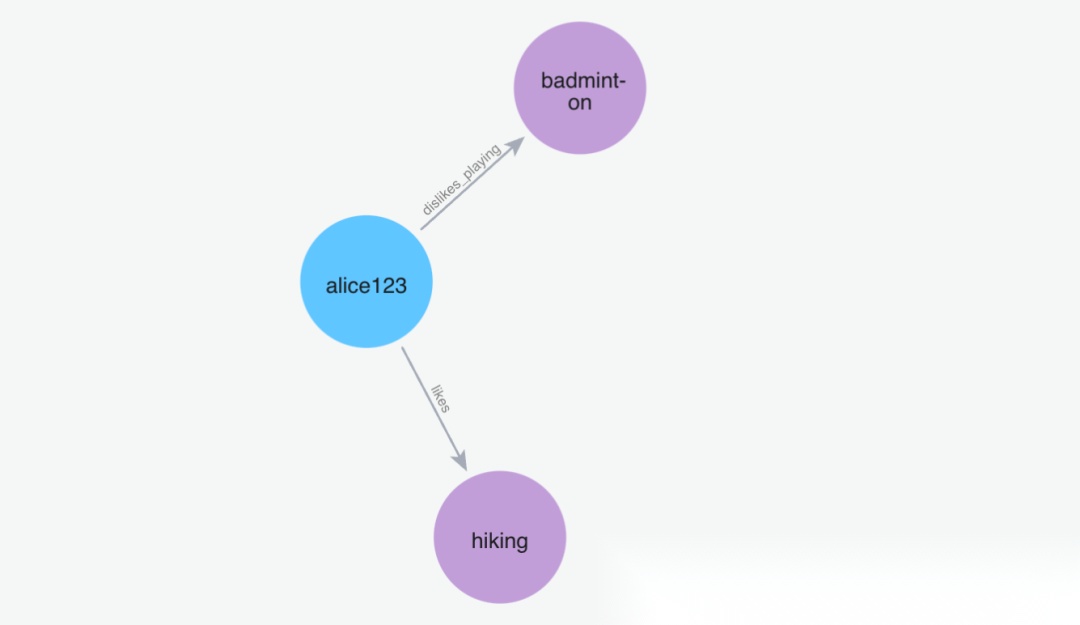
image.png
(4)添加记忆"我的朋友叫约翰,约翰有一只名叫汤米的狗"
Python 代码: m.add("My friend name is john and john has a dog named tommy", user_id="alice123")
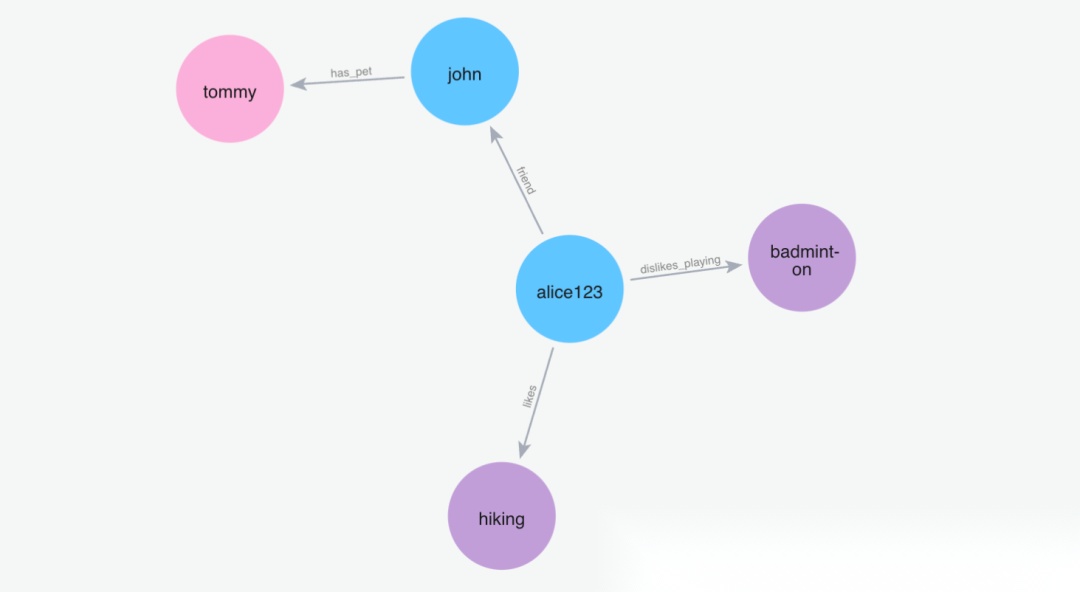
image.png
(5)添加记忆"我的名字是爱丽丝"
Python 代码: m.add("My name is Alice", user_id="alice123")
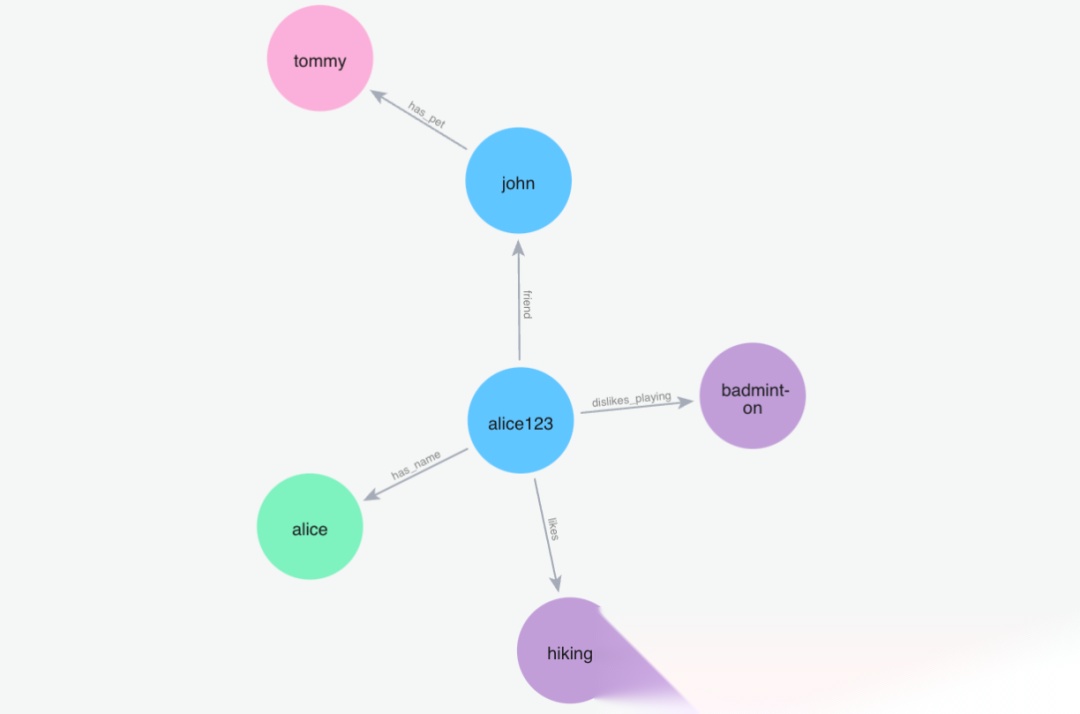
image.png
(6)添加记忆"约翰喜欢徒步旅行,哈利也喜欢徒步旅行"
Python 代码: m.add("John loves to hike and Harry loves to hike as well", user_id="alice123")
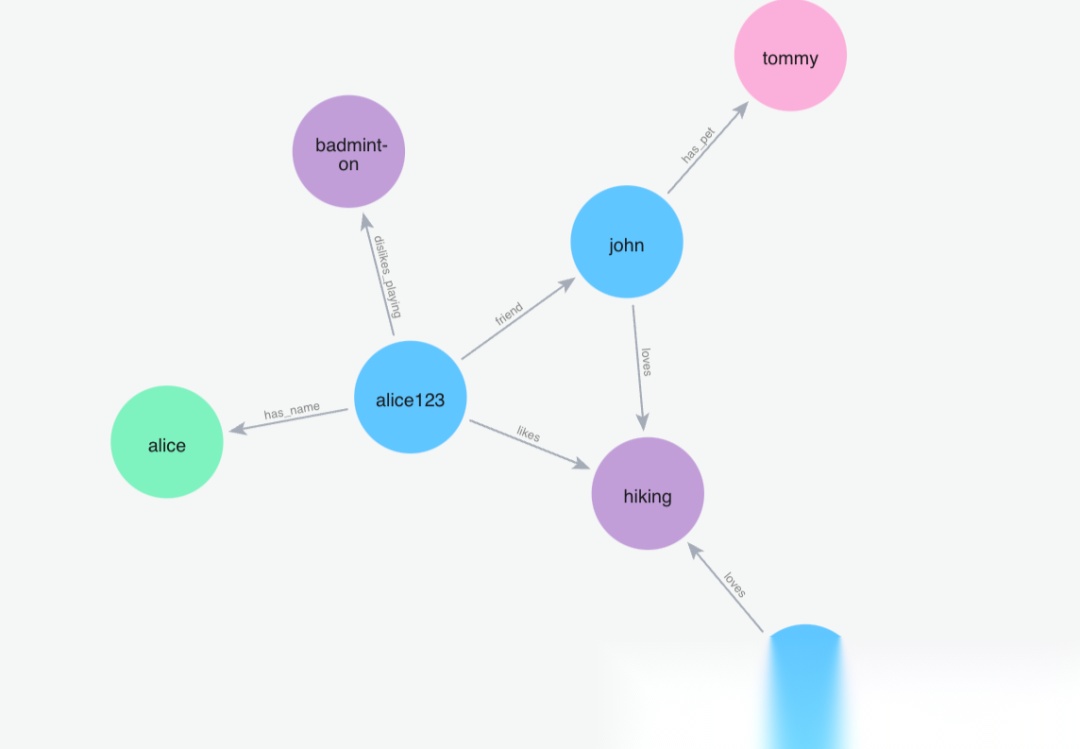
image.png
(7)添加记忆"我的朋友彼得是蜘蛛侠"
Python 代码: m.add("My friend peter is the spiderman", user_id="alice123")
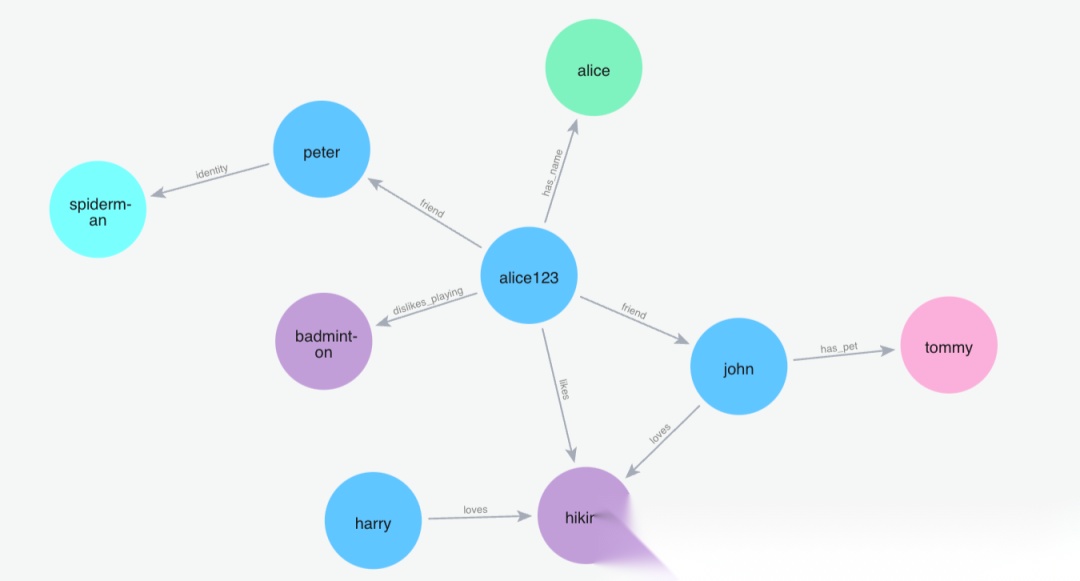
image.png
搜索记忆
(1)搜索名字
Python 代码: m.search("What is my name?", user_id="alice123")
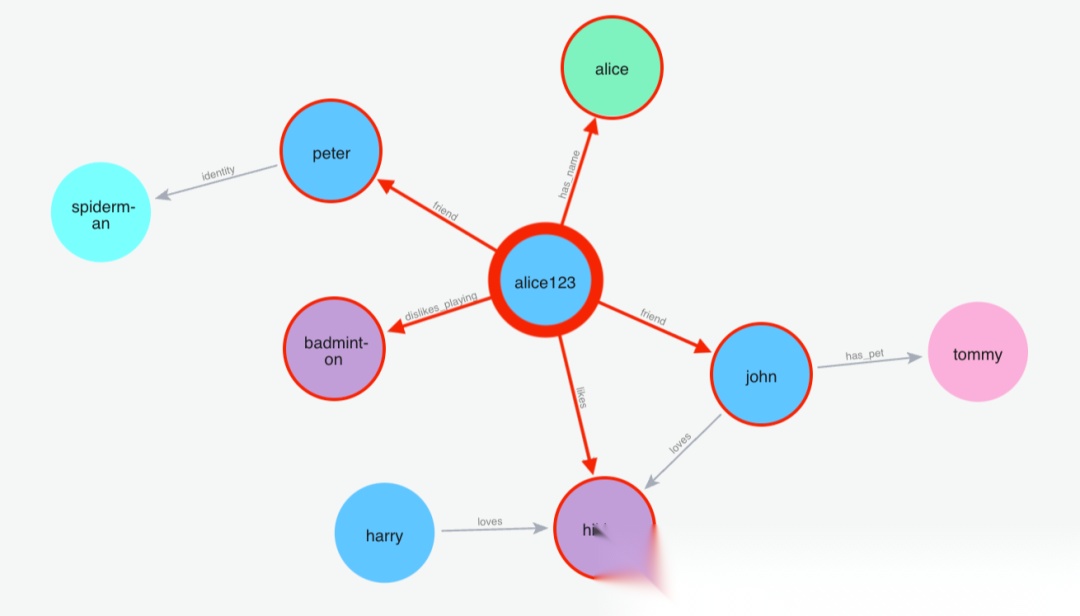
image.png
(2)搜索:蜘蛛侠
Python 代码: m.search("Who is spiderman?", user_id="alice123")
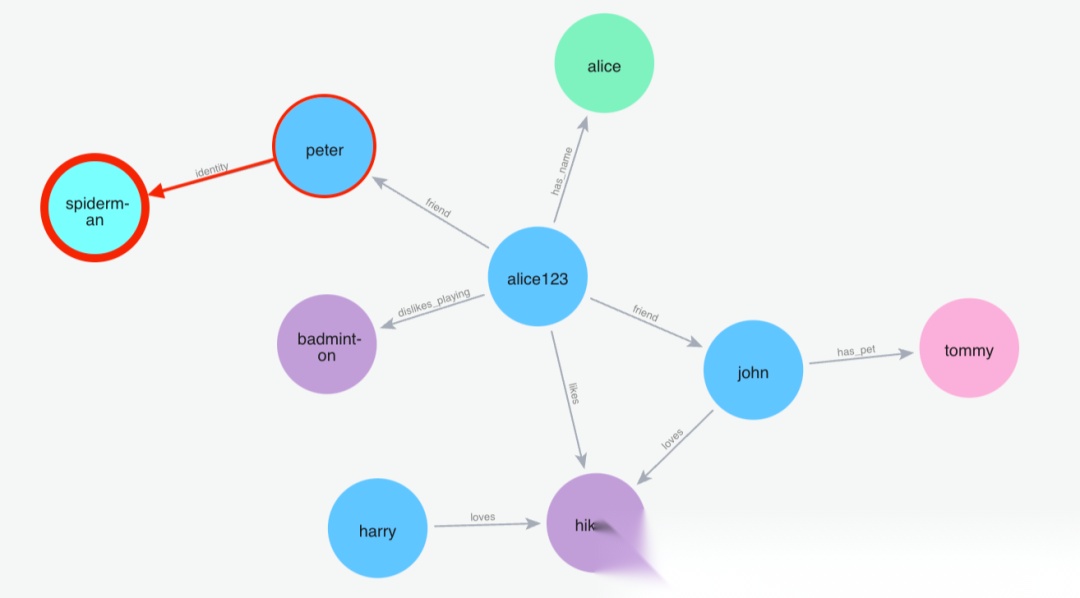
image.png
备注:图记忆的实现并非独立,而是与向量存储协同工作。每次添加或检索记忆时,系统会同时操作向量数据库和图数据库,实现信息的多维度管理。
OpenMemory MCP
OpenMemory MCP(模型上下文协议)是 Mem0 的核心协议层,旨在为 AI 交互提供本地化的"记忆背包"。MCP 作为统一的记忆基础设施,支持多种 AI 应用(如 Claude Desktop、Cursor、Windsurf 等)通过标准化协议连接,实现跨工具的记忆共享。所有数据均在本地存储,确保用户对数据的绝对隐私和控制权。
MCP 提供了四个核心 API:
add_memories:存储新的记忆对象search_memory:基于相关性和上下文检索记忆list_memories:查看所有存储的记忆delete_all_memories:清除所有记忆
接口示例:
-
add_memories:存储新的记忆对象POST /add_memories { "memories": [ { "role": "user", "content": "我喜欢科幻电影,尤其是星际穿越。" }, { "role": "assistant", "content": "星际穿越确实是一部经典的科幻电影!我会记住你喜欢这类电影。" } ], "user_id": "alice", "metadata": { "category": "movies" } } -
search_memory:基于相关性和上下文检索记忆POST /search_memory { "query": "我喜欢什么类型的电影?", "user_id": "alice", "limit": 5 } -
list_memories:查看所有存储的记忆POST /list_memories { "user_id": "alice" } -
delete_all_memories:清除所有记忆POST /delete_all_memories { "user_id": "alice" }
OpenMemory MCP 的最大优势在于其完全本地化运行,既保障了用户数据的隐私和安全,又通过标准化协议实现了跨应用的记忆共享和无缝集成。
原理描述
记忆提取与存储
Mem0 利用 LLM 从对话中自动提取关键信息。该过程包括:
- 分析对话内容,识别重要信息点
- 将信息结构化为可检索的记忆单元
- 为记忆分配相关性标签和类别
- 将记忆存储在向量数据库中
以下是一个简化的记忆提取流程示例:
defextract_and_store_memory(messages, user_id, metadata=None):
# 使用 LLM 提取关键信息
extracted_info = llm.extract_key_information(messages)
# 结构化为记忆单元
memory_unit = {
"content": extracted_info,
"source_messages": messages,
"user_id": user_id,
"timestamp": datetime.now(),
"metadata": metadata or {}
}
# 向量化记忆
vector = embedder.embed(extracted_info)
# 存储在向量数据库中
vector_store.add(vector, memory_unit)
return memory_unit
记忆检索机制
当需要检索记忆时,Mem0 会:
- 将用户查询转换为向量表示
- 在向量空间中搜索相似的记忆
- 根据相关性、时效性和重要性对结果排序
- 返回最相关的记忆供 AI 使用
以下是一个简化的记忆检索流程示例:
defretrieve_memories(query, user_id, limit=5):
# 向量化查询
query_vector = embedder.embed(query)
# 在向量空间中搜索相似记忆
similar_memories = vector_store.search(
query_vector,
filter={"user_id": user_id},
limit=limit
)
# 根据相关性、时效性和重要性排序
ranked_memories = rank_memories(similar_memories)
return ranked_memories
架构组件分析
Mem0 的架构包含以下关键组件:
- LLM 处理器:负责记忆提取和自然语言理解
- 向量存储:用于高效的语义搜索
- 图数据库:用于追踪记忆间的关系
- MCP 服务器:提供标准化 API 接口
- 客户端 SDK:便于开发者集成 Mem0 功能
这些组件协同工作,为 AI 智能体提供完整的记忆管理解决方案。
实践
环境搭建
(1)安装 Mem0
Mem0 支持托管平台和自托管开源两种使用方式。
- 托管平台:在 Mem0 平台 注册账号,通过 SDK 或 API 密钥集成记忆层。
- 自托管:适合对数据隐私和本地化有更高要求的开发者。
本文以自托管为例,结合 DeepSeek 和 Ollama,适配 OpenAI 访问不畅的场景。主要依赖如下:
- LLM 提供商:默认支持 OpenAI gpt-4o-mini,也可选 DeepSeek、Claude 等。
- 向量嵌入模型:如 Ollama 的 mxbai-embed-large。
- 向量存储:如 Qdrant。
(2) 安装 mxbai-embed-large
如无法使用 OpenAI 嵌入模型,可用本地模型替代。以 Ollama 的 mxbai-embed-large 为例:
ollama pull mxbai-embed-large
# 验证
curl http://localhost:11434/api/embeddings -d '{
"model": "mxbai-embed-large",
"prompt": "Represent this sentence for searching relevant passages: The sky is blue because of Rayleigh scattering"
}'
如返回 embedding 信息,说明模型可用。
(3)安装 Qdrant
数据库安装:
docker pull qdrant/qdrant
docker run -p 6333:6333 --name qdrant -d qdrant/qdrant
UI 界面可用 qdrant-web-ui:
git clone https://github.com/qdrant/qdrant-web-ui.git
cd qdrant-web-ui
npm install
npm start
访问 http://localhost:5173/ 查看向量数据库状态。
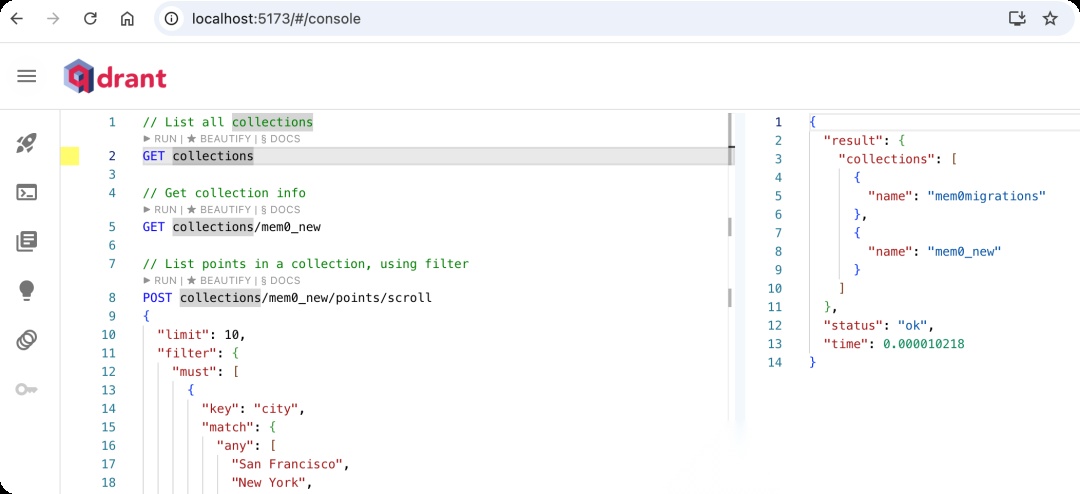
image.png
基本使用示例
以下为 Mem0 的完整使用流程,涵盖初始化、添加记忆、检索记忆等操作:
uv add dotenv langchain langgraph mem0ai ollama
代码示例:
import os
import json
from mem0 import Memory
from mem0.configs.base import MemoryConfig, LlmConfig, EmbedderConfig
# 设置 API 密钥
os.environ["DEEPSEEK_API_KEY"] = "sk-……"# 替换为你的 DeepSeek API 密钥
# 创建配置
config = {
"llm": {
"provider": "deepseek",
"model": "deepseek-chat",
"temperature": 0.2,
"max_tokens": 2000,
"top_p": 1.0
},
"embedder": {
"provider": "ollama",
"model": "mxbai-embed-large"
},
"vector_store": {
"provider": "qdrant",
"config": {
"collection_name": "mem0_new",
"embedding_model_dims": 768,
"host": "localhost",
"port": 6333,
}
},
"reset_vector_store": True
}
# 创建 Memory 实例
m = Memory.from_config(config)
# 添加对话记忆
messages = [
{"role": "user", "content": "我喜欢科幻电影,尤其是星际穿越。"},
{"role": "assistant", "content": "星际穿越确实是一部经典的科幻电影!我会记住你喜欢这类电影。"},
{"role": "user", "content": "我也喜欢克里斯托弗·诺兰的其他电影。"},
{"role": "assistant", "content": "诺兰的作品确实很出色!除了《星际穿越》,他还导演了《盗梦空间》、《信条》、《记忆碎片》等经典作品。您对这些电影有什么特别的看法吗?"}
]
# 添加记忆,并附加元数据
m.add(messages, user_id="alice", metadata={"category": "movies"})
# 检索记忆
memories = m.search(query="我喜欢什么类型的电影?", user_id="alice")
print(json.dumps(memories, indent=2, ensure_ascii=False))
# 获取所有记忆
all_memories = m.get_all(user_id="alice")
print(json.dumps(all_memories, indent=2, ensure_ascii=False))
运行 uv run main.py,可见检索结果如下:
{
"results": [
{
"id": "b052c579-23dd-4d89-933e-4c6ceb4e8958",
"memory": "喜欢克里斯托弗·诺兰的其他电影",
"hash": "a46f8ee3dcfded0fd39d1b5006810adc",
"metadata": {
"category": "movies"
},
"score": 0.6853715,
"created_at": "2025-06-24T07:36:23.381311-07:00",
"updated_at": null,
"user_id": "alice"
},
{
"id": "2fae3fa7-0fa7-4164-b521-5c0d821d1c7a",
"memory": "喜欢科幻电影,尤其是星际穿越",
"hash": "55309121dad25e817ea0b3f132db1e6c",
"metadata": {
"category": "movies"
},
"score": 0.6162164,
"created_at": "2025-06-24T07:36:23.367111-07:00",
"updated_at": null,
"user_id": "alice"
}
]
}
Mem0 与 LangGraph 集成
Mem0 可与 LangGraph 无缝集成,为智能体赋予持久记忆能力。集成步骤如下:
-
安装依赖:
uv add dotenv langchain langgraph mem0ai ollama langchain-deepseek -
配置 LLM、嵌入器和向量存储,与前述一致。
-
在 LangGraph 流程中,调用 Mem0 的 add/search 方法,实现记忆的自动存取。
代码示例略(详见原文)。
import os
from typing import TypedDict, Annotated
from langgraph.graph import StateGraph, START, END
from langgraph.prebuilt import ToolNode
from mem0 import Memory
from langchain_core.messages import HumanMessage, AIMessage
from langchain.chat_models import init_chat_model
# 设置 API 密钥
api_key = os.getenv("DEEPSEEK_API_KEY", "sk-……") # 请替换为你的 DeepSeek API 密钥
os.environ["DEEPSEEK_API_KEY"] = api_key
# 创建配置
config = {
"llm": {
"provider": "deepseek",
"model": "deepseek-chat",
"temperature": 0.2,
"max_tokens": 2000,
"top_p": 1.0
},
"embedder": {
"provider": "ollama",
"model": "mxbai-embed-large"
},
"vector_store": {
"provider": "qdrant",
"config": {
"collection_name": "mem0_new",
"embedding_model_dims": 768,
"host": "localhost",
"port": 6333,
}
},
"reset_vector_store": True
}
# 初始化 Mem0
m = Memory.from_config(config)
llm = init_chat_model(
"deepseek-chat", # 使用DeepSeek模型
api_key=api_key
)
# 定义状态类型
classState(TypedDict):
messages: list
user_id: str
memories: list
# 定义记忆检索函数
defretrieve_memories(state: State):
query = state["messages"][-1]["content"]
user_id = state.get("user_id", "alice")
memories = m.search(query=query, user_id=user_id)
return {"memories": memories["results"]}
# 定义 LLM 节点
defllm_node(state: State):
# 构建系统提示,包含记忆
memories_str = "\n".join(f"- {m['memory']}"for m in state["memories"])
system_prompt = f"你是一个有记忆能力的助手。以下是用户的相关记忆:\n{memories_str}\n请基于这些记忆回答问题。"
# 准备消息
messages = [{"role": "system", "content": system_prompt}]
messages.extend(state["messages"])
# 调用 LLM
response = llm.invoke(messages)
# 更新消息列表,转换为 dict
new_message = {"role": "assistant", "content": response.content}
return {"messages": state["messages"] + [new_message]}
# 定义记忆存储函数
defstore_memories(state: State):
user_id = state.get("user_id", "alice")
# 现在 state["messages"] 已全为 dict
m.add(state["messages"], user_id=user_id)
return {}
# 构建图
graph_builder = StateGraph(State)
graph_builder.add_node("retrieve_memories", retrieve_memories)
graph_builder.add_node("llm", llm_node)
graph_builder.add_node("store_memories", store_memories)
# 添加边
graph_builder.add_edge(START, "retrieve_memories")
graph_builder.add_edge("retrieve_memories", "llm")
graph_builder.add_edge("llm", "store_memories")
graph_builder.add_edge("store_memories", END)
# 编译图
graph = graph_builder.compile()
# 使用图处理查询
result = graph.invoke({
"messages": [{"role": "user", "content": "我最喜欢什么电影?"}],
"user_id": "alice",
"memories": []
})
print(result)
运行代码 uv run main.py 得到如下结果,可以看到 LLM 已经成功使用记忆层。
{
'messages': [{
'role': 'user',
'content': '我最喜欢什么电影?'
}, {
'role': 'assistant',
'content': '根据我们的记忆,您最喜欢的电影是《星际穿越》!这部由克里斯托弗·诺兰执导的科幻杰作确实令人难忘,特别是其中关于时间、空间和人类情感的深刻探讨。您还喜欢诺兰的其他作品,比如《盗梦空间》和《黑暗骑士》三部曲等。需要聊聊最近重温《星际穿越》的新发现吗?'
}],
'user_id': 'alice',
'memories': [{
'id': '2fae3fa7-0fa7-4164-b521-5c0d821d1c7a',
'memory': '喜欢科幻电影,尤其是星际穿越',
'hash': '55309121dad25e817ea0b3f132db1e6c',
'metadata': {
'category': 'movies'
},
'score': 0.62142074,
'created_at': '2025-06-24T07:36:23.367111-07:00',
'updated_at': None,
'user_id': 'alice'
}, {
'id': 'b052c579-23dd-4d89-933e-4c6ceb4e8958',
'memory': '喜欢克里斯托弗·诺兰的其他电影',
'hash': 'a46f8ee3dcfded0fd39d1b5006810adc',
'metadata': {
'category': 'movies'
},
'score': 0.61610943,
'created_at': '2025-06-24T07:36:23.381311-07:00',
'updated_at': None,
'user_id': 'alice'
}]
}
使用 Mem0 与 Dify 集成
Mem0 为 Dify AI 提供了强大的记忆层,通过持续的对话存储和检索功能增强 AI 代理能力:
- 在 Dify 市场中寻找并安装 Mem0 插件
- 配置 Mem0 API 密钥
- 将 Mem0 插件集成到项目工作流中
- 在提示模板中添加记忆检索指令
你是一个有记忆能力的助手。以下是用户的相关记忆:
{{memories}}
请基于这些记忆回答问题。
在 Dify 中调整 LLM 记忆配置,添加以下提示词模板:
你是我的得力助手。
请将以下内容作为你的知识储备,放在 <context></context> 标签内。
<context>
{{#context#}}
</context>
根据用户的问题,检索已有记忆的结果是:
<memory>
{{#1747805606313.text#}}
</memory>
当回答用户问题时:
若不知道答案,就直接说不知道。
若不确定,就向用户澄清问题。
避免提及信息来源于上下文。
根据用户提问的语言进行回答。
配置 Dify 工作流集成 mem0 插件
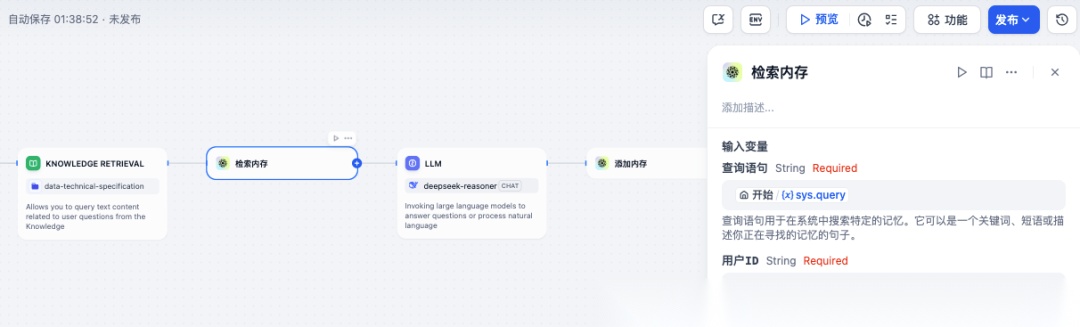
image.png
注意:目前 Dify 的 mem0 插件仅支持托管平台版本,不支持本地版本。
高级探索
高级功能
记忆分类与标签
Mem0 支持对记忆进行多维度分类和标签管理,提升检索的精度和灵活性。例如:
# 添加带标签的记忆
m.add(messages, user_id="alice", metadata={
"category": "movies",
"tags": ["sci-fi", "preferences"],
"importance": "high"
})
# 按类别检索
memories = m.search(
query="科幻电影",
user_id="alice",
filter={"category": "movies"}
)
# 按标签检索
memories = m.search(
query="科幻电影",
user_id="alice",
filter={"tags": "sci-fi"}
)
# 按重要性检索
memories = m.search(
query="科幻电影",
user_id="alice",
filter={"importance": "high"}
)
记忆导出与迁移
Mem0 支持记忆导出,采用 Pydantic schemas 格式,便于记忆的备份和迁移:
# 导出所有记忆
all_memories = m.get_all(user_id="alice")
import json
with open("alice_memories.json", "w") as f:
json.dump(all_memories, f, ensure_ascii=False, indent=2)
高级 API 使用与最佳实践
复杂检索与标签/分类操作
Mem0 支持基于多条件(标签、类别、重要性等)的复杂记忆检索,并可实现批量操作。
# 按标签和类别检索
memories = m.search(
query="深度学习",
user_id="alice",
filter={
"category": "ml",
"tags": ["neural-network", "research"]
},
limit=10
)
# 按重要性检索
memories = m.search(
query="紧急事项",
user_id="alice",
filter={"importance": "high"}
)
# 批量导出所有记忆(适合备份/迁移)
all_memories = m.get_all(user_id="alice")
with open("alice_memories.json", "w") as f:
import json
json.dump(all_memories, f, ensure_ascii=False, indent=2)
# 批量导入记忆
with open("alice_memories.json", "r") as f:
memories_data = json.load(f)
for memory in memories_data:
m.add([memory["source_messages"]], user_id="alice", metadata=memory.get("metadata"))
权限控制相关 API
Mem0 支持多租户和权限控制,可为不同用户、组织配置隔离的数据空间。
# 创建组织并分配用户
org_id = m.create_organization(name="Acme Corp")
m.add_user_to_organization(user_id="alice", org_id=org_id, role="admin")
# 以组织维度设置隔离
memories = m.search(query="合规", user_id="alice", org_id=org_id)
高级 API 示例(RESTful)
通过 OpenMemory MCP,所有操作均可通过 HTTP RESTful API 实现。
POST /search_memory
{
"query": "项目进度",
"user_id": "alice",
"org_id": "acme",
"filter": {"category": "project", "tags": "progress"},
"limit": 5
}
插件机制与二次开发
插件开发
Mem0 支持在 MCP Server 层开发自定义插件。插件可用于前置/后置处理、自定义嵌入器和存储适配器。
from mem0.plugins import register_preprocessor
defcustom_preprocessor(memory_item):
# 增加自定义元数据
memory_item["metadata"]["custom_flag"] = True
return memory_item
register_preprocessor(custom_preprocessor)
插件生命周期与隔离
插件应支持生命周期管理(初始化、热更新、卸载),并建议按功能进行隔离开发,提升健壮性和可维护性。
一些坑和建议
用了一段时间,踩过几个坑:
- 选对嵌入模型:如果不能用 OpenAI,推荐 Ollama 的 mxbai-embed-large,效果不错,本地跑也快。
- 记忆要分类:别什么都往里塞,加好标签和元数据,不然后面检索会很乱。
- 定期清理:时间长了会积累很多过时信息,需要定期清理或设置过期机制。
- 隐私问题:虽然支持本地部署,但如果用云端 LLM,对话内容还是会发出去。敏感信息要谨慎。
总结
当然,它不是银弹。记忆管理本身就很复杂——什么该记、记多久、怎么更新、如何遗忘,这些都是难题。但至少,Mem0 让我们朝着"真正智能"的 AI 迈进了一步。
如果你也受够了"健忘"的 AI,不妨试试 Mem0。开源免费,本地能跑,至少比每次都重新自我介绍要好太多了。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:

04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)

05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!

06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发


















 1274
1274

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









