



这是一篇非常有启发性的论文,它从一个全新的理论视角——强化学习(Reinforcement Learning, RL)——来审视并改进了当前大模型训练中广泛使用的监督微调(Supervised Fine-Tuning, SFT)。
- 研究者通过数学推导发现,传统的 SFT 方法在更新模型参数时,其梯度形式等价于一种带有「缺陷奖励机制」的强化学习。
- 这个缺陷会导致模型过分关注那些它本不确定的样本,从而引发训练不稳和泛化能力差的问题。
- 基于此洞见,论文提出了一种名为「动态微调」(Dynamic Fine-Tuning, DFT)的简单优化方案。通过在计算损失时,动态地乘以一个与当前词元(token)概率相关的权重,DFT 巧妙地修正了这个有问题的奖励机制。
- 这个只需一行代码的改动,在多个数学推理基准测试中,让不同模型的性能都获得了远超传统 SFT 的提升,甚至在某些场景下超越了更复杂的强化学习方法。
论文:[2508.05629] On the Generalization of SFT: A Reinforcement Learning Perspective with Reward Rectification
一、背景知识:SFT Vs RL
在驯服像 GPT、Llama、Qwen 这样强大的基础模型时,我们通常会走两条路,这很像我们人类学习知识的两种方式。
- 监督微调 (SFT) :我们收集成千上万个高质量的问答对喂给模型,通过优化算法让它模仿。
- 优点:这个过程非常简单、直接、高效。模型能很快学会专家的说话方式和知识,就像学生能快速背下课本内容一样。
- 缺点:致命的缺点是泛化能力差。这个学生只会死记硬背,考试时如果题目稍微变个花样,他就很可能答不上来。在 AI 领域,这叫做过拟合(Overfitting)。模型只是记住了训练数据的「模式」,却没有真正理解背后的「原理」。
- 强化学习(RLHF):我们给学生(LLM)聘请一位经验丰富的私人教练(奖励模型/规则)。学生每次尝试回答问题,教练都会给出评价(Reward),学生根据这些反馈不断调整自己的学习策略。根据奖励来源、设计方式的不同,又可以分为 RLHF(带人类反馈的强化学习)和 RLVR(带可验证奖励的强化学习)等方法。
- 优点:模型的泛化能力强。因为它不是在模仿单一的正确答案,而是在探索一个广阔的「好答案空间」,学会了什么是「好」的原则,因此能更好地应对新问题。
- 缺点:这个过程复杂且昂贵。首先,如果我们选择训练一个可靠的奖励模型(通常在 RLHF 中需要)本身就耗时耗力。其次,强化学习的训练过程非常不稳定,对各种超参数极其敏感,计算资源消耗也很大。
学术界有一个精辟的总结:「SFT 负责记忆,RL 负责泛化」(SFT memorizes, RL generalizes)。
本文的作者试图思考一个问题:SFT 本身,就不能变得更聪明吗?我们能不能不引入 RL 的复杂性,直接修复 SFT 的泛化缺陷?

二、用 RL 的视角审视 SFT
如果我们假设 SFT 也是一种强化学习,那么它的「奖励机制」会是什么样的?
2.1 策略梯度(Policy Gradient)
在强化学习中,有一类方法叫做策略梯度,它告诉我们应该如何调整模型的参数 ,才能让它获得更高的奖励。它的简化形式看起来是这样的:
这个公式可以拆解成两部分:
- :这是梯度的方向。它告诉我们参数 应该往哪个方向调整,才能增加生成答案 的概率 。
- :这是奖励(Reward)。它是一个标量,决定了我们这次调整的步子迈多大。如果奖励 很高,我们就朝那个方向迈一大步;如果奖励很低,就迈一小步,甚至是负的奖励就往反方向调整。
2.2 SFT 的梯度
SFT 的目标是让模型生成专家答案 的概率 最大化。它的损失函数是:
对这个损失函数求梯度,我们得到 SFT 的参数更新方向:
2.3 重要性采样
现在,SFT 的梯度和 RL 的策略梯度看起来还不太一样。SFT 的计算是基于固定的专家数据 (这在 RL 里叫 off-policy),而 RL 的策略梯度是基于模型自己生成的样本 (on-policy)。
为了让两者能直接对话,我们引入 off-policy RL 常见的技巧 重要性采样(Importance Sampling)。这个技巧的本质是,我们可以把一个基于 A 分布的计算,转换成一个基于 B 分布的计算,只需要乘上一个 A/B 的修正权重。
这样 SFT 的梯度变身成了和 RL 策略梯度一样的「on-policy」形式:
2.4 等价性
现在,让我们把变身后的 SFT 梯度和 RL 的策略梯度公式并排放在一起:
- RL 策略梯度:
- 变身后的 SFT 梯度: 。忽略了负号,因为最小化损失和最大化奖励是一样的。
这样一来:传统的 SFT,在数学上等价于一个特殊的强化学习过程:
- 隐式奖励 (Implicit Reward) 是 。这是一个指示函数,意思是:只有当模型生成的答案 和专家答案 一模一样时,奖励才是 1,否则奖励就是 0。
- 这个梯度更新还被一个权重 所加权。
三、SFT 的缺陷
通过前面的分析,我们发现 SFT 背地里其实是在遵循一套非常奇特的强化学习奖励机制。而这套机制,正是导致他只会死记硬背、不懂变通的罪魁祸首。
3.1 缺陷一:极其稀疏的奖励
SFT 的隐式奖励是 。这意味着,模型必须生成一个与标准答案一字不差的完整句子,才能得到 1 的奖励。哪怕只错了一个标点符号,奖励也是 0。
这种奖励机制过于严苛和稀疏,让模型很难学到「部分正确」的概念,也难以探索多样的表达方式。
3.2 缺陷二:与自信成反比的奖励权重
如果说稀疏奖励只是有点苛刻,那么 这个权重项,则可以说是畸形和有害的。
代表了模型对于生成正确答案 的自信程度(概率)。这个权重项意味着,最终的梯度更新大小,与模型的自信程度成反比。
让我们回到学生学习的类比中,SFT 的这位「隐形导师」的评分标准是:
- 对于一个问题,比如「1+1=?」,学生非常自信地答出「2」( 很大,比如 0.99)。导师会说:
嗯,不错。奖励你0.01分(梯度更新很小) - 对于另一个非常难的奥数题,学生完全是瞎蒙的,磕磕绊绊猜出了正确答案( 极小,比如 0.0001)。导师会突然变得异常兴奋,激动地喊道:
天哪!你居然做出来了!太不可思议了!奖励你10000分(梯度更新极大)
这种奖励机制会带来灾难性的后果:
- 训练极其不稳定:当模型遇到一个它认为概率极低的正确答案时, 会变成一个巨大的数值,导致梯度爆炸。这就像给学生打了一针强效兴奋剂,让他的大脑(模型参数)剧烈震荡,无法平稳学习。
- 严重过拟合:模型会不成比例地关注那些训练数据中罕见的、奇怪的、低概率的正确样本。它会耗费大量精力去「钻牛角尖」,试图记住这些偶然事件,而不是去学习那些普遍的、高概率的、真正重要的规律。
- 泛化能力差:最终,学生的基础知识(普遍规律)学得一塌糊涂,却对各种偏门怪题的「标准答案」记忆犹新。一旦遇到新问题,自然就束手无策了。
至此,病因已经完全明确。SFT 之所以泛化能力差,根源就在于其梯度更新中隐藏的这个 权重,它构成了一个病态的、不稳定的、鼓励过拟合的优化环境。
四、DFT:一行代码,妙手回春
4.1 治疗原理
有问题的部分是 这个权重。我们该如何消除它的负面影响?作者的选择非常简单:再乘上一个 ,把它抵消掉。
这就是论文提出的动态微调(Dynamic Fine-Tuning, DFT) 的核心思想。我们对原始的 SFT 梯度进行修正:
这里的 代表 stop-gradient(停止梯度)操作。它意味着,我们只是借用 的值来作为权重,调整梯度的大小,但我们不希望梯度通过这个权重本身进行传播。通俗地说,我们只想修正 SFT 梯度的大小,而不改变它本身指向的优化方向。
4.2 DFT 损失函数
这个修正后的梯度,对应到一个新的损失函数。在实际操作中,我们通常将损失计算分解到每一个词元(token)上。最终,DFT 的损失函数变成了这个形式:
这看起来可能有点复杂,但让我们把它翻译成伪代码,你会立刻感受到它的简洁之美:
# 传统的SFT损失(伪代码)
log_probs = log_softmax(logits)
sft_loss = -log_probs[target_token_id]
# DFT损失(伪代码)
log_probs = log_softmax(logits)
probs = softmax(logits)
token_prob = probs[target_token_id]
token_log_prob = log_probs[target_token_id]
# 核心改动:在SFT损失前,乘以该token的概率
dft_loss = -stop_gradient(token_prob) * token_log_prob
真正的核心改动只有一行代码。 我们只是在计算每个正确词元的损失时,额外乘以了模型对这个词元的预测概率。
4.3 DFT 的「学习哲学」
这个简单的改动,彻底改变了模型的学习哲学:
- SFT 的哲学:越不自信,越要下猛药。
- DFT 的哲学:稳扎稳打,全面发展。
在 DFT 的机制下,损失值在自信度 p 两端趋近 0。这意味着,模型会暂时「忽略」它完全搞不懂的知识点,避免在上面花费过多精力、产生剧烈震荡。它会优先学习那些它能理解和掌握的知识。
这更像一个优秀的学习者:先打好坚实的基础,再去攻克难题,而不是在一个难题上死磕到底,结果基础全忘了。
4.4 一个有趣的反面对比:Focal Loss
值得一提的是,DFT 的设计哲学与计算机视觉领域一个著名的损失函数Focal Loss截然相反。
- Focal Loss: 。它通过 这个因子,降低了模型已经很自信( 很大)的「简单样本」的权重,让模型更专注于学习那些它搞不懂的「困难样本」。它的目标是解决欠拟合问题。
- DFT: 。它通过 这个因子,降低了模型非常不自信( 很小)的「困难样本」的权重,避免模型在它们身上过拟合。它的目标是解决过拟合问题。
这种鲜明的对比,可能正反映了 AI 发展的时代变迁:在过去,模型能力不足,我们担心它学不够(欠拟合);而今天,LLM 的记忆和拟合能力超强,我们更担心它学过头(过拟合)。DFT,正是为 LLM 时代量身定做的解决方案。
五、实验结果
5.1 发现一:DFT 全方位超越 SFT
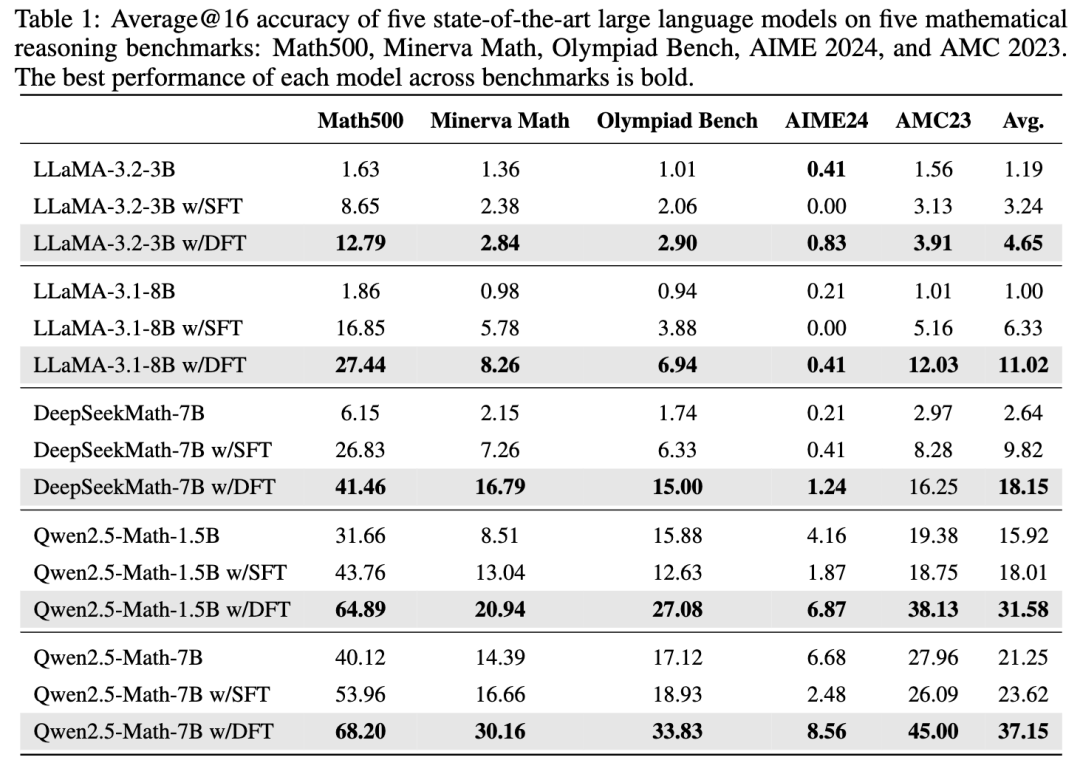
如上表所示,在 Qwen、LLaMA、DeepSeekMath 等多个主流模型上,DFT 带来的性能提升远超 SFT。
5.2 发现二:越是难题,DFT 越有用
还是上面那张表,SFT 的过拟合问题在难题上暴露无遗。在一些奥林匹克级别的数学竞赛(Olympiad Bench, AIME24)上,SFT 甚至会让模型性能下降。因为它让模型学到了一些只在训练集有效的「解题歪招」。
而 DFT 在这种高压环境下,表现出了很强的鲁棒性,比如 Qwen2.5-Math-7B 在 AIME24 benchmark 上的表现:
- 基础模型得分:6.68
- SFT 后得分:2.48 (下降了 4.2 分)
- DFT 后得分:8.56 (提升了 1.88 分)
这暗示 DFT 确实学会了更根本、更通用的解题原则,而不是在死记硬背。
5.3 发现三:DFT 是更高效的学习者
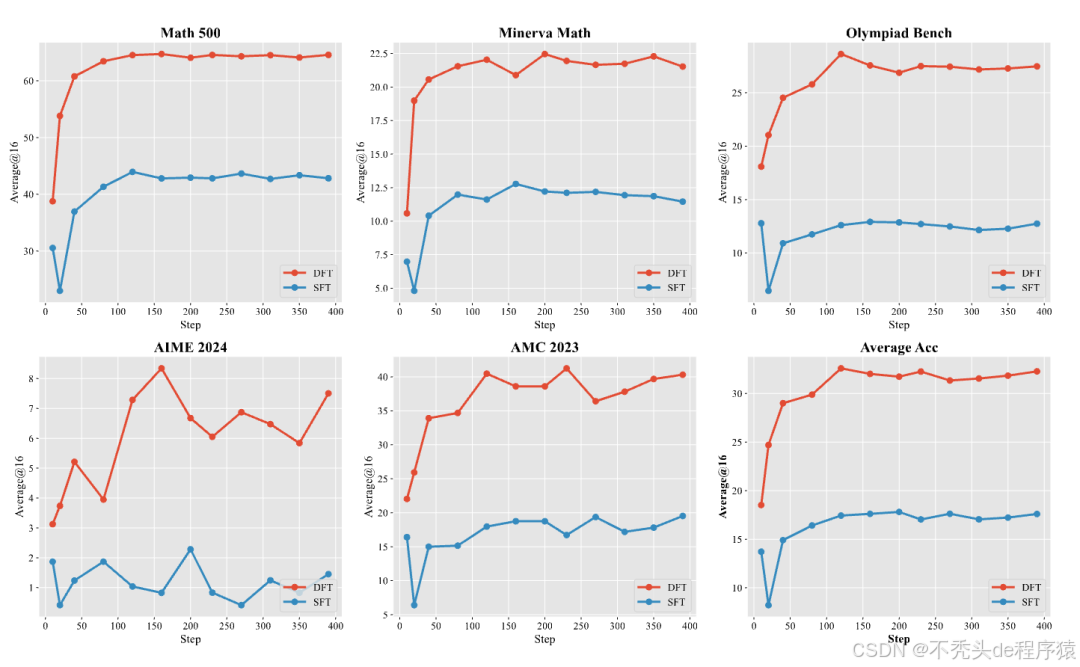
从上图的学习曲线可以看出,DFT 不仅最终效果好,学习速度也更快。在多数任务上,DFT 在训练刚开始(约 10-20 步)的性能,就已经超过了 SFT 训练到最后的最佳性能。这意味着 DFT 的梯度更新更有效、更稳定,能引导模型更快地走向最优解。
5.4 发现四:DFT 如何重塑概率分布
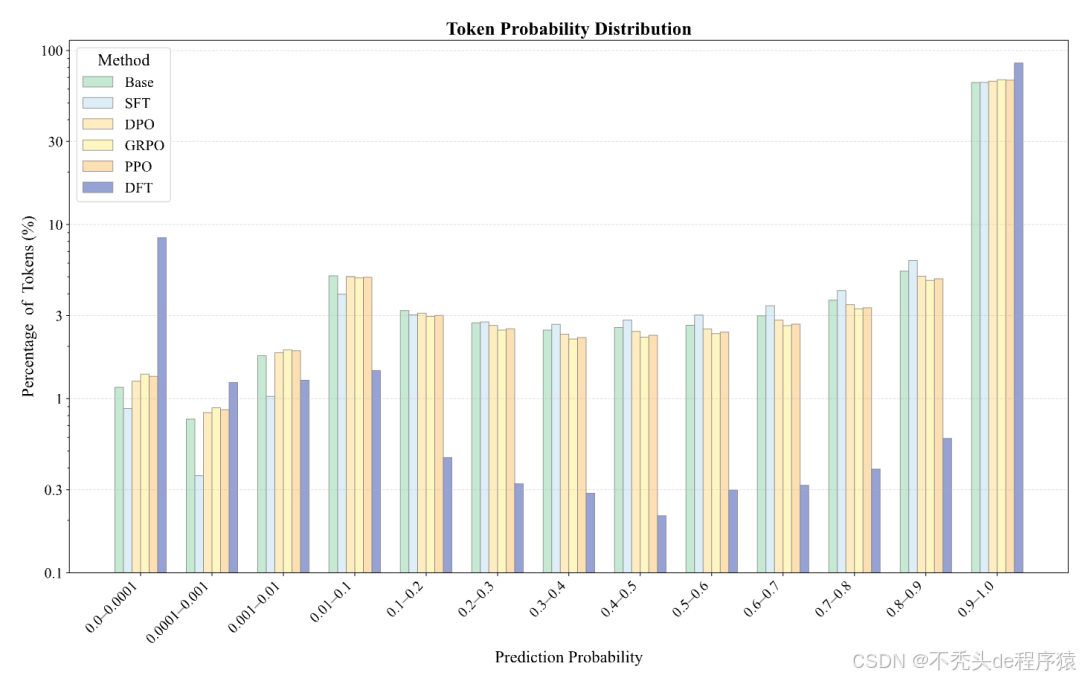
作者们做了一个分析,探究了不同方法如何改变模型对正确答案的概率分配。
- SFT:试图普遍提升所有正确词元的概率。它的策略是「雨露均沾」,但结果是重点不突出。
- DFT 和 RL 方法:则表现出一种惊人的 「两极分化」 效应。它们会极大地提升一部分词元的概率,同时主动地降低另一部分词元的概率。
深入分析发现,被降低概率的,大多是像 the/let/,/. 这样的语法功能词或连接词。而被提升概率的,则是承载核心语义的关键数字和术语。
这说明,DFT 教会了模型「抓重点」。它让模型把信心(高概率)集中在那些真正重要的内容上,而对那些语法性的、不那么重要的部分保持「平常心」。这是一种更智能、更高效的资源分配策略,也是其强大泛化能力的内在写照。
5.5 发现五:DFT 在 RL 场景中依然有效
作者们还做了一个探索性实验:在一个有正负样本的「离线 RL」场景下,DFT 的表现如何?
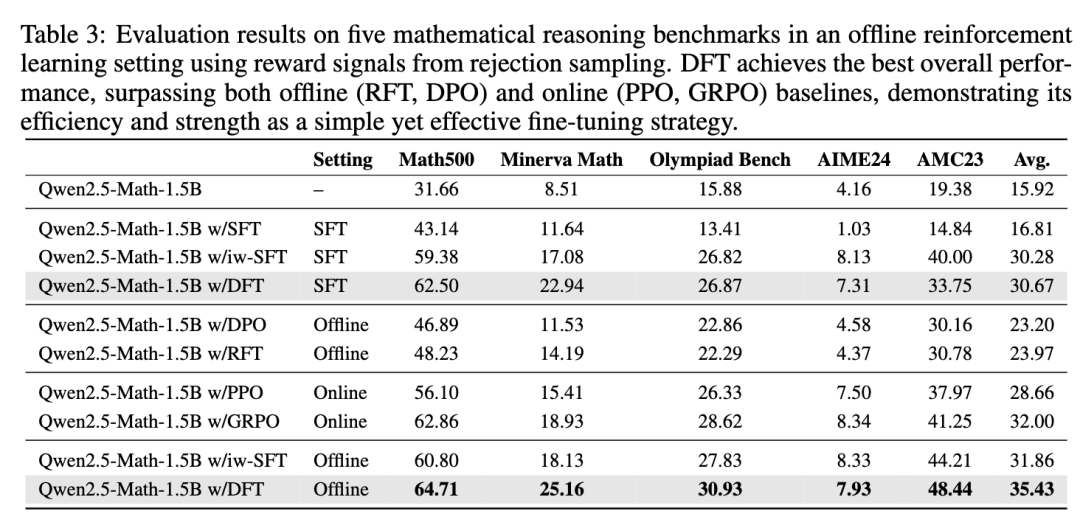
DFT 作为一个极其简单的微调方法,其性能不仅超过了 DPO、RFT 等专门的离线 RL 算法,甚至还超过了 PPO、GRPO 这种更复杂、需要在线交互的在线 RL 算法。
这说明 DFT 的潜力可能远超我们的想象。它提供了一个强大、简单、高效的基准,甚至可以作为更复杂 RL 方法的有力替代品。
六、总结
6.1 贡献与启发
- 理论突破:首次从强化学习视角,严格证明 SFT 等价于带有病态奖励机制的策略梯度方法,为理解 SFT 泛化能力差提供新理论基础。
- 问题定位:明确指出 SFT 梯度更新中隐含的 权重导致训练不稳定和罕见样本过拟合。
- 方法创新:提出动态微调(DFT),通过在损失函数中乘以 权重,仅需「一行代码」即可修正 SFT 缺陷,使优化过程更稳健。
- 实证优势:在多个高难度数学推理任务上,DFT 显著优于 SFT,尤其在 SFT 失效场景下表现更鲁棒,强力支持其提升泛化能力的结论。
- 范式启发:
- 对抗过拟合:DFT 抑制对低概率样本的过度反应,理念与 Focal Loss 相反,提示 LLM 微调时防止过拟合更为关键。
- 大道至简:强调基础技术的重新审视,理论洞察可带来最简洁有效的实践方案。
6.2 局限与挑战
- 任务局限:实验仅覆盖数学推理,DFT 在开放性任务(如创意写作、代码生成、对话)上的效果尚待验证。
- 规模验证不足:目前仅在最大 7B 左右模型上测试,DFT 在更大规模模型上的有效性需进一步实验确认。
- 知识探索风险:DFT 降低对低概率正确样本的关注,可能导致模型难以学习反直觉但正确的新知识,带来「保守性」问题。
- 数据质量依赖:DFT 依赖高质量专家数据,若数据噪声多,可能忽略纠正模型偏见的机会。
- 学习僵化风险:损失项 在 趋近于 0 时梯度消失,模型可能彻底失去修正极低概率知识的能力,造成「学习僵化」。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:

04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)

05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!

06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









