



前三代 RAG 进化小史
第一代 RAG ,是以 embeding + 全文检索为基础做召回,以rerank模型为精排。这代其实RAG受限于当时的技术条件而诞生的一个技术,那个时候大模型窗口普遍4-8k,并发少,速度慢,模型效果也一般,所以只能采用传统技术来做召回,并且采用小模型(rerank)来做排序。 第一代RAG解决了从无到有的问题。下图是 一代 RAG 典型的流程。
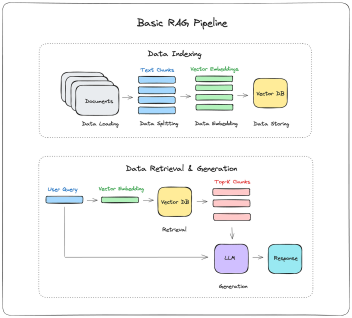
第一代RAG 最大的问题就出在召回方案缺乏语义理解,受限于 embeding 对文本长度的支持,还长期受限于文本碎片化的困扰。后续RAG公司没有从根本上去解决这个问题,而是不断的在其上打补丁比如,加入实体图搜索,在数据预处理上进行大量场景定制,在召回策略上也要进行场景定制。一代RAG天花板太低,实际上效果很难再提升,唯一的出入就是定制,但这样很难控制成本。
随着大模型技术的发展,我们推出了第二代 RAG , 该RAG核心是使用大模型做召回,解决了海量数据召回速度和成本问题,同时高度优化窗口的使用率,彻底解决语义召回的难题。 效果也是出奇的好,并且实际成本相比定制化RAG 也更低,成本很透明:
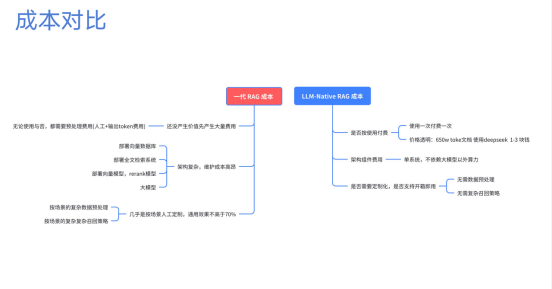
但是第二代依然有明显的缺陷,对于需要复杂拆解的问题比较困难,下面图片是个例子:

于是我推出了第三代 RAG , Agentic RAG, 基于二代的基础上,我们引入了 Agentic 范式,并增加了联网以及规划能力,从而使用通用的方式解决了,下推演示了这种规划能力:
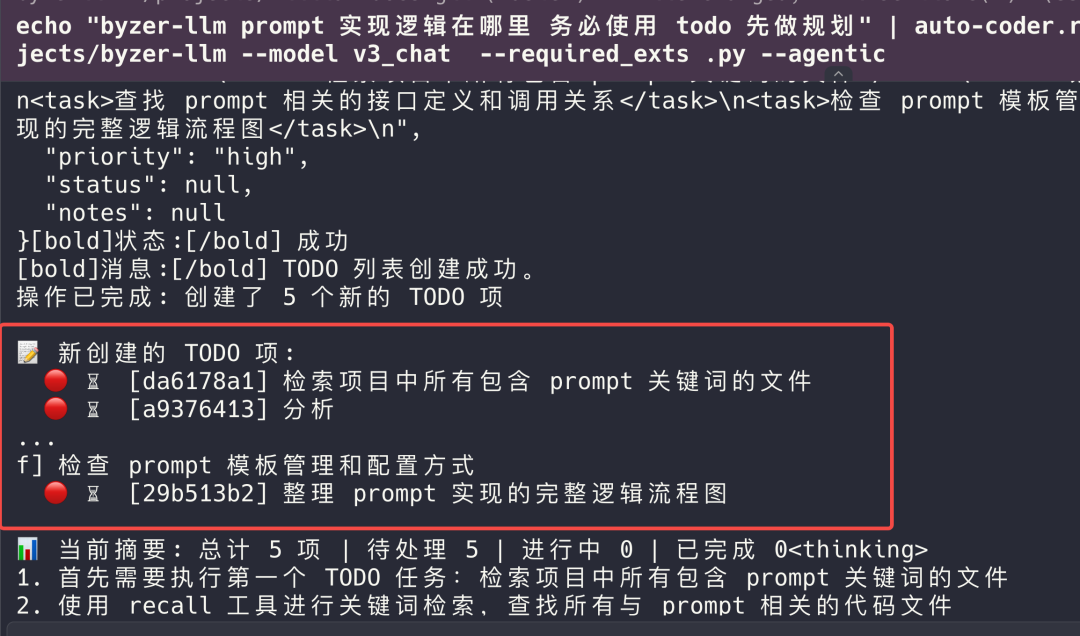
通过提前拆解规划问题,从而将复杂的问题拆解成一些简单的信息召回问题,然后结合多轮召回,最后给出答案。
这就是第三代 Agentic LLM Native RAG. 第三代 RAG 是已经 RAG 的顶级形态。 那么第四代 RAG 进化方向应该在哪呢?
第四代RAG
经过前三代RAG的积累,第四代 RAG 在使用方式开始进入新的阶段。传统方式将 RAG 作为一个服务(比如兼容 OpenAI 接口),比如这样:
auto-coder.rag serve --lite --port 8102 \
--doc_dir ./byzer-llm \
--model v3_chat
然后就可以通过 OpenAI SDK 通过 127.0.0.1:8102 进行访问了。这种方式对于和其他产品结合并不方便。
为此,我们提供了命令行模式:
echo "byzer-llm prompt 函数是什么" | auto-coder.rag run \
--doc_dir ./byzer-llm --model v3_chat \
--output_format text \
--agentic
这意味着你可以随时随地的对任意一个目录进行 RAG 查询。命令行的方式几乎可以被任何Agent 调用,你可以很轻松的嵌入到 Cursor/Auto-Coder/Claude Code/Codex/Qoder 中,你只需要给这些 Code Agent 通过 Rule 添加一个简单的使用说明, Code Agent 就会在合适的时候使用知识库进行学习:
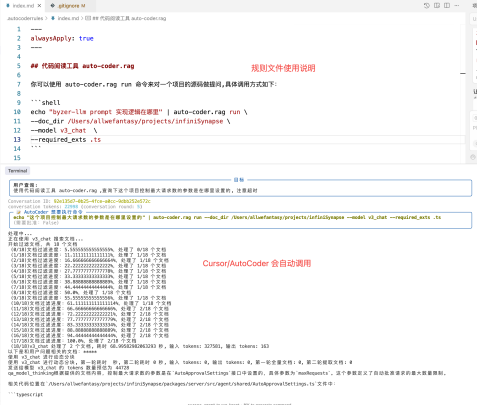
除了命令行,我们也提供了 Java,Go, NodeJS ,Python 的绑定,比如Java, 你可以添加如下依赖:
<dependency>
<groupId>tech.mlsql</groupId>
<artifactId>autocoder-rag-sdk</artifactId>
<version>0.0.2</version>
</dependency>
然后可以写类似的代码:
package com.example;
import com.autocoder.rag.sdk.RAGClient;
import com.autocoder.rag.sdk.RAGConfig;
import java.util.stream.Stream;
import java.util.stream.Collectors;
public class Main {
public static void main(String[] args) {
RAGConfig config = new RAGConfig("./byzer-llm");
config.setModel("v3_chat");
RAGClient client = new RAGClient(config);
String query = "byzer-llm prompt function是什么";
try {
Stream<String> stream = client.queryStream(query);
String result = stream.collect(Collectors.joining("\n"));
System.out.println(result);
} catch (Exception e) {
System.err.println("Error: " + e.getMessage());
System.exit(1);
}
}
}
就完成了流式的 RAG 查询,可以将 RAG 方便的各种集成到用户的应用中。
第四代RAG 无需部署即可实现开箱即用,并且能够让各种语言以库的方式被直接使用。所以我们将 第四代 RAG 称为 Agentic LLM Native RAG SDK. 你也可以简称为 RAG SDK.
RAG 是未来所有AI应用的基础设施,而 auto-coder.RAG 提供了更加便利友好方式和集成方式,以及最优秀的查询效果。期待大家使用和集成。
最后
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。

最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师给大家这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下


这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】


















 24万+
24万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









