



前言
在深度学习的璀璨星空中,Transformer架构无疑是最为耀眼的明星之一。自2017年被提出以来,Transformer以其卓越的性能和强大的表现力,迅速席卷了自然语言处理、计算机视觉等多个领域,成为了众多前沿研究和应用的基石。而在Transformer架构中,自注意力(Self-Attention)机制更是其核心与灵魂所在,它的出现彻底革新了模型处理序列数据的方式,为深度学习带来了一场意义深远的变革。
一、为什么需要自注意力机制
在深入探讨自注意力机制之前,我们先来回顾一下传统神经网络在处理序列数据时面临的困境。
(一)RNN的局限性
循环神经网络(RNN),包括LSTM(长短期记忆网络)和GRU(门控循环单元),曾经是处理序列数据的主流模型。RNN通过循环连接来捕捉序列中的依赖关系,按顺序依次处理每个时间步的输入,理论上可以学习到长距离依赖。然而,在实际应用中,RNN面临着梯度消失和梯度爆炸的问题,尤其是当序列长度较长时,这些问题会导致模型难以捕捉到长距离的依赖关系,从而影响模型的性能。
(二)CNN的不足
卷积神经网络(CNN)擅长提取局部特征,通过卷积核在图像或序列上滑动来进行特征提取。虽然CNN在计算机视觉领域取得了巨大的成功,但在处理序列数据时,它对序列中元素间的全局关系把握不足。CNN只能捕捉局部区域内的信息,对于跨越较长距离的依赖关系,CNN难以有效建模。
(三)自注意力机制的诞生
正是为了弥补传统神经网络在处理序列数据时的这些缺陷,自注意力机制应运而生。自注意力机制允许模型在处理序列中的每个位置时,能够并行地关注序列中的所有其他位置,从而直接捕捉到序列中任意两个位置之间的依赖关系,不受距离的限制。这种全新的机制使得模型能够更好地处理长序列数据,捕捉到丰富的上下文信息,为Transformer架构的强大性能奠定了基础。
二、自注意力机制详解
(一)词嵌入(Word Embedding)
在深入理解自注意力机制之前,我们需要先了解词嵌入这一关键概念。在自然语言处理任务中,我们输入的文本通常是由一个个单词组成的序列,而计算机无法直接处理这些文本数据。词嵌入就是将文本中的每个单词映射到一个低维的向量空间中,使得每个单词都可以用一个固定长度的向量来表示。这些向量不仅能够表示单词的语义信息,还能反映单词之间的语义关系。例如,语义相近的单词在向量空间中的位置也会比较接近。常见的词嵌入方法有Word2Vec、GloVe等,它们通过对大规模文本语料库的学习,能够将单词转化为具有丰富语义信息的向量表示。
(二)位置编码(Positional Encoding)
自注意力机制本身没有捕捉序列中元素位置信息的能力,它平等地对待输入序列中的每个元素,无法区分相同元素在不同位置的语义差异。然而,在很多自然语言处理等任务中,序列的顺序至关重要,所以需要引入位置编码来给模型注入位置信息,帮助模型更好地理解序列的结构和语义。
**1. 绝对位置编码:**给每个位置赋予一个固定的编码向量,常见的是正弦余弦位置编码。对于第i个位置,其位置编码向量的第j维计算公式为:
◦ 当j为偶数时,PE_{(i,j)} = sin(i / 10000^{j/d_{model}})
◦ 当j为奇数时,PE_{(i,j)} = cos(i / 10000^{j/d_{model}})
其中,d_{model}是位置编码向量的维度,i是位置索引。这种编码方式利用了正弦和余弦函数的周期性和单调性,能让模型学习到不同位置之间的相对距离关系。
\2. 相对位置编码:考虑的是元素之间的相对位置关系。例如,在计算某个位置的注意力时,会根据当前位置与其他位置的相对距离来调整注意力权重。比如,在语言模型中,相对位置编码可以帮助模型更好地处理句子中的指代关系等依赖于相对位置的语义信息。
(三)计算Query、Key和Value
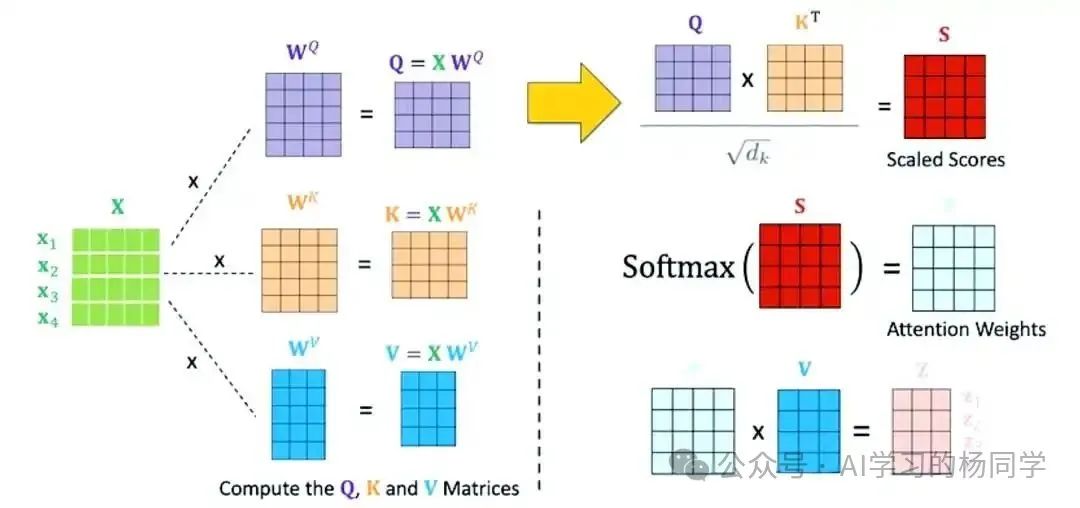
自注意力机制引入了三个矩阵WQ、WK和WV,这三个矩阵都是随机初始化并且可以通过反向传播梯度下降学习的矩阵,它们的维度通常是相同的。Transformer会对输入X分别通过三个不同的线性变换矩阵WQ、WK、WV来生成Query(查询)、Key(键)、Value(值)向量。
我们将输入矩阵分别与WQ、WK和WV相乘,得到Query矩阵Q、Key矩阵K和Value矩阵V。具体公式如下:
Q = XWQ
K = XWK
V = XWV
(四)计算注意力分数(Attention Scores)
接下来,我们计算每个位置与其他位置之间的注意力分数。计算方法是将Query矩阵中的每一行与Key矩阵的每一行进行点积运算。公式如下所示:
Attention Scores = QK^T
注意力分数衡量了当前位置与其他位置的关联程度,通过这个分数我们可以知道该句子中与当前词汇最相关的词汇是什么,以及自注意力分数是多少。
(五)Softmax归一化
得到注意力分数后,我们使用Softmax函数对其进行归一化,将分数转换为概率分布,表示每个位置对其他位置的关注程度。公式如下:
Attention Weights = softmax(\frac{Attention Scores}{\sqrt{d_k}})
其中,\sqrt{d_k}是为了对注意力分数进行缩放,避免点积结果过大导致Softmax函数梯度消失。经过Softmax归一化后,每一行的注意力权重之和为1。
(六)计算输出
最后,我们将归一化后的注意力权重与Value矩阵相乘,得到自注意力机制的输出。公式如下:
Output = Attention Weights \cdot V
将注意力权重与V向量相乘,能够根据每个位置与当前位置的关联程度,对V向量所携带的信息进行加权聚合,从而得到一个综合考虑了全局依赖关系的输出向量,使输出能融合输入序列各位置的相关信息。这个输出矩阵的形状与输入相同,输出矩阵中的每一行,都综合考虑了输入序列中所有位置的信息,并且根据注意力分数对不同位置的Value进行了加权求和。
三、自注意力机制的优势
(一)并行计算能力
与传统的循环神经网络(RNN)和卷积神经网络(CNN)不同,自注意力机制可以并行地计算序列中每个位置的输出。它无需像RNN那样顺序地处理每个时间步,也无需像CNN那样通过卷积核逐步滑动来提取特征,极大地提高了模型的训练速度,使其能够高效处理大规模数据,适应各种实时性要求较高的任务。
(二)长序列处理能力
传统的序列模型在处理长序列数据时,容易出现梯度消失或梯度爆炸问题,导致难以捕捉长距离的依赖关系。自注意力机制可以直接计算序列中任意两个位置之间的依赖关系,不受距离的限制,能够有效地捕捉输入序列中的长程依赖信息,对于处理长文本、长视频等长序列数据具有明显优势。
(三)动态适应性
自注意力机制能够根据输入序列的内容动态地分配注意力权重。在处理不同的输入时,它会自动关注与当前位置相关度更高的信息,忽略无关信息,对输入数据中的重要特征更加敏感,能自适应地学习到输入序列中的复杂模式和结构,提高模型的准确性和泛化能力。
(四)全局信息捕捉能力
自注意力机制在计算每个位置的输出时,会考虑整个输入序列的所有位置信息,而不像CNN只能捕捉局部区域的信息。这使得它能够从全局视角对输入进行建模,更好地理解输入数据的整体语义和结构,在一些需要全局信息的任务中表现出色。
(五)可解释性相对较强
相比于一些复杂的黑盒模型,自注意力机制具有一定的可解释性。通过注意力权重,我们可以直观地看到模型在处理每个位置时关注了哪些其他位置的信息,有助于理解模型的决策过程和对输入数据的理解方式,为模型的分析和改进提供了一定的依据。
四、自注意力机制的不足
(一)计算复杂度高
自注意力机制的计算复杂度为O(n^2) ,其中n是输入序列的长度。随着序列长度增加,计算量呈平方级增长。在处理长序列时,会消耗大量计算资源和时间,如训练超长文本时,计算资源需求可能超出硬件承载能力,导致训练中断或训练时间极长 ,限制了模型处理长序列数据的效率和可行性。
(二)内存占用大
计算过程中要存储大量中间结果,像注意力分数、加权表示等。对于长序列,这些中间结果占用大量内存空间,可能引发内存不足,限制模型处理序列长度和批量大小,如在处理长视频序列时,因内存限制,无法一次性处理较长的视频片段。
(三)缺乏局部性建模
自注意力机制虽关注全局信息,但相对忽视局部信息建模。它平等对待序列中每个位置,未显式利用数据局部结构和模式。在一些任务中,局部信息对理解和处理数据很关键,例如图像中的局部纹理、语音中的局部音频特征等,缺乏局部建模能力会影响模型在这些任务中的表现 。
(四)语义理解的局限性
虽然自注意力机制能捕捉词与词之间的依赖关系,但对于复杂语义理解任务,仅靠词之间的共现关系,可能无法完全理解文本深层语义。如对于隐喻、象征等修辞手法的文本,自注意力机制难以准确把握背后含义。
五、后续研究方向
(一)降低计算复杂度和内存占用
研究低秩近似方法,利用低秩矩阵分解减少QKT计算复杂度;探索稀疏注意力技术,如Longformer和BigBird,通过引入局部窗口和全局注意力机制,仅计算部分注意力分数,将复杂度降低为O(nlogn)或O(n);发展线性注意力机制,使用核函数近似注意力机制,避免QKT操作,以线性空间和时间复杂度实现注意力计算 。
(二)增强局部性建模能力
结合卷积神经网络等局部特征提取能力强的模型,将卷积操作融入自注意力机制,使模型在关注全局信息同时,有效捕捉局部信息;设计专门的局部注意力模块,针对局部区域进行精细化的注意力计算,增强对局部结构和模式的学习。
(三)提升语义理解深度
引入知识图谱等外部知识,将知识图谱中的语义知识融入自注意力计算过程,辅助模型理解文本的深层语义;改进训练方式和损失函数,如采用对抗训练等技术,增强模型对复杂语义的理解和表达能力。
六、总结
自注意力机制作为Transformer架构的核心组件,彻底改变了深度学习模型处理序列数据的方式。通过引入位置编码、Query - Key - Value机制以及Softmax归一化等步骤,自注意力机制能够高效地捕捉序列中的长距离依赖关系,并且具有并行计算、动态适应、全局信息捕捉和一定可解释性等诸多优势。这些优势使得Transformer架构在自然语言处理、计算机视觉等领域取得了巨大的成功,推动了深度学习技术的飞速发展。
**然而,自注意力机制也存在计算复杂度高、内存占用大、缺乏局部性建模以及语义理解有局限性等不足。**未来的研究可以围绕降低计算复杂度和内存占用、增强局部性建模能力以及提升语义理解深度等方向展开。
对于研究者和开发者来说,深入理解自注意力机制的原理、优势与不足,不仅有助于更好地应用Transformer架构解决实际问题,还能为进一步改进和创新模型提供坚实的理论基础。在未来的研究中,我们可以期待看到更多基于自注意力机制的改进和拓展,以及其在更多领域的广泛应用。
最后
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。

最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师给大家这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下


这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 2467
2467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









