




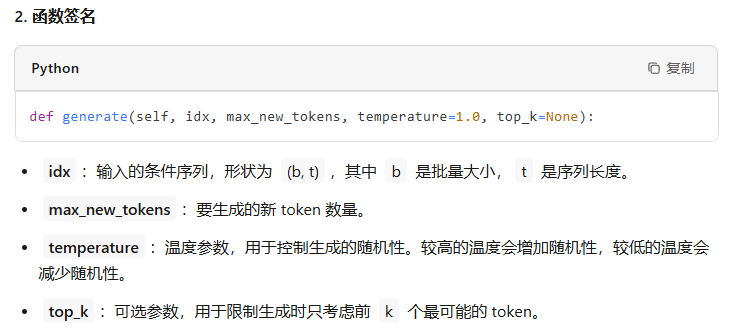
前言
要理解大语言模型(LLM),首先要理解它的本质,无论预训练、微调还是在推理阶段,核心都是next token prediction,也就是以自回归的方式从左到右逐步生成文本。
什么是 token
token是指文本中的一个词或者子词,给定一句文本,送入语言模型前首先要做的是对原始文本进行tokenize,也就是把一个文本序列拆分为离散的token序洌

其中,tokenize是在无标签的语料上训练得到的一个token数量固定且唯一的分词器,这里的token数量就是大家常说的词表
英文中的 Token
- 在英文中,Token 通常是单词、子词或标点符号。一个单词可能对应一个 Token,也可能被拆分为多个 Token。例如,“unhappiness” 可能被拆分为 “un”、“happi” 和 “ness”。
- 一般来说,1 个 Token 对应 3 至 4 个字母,或者约 0.75 个单词。
中文中的 Token
- 在中文中,Token 通常是单个汉字或经过分词后的词语。例如,“人工智能” 可能被拆分为 “人工” 和 “智能”。
- 不同平台对 Token 的定义有所不同。例如,通义千问和千帆大模型中 1 Token 等于 1 个汉字,而腾讯混元大模型中 1 Token 约等于 1.8 个汉字
当我们对文本进行分词后,每个token可以对应一个embedding,这也就是语言模型中的embedding层,获得某个token的embedding就类似一个查表的过程
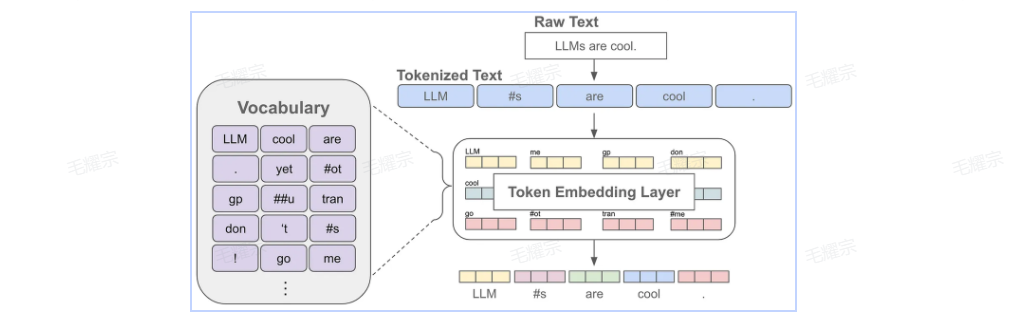
我们知道文本序列是有顺序的,而常见的语言模型都是基于注意力机制的transformer结构,无法自动考虑文本的前后顺序,因此需要自动加上位置编码,也就是每个位置有一个位置embedding 然后和对应位置的token embedding进行相加
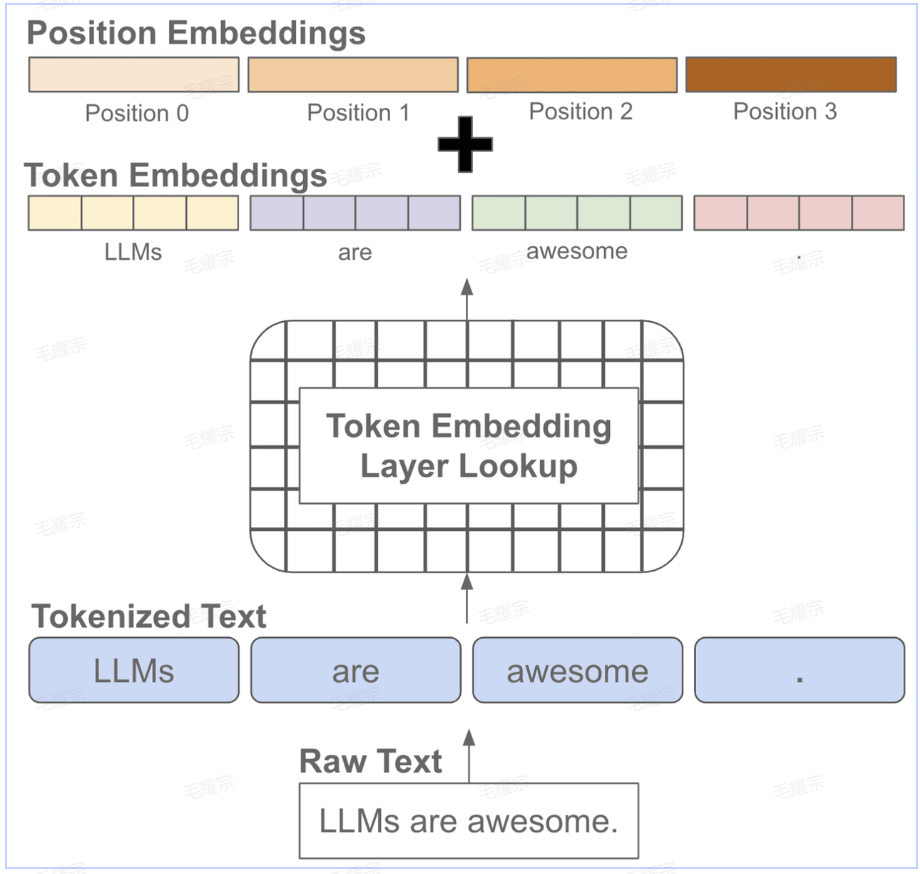
在模型训练或推理阶段大家经常会听到上下文长度这个词,它指的是模型训练时接收的token训练的最大长度,如果在训练阶段只学习了一个较短长度的位置embedding,那模型在推理阶段就不能够适用于较长文本(因为它没见过长文本的位置编码)
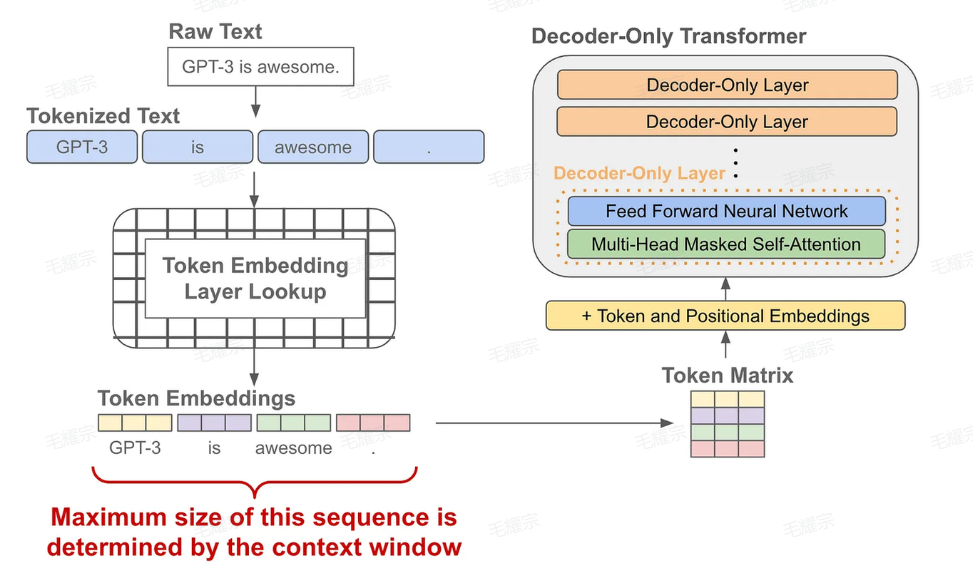

语言模型的预训练
当我们有了token的embedding和位置embedding后,将它们送入一个decoder-only的transofrmer模型,它会在每个token的位置输出一个对应的embedding(可以理解为就像是做了个特征加工)
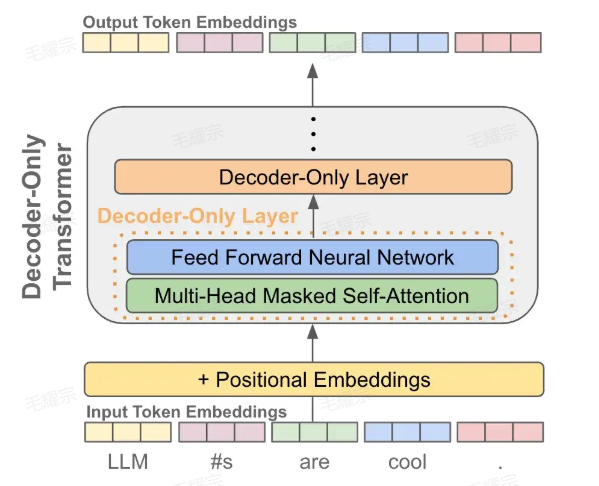
有了每个token的一个输出embedding后,我们就可以拿它来做 next token prediction了,其实就是当作一个分类问题来看待:
- 首先我们把输出embedding送入一个线性层,输出的维度是词表的大小,就是让预测这个token的下一个token属于词表的"哪一个"
- 为了将输出概率归一化,需要再进行一个softmax变换
- 训练时就是最大化这个概率使得它能够预测真实的下一个token
- 推理时就是从这个概率分布中采样下一个token
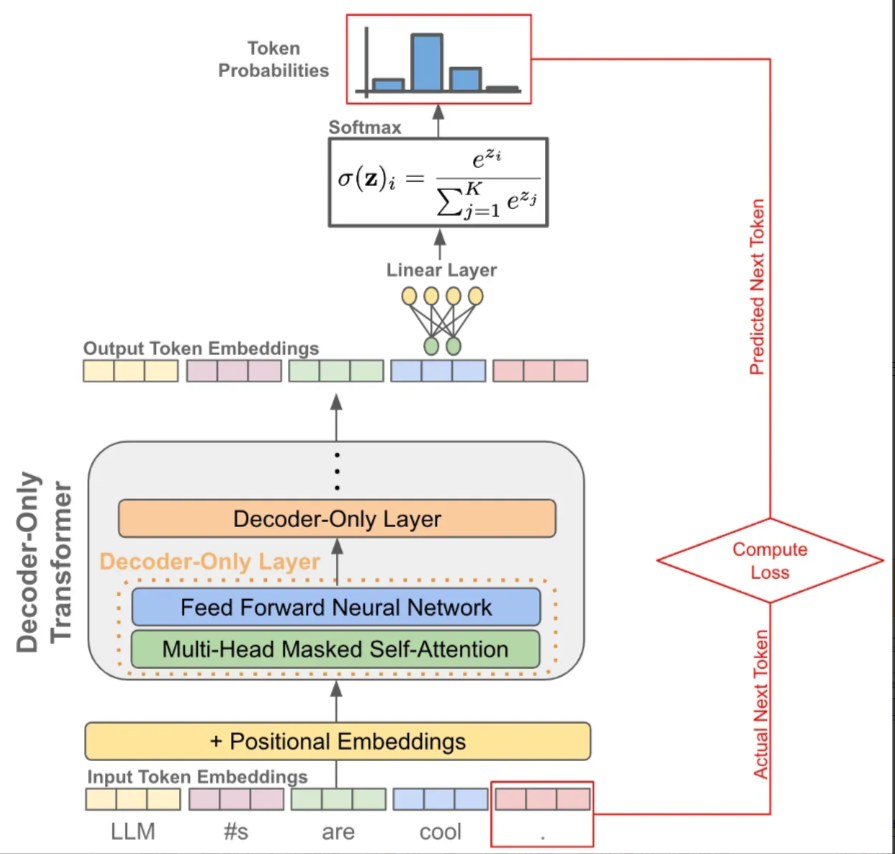
训练阶段: 因为有 **因果自注意力(Causal Self-Attention)**的存在,我们可以一次性对一整个句子每个token进行下一个token的预测,并计算所有位置token的loss
因果自注意力通过引入一个“掩码”(mask)来实现这一机制。具体来说:
- 在计算注意力权重时,模型会将当前时刻之后的所有位置的注意力权重设置为零。
- 这样,模型在预测下一个词时,只能基于已经生成的词(即前面的词)来进行预测。
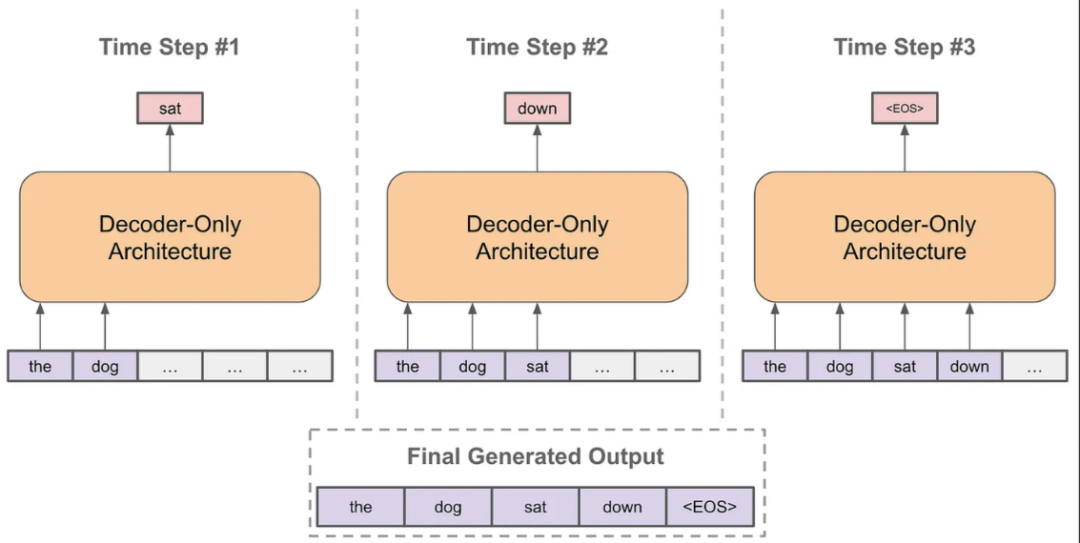
推理阶段:以自回归的方式进行预测
 |  |
|---|---|
其中,在预测下一个token时,每次我们都有一个概率分布用于采样,根据不同场景选择采样策略会略有不同,比如有贪婪策略、核采样、Top-k采样等,另外经常会看到Temperature这个概念,它是用来控制生成的随机性的,温度系数越小越稳定。
代码实现
https://github.com/karpathy/nanoGPT/tree/master
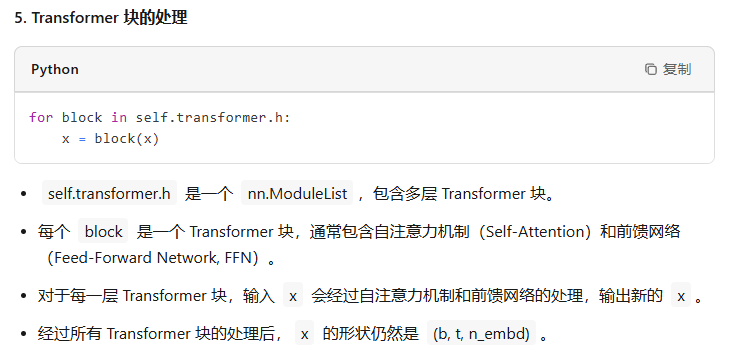
对于各种基于Transformer的模型,它们都是由很多个Block堆起来的,每个Block主要有两个部分组成:
- Multi-headed Causal Self-Attention
- Feed-forward Neural Network
结构的示意图如下:
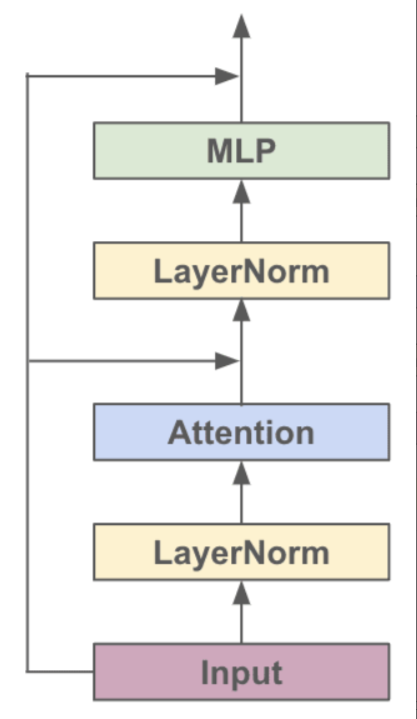
看图搭一下单个Block
class Block(nn.Module): def __init__(self, config): super().__init__() self.ln_1 = LayerNorm(config.n_embd, bias=config.bias) self.attn = CausalSelfAttention(config) self.ln_2 = LayerNorm(config.n_embd, bias=config.bias) self.mlp = MLP(config) def forward(self, x): x_ = x + self.attn(self.ln_1(x)) x = x + self.mlp(self.ln_2(x_)) return x
整个nano-GPT的结构
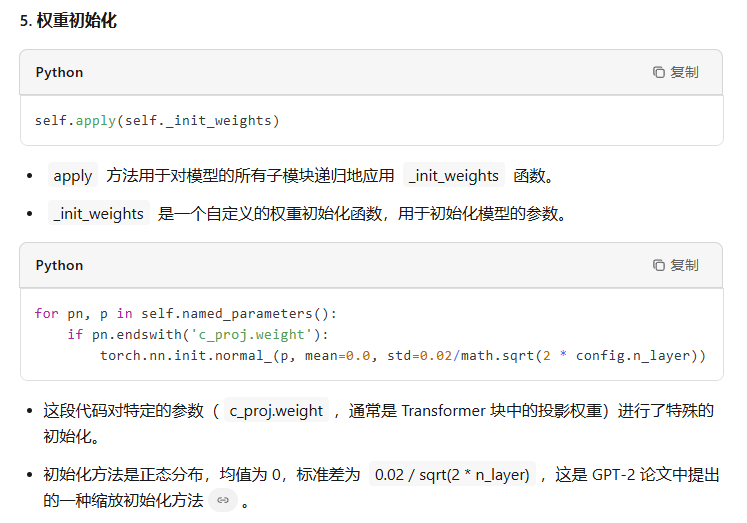
class GPT(nn.Module): def __init__(self, config): super().__init__() assert config.vocab_size is not None assert config.block_size is not None self.config = config self.transformer = nn.ModuleDict(dict( wte = nn.Embedding(config.vocab_size, config.n_embd), wpe = nn.Embedding(config.block_size, config.n_embd), drop = nn.Dropout(config.dropout), h = nn.ModuleList([Block(config) for _ in range(config.n_layer)]), ln_f = LayerNorm(config.n_embd, bias=config.bias), )) self.lm_head = nn.Linear(config.n_embd, config.vocab_size, bias=False) # with weight tying when using torch.compile() some warnings get generated: # "UserWarning: functional_call was passed multiple values for tied weights. # This behavior is deprecated and will be an error in future versions" # not 100% sure what this is, so far seems to be harmless. TODO investigate self.transformer.wte.weight = self.lm_head.weight # https://paperswithcode.com/method/weight-tying # init all weights self.apply(self._init_weights) # apply special scaled init to the residual projections, per GPT-2 paper for pn, p in self.named_parameters(): if pn.endswith('c_proj.weight'): torch.nn.init.normal_(p, mean=0.0, std=0.02/math.sqrt(2 * config.n_layer))
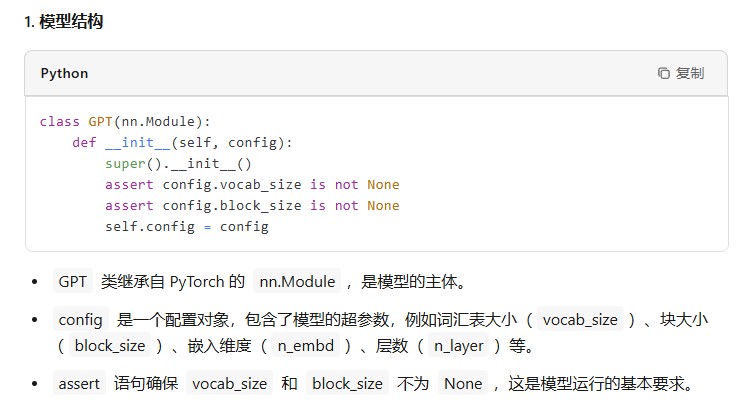
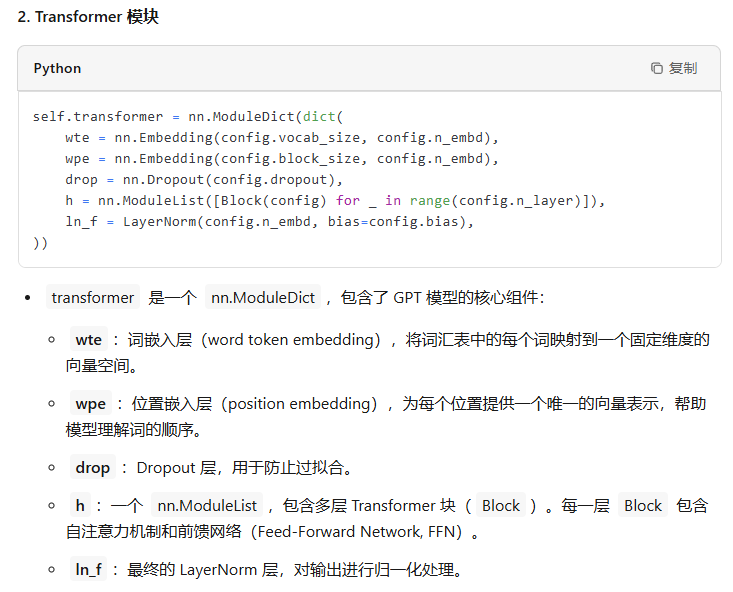
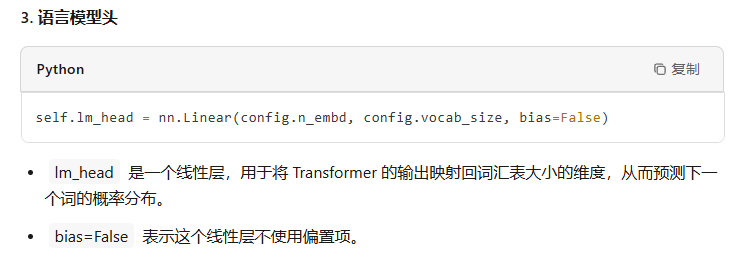
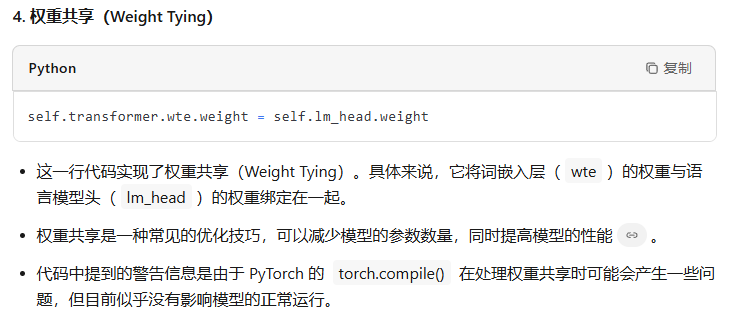
最后一层用来分类的线性层的权重和token embedding层的权重共享。
训练和推理的forward
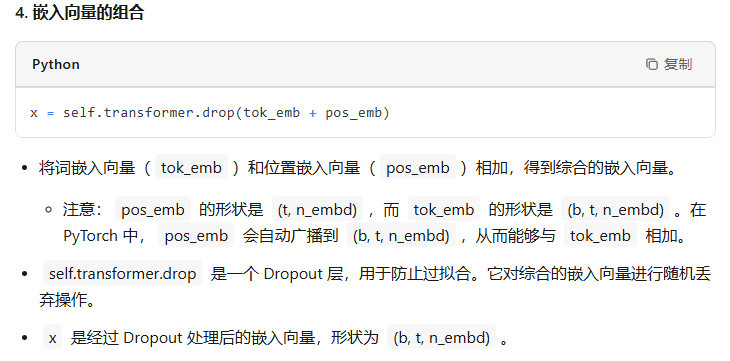
首先需要构建token embedding和位置embedding,把它们叠加起来后过一个dropout,然后就可以送入transformer的block中了。
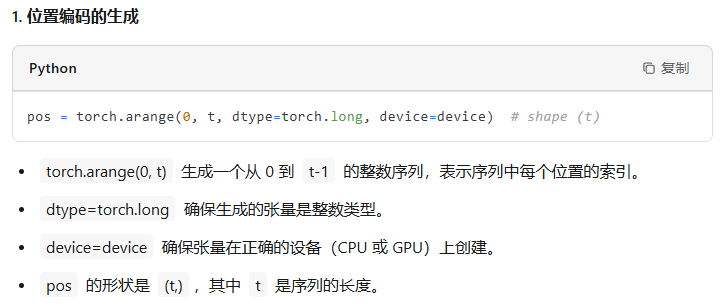
pos = torch.arange(0, t, dtype=torch.long, device=device) # shape (t)# forward the GPT model itselftok_emb = self.transformer.wte(idx) # token embeddings of shape (b, t, n_embd)pos_emb = self.transformer.wpe(pos) # position embeddings of shape (t, n_embd)x = self.transformer.drop(tok_emb + pos_emb)for block in self.transformer.h: x = block(x)x = self.transformer.ln_f(x)



接下来看推理阶段
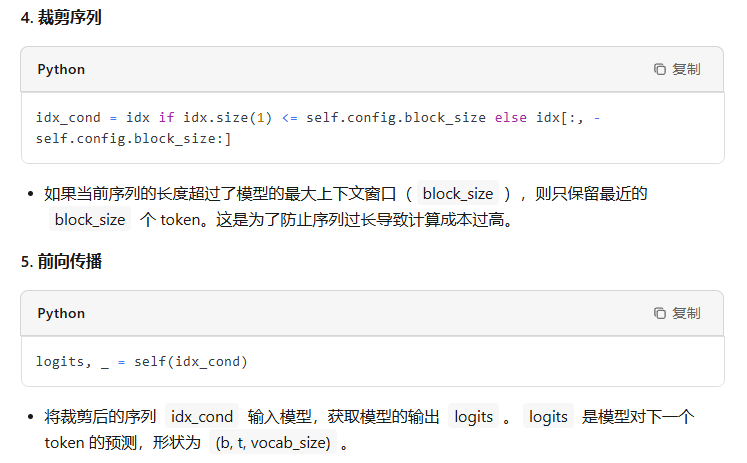
- 根据当前输入序列进行一次前向传播
- 利用温度系数对输出概率分布进行调整
- 通过softmax进行归一化
- 从概率分布进行采样下一个token
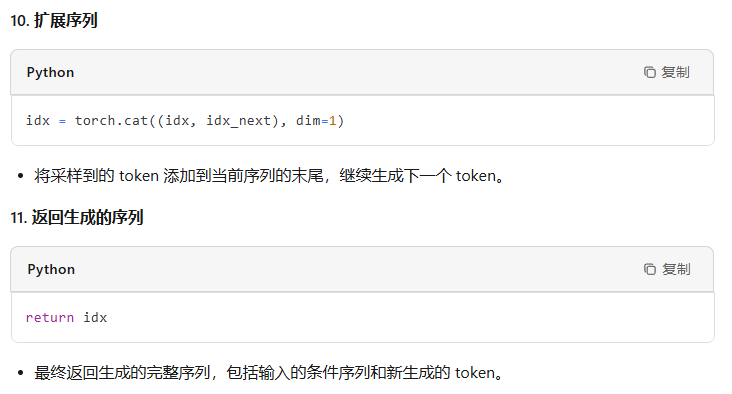
- 拼接到当前句子并再进入下一轮循环
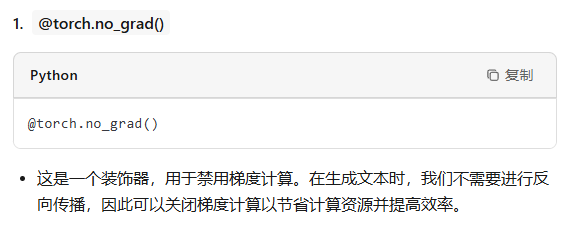
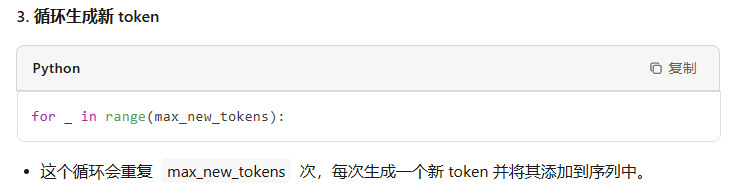
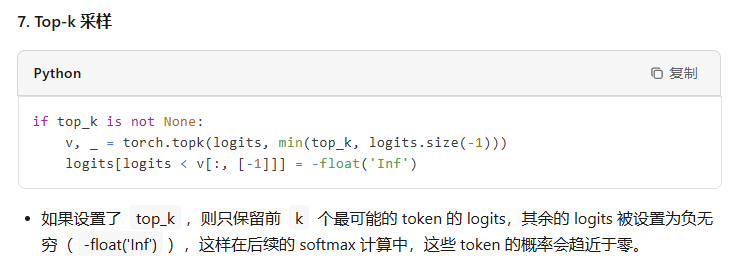
@torch.no_grad() def generate(self, idx, max_new_tokens, temperature=1.0, top_k=None): """ Take a conditioning sequence of indices idx (LongTensor of shape (b,t)) and complete the sequence max_new_tokens times, feeding the predictions back into the model each time. Most likely you'll want to make sure to be in model.eval() mode of operation for this. """ for _ in range(max_new_tokens): # if the sequence context is growing too long we must crop it at block_size idx_cond = idx if idx.size(1) <= self.config.block_size else idx[:, -self.config.block_size:] # forward the model to get the logits for the index in the sequence logits, _ = self(idx_cond) # pluck the logits at the final step and scale by desired temperature logits = logits[:, -1, :] / temperature # optionally crop the logits to only the top k options if top_k is not None: v, _ = torch.topk(logits, min(top_k, logits.size(-1))) logits[logits < v[:, [-1]]] = -float('Inf') # apply softmax to convert logits to (normalized) probabilities probs = F.softmax(logits, dim=-1) # sample from the distribution idx_next = torch.multinomial(probs, num_samples=1) # append sampled index to the running sequence and continue idx = torch.cat((idx, idx_next), dim=1) return idx

温度参数(Temperature)的作用
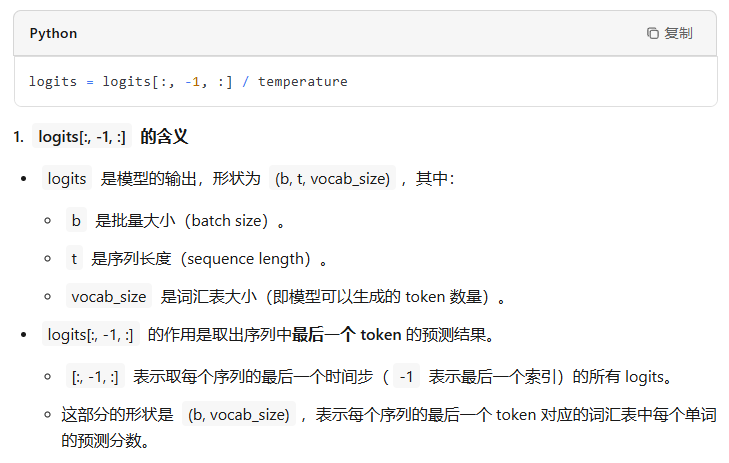
温度参数 temperature 是一个超参数,用于控制生成文本的随机性。它的作用是调整 logits 的分布,从而影响最终的概率分布。
具体来说:
-
temperature > 1:增加随机性 -
当温度参数大于 1 时,会放大 logits 的值,使得 logits 的分布更加“平坦”。
-
这意味着在 softmax 转换为概率分布后,各个 token 的概率会更加接近,从而增加生成结果的随机性。
-
例如,假设原始 logits 是
[10, 20, 30],除以温度参数 2 后变为[5, 10, 15],经过 softmax 后,概率分布会更加均匀。 -
temperature < 1:减少随机性 -
当温度参数小于 1 时,会缩小 logits 的值,使得 logits 的分布更加“尖锐”。
-
这意味着在 softmax 转换为概率分布后,高概率的 token 会更加突出,而低概率的 token 的概率会进一步降低,从而减少生成结果的随机性。
-
例如,假设原始 logits 是
[10, 20, 30],除以温度参数 0.5 后变为[20, 40, 60],经过 softmax 后,概率分布会更加集中在高概率的 token 上。 -
temperature = 1:保持原始分布 -
当温度参数等于 1 时,logits 不变,模型的输出概率分布保持原始的预测结果。
为什么要调整温度参数?
-
增加随机性(
temperature > 1): -
有助于生成更多样化的文本,避免模型总是生成相同的、高概率的 token。
-
适用于需要创造性或多样性的场景,例如诗歌生成、故事创作等。
-
减少随机性(
temperature < 1): -
有助于生成更稳定、更符合预期的文本,减少生成的噪声。
-
适用于需要高准确性的场景,例如机器翻译、问答系统等。
最后
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。

最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师给大家这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下


这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 1722
1722

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









