



前言
最近很多初学者在聊天当中,提到了Transformer模型。在前几天的发文中也说了几次。
今天还是想以非常直观、简单的语言,让大家有一个大的轮廓,从而更清晰的、更好的学习后面的理论部分。
最初听过一个很简单的例子:想象你在读一篇文章,如果你只能逐字阅读,你会花很长时间才能理解每个句子。但如果你能一次看到整篇文章,你会更快抓住文章的意思。Transformer 的能力就像这样,能一次性处理整个输入,从而更快、更准确地理解数据。
这里,我们再用一个非常直观地例子给大家~
假设你加入了一个多语言的在线聊天室,有些人用中文发送消息,有些人用英文。作为一个只懂英语的 Transformer 模型,让我们分步骤来看它如何处理消息:
1. 接收消息和理解(编码器)
每当有人发送一条消息,比如:
-
中文:“你好,最近怎么样?”
-
英文:“Hello, how have you been lately?”
作为一个 Transformer 模型:
-
编码器:首先,它会将每个词语转换成向量(数字表示),比如 “你好” 可能被转换成一个向量 [0.1, -0.3, 0.5],而 “Hello” 可能被转换成 [0.2, 0.4, -0.1]。这些向量捕捉了每个词的语义信息。
-
注意力机制:Transformer 通过注意力机制来决定每个词在当前上下文中的重要性。比如,在理解 “你好,最近怎么样?” 这句话时,注意力机制可能会更关注 “最近” 和 “怎么样” 这些词,因为它们提供了关于时间和状态的信息。
2. 理解和生成(解码器)
当编码器把消息转换成内部表示后,解码器负责生成回复:
- 解码器:它根据之前编码器处理的信息和自身的知识,生成适当的回复。比如,在回复 “你好,最近怎么样?” 时,解码器可能生成 “Hello, I’ve been good, thanks!” 这样的英文回复。
3. 处理多语言
现在假设聊天室中有:
-
一个说中文的朋友,发送了 “你好,最近怎么样?”
-
一个说英文的朋友,发送了 “Hello, how have you been lately?”
作为 Transformer 模型:
- 多头注意力机制:它能够并行处理这两种语言的消息。对于 “你好,最近怎么样?” 和 “Hello, how have you been lately?” 这两条消息,Transformer 可以同时分析它们的语义和重要信息,找出它们之间的对应关系,从而理解并生成合适的回复。
通过编码器和解码器的组合,利用注意力机制和多头注意力机制来有效地理解和生成文本数据,无论消息是中文还是英文,都能够得到适当的处理和回复。
Transformer 特别擅长处理序列数据,如自然语言文本。最初由 Google 提出的 Transformer 被用来处理文本翻译任务,现在它在多种任务中表现优异,包括文本生成、分类和信息提取等。和传统的序列模型(如 RNN)不同,Transformer 通过并行处理整个输入序列,大大提高了处理速度和效率。
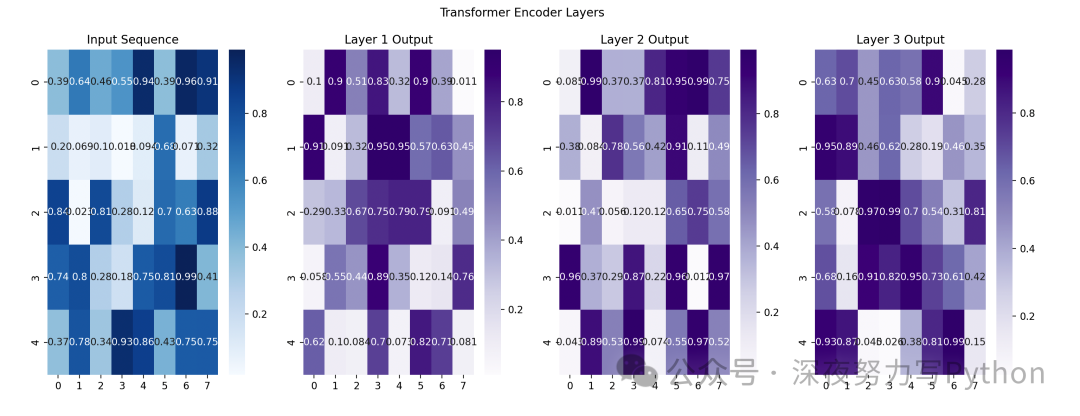
基本原理
Transformer 的核心组件是 注意力机制 (Attention Mechanism),它允许模型在处理每个元素时,同时参考输入序列中的所有其他元素。
Transformer 主要由两个部分组成:编码器(Encoder)和 解码器(Decoder)。
编码器:
-
输入数据经过编码器层,转换为一系列向量表示。
-
每个编码器层由 多头注意力机制 (Multi-Head Attention) 和 前馈神经网络 (Feed-Forward Neural Network) 组成。
解码器:
-
解码器也有多层,每层同样由多头注意力机制和前馈神经网络组成。
-
解码器会利用编码器的输出和已生成的序列来生成新输出。
注意力机制
注意力机制的目标是根据输入的每个单词生成一个权重,表示该单词对当前任务的重要性。计算这些权重的过程称为点积注意力 (Scaled Dot-Product Attention),其公式如下:
其中:
-
是查询矩阵 (Query)。
-
是键矩阵 (Key)。
-
是值矩阵 (Value)。
-
是键的维度(用于缩放)。
多头注意力机制
为了捕捉不同位置之间的关系,Transformer 使用 多头注意力机制 (Multi-Head Attention),它将查询、键、值矩阵拆分为多组,然后独立地应用注意力机制,最后将这些结果合并。
其中:
-
是线性变换矩阵。
-
是输出变换矩阵。
完整案例
下面我们通过一个简单的 Python 代码示例,演示如何使用 Transformer 进行文本分类。
代码中,使用 PyTorch 和其 Transformer 模块。
准备数据
我们使用一个示例数据集,其中每个句子被标注为正面或负面。
import torch
from torch.utils.data import Dataset, DataLoader
from transformers import BertTokenizer
# 示例数据集
class SimpleDataset(Dataset):
def __init__(self, texts, labels):
self.texts = texts
self.labels = labels
self.tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
self.max_len = 128
def __len__(self):
return len(self.texts)
def __getitem__(self, idx):
text = self.texts[idx]
label = self.labels[idx]
encoding = self.tokenizer.encode_plus(
text,
add_special_tokens=True,
max_length=self.max_len,
return_token_type_ids=False,
padding='max_length',
truncation=True,
return_attention_mask=True,
return_tensors='pt',
)
return {
'text': text,
'input_ids': encoding['input_ids'].flatten(),
'attention_mask': encoding['attention_mask'].flatten(),
'labels': torch.tensor(label, dtype=torch.long)
}
# 创建数据集
texts = ["I love this movie!", "This was a terrible film."]
labels = [1, 0]
dataset = SimpleDataset(texts, labels)
dataloader = DataLoader(dataset, batch_size=2, shuffle=True)
定义模型
我们使用预训练的 BERT 模型进行分类任务。
from transformers import BertModel, BertConfig
import torch.nn as nn
class SimpleTransformerModel(nn.Module):
def __init__(self, num_labels):
super(SimpleTransformerModel, self).__init__()
self.bert = BertModel.from_pretrained('bert-base-uncased')
self.classifier = nn.Linear(self.bert.config.hidden_size, num_labels)
def forward(self, input_ids, attention_mask):
outputs = self.bert(input_ids=input_ids, attention_mask=attention_mask)
pooled_output = outputs[1] # 取池化后的输出
logits = self.classifier(pooled_output)
return logits
# 初始化模型
model = SimpleTransformerModel(num_labels=2)
训练模型
简单的训练过程如下:
import torch.optim as optim
from torch.nn import CrossEntropyLoss
# 损失函数和优化器
criterion = CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=2e-5)
# 训练循环
model.train()
for epoch in range(3): # 训练 3 个 epoch
for batch in dataloader:
optimizer.zero_grad()
input_ids = batch['input_ids']
attention_mask = batch['attention_mask']
labels = batch['labels']
outputs = model(input_ids, attention_mask)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
print(f'Epoch {epoch+1}, Loss: {loss.item()}')
最后
Transformer 目前来说是一种非常重要的架构。它通过注意力机制高效处理序列数据,克服了传统模型的许多限制。
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 5510
5510

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









