



前言
从ChatGPT上线开始,我就有了一个想法,打造一个个人知识库,它可以充当我的第二大脑,记住我的尽量多的信息(包括隐私信息)。
无论是我每天的琐碎事务,还是重要的决策和回忆,它都能存储并快速检索。当我问它“我去年5月做了什么?”时,它不仅能够从知识库中找到当时的记录,还能结合上下文和细节,帮助我回忆起那些可能遗忘的瞬间。
但要实现这个想法,用在线服务肯定是不行的,我需要它完全本机运行。现在,有了可完全本机部署的deepseek-r1和bge-m3,加上界面优雅的Cherry Studio,是时候实现它了。
注意1:以下步骤在苹果M系列芯片,16G内存的MacBook Pro上实现。由于Mac拥有统一内存和显存,类似配置的PC除了16G及以上的内存外,还需要有额外的显存分配才能正常运行。
注意2:先不要吐槽非满血版deepseek-r1的模型效果,可以先学会怎么本机部署,往后开源的模型会越来越好的(一年前谁能想到现在端侧大模型效果这么好了呢)。
直接开始:
1、下载安装ollama: https://ollama.com/download
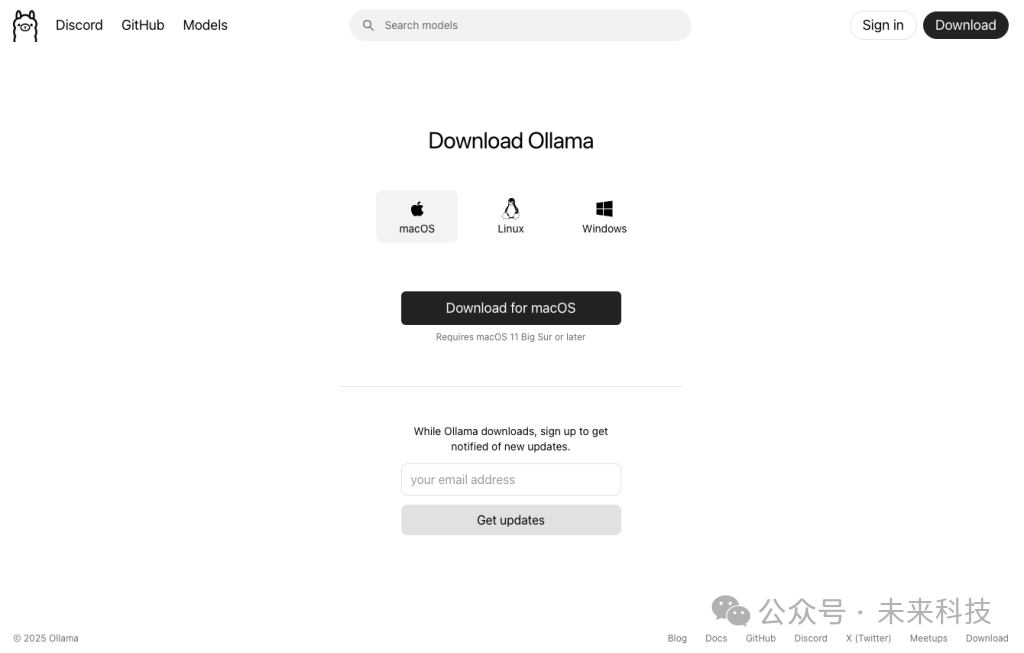
按自己的电脑系统选择即可,安装后,双击启动。
2、下载DeepSeek-R1:14b模型(9GB)
这里我选择了我的设备能运行的最大尺寸的模型,14b参数的这个。打开终端,输入命令:ollama run deepseek-r1:14b
回车之后,模型就开始下载啦,确保电脑硬盘还有足够的剩余空间(下图示意是7b参数的版本,共4.7GB)
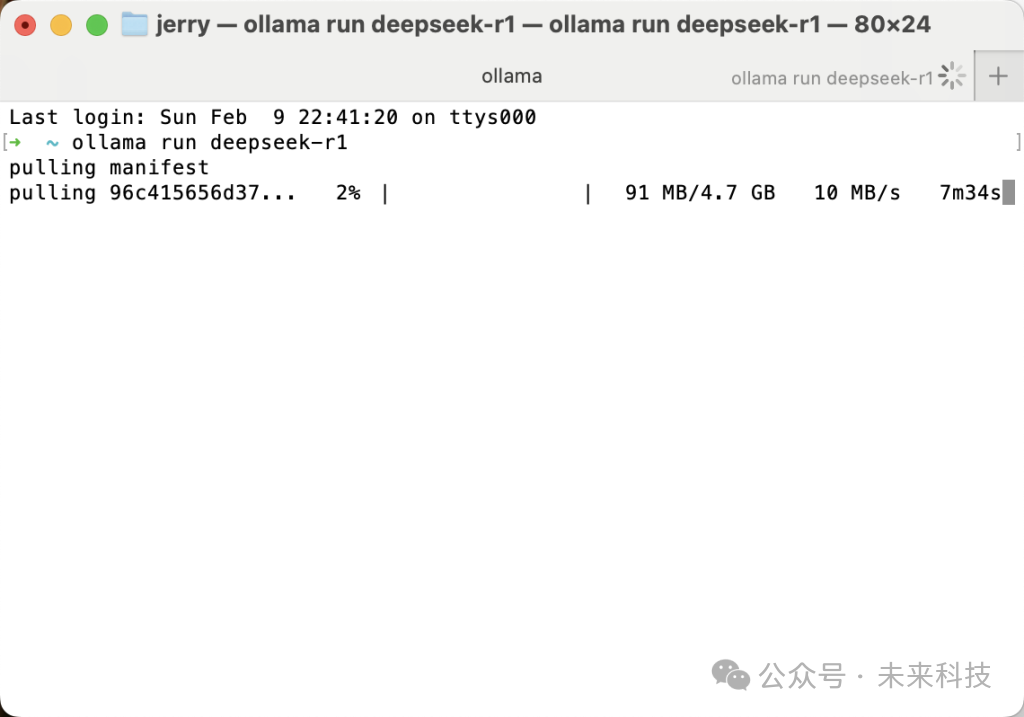
等待模型下载完成后,当你看到 >>> 提示符,这时已经可以跟模型聊天啦,让我们来试试:

到这里,如果你不需要知识库,你已经完成了deepseek-r1模型的本地部署,是不是很简单?只是这个聊天界面在命令行中,也无法保存跟deepseek的聊天记录。
拓展阅读: 更多尺寸的模型下载命令可以在这里找到:https://ollama.com/library/deepseek-r1
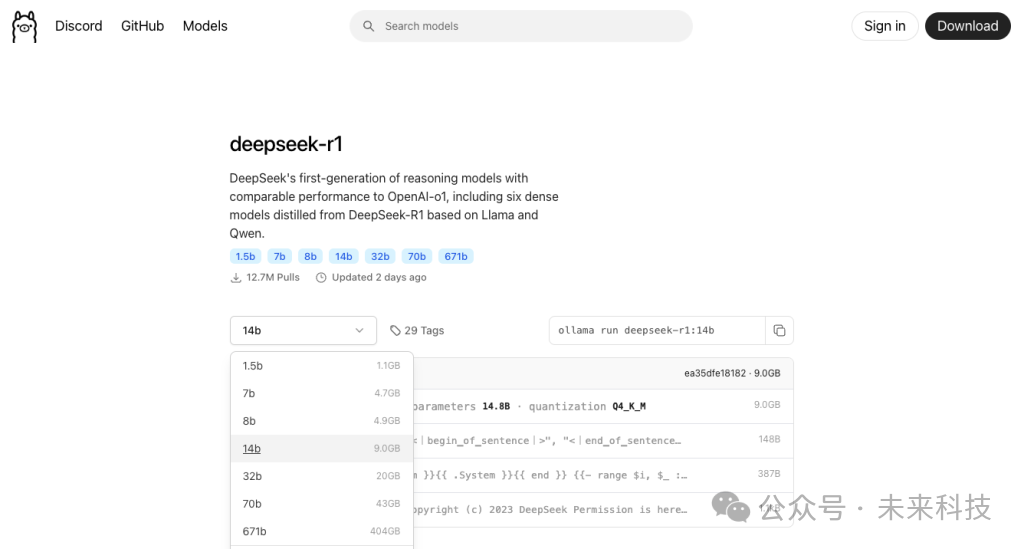
也可以在顶部Models菜单中找到其他的开源模型,比如阿里的通义千问qwen2.5、智谱的GLM-4、Meta的Llama3.2等等,有兴趣都可以试试,Ollama支持多个模型同时安装。
查看已安装模型的命令:ollama list
删除已安装模型的命令(rm后是要删除的模型名称):ollama rm deepseek-r1:14b
3、下载embedding模型 bge-m3(1.2GB)
打开终端,输入命令:ollama pull bge-m3
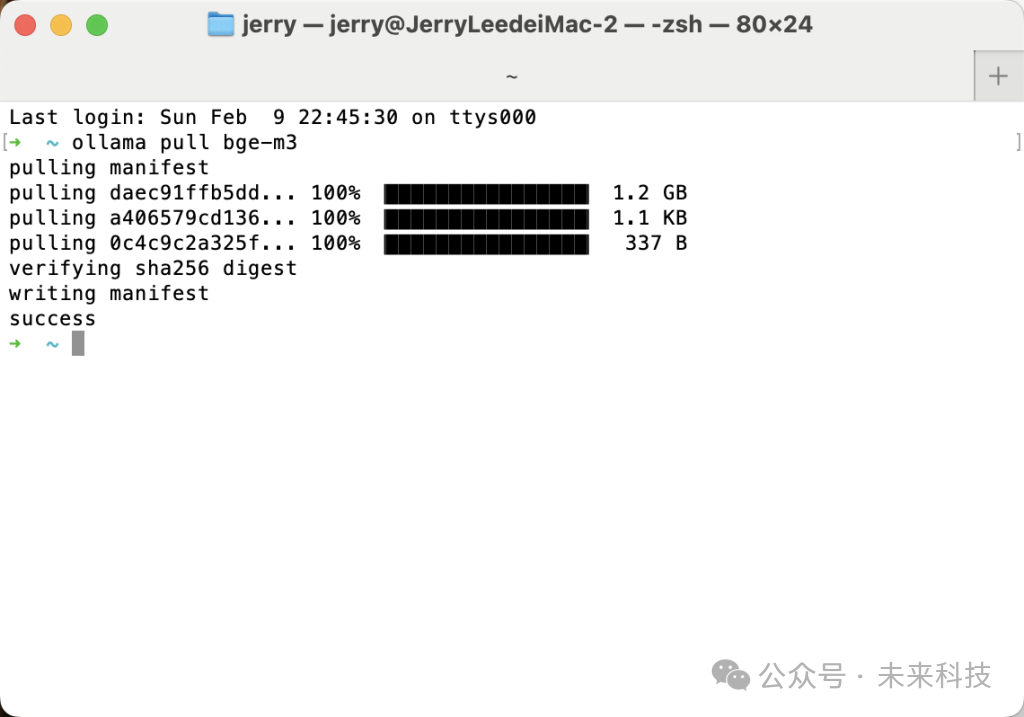
等待下载完毕,看到success,关闭终端就行了。embedding嵌入模型的作用是把知识库里的文档内容转化为便于搜索的向量,这里只需要理解它是用来处理知识库文档数据的即可。
4、安装Cherry Studio
访问:https://cherry-ai.com,根据电脑系统选择相应版本下载安装
Cherry Studio是一款支持本地知识库的AI客户端,其实同类产品还有很多,比如Chatbox(有联网搜索和手机端)、Enchanted(简洁轻量)、OpenWebUI(可供局域网内多人访问)等等,有兴趣的同学可以挨个体验下。
到这里我们需要下载和安装的东西都完成了,接下来断开网络也可以使用。
5、配置模型提供商:Ollama,添加LLM语言模型和embedding嵌入模型
启动Cherry Studio,依次点击左下角设置-模型服务-Ollama,开启Ollama,API地址保持默认,点击管理按钮,可以看到会自动读取到我们刚才下载的deepseek-r1:14b和bge-m3[嵌入] 两个模型,点击添加。
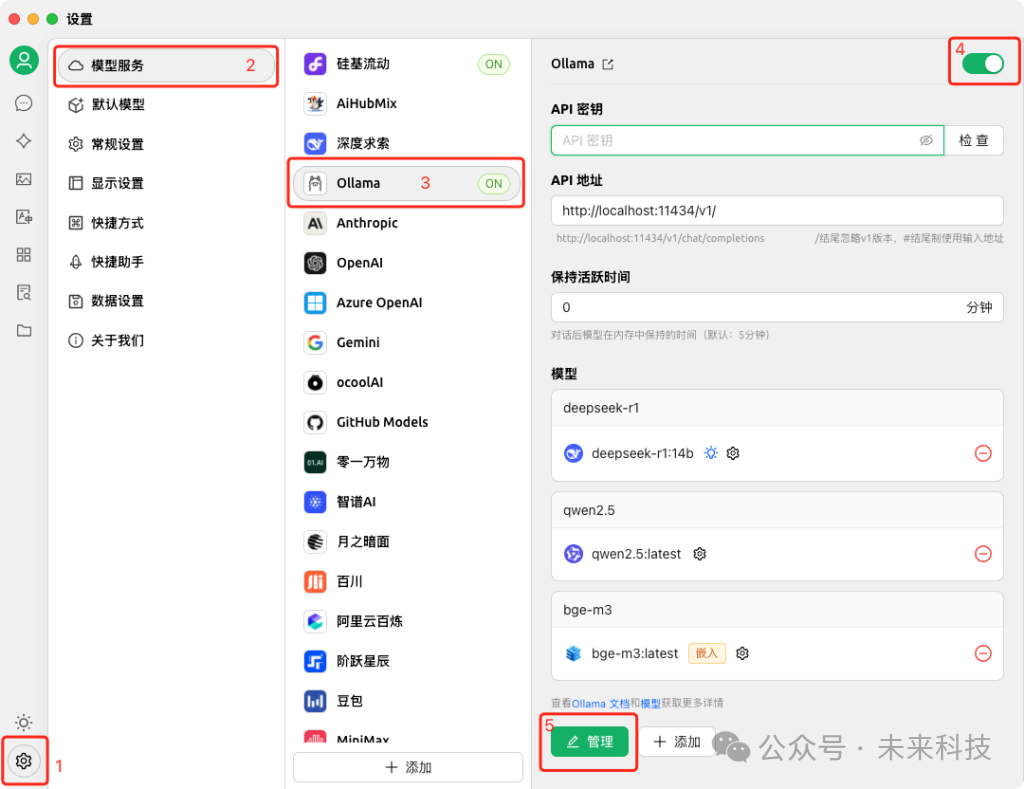
这样我们就把Ollama下载的两个模型配置到Cherry Studio中了。
拓展阅读: 在模型服务的设置这里,可以看到Cherry Studio已经支持的模型提供商,推荐大家还可以添加一个部署在siliconflow硅基流动的DeepSeek-R1满血版,但与这个模型产生的交互都需要连接网络,你的问题会被发送到siliconflow硅基流动的服务器,使用满血版会按实际用量计费,你可以根据自己的实际情况选择是否使用。配置时需要用到的api密钥,可通过这个链接https://cloud.siliconflow.cn/i/r2Z3LRPQ注册获取,现在新注册会有免费额度赠送。
6、创建知识库,导入本地文档
点击Cherry Studio左侧的知识库按钮,再点击“添加”,给知识库取个名字,嵌入模型选择我们刚才下载的bge-m3,点击确定后,即可创建出一个知识库。
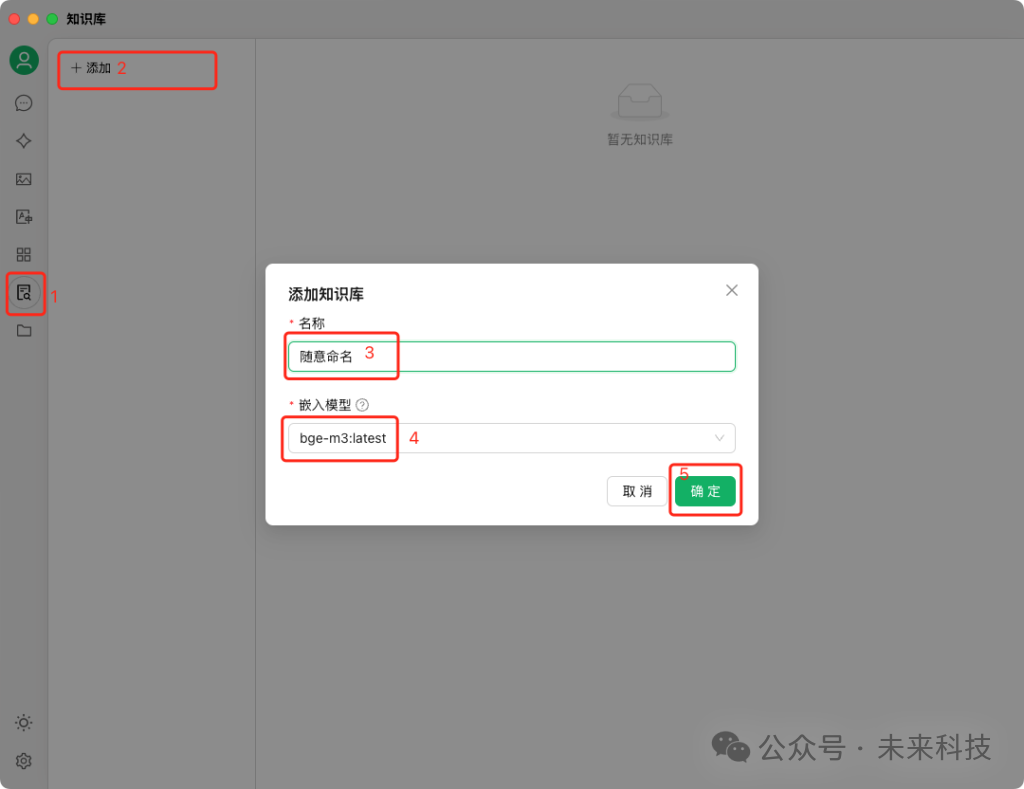
这时可以添加文件或者直接拖拽文件到知识库里,支持pdf、docx、pptx、txt等格式,把个人简历、日记、工作文档、甚至微信聊天记录(前提是手动导成文本)放进来都可以。
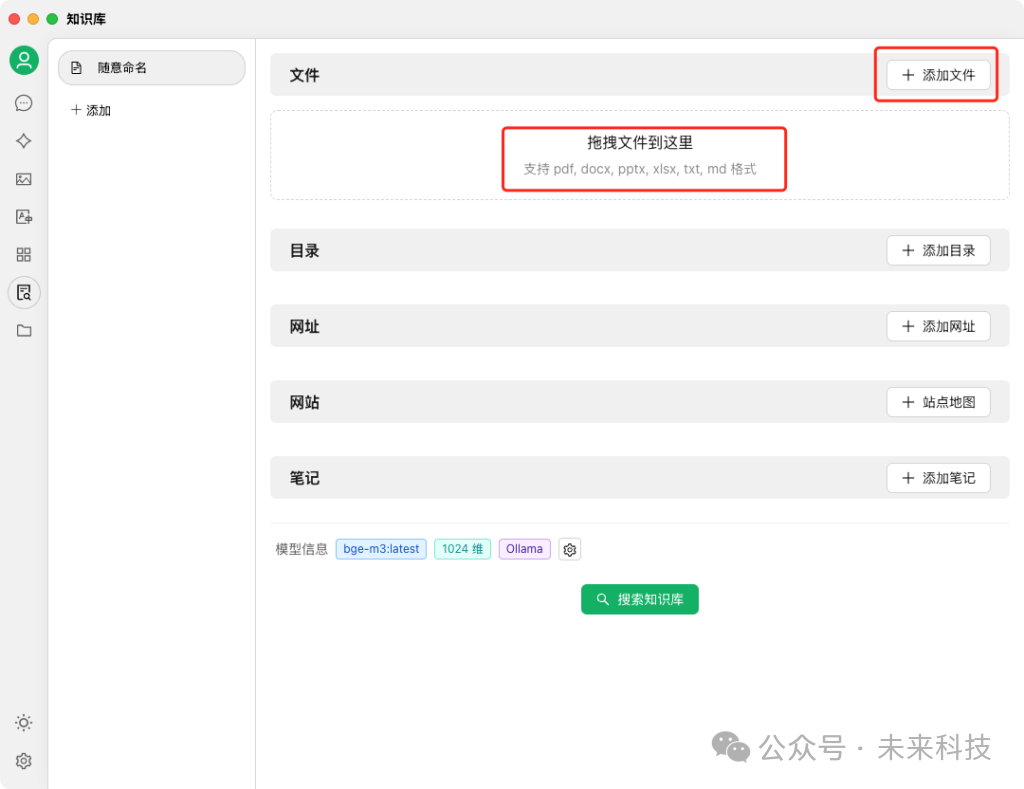
我们先加一两个文档试试,可以看到加入后,每个文档都会经过嵌入模型的处理,有个蓝色小点loading过程,如果看到绿色小勾,就代表这个文档可以被deepseek检索到了。
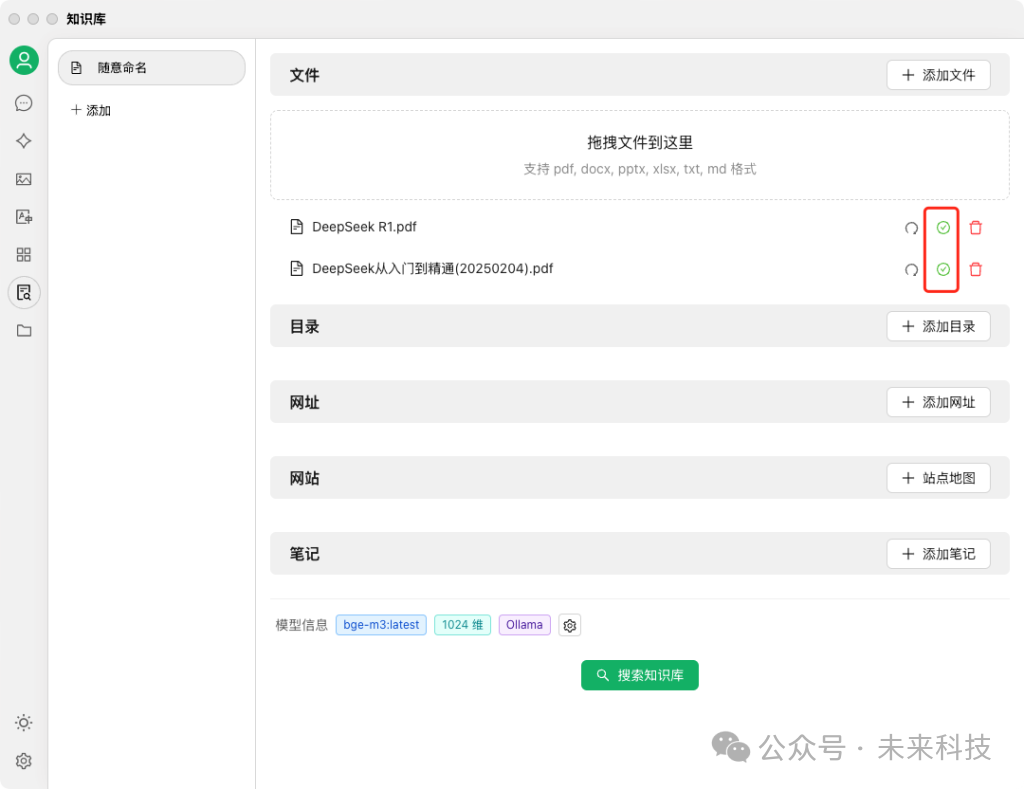
此时,DeepSeek就学习了你上传的文档。这是一种被称为RAG的技术,AI收到你的问题后,会先到知识库里找出最相关的几个片段,然后结合它自有的知识,组织一段新的表述回复给你。这样就能把AI大模型原本训练时没有的知识(比如关于你个人的信息)告诉它。
好啦,现在你电脑上的DeepSeek-R1就拥有了知晓你私人文档的知识库:回到聊天界面,顶部选择deepseek-r1:14b|Ollama这个模型,输入框下方知识库按钮选中刚才创建的知识库,现在试试询问一个DeepSeek本身不知道的问题——
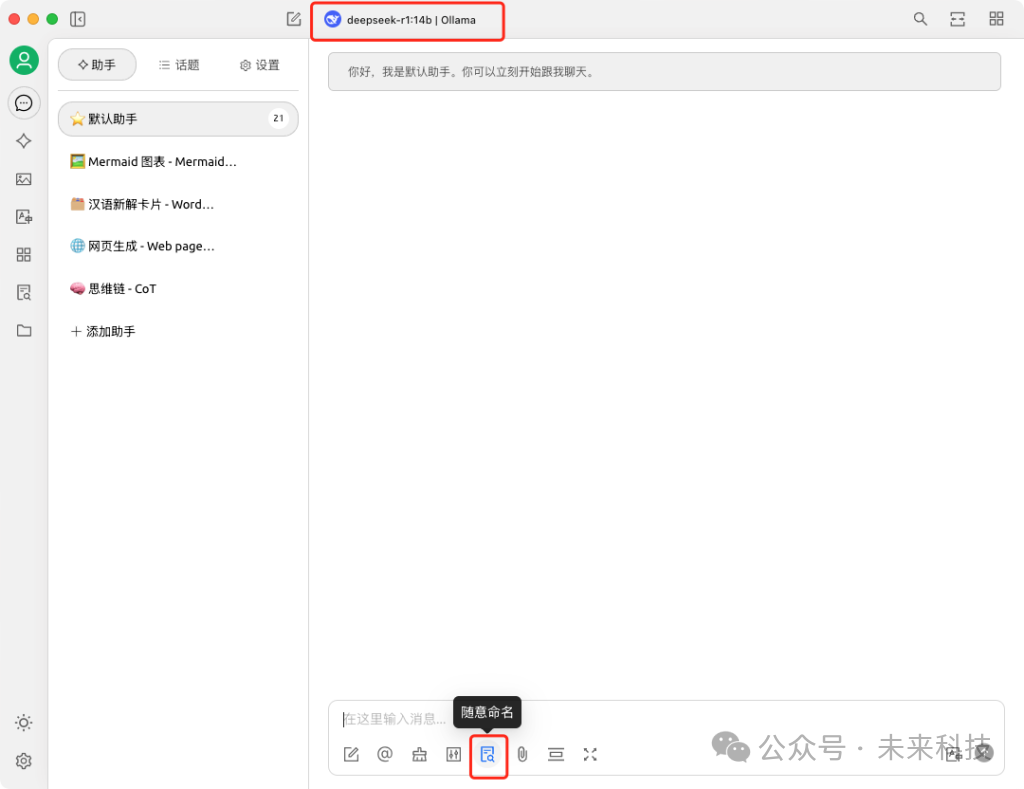
大功告成!我也要再去丰富一下我的个人知识库了
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









