




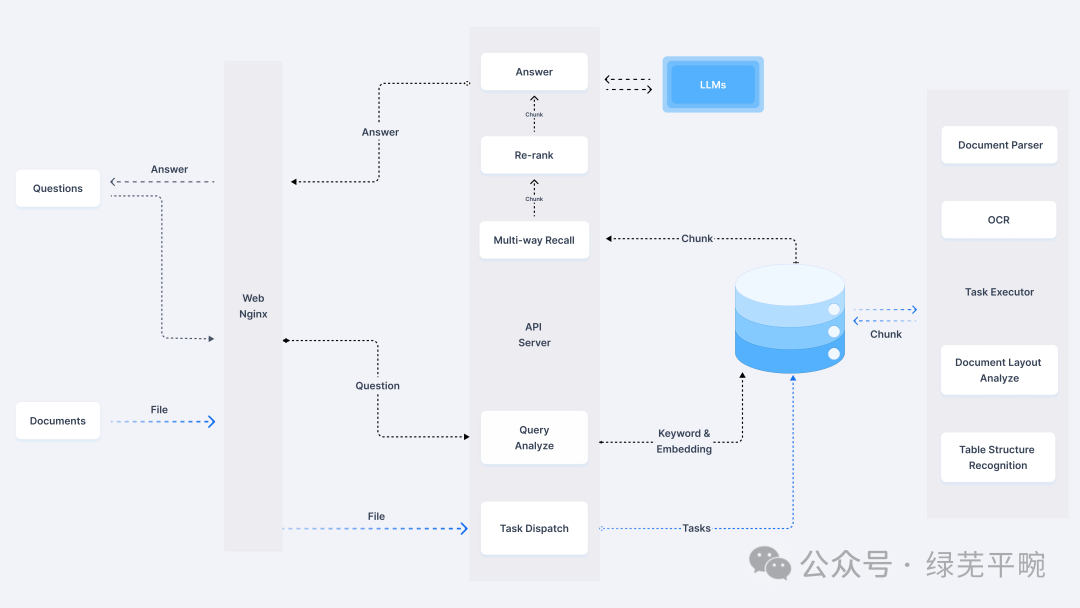
将开源的大语言预训练模型部署到用户设备上进行推理应用,特别是结合用户专业领域知识库构建AI应用,让AI在回答时更具有专业性,目前已经有很多成熟的应用方案。其中,支持大模型本地化部署的平台及工具很多,比较出名的有ollama、vLLM、LangChain、Ray Serve等,大大简化了模型的部署工作,并提供模型全生命周期管理。对应地,需要知识库构建的相应工具,能处理各种格式(doc/pdf/txt/xls等)的各种文档,能够直接读取文档并处理大量信息资源,包括文档上传、自动抓取在线文档,然后进行文本的自动分割、向量化处理,来实现本地检索增强生成(RAG)等功能。这类工具主要有RAGFlow、MaxKB、AnythingLLM、FastGPT、Dify 、Open WebUI 等。本文将采用ollama + RAGFlow方式进行搭建,系统架构如下:
1 安装ollama
ollama是一个开源的大型语言模型服务工具,旨在帮助用户在本地环境中部署和运行大型语言模型,其核心功能是提供一个简单、灵活的方式,将这些复杂的AI模型从云端迁移到本地机器上,简化大型语言模型在本地环境中的运行和管理。它不仅为开发者提供了一个强大的平台来部署和定制AI模型,而且也让终端用户能够更加私密和安全地与这些智能系统进行交互。
(1)执行如下命令安装
curl -fsSL https://ollama.com/install.sh | sh
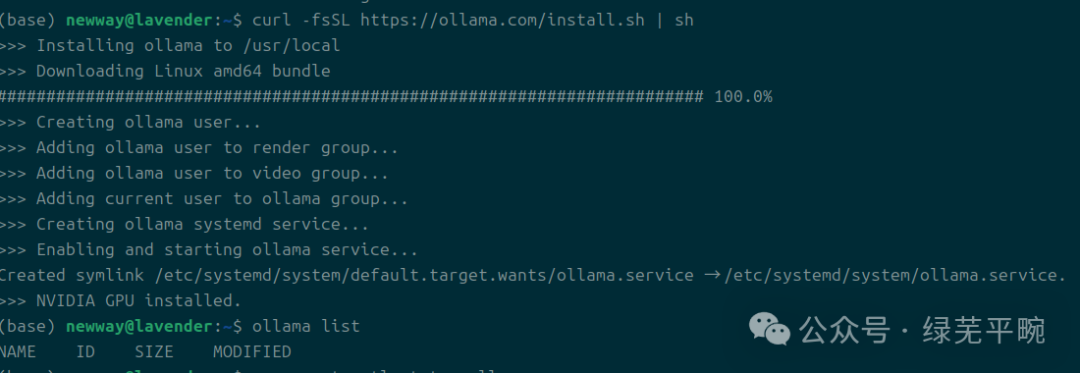
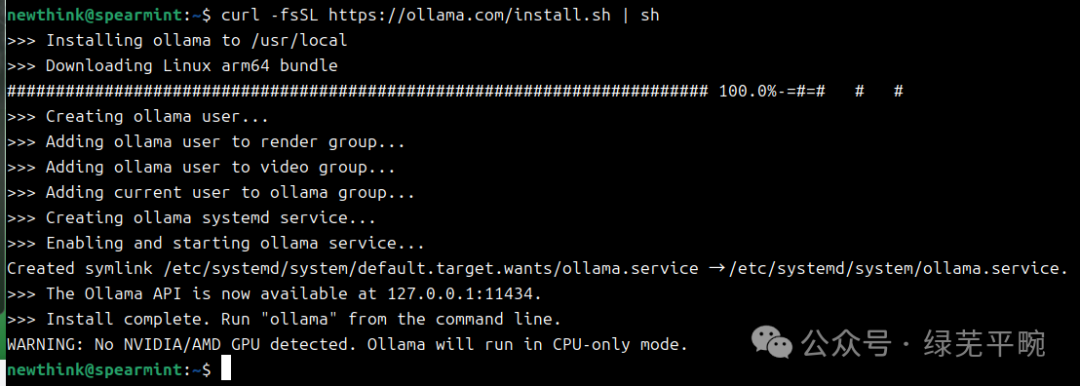
在安装过程中,ollama会识别相应的GPU加速卡,若未识别相应设备,则使用CPU模式
GPU模式“NVIDIA GPU installed”
CPU模式“No NVIDIA/AMD GPU detected. Ollama will run in CPU-only mode”
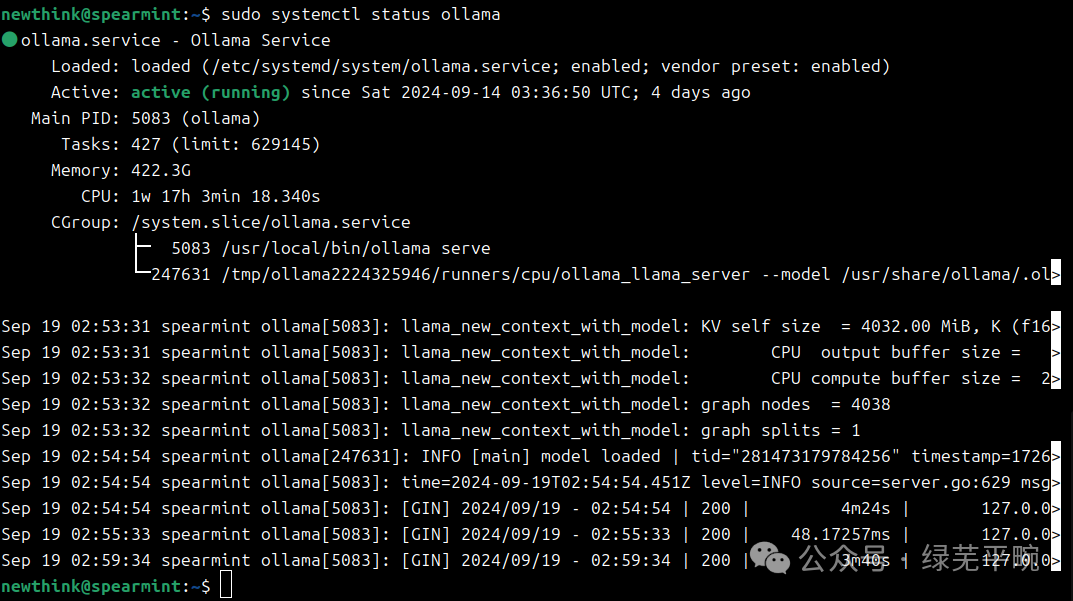
(2)安装后查看ollama状态
sudo systemctl status ollama
(3)设置ollama环境变量
sudo vi /etc/systemd/system/ollama.service
增加Environment=”OLLAMA_HOST=0.0.0.0:11434”,否则后面在RAGFlow容器环境下配置连接时,无法连接ollama.
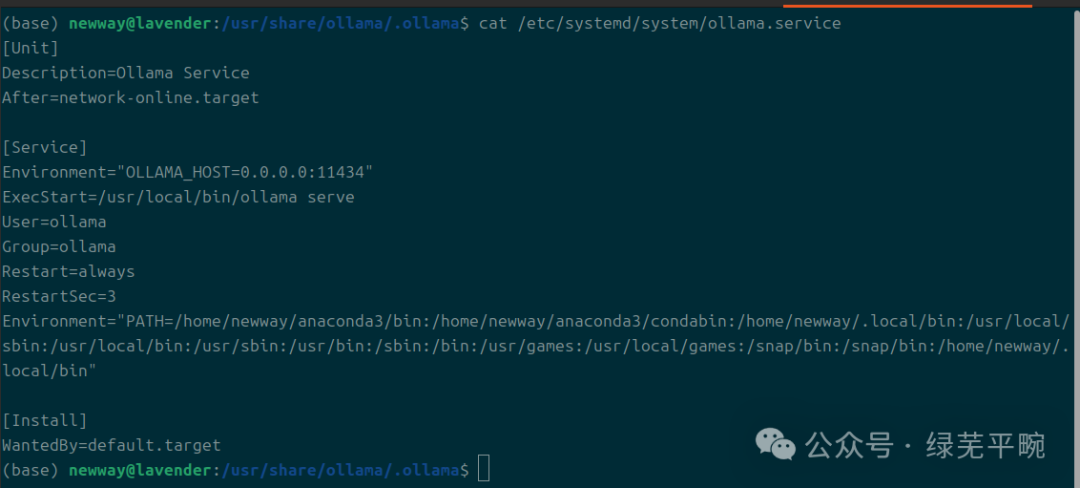
# 修改并重启服务``sudo systemctl daemon-reload``sudo systemctl restart ollama.ser 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









