



文章目录
Standalone集群的架构
Spark的Standalone集群搭建的准备工作
把Spark安装包spark-1.6.3-bin-hadoop2.6.tgz拷贝到node1节点
使用tar -zxvf spark-1.6.3-bin-hadoop2.6.tgz进行解压
修改进入conf下配置文件的名字

使用mv命令,改完名字浏览如下图所示

修改slaves配置文件内容
slaves配置文件里面放的是从节点的IP
所以,将node02,node03,node04放入slaves中
[注意要竖着写,一行一个,行尾不要空格不然会出现解析错误]

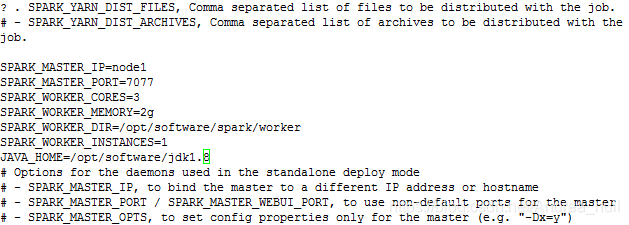
修改spark-env.sh内容
SPARK_MASTER_PORT字段设置主节点的IP
SPARK_MASTER_IP字段设置端口(用来Master与Worker的心跳,资源通信)
SPARK_WORKER_CORES代表每一个worker进程能管理几个核(有几个核的支配权)。
[注]如果CPU是4核8线程,那么这个核是支持超线程的核。
如果是普通的核,一个核在一个时刻只能处理一个线程。
这个配置是根据当前节点的资源情况来配置的,如果节点有8个core,并且支持超线程,此时可以将这个节点看成由16个core组成。
SPARK_WORKER_MEMORY字段代表每个worker可以管理多大内存。
SPARK_WORKER_DIR配置worker路径
SPARK_WORKER_INSTANCES设置每个节点上启动的worker进程数。
配置完成如下(为了防止找不到JAVA_HOME,手动设置了一下)
将配置好的文件发往其他节点
scp -r spark-1.6.3 root@node2: ‘pwd’
scp -r spark-1.6.3 root@node3:‘pwd’
scp -r spark-1.6.3 root@node4:‘pwd’
注意:此处的‘’不是上引号,是制表符上面和波浪线一起的符号
将启动命令改名
进入sbin目录下,找到start-all.sh文件(此文件与hadoop的start.sh冲突),将其改为:start-spark.sh
mv start-all.sh start-spark.sh
运行:start-spark.sh
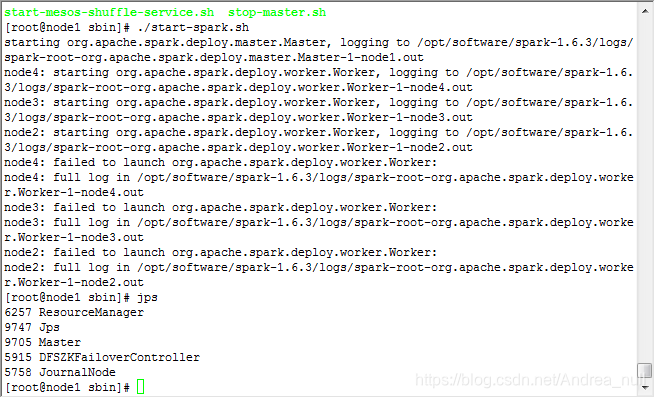
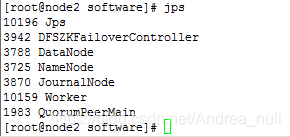
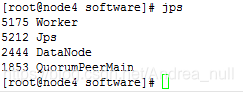
集群成功启动

















 5430
5430

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









