



 本文介绍了监督学习与无监督学习的区别,强调监督学习的分类特性与无监督学习的聚类核心。通过线性回归分析历年双十一成交额,展示了数据的线性趋势。并使用Python的matplotlib库绘制了成交额与年份的关系图,直观地呈现了数据分布。
本文介绍了监督学习与无监督学习的区别,强调监督学习的分类特性与无监督学习的聚类核心。通过线性回归分析历年双十一成交额,展示了数据的线性趋势。并使用Python的matplotlib库绘制了成交额与年份的关系图,直观地呈现了数据分布。
监督学习
监督学习,就是常说的分类,通过已有的训练样本(即已知数据以及其对应的输出)去训练得到一个最优模型(这个模型属于某个函数的集合,最优则表示在某个评价准则下是最佳的),再利用这个模型将所有的输入映射为相应的输出,对输出进行简单的判断从而实现分类的目的,也就具有了对未知数据进行分类的能力。监督学习里典型的例子就是KNN、SVM。
无监督学习
无监督学习,就是去对原始资料进行分类,以便了解资料内部结构。无监督式学习网络在学习时并不知道其分类结果是否正确。无监督学习里典型的例子就是聚类。
区分监督学习与无监督学习:
①监督学习中的数据中是提前做好了分类信息的,必须要有训练集与测试样本;
无监督学习没有训练集,只有一组数据。
②有监督的核心是分类,无监督的核心是聚类。
③有监督学习的方法就是识别事物,会给数据加上标签;
无监督学习方法只有要分析的数据集的本身,数据没有被加上标签。
线性回归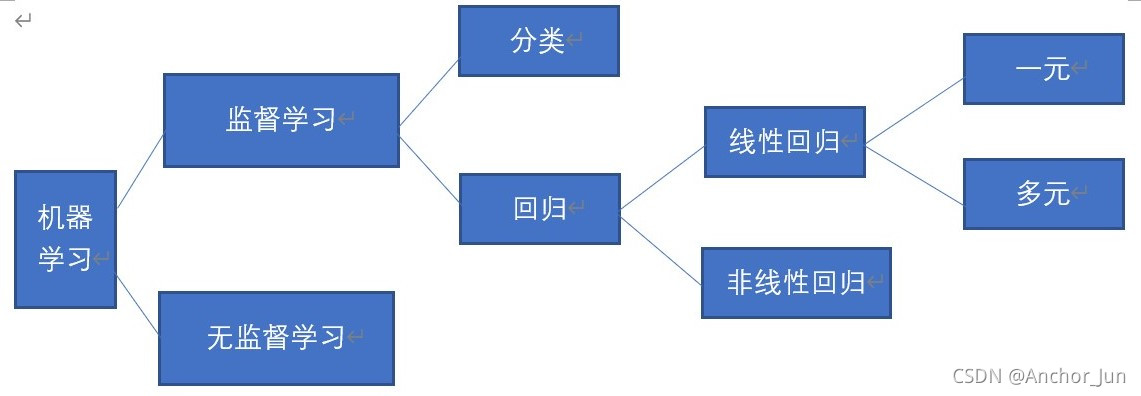
什么是线性回归:
线性回归就是一种x和y之间的关系为线性关系的回归分析。
先行关系用公式表达为:。
一元线性回归自然就是一个变量X啦。公式为:。
线性回归的目标是,找到一组a和b,使得ε最小。(ε就是误差,也就是学过的正态分布。)
用图像来表示,就是可以用一条直线把图中所有的点均匀的分布于两侧。
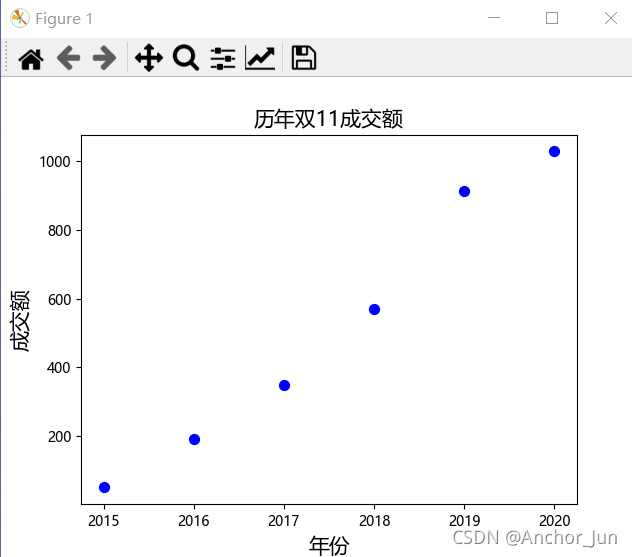
以一个题为例:给出历年的双十一成交额,years = [2015, 2016, 2017, 2018, 2019,2020]
turs = [52, 191, 350, 571, 912, 1027],做一个图表。
import matplotlib.pyplot as plt
import numpy as np
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['Microsoft YaHei']
mpl.rcParams['axes.unicode_minus'] = False
years = [2015, 2016, 2017, 2018, 2019,2020]
turs = [52, 191, 350, 571, 912, 1027]
plt.scatter(years, turs,c='b',s=50)
plt.xlabel("年份", fontsize=15)
plt.ylabel("成交额", fontsize=15)
plt.title("历年双11成交额", fontsize=15)
plt.show()
运行成功后图片为:
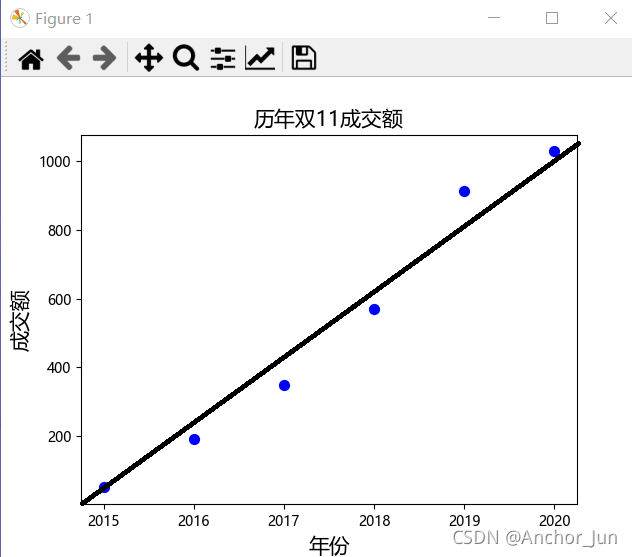
所以,本题的线性回归线大致如图所示:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









