




 本文探讨了在爬虫过程中如何应对反爬策略,包括使用代理服务器避免IP被屏蔽,模拟GET和POST请求进行网页交互,以及处理超时和异常。还提到了通过设置User-Agent进行简单的浏览器伪装。
本文探讨了在爬虫过程中如何应对反爬策略,包括使用代理服务器避免IP被屏蔽,模拟GET和POST请求进行网页交互,以及处理超时和异常。还提到了通过设置User-Agent进行简单的浏览器伪装。
写在前面的话:爬虫有风险,使用需谨慎(应当遵守行业道德及职业操守,遵守国家法律法规。以下内容均是在此前提下进行操作)
反爬技术基本有:
模拟登陆,模拟浏览器,代理服务器......文章在持续更新总结梳理中......
1.代理服务器的设置
目的:防止自有IP地址被屏蔽
推荐免费的代理服务器列表:
http://www.xicidaili.com/
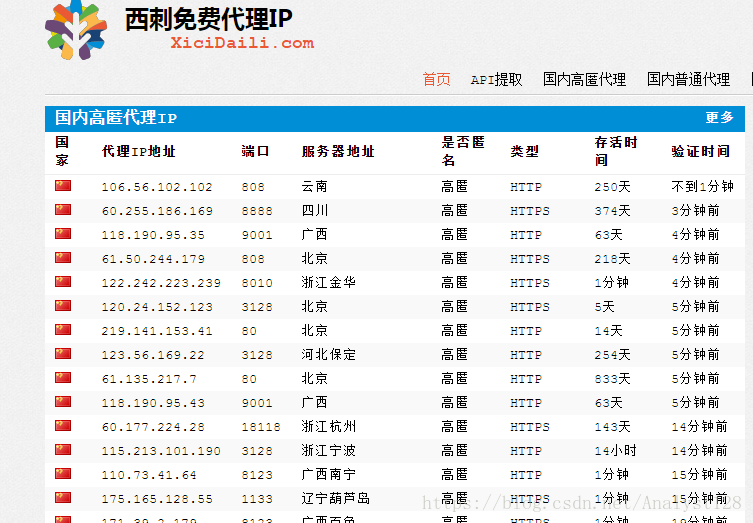
建立自定义函数,利用代理服务器爬取网页内容
#代理服务器设置
import urllib.request
def use_proxy(url,proxy_addr): #定义一个具有代理服务器功能的函数
proxy=urllib.request.ProxyHandler({"http":proxy_addr})
opener=urllib.request.build_opener(proxy,urllib.request.HTTPHandler) #添加代理IP
urllib.request.install_opener(opener) #安装opener为全局变量
data=urllib.request.urlopen(url).read().decode("utf-8","ignore")
#用"ignore"忽略编码错误问题
return data
proxy_addr="106.56.102.102:808" #有部分代理服务器可能没有效果,此时应该更换
url="http://xxxxx.com"
data=use_proxy(url,proxy_addr) # 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 488
488

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









