



在线验证
怎么验证你写的表达式 是否能正确匹配到要搜索的字符串呢?
大家可以访问这个网址: https://regex101.com/
但是有些特殊的字符,术语叫 metacharacters(元字符)。
它们出现在正则表达式字符串中,不是表示直接匹配他们, 而是表达一些特别的含义。
这些特殊的元字符包括下面这些:
. * + ? \ [ ] ^ $ { } | ( )
我们分别介绍一下它们的含义:
点-匹配所有字符
. 表示要匹配除了 换行符 之外的任何 单个 字符。
比如,你要从下面的文本中,选择出所有的颜色。
苹果是绿色的
橙子是橙色的
香蕉是黄色的
乌鸦是黑色的
也就是要找到所有 以 色 结尾,并且包括前面的一个字符的 词语。
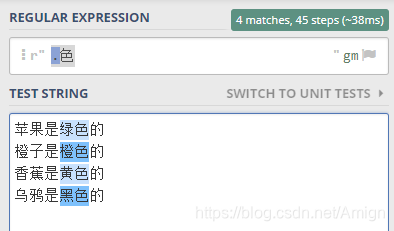
就可以这样写正则表达式 .色 。
其中 点 代表了任意的一个字符, 注意是一个字符。
.色 合起来就表示 要找 任意一个字符 后面是 色 这个字, 合起来两个字的 字符串
验证一下,如下图所示
只要表达式正确,就可以写在Python代码中,如下所示
content = ‘’‘苹果是绿色的
橙子是橙色的
香蕉是黄色的
乌鸦是黑色的’’’
import re
p = re.compile(r’.色’)for one in p.findall(content):
print(one)
运行结果如下
绿色
橙色
黄色
黑色
星号-重复匹配任意次
- 表示匹配前面的子表达式任意次,包括0次。
比如,你要从下面的文本中,选择每行逗号后面的字符串内容,包括逗号本身。注意,这里的逗号是中文的逗号。
苹果,是绿色的
橙子,是橙色的
香蕉,是黄色的
乌鸦,是黑色的
猴子,
就可以这样写正则表达式 ,.* 。
紧跟在 . 后面, 表示 任意字符可以出现任意次, 所以整个表达式的意思就是在逗号后面的 所有字符,包括逗号
验证一下,如下图所示
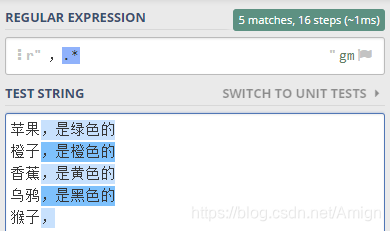
特别是最后一行,猴子逗号后面没有其它字符了,但是*表示可以匹配0次, 所以表达式也是成立的。
只要表达式正确,就可以写在Python代码中,如下所示
content = ‘’‘苹果,是绿色的
橙子,是橙色的
香蕉,是黄色的
乌鸦,是黑色的
猴子,’’’
import re
p = re.compile(r’,.’)for one in p.findall(content):
print(one)
运行结果如下
,是绿色的
,是橙色的
,是黄色的
,是黑色的
,
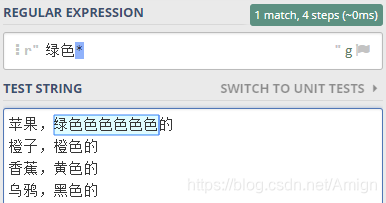
注意, . 在正则表达式中非常常见,表示匹配任意字符任意次数。
当然这个 * 前面不是非得是 点 ,也可以是其它字符,比如
加号-重复匹配多次
- 表示匹配前面的子表达式一次或多次,不包括0次。
比如,还是上面的例子,你要从文本中,选择每行逗号后面的字符串内容,包括逗号本身。
但是 添加一个条件, 如果逗号后面 没有内容,就不要选择了。
比如,下面的文本中,最后一行逗号后面 没有内容,就不要选择了。
苹果,是绿色的
橙子,是橙色的
香蕉,是黄色的
乌鸦,是黑色的
猴子,
就可以这样写正则表达式 ,.+ 。
验证一下,如下图所示
最后一行,逗号后面没有其它字符了,+表示至少匹配1次, 所以最后一行没有子串选中。
问号-匹配0-1次
? 表示匹配前面的子表达式0次或1次。
比如,还是上面的例子,你要从文本中,选择每行逗号后面的1个字符,也包括逗号本身。
苹果,绿色的
橙子,橙色的
香蕉,黄色的
乌鸦,黑色的
猴子,
就可以这样写正则表达式 ,.? 。
验证一下,如下图所示
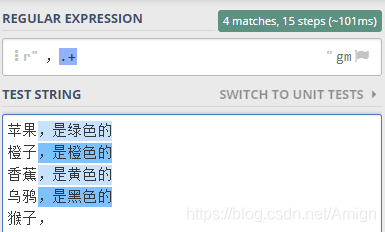
最后一行,逗号后面没有其它字符了,但是?表示匹配1次或0次, 所以最后一行也选中了一个逗号字符。
花括号-匹配指定次数
花括号表示 前面的字符匹配 指定的次数 。
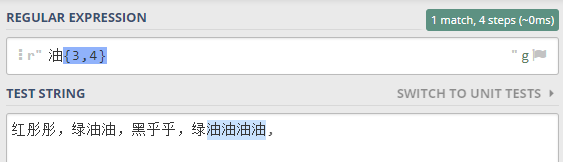
比如 ,下面的文本
红彤彤,绿油油,黑乎乎乎乎,绿油油油油
表达式 油{3} 就表示匹配 连续的 油 字 3次
表达式 油{3,4} 就表示匹配 连续的 油 字 至少3次,至多 4 次
就只能匹配 后面的,如下所示:
贪婪模式和非贪婪模式
我们要把下面的字符串中的所有html标签都提取出来,
source = ‘
得到这样的一个列表
[’’, ‘’, ‘
很容易想到使用正则表达式 <.>
写出如下代码
source = ‘
import re
p = re.compile(r’<.>’)
print(p.findall(source))
但是运行结果,却是
[‘
怎么回事? 原来 在正则表达式中, ‘’, ‘+’, ‘?’ 都是贪婪地,使用他们时,会尽可能多的匹配内容,
所以, <.> 中的 星号(表示任意次数的重复),一直匹配到了 字符串最后的 里面的e。
解决这个问题,就需要使用非贪婪模式,也就是在星号后面加上 ? ,变成这样 <.*?>
代码改为
source = ‘
import re# 注意多出的问号
p = re.compile(r’<.?>’)
print(p.findall(source))
对元字符的转义
反斜杠 \ 在正则表达式中有多种用途。
比如,我们要在下面的文本中搜索 所有点前面的字符串,也包含点本身
苹果.是绿色的
橙子.是橙色的
香蕉.是黄色的
如果,我们这样写正则表达式 .. , 聪明的你肯定发现不对劲。
因为 点 是一个 元字符, 直接出现在正则表达式中,表示匹配任意的单个字符, 不能表示 . 这个字符本身的意思了。
怎么办呢?
如果我们要搜索的内容本身就包含元字符,就可以使用 反斜杠进行转义。
这里我们就应用使用这样的表达式: ..
示例,Python程序如下
content = ‘’‘苹果.是绿色的
橙子.是橙色的
香蕉.是黄色的’’’
import re
p = re.compile(r’..’)for one in p.findall(content):
print(one)
运行结果如下
苹果.
橙子.
香蕉.
匹配某种字符类型
反斜杠后面接一些字符,表示匹配 某种类型 的一个字符。
比如
\d 匹配0-9之间任意一个数字字符,等价于表达式 [0-9]
\D 匹配任意一个不是0-9之间的数字字符,等价于表达式 [^0-9]
\s 匹配任意一个空白字符,包括 空格、tab、换行符等,等价于表达式 [\t\n\r\f\v]
\S 匹配任意一个非空白字符,等价于表达式 [^ \t\n\r\f\v]
\w 匹配任意一个文字字符,包括大小写字母、数字、下划线,等价于表达式 [a-zA-Z0-9_]
缺省情况也包括 Unicode文字字符,如果指定 ASCII 码标记,则只包括ASCII字母
\W 匹配任意一个非文字字符,等价于表达式 [^a-zA-Z0-9_]
反斜杠也可以用在方括号里面,比如 [\s,.] 表示匹配 : 任何空白字符, 或者逗号,或者点
方括号-匹配几个字符之一
方括号表示要匹配 指定的几个字符之一 。
比如
[abc] 可以匹配 a, b, 或者 c 里面的任意一个字符。等价于 [a-c] 。
[a-c] 中间的 - 表示一个范围从a 到 c。
如果你想匹配所有的小写字母,可以使用 [a-z]
一些 元字符 在 方括号内 失去了魔法, 变得和普通字符一样了。
比如
[akm.] 匹配 a k m . 里面任意一个字符
这里 . 在括号里面不在表示 匹配任意字符了,而就是表示匹配 . 这个 字符
如果在方括号中使用 ^ , 表示 非 方括号里面的字符集合。
比如
content = ‘a1b2c3d4e5’
import re
p = re.compile(r’[^\d]’ )for one in p.findall(content):
print(one)
[^\d] 表示,选择非数字的字符
输出结果为:
a
b
c
d
e
起始、结尾位置 和 单行、多行模式
^ 表示匹配文本的 开头 位置。
正则表达式可以设定 单行模式 和 多行模式
如果是 单行模式 ,表示匹配 整个文本 的开头位置。
如果是 多行模式 ,表示匹配 文本每行 的开头位置。
比如,下面的文本中,每行最前面的数字表示水果的编号,最后的数字表示价格
001-苹果价格-60,002-橙子价格-70,003-香蕉价格-80,
如果我们要提取所有的水果编号,用这样的正则表达式 ^\d+
上面的正则表达式,使用在Python程序里面,如下所示
content = ‘’‘001-苹果价格-60
002-橙子价格-70
003-香蕉价格-80’’’
import re
p = re.compile(r’^\d+’, re.M)for one in p.findall(content):
print(one)
注意,compile 的第二个参数 re.M ,指明了使用多行模式,
运行结果如下
001
002
003
如果,去掉 compile 的第二个参数 re.M, 运行结果如下
001
就只有第一行了。
因为单行模式下,^ 只会匹配整个文本的开头位置。
$ 表示匹配文本的 结尾 位置。
如果是 单行模式 ,表示匹配 整个文本 的结尾位置。
如果是 多行模式 ,表示匹配 文本每行 的结尾位置。
比如,下面的文本中,每行最前面的数字表示水果的编号,最后的数字表示价格
001-苹果价格-60,002-橙子价格-70,003-香蕉价格-80,
如果我们要提取所有的水果编号,用这样的正则表达式 \d+$
对应代码
content = ‘’‘001-苹果价格-60
002-橙子价格-70
003-香蕉价格-80’’’
import re
p = re.compile(r’\d+′,re.MULTILINE)foroneinp.findall(content):print(one)注意,compile的第二个参数re.MULTILINE,指明了使用多行模式,运行结果如下607080如果,去掉compile的第二个参数re.MULTILINE,运行结果如下80就只有最后一行了。因为单行模式下,', re.MULTILINE)for one in p.findall(content):
print(one)
注意,compile 的第二个参数 re.MULTILINE ,指明了使用多行模式,
运行结果如下
60
70
80
如果,去掉 compile 的第二个参数 re.MULTILINE, 运行结果如下
80
就只有最后一行了。
因为单行模式下,′,re.MULTILINE)foroneinp.findall(content):print(one)注意,compile的第二个参数re.MULTILINE,指明了使用多行模式,运行结果如下607080如果,去掉compile的第二个参数re.MULTILINE,运行结果如下80就只有最后一行了。因为单行模式下, 只会匹配整个文本的结束位置。
竖线-匹配两者之一
竖线表示 匹配 前者 或 后者 。
比如 ,
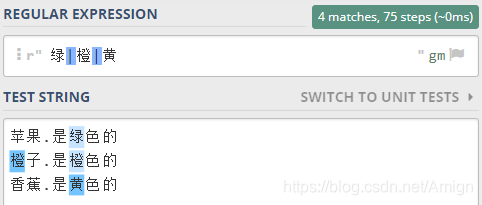
特别要注意的是, 竖线在正则表达式的优先级是最低的, 这就意味着,竖线隔开的部分是一个整体
比如 绿色|橙 表示 要匹配是 绿色 或者 橙 ,
而不是 绿色 或者 绿橙
括号-组选择
括号称之为 正则表达式的 组选择。 是从正则表达式 匹配的内容 里面 扣取出 其中的某些部分
前面,我们有个例子,从下面的文本中,选择每行逗号前面的字符串,也 包括逗号本身 。
苹果,苹果是绿色的
橙子,橙子是橙色的
香蕉,香蕉是黄色的
就可以这样写正则表达式 ^., 。
但是,如果我们要求 不要包括逗号 呢?
当然不能直接 这样写 ^.
因为最后的逗号 是 特征 所在, 如果去掉它,就没法找 逗号前面的了。
但是把逗号放在正则表达式中,又会包含逗号。
解决问题的方法就是使用 组选择符 : 括号。
我们这样写^(.*), ,结果如下
大家可以发现,我们把要从整个表达式中提取的部分放在括号中,这样 水果 的名字 就被单独的放在 组 group 中了。
对应的Python代码如下
content = ‘’‘苹果,苹果是绿色的
橙子,橙子是橙色的
香蕉,香蕉是黄色的’’’
import re
p = re.compile(r’^(.*),’, re.MULTILINE)for one in p.findall(content):
print(one)
分组,还可以多次使用。
比如,我们要从下面的文本中,提取出每个人的 名字 和对应的 手机号
张三,手机号码15945678901
李四,手机号码13945677701
王二,手机号码13845666901
可以使用这样的正则表达式 ^(.+),.+(\d{11})
可以写出如下的代码
content = ‘’‘张三,手机号码15945678901
李四,手机号码13945677701
王二,手机号码13845666901’’’
import re
p = re.compile(r’^(.+),.+(\d{11})’, re.MULTILINE)for one in p.findall(content):
print(one)

















 538
538

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









