




 内存屏障用于解决编译器优化和CPU乱序执行导致的执行顺序问题。文章介绍了Linux下barrier()、mb()、rmb()、wmb()宏的作用,它们通过volatile和特定汇编指令确保内存访问顺序,以保证并发环境中的数据一致性。在现代编译器和CPU追求性能优化的背景下,理解并适当使用内存屏障至关重要。
内存屏障用于解决编译器优化和CPU乱序执行导致的执行顺序问题。文章介绍了Linux下barrier()、mb()、rmb()、wmb()宏的作用,它们通过volatile和特定汇编指令确保内存访问顺序,以保证并发环境中的数据一致性。在现代编译器和CPU追求性能优化的背景下,理解并适当使用内存屏障至关重要。
内存屏障主要解决的问题是编译器的优化和CPU的乱序执行。
编译器在优化的时候,生成的汇编指令可能和c语言程序的执行顺序不一样,在需要程序严格按照c语言顺序执行时,需要显式的告诉编译不需要优化,这在linux下是通过barrier()宏完成的,它依靠volatile关键字和memory关键字:
- /* Optimization barrier */
/* The "volatile" is due to gcc bugs */
#define barrier() __asm__ __volatile__("": : :"memory")
- volatile: 告诉编译barrier()周围的指令不要被优化;
- memory:是告诉编译器汇编代码会使内存里面的值更改,编译器应使用内存里的新值而非寄存器里保存的老值。
同样,CPU执行会通过乱序以提高性能。汇编里的指令不一定是按照我们看到的顺序执行的。linux中通过mb()系列宏来保证执行的顺序。具体做法是通过mfence/lfence指令(它们是奔4后引进的,早期x86没有)以及x86指令中带有串行特性的指令(这样的指令很多,例如linux中实现时用到的lock指令,I/O指令,操作控制寄存器、系统寄存器、调试寄存器的指令、iret指令等等)。简单的说,如果在程序某处插入了mb()/rmb()/wmb()宏,则宏之前的程序保证比宏之后的程序先执行,从而实现串行化。wmb的实现和barrier()类似,是因为在x86平台上,写内存的操作不会被乱序执行。
实际上在RSIC平台上,这些串行工作都有专门的指令由程序员显式的完成,比如在需要的地方调用串行指令,而不像x86上有这么多隐性的带有串行特性指令(例如lock指令)。所以在risc平台下工作的朋友通常对串行化操作理解的容易些。
更详细的介绍请参考: http://vh21.github.io/linux/2015/06/22/concurrency-in-the-linux-kernel-2.html
現在的 Compiler 與 CPU 為了最佳化執行效能,必要時可能重新安排執行程式的流程與順 序。從 [1] 中我們可以大略認識幾個可能造成存取亂序的軟硬體最佳化,
- Compiler 最佳化 Compiler 可依據 CPU 的 instruction issue 數目、執行的 latency cycles 以及程 式流程,在不影響程式上下文執行結果下重排或簡化程式。
- 硬體設計最佳化
- Multiple issue of instructions:一個 cycle 可以執行多條指令
- Out-of-order execution:如果某一條指令 stall 等待之前的結果時,CPU 可以先執 行下一條沒有相依性的指令。
- Speculation:當 CPU 遇到一些條件式判斷的指令時,在判斷出結果前可以先預測性 的執行可能的 path 以求得 performance gain。
- Speculative loads:在 cacheable region,load instruction 真正被執行前就猜測 性的先把資料讀進 cache。
- Load and store optimizations: 讀寫外部記憶體會花上很長的時間且可能 stall pipeline 等待結果,CPU 可藉由減少傳輸次數提高 performance,例如合併數筆相鄰 位址的 store 成一筆。
- External memory systems:在許多現今複雜的 SOC 系統中,有許多不同的 master、 slave、與以及之間不同的 routing。有些 device 同時接受來自不同 master 的資料 傳輸請求。這些傳輸的 transaction 有可能在些 interconnection 之間被 buffer 或是 reorder。
基於以上原因,你的程式的執行順序與流程可能在編譯時被重排或者修改,CPU 執行結果 的出現順序又可能與 assembly 看到的不同, Compiler 跟 CPU 只會保證執行上下文結果 是正確的。這在 SMP 環境下,其他 CPU 或是 IO 因為上述因素有可能得到非預期的執行 結果。我們需要在某些 CPU/CPU 或是 CPU/IO 之間需要溝通的地方[2]確保 Compiler 與 CPU 的執行順序,memory barrier 提供這樣的功能。
Compiler support
volatile keyword:volatile 是一個 type qualifier。它聲明所修飾的變數的值有可 能被 memory-mapped IO 或者是 asynchronously interrupting function 修改,這個關 鍵字告訴 compiler 不要針對此變數的存取做最佳化。你可以對變數設定 volatile,但是 他對於所有存取這個變數的地方都會造成效果。這造成效能的減損。Linux kernel 裡面提 供 ACCESS_ONCE() macro [3]在使用上進一步最佳化,只在有需要的地方才套用 volatile 這個關鍵字,保留給 programmer 更多彈性。以下是 linux-3.19 前的實現版 本.
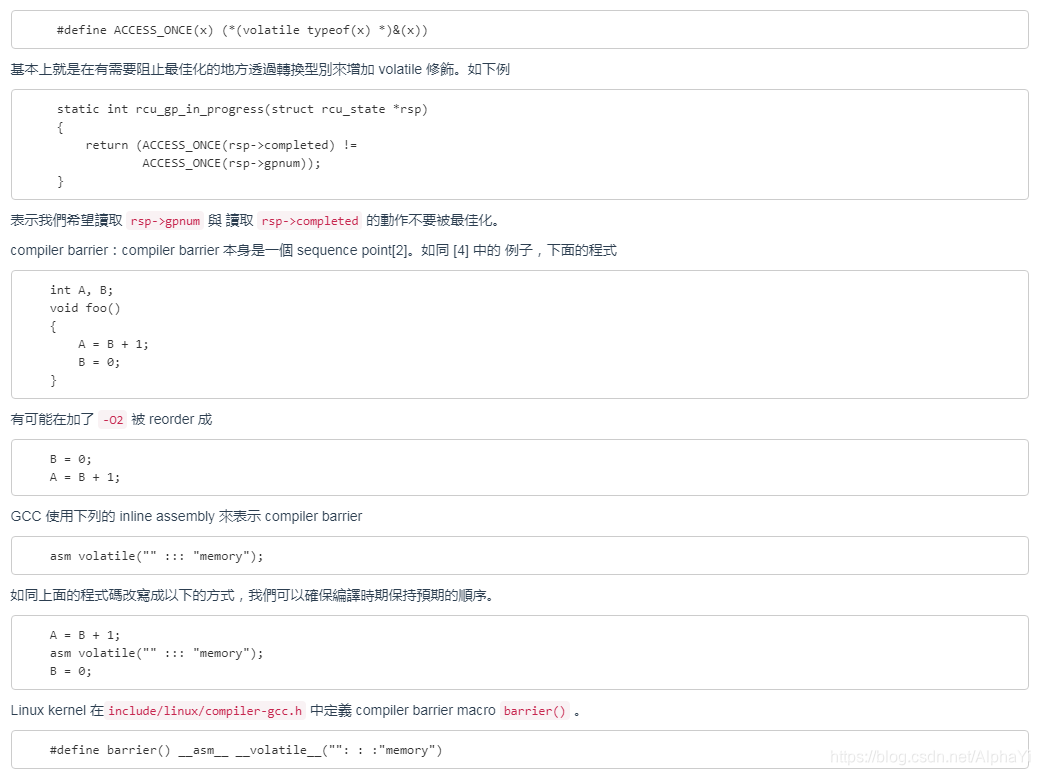
CPU barrier
每個 CPU architecture 根據各自的 memory model,通常會提供自己的 barrier instruction,以達到不同程度的讀寫順序的保證。如 ARM 的 dmb 等,有的有不同程度 與作用範圍的 barrier,以達到更細度的控制。
在 Linux 中,這些指令在 arch 下被包成通用的介面,分類介紹如下,
-
mb()/rmb()/wmb():
rmb()確保 barrier 之前的 read operation 都能在 barrier 之後的 read operation 之前發生,簡單來說就是確保 barrier 前後的 read operation 的順序;wmb()如同rmb()但是只針對 write operation。mb()則是針對所有的 memory access。 -
smp_mb()/smp_rmb()/smp_wmb():在 SMP 的系統被定義成
mb()/rmb()/wmb(),UP 時就只是 compiler barrier。可特別用在只於 SMP 時才需要 barrier 的地方[8]。 -
dma_rmb/dma_wmb():如果 architecture 對於 barrier 作用的範圍有提供更 fine-grained 的控制,在 device driver 中需要同步 CPU 與 IO 中的 memory data 時 我們就不需要使用作用達到整個系統的 barrier。如同 [9] 中 ARM 的例子,

-
smp_load_acquire()/smp_store_release():這部分是單向的 barrier。 ACQUIRE 確保 之後所有的 memory operation 都只在 ACQUIRE 之後出現;RELEASE 則是確保之前所有的 memory operation 都在 RELEASE 之前出現。通常這兩個都是成對出現。透過這兩個 macro,我們可以確保之前在 critical section 之內的變數存取都會在這次的 critical section 前完成!
-
read_barrier_depends()/smp_read_barrier_depends():只有在 barrier 上下的資料 存取有相依性時才有作用,這樣我們就可以避免使用
rmb()達到更輕量的控制。但是這 只有 ALPHA CPU 才有支援,其他的 architecture 都是定義成空巨集。 -
smp_mb__before_atomic()/smp_mb__after_atomic():在某些沒有 return value 的 atomic operation 中有些沒有使用 memory barrier。這兩個 macro 讓我們在這些操作前 後確保資料一致性。
Barrier 在需要時幫助我們達到記憶體存取的順序的準確與可預測性。但是相對的它也減 低了原本效能最佳化的好處。它在其它 Concurrency 機制的實現上是個不可或缺的角色!
Reference
- Chapter 13 Memory ordering, ARM Cortex-A Series Programmer’s Guide for ARMv8-A
- Sequence point
- LINUX KERNEL MEMORY BARRIERS
- Memory Ordering at Compile Time
- C語言: 認識關鍵字volatile
- How To Add a Sequence Point?
- Memory ordering
- Ordering and Barriers, Linux kernel development
- [PATCH v6 2/5] arch: Add lightweight memory barriers dma_rmb() and dma_wmb()


















 1255
1255

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









