



文章:
Fault-tolerance approaches for distributed and cloud computing environments: A systematic review, taxonomy and future directions
Kirti, Medha, Ashish Kumar Maurya, and Rama Shankar Yadav. "Fault‐tolerance approaches for distributed and cloud computing environments: A systematic review, taxonomy and future directions." Concurrency and Computation: Practice and Experience 36, no. 13 (2024): e8081.
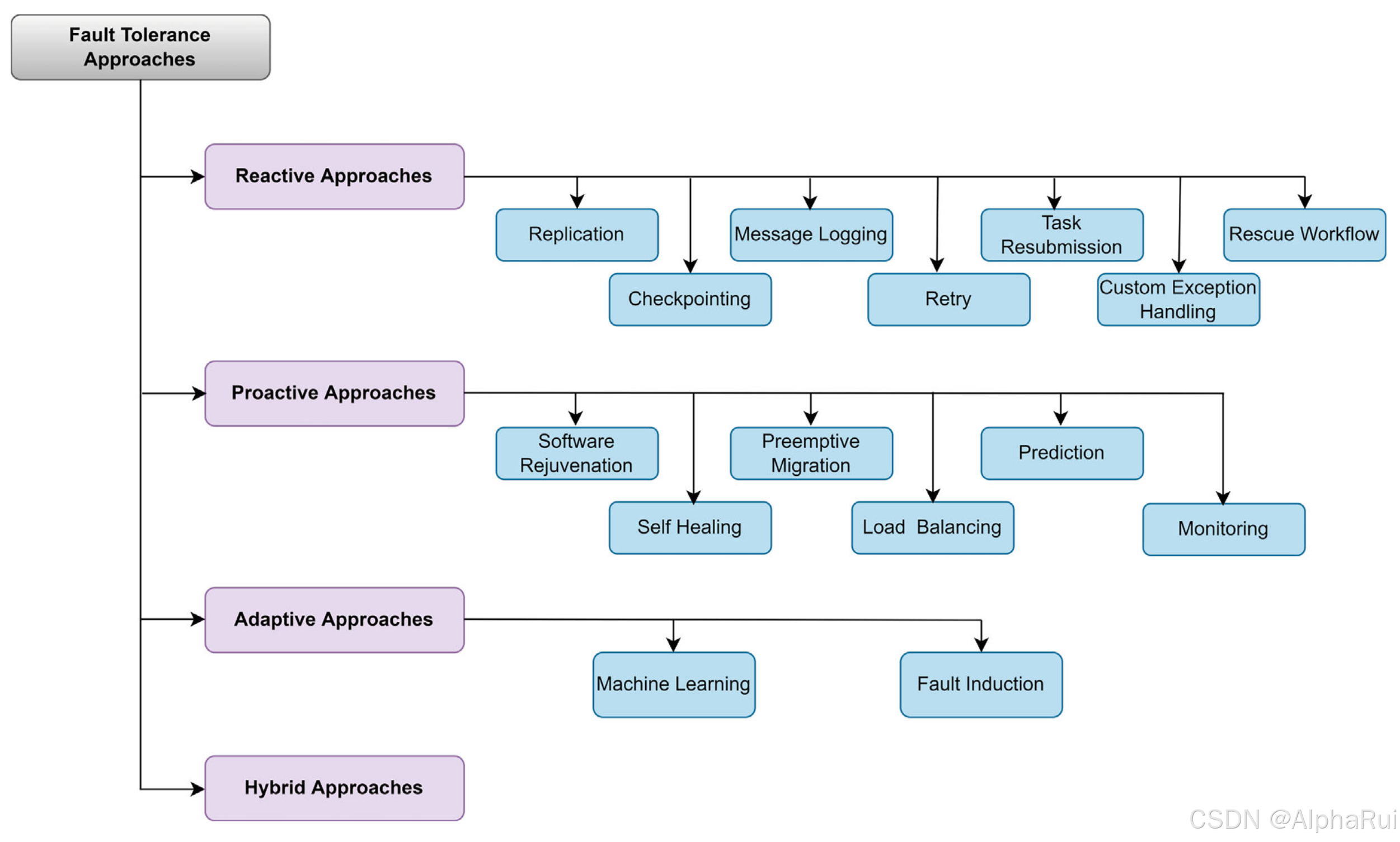
四种主要的方法分类:Reactive Approaches, Proactive Approaches, Adaptive Approaches, Hybrid Approaches.
- Reactive Approaches: 在系统中发生故障后提供了一种预防措施,包含7种措施:复制 (replication), 检查点 (checkpointing), 重试 (retry), 消息记录 (message logging), 自定义异常处理 (custom exception handling), 任务重新提交 (task resubmission), 救援工作流程 (rescue workflow)
- Proactive Approaches: 通过预先预测来防止系统或最大程度地减少故障效应。包含6种措施:software rejuvenation, self-healing, preemptive migration, load balancing, prediction and monitoring
- Adaptive Approaches: 预测,学习和适应更改以处理系统中的新故障。包含:learns and adapts the changes based on artificial intelligence and machine learning
- Hybrid Approaches: 结合了反应性,主动和自适应方法。
Introduction
在云计算中:
由于云基础架构的规模和复杂性 (scale and complexity),云基础架构的规模和复杂性由多个互连组件 (interconnected components) 组成,例如服务器,存储设备和网络 (servers, storage devices, networks)。
当云系统中发生故障时,它们会影响云服务的可用性,可靠性和性能 (availability, reliability, and performance),从而导致停机时间,数据丢失或服务质量下降 (downtime, data loss, or degradation in service quality)。
在分布式计算中:
故障也可能来自基础组件的复杂性和异质性 (the complexity and heterogeneity of the underlying components),例如节点和网络。由于通信故障,节点故障或网络分区 (communication failures, node failures, or network partitions),分布式计算可能容易受到故障的影响。
定义
2.1 What is fault-tolerant?
1. Fault: A fault is considered a condition due to which the system fails to perform the required functionality as defined. Faults can be caused by various factors, such as hardware defects, software bugs, or environmental conditions.
2. Error: Error in a system is defined as the difference between the actual and the expected output, which occurs due to the presence of fault. Errors can occur at different stages of the system lifecycle, such as during the design, implementation, or operation of a system. Due to the error, the system fails or stops working, which leads to failure.
- Error 是由于 Fault(故障)导致的系统状态偏离期望的表现。
- 它代表的是 系统内部的不一致,但此时系统可能仍能继续运行,而用户不一定会察觉到错误。
3. Failure: A failure is the inability of a component or system to perform its intended function. Failures can occur as a result of faults or other reasons, such as human errors or natural disasters. Failures can impact the availability, reliability, and performance of a system.
- Failure 是指系统或组件无法完成预期的功能,导致系统不符合需求。
- 它是 Error 影响到系统行为 后的最终表现,通常是 用户可感知的。
在容错计算中,这三个概念是递进关系:
1️⃣ Fault(故障) → 硬件缺陷、软件 Bug、外部干扰(如宇宙射线导致的 bit-flip)。
2️⃣ Error(错误) → Fault 产生的错误状态,但可能不会影响最终输出。
3️⃣ Failure(失效) → Error 没有被修复,最终导致系统无法正常工作。
4. Fault tolerance is the ability that enables a system to remain functioning in the presence of partial failure.
2.2 Types of faults 五种常见的故障类型
1. Transient Faults(瞬时故障)
-
瞬时故障是临时性的,它们发生一段时间后会自动消失,不会永久影响系统,不会对系统造成长期损害。
-
这些故障通常是由于外部环境问题(如网络抖动、电磁干扰)导致的,系统通常可以通过重试或纠错来恢复。
2. Permanent Faults(永久性故障)
-
永久性故障是长期存在的,只有修复或更换硬件才能解决。不会自行恢复。
-
这类故障通常是由于组件损坏、硬件老化或软件严重错误导致的。
3. Intermittent Faults(间歇性故障)
-
间歇性故障是不定期发生的,它们出现后又消失,表现出随机性。
-
这种故障通常由于硬件老化、温度波动、接触不良等导致,难以检测和复现。
4. Benign Faults(良性故障)
-
良性故障是指某个子系统或组件停止工作,但不会导致整个系统崩溃。
-
由于系统设计了容错机制,良性故障不会造成重大影响。
📌 现实案例: 服务器集群中的一个节点宕机,但由于集群有多个副本,用户不会察觉。
副电源模块损坏,但主电源仍在工作,因此设备不会宕机。
冗余网络路径失效,但主网络仍然可用,不影响业务。
5. Byzantine Faults(拜占庭故障)
-
拜占庭故障(Byzantine Fault)是最严重的故障类型,它会导致系统做出错误决策,甚至出现不可预测的行为。
-
这种故障的关键特点是系统的某些组件可能会提供错误或矛盾的信息,导致整个系统无法达成一致。
🔹 系统可能继续运行,但行为是错误的
🔹 组件可能提供虚假或矛盾的信息
🔹 难以检测,因为表面上系统仍在工作
📌 现实案例:
-
分布式系统中的错误共识:在区块链网络中,如果恶意节点向不同部分的网络发送不同版本的数据,可能导致共识失败(如双重支付问题)。
-
航天器控制系统:如果某个传感器提供了错误的数据,但仍然处于“工作”状态,可能导致飞行计算机做出错误决策(如航天器姿态调整错误)。
📌 解决方案:
-
拜占庭容错算法(Byzantine Fault Tolerance, BFT):
-
例如区块链使用的 PBFT(Practical Byzantine Fault Tolerance) 算法,确保即使有一部分节点恶意作恶,系统仍能保持正确性。
-
-
三模冗余(TMR, Triple Modular Redundancy):
-
NASA 的航天器控制系统中,使用 三重冗余计算机,当检测到结果不一致时,采用多数投票方式决定正确结果。
-
方法
3.1 Reactive fault tolerance approaches
3.1.1 Replication
Replication in distributed and cloud systems provides fault tolerance by creating multiple copies of data and distributing them across multiple nodes or locations.
复制: 创建多个数据副本并在多个节点或位置进行分配
- Active replication:主动复制在每个节点上传播更新请求。
- Passive replication:在被动复制中,请求在单个节点上处理,并将更新传播到其他节点
(1)主动复制(Active Replication)
-
每个节点都独立执行相同的请求,并得到相同的结果。
-
也称为 状态机复制(State Machine Replication, SMR),即每个副本执行相同的操作序列,确保状态一致。
机制:
-
客户端(Client)发送请求给所有副本(通常通过广播)。
-
所有副本同时执行相同的请求(即多个服务器处理相同的事务)。
-
确保所有副本计算出的状态一致,以达到容错目的。
-
如果某个节点故障,其他节点仍能正常提供服务。
📌 现实案例
🔹 银行交易系统:多个银行服务器同时处理转账请求,确保所有分支机构的数据一致。
🔹 航空订票系统:所有服务器同时更新航班座位信息,避免超卖。
🔹 区块链共识机制(如 PBFT, Raft):所有节点都执行相同交易,确保一致性。
优势
快速故障恢复:任意节点宕机,其他节点仍然有最新数据。
无需额外同步步骤:所有节点同时处理请求,不需要等待主节点同步数据。
劣势
计算资源浪费:所有副本执行相同的计算,增加系统负担。
通信开销大:客户端需要广播请求,多个副本并行计算,占用带宽。
需要保证执行的确定性:如果不同副本对相同请求计算结果不同,就可能导致状态不一致。
(2)被动复制(Passive Replication)
-
只有一个主节点(Primary)执行请求,然后将更新结果传播给其他副本(Backup)。
-
其他副本不执行请求,只接收更新后的状态。
机制:
-
客户端(Client)发送请求给主节点(Primary)。
-
主节点执行请求,计算结果。
-
主节点将更新后的数据同步到所有备份节点(Backup)。
-
如果主节点宕机,系统会选出新的主节点继续提供服务(通常使用主备切换机制,如主从复制)。
📌 现实案例
🔹 数据库主从复制(MySQL Master-Slave):所有写操作只在主库执行,其他从库仅同步数据。
🔹 分布式缓存(如 Redis 主从模式):主节点处理所有写请求,从节点复制数据,处理读请求。
🔹 云存储(如 Amazon S3 的多数据中心备份):主数据中心处理请求,并将结果同步到其他数据中心。
优势:
计算资源高效利用:只有主节点执行计算,备份节点仅同步数据,减少计算开销。
通信开销小:相比主动复制,不需要所有副本都执行相同计算,只同步最终结果。
劣势:
主节点故障时可能会丢数据:如果主节点宕机,而更新还未同步到备份节点,可能会丢失最新数据。
恢复时间较长:主节点故障后,需要选出新的主节点,可能会导致短暂的系统不可用。
备份节点可能有数据延迟:因为数据是异步复制的,所以备份节点可能滞后于主节点。
| 对比项 | 主动复制(Active Replication) | 被动复制(Passive Replication) |
|---|---|---|
| 请求处理方式 | 所有副本同时执行请求 | 主节点执行请求,备份节点只接收结果 |
| 一致性 | 强一致性(每个副本状态完全同步) | 最终一致性(备份节点可能稍有延迟) |
| 计算资源 | 高(所有副本都计算) | 低(只有主节点计算) |
| 通信开销 | 高(每个请求广播给所有副本) | 低(只同步最终状态) |
| 故障恢复 | 无缝恢复(任意副本都可以继续工作) | 可能有短暂中断(主节点故障时需要选举新的主节点) |
| 适用场景 | 金融、区块链、分布式共识 | 数据库、缓存、云存储 |
什么时候使用主动复制 vs. 被动复制?
使用主动复制(Active Replication)的情况
-
强一致性要求高(如金融交易系统、区块链共识)。
-
需要高可用性和快速恢复(如航空订票系统)。
-
系统能够承受高计算和通信开销。
使用被动复制(Passive Replication)的情况
-
读请求远多于写请求(如数据库主从复制)。
-
计算成本较高,不适合所有副本执行相同计算(如大规模数据处理)。
-
可以容忍短暂的延迟(如异步数据同步的分布式缓存)。

















&spm=1001.2101.3001.5002&articleId=146175593&d=1&t=3&u=749ea4401ddf4553b0d10e941f1231c3)

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









