问题起源于编程珠玑Column 12中的题目10,其描述如下:
How could you select one of n objects at random, where you see the objects sequentially but you do not know the value of n beforehand? For concreteness, how would you read a text file, and select and print one random line, when you don’t know the number of lines in advance?
问题定义可以简化如下:在不知道文件总行数的情况下,如何从文件中随机的抽取一行?
首先想到的是我们做过类似的题目吗?当然,在知道文件行数的情况下,我们可以很容易的用C运行库的rand函数随机的获得一个行数,从而随机的取出一行,但是,当前的情况是不知道行数,这样如何求呢?我们需要一个概念来帮助我们做出猜想,来使得对每一行取出的概率相等,也即随机。这个概念即蓄水池抽样(Reservoir Sampling)。
有了这个概念,我们便有了这样一个解决方案:定义取出的行号为choice,第一次直接以第一行作为取出行 choice ,而后第二次以二分之一概率决定是否用第二行替换 choice ,第三次以三分之一的概率决定是否以第三行替换 choice ……,以此类推,可用伪代码描述如下:
i = 0
while more input lines
with probability 1.0/++i
choice = this input line
print choice
这种方法的巧妙之处在于成功的构造出了一种方式使得最后可以证明对每一行的取出概率都为1/n(其中n为当前扫描到的文件行数),换句话说对每一行取出的概率均相等,也即完成了随机的选取。
证明如下:
问题: 证明当前任意一行为取出行的概率为1/i,i为当前扫描到的行号,也即每一行取出的概率相等
我们用数学归纳法来证明,
当i=1时,当前只浏览了第一行,因此第一行为取出行的概率为1/1=1,符合直接取出的条件
当i=k时,有前k行为取出行的概率为1/k,我们要证明的是,当i=k+1时,前k+1行每一行被取出的概率均相等,且为1/(k+1)。当扫描到第k+1行时,我们以1/(k+1)概率替换choice,易知,第k+1行为choice的概率即为1/(k+1),对于第k行,其为choice的概率是第k行为取出行的概率 * 第k+1行没有被取出的概率即,
对于第k行的证明同样可应用到前k-1行,对于其中第m行其为choice的概率是第m行为取出行的概率 * 第m+1行没有被取出的概率 * … *第k+1行没有被取出的概率,即
由此证得当i=k+1时,所有行的取出概率为1/(k+1)。证毕。
回顾这个问题,我们可以对其进行扩展,即如何从未知或者很大样本空间随机地取k个数?
类比下即可得到答案,即先把前k个数放入蓄水池,对第k+1,我们以k/(k+1)概率决定是否要把它换入蓄水池,换入时随机的选取一个作为替换项,这样一直做下去,对于任意的样本空间n,对每个数的选取概率都为k/n。也就是说对每个数选取概率相等。
伪代码:
Init : a reservoir with the size: k
for i= k+1 to N
M=random(1, i);
if( M < k)
SWAP the Mth value and ith value
end for
证明我们仍然使用数学归纳法:
问题,证明对于任意样本号n,n>=k,每个样本作为取出样本的概率相等,即k/n。
证明:
当n=k时,由我们把前k个数放入蓄水池可知,每个样本的取出概率均相等,即k/k=1。 设当前样本号为n,其每个取出样本概率均相等,即为k/n,我们要证明的是这种情况对于n+1也成立。
由于我们以k/(n+1)决定是否把n+1放入蓄水池,那么对于n+1其出现在蓄水池中的概率就是k/(n+1),对于前n个元素中的任意元素m(k+1<=m<=n),其出现在蓄水池中的概率为 m出现在蓄水池中的概率 * [(m+1被选中的概率*m没被m+1替换的概率 + m+1没被选中的概率)*(m+2被选中的概率*m没被m+2替换的概率 + m+2没被选中的概率)*…*(n+1被选中的概率*m没被n+1替换的概率 + n+1没被选中的概率)],即
可见,对于n+1每个样本取出概率也相等,即为k/(n+1)。证毕。
蓄水池抽样问题是一类问题,在这里总结一下,并由衷的感叹这种方法之巧妙,不过对于这种思想产生的源头还是发觉不够,如果能够知道为什么以及怎么样想到这个解决方法的,定会更加有意义。
随即抽样问题:
要求从N个元素中随机的抽取k个元素,其中N无法确定。
是在 《计算机程序设计与艺术》 中看到的这个题目,书中只给出了解法,没给出证明。
解决方法是叫Reservoir Sampling (蓄水池抽样)
Init : a reservoir with the size: k
for i= k+1 to N
M=random(1, i);
if( M < k)
SWAP the Mth value and ith value
end for
证明:
每次都是以 k/i 的概率来选择
例: k=1000的话,从1001开始作选择,1001被选中的概率是1000/1001,1002被选中的概率是1000/1002,与我们直觉是相符的。
接下来证明:
假设当前是i+1, 按照我们的规定,i+1这个元素被选中的概率是k/i+1,也即第 i+1 这个元素在蓄水池中出现的概率是k/i+1
此时考虑前i个元素,如果前i个元素出现在蓄水池中的概率都是k/i+1的话,说明我们的算法是没有问题的。
对这个问题可以用归纳法来证明:k < i <=N
1.当i=k+1的时候,蓄水池的容量为k,第k+1个元素被选择的概率明显为k/(k+1), 此时前k个元素出现在蓄水池的概率为 k/(k+1), 很明显结论成立。
2.假设当 j=i 的时候结论成立,此时以 k/i 的概率来选择第i个元素,前i-1个元素出现在蓄水池的概率都为k/i。
证明当j=i+1的情况:
即需要证明当以 k/i+1 的概率来选择第i+1个元素的时候,此时任一前i个元素出现在蓄水池的概率都为k/(i+1).
前i个元素出现在蓄水池的概率有2部分组成, ①在第i+1次选择前得出现在蓄水池中,②得保证第i+1次选择的时候不被替换掉
①.由2知道在第i+1次选择前,任一前i个元素出现在蓄水池的概率都为k/i
②.考虑被替换的概率:
首先要被替换得第 i+1 个元素被选中(不然不用替换了)概率为 k/i+1,其次是因为随机替换的池子中k个元素中任意一个,所以不幸被替换的概率是 1/k,故
前i个元素(池中元素)中任一被替换的概率 = k/(i+1) * 1/k = 1/i+1
则(池中元素中)没有被替换的概率为: 1 - 1/(i+1) = i/i+1
综合① ②,通过乘法规则
得到前i个元素出现在蓄水池的概率为 k/i * i/(i+1) = k/i+1
故证明成立
1. 给你一个长度为N的链表。N很大,但你不知道N有多大。你的任务是从这N个元素中随机取出k个元素。你只能遍历这个链表一次。你的算法必须保证取出的元素恰好有k个,且它们是完全随机的(出现概率均等)。
解答:
先选中前k个, 从第k+1个元素到最后一个元素为止, 以1/i (i=k+1, k+2,...,N) 的概率选中第i个元素,并且随机替换掉一个原先选中的元素, 这样遍历一次得到k个元素,可以保证完全随机选取。这个算法叫做蓄水池抽样,在某门课上听到的,证明起来也不是很复杂。
可以参考编程珠玑问题12.10:如何从n个排序的对象中选择一个,但实现不知道n的大小?
解答:总是选择第一个对象,并使用1/2的概率选择第二个对象,使用1/3的概率选择第三个对象,以此类推。在过程结束时,每个对像被选中的概率都是1/n。伪码如下:
i = 0;
while( more objects)
{
with probability 1.0/i++
choice = this object
print choice
}
2. 给你一个数组A[1..n],请你在O(n)的时间里构造一个新的数组B[1..n],使得B[i]=A[1]*A[2]*...*A[n]/A[i]。你不能使用除法运算。
Solution:
1. 由于不知道N多大,因此不能使用[0, n]之间的等概率随机整数。遍历链表,给每个元素赋一个0到1之间的随机数作为权重(像Treap一样),最后取出权重最大的k个元素。你可以用一个堆来维护当前最大的k个数。
2. 从前往后扫一遍,然后从后往前再扫一遍。也就是说,线性时间构造两个新数组,P[i]=A[1]*A[2]*...*A[i],Q[i]=A[n]*A[n-1]*...*A[i]。于是,B[i]=P[i-1]*Q[i+1]。
本文由新浪微博
hbzyn1转载
 理解Reservoir Sampling算法及其应用
理解Reservoir Sampling算法及其应用





 本文探讨了Reservoir Sampling算法的原理、实现方法及在处理海量数据时随机选取元素的应用场景,包括从未知数量的文件中随机抽取一行、从无限样本空间中随机选取k个数,以及算法的数学证明过程。
本文探讨了Reservoir Sampling算法的原理、实现方法及在处理海量数据时随机选取元素的应用场景,包括从未知数量的文件中随机抽取一行、从无限样本空间中随机选取k个数,以及算法的数学证明过程。

















 819
819

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










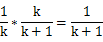{kind=link}
{kind=link}
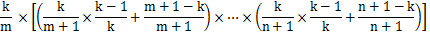{kind=link}
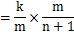{kind=link}
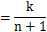{kind=link}