



1、怎样做用户登录,为什么用异步不用同步,怎样设计多线程模式,连接池的实现原理(如何设计连接数)
1、用户登录流程设计 项目中用户登录流程基于分布式服务协作实现,核心涉及GateServer、VerifyServer、StatusServer和ChatServer的交互,具体步骤如下:
-
客户端发起登录请求 前端QT客户端通过封装的HTTP模块(基于QT Network)向
GateServer发送登录请求(包含用户名、密码哈希值),请求格式采用JSON或Protobuf序列化(确保数据紧凑性)。 -
GateServer路由验证
GateServer作为网关,收到请求后通过gRPC调用VerifyServer(验证服务),将用户信息转发给VerifyServer进行身份校验。 -VerifyServer查询MySQL数据库(用户表),验证用户名密码的合法性(密码存储采用加盐哈希,如bcrypt算法,避免明文风险)。 -
负载均衡分配ChatServer 验证通过后,
GateServer调用StatusServer(状态服务)查询当前各ChatServer的负载情况(如在线连接数、CPU使用率),StatusServer返回负载最低的ChatServer地址(IP+端口)。 - 负载均衡策略:采用“最小连接数”算法,优先选择当前连接数最少的ChatServer,避免单节点过载。 -
返回连接信息并建立长连接
GateServer将目标ChatServer的地址返回给客户端,客户端收到后通过QT的TCP模块(封装的异步TCP客户端)与该ChatServer建立长连接,并发送“登录确认”消息(携带用户ID和临时token)。 -ChatServer验证token有效性(通过gRPC与VerifyServer二次确认),验证通过后记录用户在线状态(更新Redis缓存,键为user:status:{userID},值为在线状态+连接信息),并返回登录成功响应。 -
同步好友列表与历史消息 登录成功后,客户端通过TCP长连接向
ChatServer请求好友列表(ChatServer从MySQL查询好友关系表)和未读消息(ChatServer从Redis或MySQL查询离线消息表),并在本地通过QListWidget渲染好友列表,完成登录流程。
2、为什么用异步IO而非同步IO?
项目中服务器(尤其是ChatServer)采用Boost.Asio的异步IO模型,而非同步IO,核心原因是提升高并发场景下的资源利用率和系统吞吐量,具体如下: - 同步IO的瓶颈:同步IO中,一个线程对应一个连接,连接建立后线程会阻塞在recv/send操作上(等待数据或发送完成)。当并发连接数达到数千(如项目中8000+连接),同步IO需要创建同等数量的线程,导致:
- 线程上下文切换开销剧增(CPU大量时间用于线程调度,而非处理业务);
- 内存占用过高(每个线程栈空间通常为1-8MB,8000线程约占8-64GB内存);
- 无法应对突发流量(线程创建/销毁耗时,难以动态扩容)。
异步IO的优势:异步IO基于“事件驱动”模型,通过io_context(Boost.Asio的核心)管理IO事件,一个线程可处理多个连接的IO操作(非阻塞):
-
- 线程数量与CPU核心数匹配(而非连接数),减少切换开销;
-
- 连接建立、数据读写等操作通过回调函数触发,线程仅在有事件时工作,资源利用率更高;
-
- 支持数万级并发连接(项目中单服务器8000连接,多服务器支持2W+),满足高并发需求。 例如,
ChatServer中,TCP连接的accept、read、write均通过异步接口(async_accept、async_read、async_write)实现,线程池中的线程仅负责轮询io_context的事件队列,避免阻塞。
- 支持数万级并发连接(项目中单服务器8000连接,多服务器支持2W+),满足高并发需求。 例如,
多线程模式设计(以ChatServer为例)
- 项目中
ChatServer的多线程模式基于“io_context池”实现,核心是“线程池+IO事件分发”,平衡并发性能与线程安全,具体设计如下: 1. io_context池的创建 初始化时创建一个io_context池(数量通常等于CPU核心数,如8核CPU创建8个io_context),每个io_context绑定一个线程(线程池),线程启动后循环调用io_context.run()(阻塞等待IO事件)。 2. 连接的负载均衡分配 当新客户端连接请求到达时,ChatServer的监听线程通过“轮询”或“哈希”策略,将连接分配给io_context池中的一个io_context: - 轮询策略:按顺序将第N个连接分配给第N%池大小个io_context,确保每个io_context处理的连接数均匀; - 哈希策略:基于客户端IP或端口哈希,将同一客户端的连接分配给固定io_context,减少线程间数据交互。 3. 业务逻辑与IO分离 IO操作(如TCP读写)由io_context绑定的线程处理,而复杂业务逻辑(如消息转发、群组权限校验)通过“任务队列+业务线程池”异步执行: - IO线程读取消息后,将解码后的消息封装为任务,投递到业务线程池; - 业务线程处理完成后,将结果通过post接口投递回io_context,由IO线程负责将响应写回客户端。 - 此设计避免IO线程被业务逻辑阻塞,保证IO响应速度。 4. 线程安全保障 不同io_context绑定的线程处理独立的连接,通过“每个连接绑定一个线程”避免共享资源竞争;若需跨连接操作(如群组消息广播),通过std::mutex或无锁队列(如concurrent_queue)同步数据。 ### 4、连接池的实现原理及连接数设计 项目中封装了MySQL连接池、Redis连接池、gRPC连接池,核心目的是避免频繁创建/销毁连接的开销(连接建立涉及TCP握手、认证等步骤,耗时且耗资源),实现原理和连接数设计如下: #### (1)连接池的通用实现原理 所有连接池均采用“预创建+队列管理+复用回收”模式,结构如下: -
- 初始化阶段: 启动时创建“最小连接数”的连接(如MySQL连接池初始创建10个连接),存储在一个线程安全的队列(如
std::queue+std::mutex)中,每个连接包含: - 实际连接对象(如mysql_conn、redisContext、grpc::Channel); - 最后使用时间(用于超时回收); - 健康状态(如是否断开,通过心跳检测)。
- 初始化阶段: 启动时创建“最小连接数”的连接(如MySQL连接池初始创建10个连接),存储在一个线程安全的队列(如
-
- 获取连接: 业务线程请求连接时,从队列中取出一个空闲连接: - 若队列非空,直接返回连接(标记为“忙碌”); - 若队列空且当前连接数<“最大连接数”,创建新连接并返回; - 若队列空且已达最大连接数,阻塞等待(或返回“超时”,根据业务设置)。
-
- 释放连接: 业务线程使用完连接后,将连接归还给队列(标记为“空闲”),而非销毁;连接池定期(如每30秒)检查空闲连接,若超时(如5分钟未使用)且当前连接数>最小连接数,则销毁多余连接,节省资源。 4. 健康检测: 对数据库/Redis连接,定期发送心跳包(如MySQL的
ping()、Redis的PING命令),若连接失效则从队列中移除并重建,保证连接可用性。 #### (2)连接数设计(核心依据:并发量+服务性能) 不同连接池的连接数需根据依赖服务的性能和业务并发量调整:
- 释放连接: 业务线程使用完连接后,将连接归还给队列(标记为“空闲”),而非销毁;连接池定期(如每30秒)检查空闲连接,若超时(如5分钟未使用)且当前连接数>最小连接数,则销毁多余连接,节省资源。 4. 健康检测: 对数据库/Redis连接,定期发送心跳包(如MySQL的
-
- MySQL连接池: - 最小连接数:设为CPU核心数(如8核→8个),保证基础并发需求; - 最大连接数:参考MySQL服务器的
max_connections配置(默认151),结合业务峰值SQL查询量,通常设为50-100(避免超过数据库承载上限); - 依据:MySQL是多线程模型,过多连接会导致其内部线程切换开销增大,反而降低性能。
- MySQL连接池: - 最小连接数:设为CPU核心数(如8核→8个),保证基础并发需求; - 最大连接数:参考MySQL服务器的
-
- Redis连接池: - 最小连接数:10-20(Redis单线程处理命令,连接数可适当多于MySQL); - 最大连接数:200-500(Redis处理速度快,连接开销低,可支持更多并发连接); - 依据:Redis基于IO多路复用,单实例可支持10W+连接,连接池最大数主要受限于业务中Redis操作的并发量(如用户状态查询、消息缓存读写)。
-
- gRPC连接池: - 最小连接数:与微服务节点数匹配(如3个
ChatServer→每个服务对应3个连接); - 最大连接数:每个服务节点对应5-10个连接(gRPC连接基于HTTP/2,支持多路复用,无需过多连接); - 依据:gRPC连接是长连接,且支持一个连接上并发发送多个请求,连接数过多会浪费资源。 通过以上设计,连接池可将连接创建开销降低90%以上,同时避免服务过载,保障系统在高并发下的稳定性。
- gRPC连接池: - 最小连接数:与微服务节点数匹配(如3个
2、gRPC怎么来的,为什么叫gRPC
gRPC 是 Google 在内部 Stubby 框架基础上,为适应现代分布式系统需求开发的开源 RPC 框架,命名中的 “g” 代表其开发者 Google,“RPC” 则点明其远程过程调用的核心功能。它凭借高性能、跨语言等特性,成为分布式系统中服务间通信的主流选择
多服务器扩容未呈现“单服容量×服务器数量”的正比关系,核心原因是分布式系统引入了单服务器没有的“额外开销”和“非理想因素”,这些因素会消耗部分服务器资源,导致整体容量的“边际效益递减”。结合你的即时通讯项目场景,具体可拆解为以下5点关键原因:
“单服务器支持8000连接,多服务器分布部署可支持1W~2W活跃用户”,多服务器和单服务器相比应该是一个正比关系的扩容,这里为什么不是正比关系
一、分布式服务的“基础设施开销”占用资源
单服务器是“单体架构”,所有功能(用户连接、消息转发、数据存储)在一个进程内完成,几乎没有跨节点通信开销;而多服务器是“微服务架构”,需要额外的基础设施服务(如网关、状态同步、负载均衡),这些服务本身会占用CPU、内存、带宽资源,无法将所有服务器资源都用于承载用户连接。
- 例如你的项目中:
- GateServer网关:负责用户登录路由、请求转发,需要处理所有客户端的初始HTTP请求和TCP连接分发,本身会占用10%-20%的CPU/内存(尤其高并发登录时);
- StatusServer状态服务:实时同步各ChatServer的负载(连接数、CPU使用率),需要与所有ChatServer通过gRPC高频通信(如每3秒一次心跳),消耗带宽和计算资源;
- 服务间通信开销:用户消息跨ChatServer转发时(如A用户在ChatServer1,B用户在ChatServer2),需要通过gRPC或Redis Pub/Sub跨节点传输,这部分通信延迟和带宽占用,会让ChatServer的“有效承载能力”下降(单服8000连接是无跨节点转发的理想值,多服时每个ChatServer实际能承载的“独立用户”可能降至6000-7000)。
二、负载不均衡导致“部分节点先满”
正比扩容的前提是“用户连接能完美平均分配到所有服务器”,但实际分布式环境中,负载均衡无法做到100%均匀,总会有部分节点因“用户行为集中”或“路由策略偏差”先达到负载上限,导致整体容量未达理论值。
- 即时通讯场景的典型不均衡场景:
- 群组消息集中:若一个1000人的大群中,80%用户连接到ChatServer1,20%在ChatServer2,那么ChatServer1需要转发所有群消息(向800人推送),CPU/带宽会先满(即使其他ChatServer还有空闲);
- 登录峰值不均:GateServer的负载均衡策略(如“最小连接数”)可能因“用户登录时间集中”出现偏差,比如某10秒内80%登录请求路由到同一ChatServer,导致该节点过载,而其他节点空闲;
- 用户粘性差异:部分用户长期在线(如企业用户),会长期占用某ChatServer的连接,导致该节点连接数持续高位,无法再接纳新用户。
这种不均衡下,即使有N台服务器,整体容量也会受限于“负载最高的节点”,而非“单服容量×N”。
三、数据同步与一致性的“资源消耗”
单服务器中,用户状态(在线/离线)、聊天记录、好友关系都存储在本地(或本地连接的MySQL/Redis),访问无网络开销;多服务器中,为保证“数据一致性”(如用户切换ChatServer时状态同步、跨服消息可见),需要额外的同步机制,这些机制会消耗资源,降低服务器的“有效承载”。
- 你的项目中具体同步开销:
- 用户状态同步:用户登录时,StatusServer需要更新所有ChatServer的“在线用户列表”(或通过Redis共享状态),每次同步会产生Redis读写或gRPC调用,占用ChatServer的IO资源;
- 离线消息同步:用户从ChatServer1切换到ChatServer2时,需要从MySQL/Redis拉取未读消息,这部分IO操作会占用ChatServer的数据库连接池资源,导致可用于新连接的资源减少;
- 分布式锁开销:跨服操作(如创建群组、添加好友)需要分布式锁(如Redis锁)防止并发冲突,锁的获取/释放会产生延迟和CPU消耗,间接影响连接处理能力。
四、“连接数”与“活跃用户”的本质差异(易被忽略的前提)
你提到“单服务器支持8000连接”,但“多服务器支持1W~2W活跃用户”——这里有个关键前提:“连接数≠活跃用户数”,多服务器场景下“活跃用户的资源消耗远高于单服务器的‘纯连接’”。
- 单服务器的8000连接:可能包含大量“低活跃连接”(如用户打开客户端但不发消息),这类连接仅需维持TCP心跳(30秒/次),资源消耗极低;
- 多服务器的活跃用户:每个活跃用户会产生“跨服消息转发”(如与其他服务器的用户聊天)、“状态高频更新”(如在线状态同步)、“群组消息接收”(跨服广播),这些操作的CPU/带宽消耗是“纯连接”的5-10倍。
例如:单服8000连接中,若50%是低活跃用户,实际消耗的资源仅相当于4000活跃用户;而多服1W2W活跃用户,每个用户的资源消耗是单服低活跃用户的5倍,相当于单服5W10W低活跃连接的资源消耗——显然无法用“单服8000连接×服务器数”直接正比换算。
五、高可用设计的“冗余损耗”
多服务器部署通常需要“冗余设计”(避免单点故障),这部分冗余节点不会承载全量用户,会进一步拉低“整体容量/服务器数”的比例。
- 你的项目中可能的冗余设计:
- GateServer冗余:部署2台GateServer(主备或负载均衡),其中1台承担70%流量,1台承担30%(或备用),备用节点的资源未被完全利用;
- ChatServer冗余:为避免某ChatServer宕机导致用户失联,通常会预留10%-20%的“空闲ChatServer”(或每个ChatServer仅承载80%上限连接),防止突发流量;
- 数据库/Redis冗余:MySQL主从、Redis集群,从节点主要用于备份或读负载分担,不直接承载用户连接,也会消耗部分服务器资源。
总结:分布式扩容是“边际效益递减”的过程
单服务器是“无额外开销的理想状态”,多服务器则需要承担“基础设施开销、负载不均、数据同步、冗余损耗”等成本——这些成本会随着服务器数量增加而累积,导致“每增加一台服务器,新增的有效容量会逐渐减少”,最终整体容量落在“单服容量×服务器数”的理论下限(1W)和上限(2W)之间,而非严格的正比关系。
这也是分布式系统的普遍规律:扩容效率会随节点数增加而下降,不存在“无限正比扩容”,实际容量需要结合业务场景(如消息频率、跨服比例)和架构设计(如冗余度、同步机制)综合评估。
4、怎么封装的http和tcp
在你的即时通讯项目中,HTTP和TCP的封装需要兼顾“易用性”(上层调用无需关注底层细节)、“可靠性”(处理连接异常、数据完整性)和“适配业务”(如即时通讯的消息格式、登录流程)。以下从客户端(QT) 和服务器端(C++/Boost) 两个维度,详细说明HTTP和TCP的封装实现:
一、客户端(QT)的HTTP和TCP封装
QT提供了成熟的网络库(QTcpSocket、QNetworkAccessManager),封装的核心是简化上层调用(通过信号槽回调)、统一错误处理(如断线重连)和适配业务协议(如自定义消息格式)。
1. TCP封装(用于与ChatServer的长连接)
目标:实现“建立连接→发送消息→接收消息→断线重连”的完整链路,屏蔽QTcpSocket的底层细节。
核心类设计:TcpClient
class TcpClient : public QObject {
Q_OBJECT
public:
explicit TcpClient(QObject *parent = nullptr) : QObject(parent) {
// 初始化socket,绑定信号槽
socket = new QTcpSocket(this);
connect(socket, &QTcpSocket::connected, this, &TcpClient::onConnected);
connect(socket, &QTcpSocket::disconnected, this, &TcpClient::onDisconnected);
connect(socket, &QTcpSocket::readyRead, this, &TcpClient::onReadyRead);
connect(socket, &QTcpSocket::errorOccurred, this, &TcpClient::onError);
// 初始化重连定时器(断线后5秒重试)
reconnectTimer = new QTimer(this);
reconnectTimer->setInterval(5000);
reconnectTimer->setSingleShot(false);
connect(reconnectTimer, &QTimer::timeout, this, &TcpClient::connectToServer);
}
// 连接服务器(IP+端口)
void connectToServer(const QString &ip, quint16 port) {
this->ip = ip;
this->port = port;
if (socket->state() != QTcpSocket::ConnectedState) {
socket->connectToHost(ip, port);
}
}
// 发送消息(业务层只需传入序列化后的消息体)
bool sendMessage(const QByteArray &data) {
if (socket->state() != QTcpSocket::ConnectedState) {
emit errorOccurred("未连接到服务器");
return false;
}
// 自定义协议:4字节长度(大端) + 消息体(解决粘包)
quint32 len = data.size();
QByteArray buffer;
QDataStream stream(&buffer, QIODevice::WriteOnly);
stream.setByteOrder(QDataStream::BigEndian); // 统一字节序
stream << len; // 写入长度
buffer.append(data); // 写入消息体
return socket->write(buffer) == buffer.size();
}
signals:
void connected(); // 连接成功信号
void disconnected(); // 断开连接信号
void messageReceived(const QByteArray &data); // 收到消息信号(已解包)
void errorOccurred(const QString &error); // 错误信号
private slots:
void onConnected() {
reconnectTimer->stop(); // 连接成功,停止重连
emit connected();
}
void onDisconnected() {
emit disconnected();
reconnectTimer->start(); // 断开后启动重连
}
void onReadyRead() {
// 按自定义协议解包:先读4字节长度,再读对应长度的消息体
while (socket->bytesAvailable() >= 4) { // 确保能读到长度字段
QDataStream stream(socket);
stream.setByteOrder(QDataStream::BigEndian);
quint32 len;
stream >> len; // 读取长度
if (socket->bytesAvailable() < len) {
return; // 消息体未完全到达,等待下次readyRead
}
QByteArray data = socket->read(len); // 读取消息体
emit messageReceived(data); // 发送给业务层
}
}
void onError(QAbstractSocket::SocketError err) {
emit errorOccurred(socket->errorString());
}
private:
QTcpSocket *socket;
QTimer *reconnectTimer;
QString ip;
quint16 port;
};
封装关键点:
- 粘包/拆包处理:自定义协议(4字节长度+消息体),通过
onReadyRead按长度读取完整消息,避免粘包; - 断线重连:通过
QTimer实现自动重连,上层无需关心连接维护; - 信号槽解耦:业务层只需连接
messageReceived信号处理消息,调用sendMessage发送消息,无需操作底层socket; - 字节序统一:用大端字节序(网络字节序),避免不同平台(如Windows/Linux)的字节序差异。
2. HTTP封装(用于与GateServer的登录/注册请求)
目标:简化HTTP GET/POST请求,自动处理JSON序列化/反序列化,适配登录、注册等业务接口。
核心类设计:HttpClient
class HttpClient : public QObject {
Q_OBJECT
public:
explicit HttpClient(QObject *parent = nullptr) : QObject(parent) {
manager = new QNetworkAccessManager(this);
// 连接请求完成信号
connect(manager, &QNetworkAccessManager::finished,
this, &HttpClient::onReplyFinished);
}
// POST请求(如登录:提交用户名/密码)
void post(const QString &url, const QJsonObject ¶ms) {
QNetworkRequest request;
request.setUrl(QUrl(url));
request.setHeader(QNetworkRequest::ContentTypeHeader, "application/json");
// 序列化JSON参数
QByteArray data = QJsonDocument(params).toJson();
QNetworkReply *reply = manager->post(request, data);
// 存储reply与当前请求的关联(可通过reply->property区分请求类型)
reply->setProperty("requestType", "post");
}
// GET请求(如获取好友列表)
void get(const QString &url, const QMap<QString, QString> ¶ms) {
QString paramStr;
for (auto it = params.begin(); it != params.end(); ++it) {
paramStr += QString("%1=%2&").arg(it.key()).arg(it.value());
}
if (!paramStr.isEmpty()) paramStr.chop(1); // 去掉最后一个&
QString fullUrl = url + "?" + paramStr;
QNetworkRequest request;
request.setUrl(QUrl(fullUrl));
QNetworkReply *reply = manager->get(request);
reply->setProperty("requestType", "get");
}
signals:
void requestSuccess(const QJsonObject &response); // 请求成功(返回JSON)
void requestFailed(const QString &error); // 请求失败
private slots:
void onReplyFinished(QNetworkReply *reply) {
if (reply->error() != QNetworkReply::NoError) {
emit requestFailed(reply->errorString());
reply->deleteLater();
return;
}
// 解析响应(假设返回JSON)
QByteArray data = reply->readAll();
QJsonDocument doc = QJsonDocument::fromJson(data);
if (doc.isObject()) {
emit requestSuccess(doc.object());
} else {
emit requestFailed("响应格式错误,非JSON");
}
reply->deleteLater();
}
private:
QNetworkAccessManager *manager;
};
封装关键点:
- 协议适配:默认设置
Content-Type: application/json,与GateServer的HTTP API对接; - 序列化简化:业务层只需传入
QJsonObject(参数),底层自动转为JSON字符串; - 响应处理:自动解析JSON响应,通过
requestSuccess返回业务层,无需手动处理字节流; - 错误统一处理:网络错误(如超时、连接失败)或响应格式错误,通过
requestFailed统一通知。
二、服务器端的HTTP和TCP封装(C++/Boost)
服务器端需处理高并发,因此基于Boost.Asio(异步IO) 和Boost.Beast(HTTP) 封装,核心是“高效处理多连接”和“业务逻辑解耦”。
1. TCP封装(ChatServer的长连接处理)
目标:基于Boost.Asio的异步模型,实现“接收连接→管理连接→读写消息→协议解析”,支持高并发(单服8000连接)。
核心类设计:TcpSession(单个连接)和TcpServer(监听与管理)
(1)TcpSession:处理单个客户端连接
class TcpSession : public std::enable_shared_from_this<TcpSession> {
public:
TcpSession(tcp::socket socket, ChatServer *server)
: socket_(std::move(socket)), server_(server) {}
// 启动会话(开始读取数据)
void start() {
readLength(); // 先读消息长度(自定义协议:4字节长度)
}
// 发送消息(业务层调用,线程安全)
void send(const std::string &data) {
bool writeInProgress = !writeQueue_.empty();
writeQueue_.push(data);
if (!writeInProgress) {
write(); // 若当前无发送任务,直接开始发送
}
}
private:
// 读取消息长度(4字节,大端)
void readLength() {
auto self(shared_from_this());
asio::async_read(socket_, asio::buffer(&length_, 4),
[this, self](std::error_code ec, std::size_t /*length*/) {
if (!ec) {
length_ = ntohl(length_); // 网络字节序转主机字节序
readData(length_); // 读取消息体
} else {
// 连接断开,通知服务器移除会话
server_->removeSession(shared_from_this());
}
});
}
// 读取消息体(长度为length_)
void readData(size_t length) {
auto self(shared_from_this());
data_.resize(length);
asio::async_read(socket_, asio::buffer(data_),
[this, self](std::error_code ec, std::size_t /*length*/) {
if (!ec) {
// 消息体读取完成,交给业务层处理(如消息转发)
server_->onMessageReceived(shared_from_this(), data_);
readLength(); // 继续读取下一条消息
} else {
server_->removeSession(shared_from_this());
}
});
}
// 发送消息(从队列中取数据,异步发送)
void write() {
auto self(shared_from_this());
const std::string &data = writeQueue_.front();
// 按协议封装:4字节长度 + 消息体
uint32_t len = htonl(data.size()); // 主机字节序转网络字节序
std::vector<asio::const_buffer> buffers;
buffers.push_back(asio::buffer(&len, 4));
buffers.push_back(asio::buffer(data));
asio::async_write(socket_, buffers,
[this, self](std::error_code ec, std::size_t /*length*/) {
if (!ec) {
writeQueue_.pop();
if (!writeQueue_.empty()) {
write(); // 继续发送队列中的下一条消息
}
} else {
server_->removeSession(shared_from_this());
}
});
}
tcp::socket socket_; // 连接的socket
ChatServer *server_; // 指向服务器(用于回调)
uint32_t length_; // 消息长度(4字节)
std::string data_; // 消息体
std::queue<std::string> writeQueue_; // 发送队列(线程安全,需加锁)
std::mutex writeMutex_; // 保护writeQueue_的互斥锁
};
(2)TcpServer:监听端口,管理所有TcpSession
class TcpServer {
public:
TcpServer(asio::io_context &ioc, uint16_t port)
: acceptor_(ioc, tcp::endpoint(tcp::v4(), port)) {
doAccept(); // 开始接受连接
}
// 接受新连接
void doAccept() {
acceptor_.async_accept(
[this](std::error_code ec, tcp::socket socket) {
if (!ec) {
// 创建新会话,加入管理列表
auto session = std::make_shared<TcpSession>(std::move(socket), this);
std::lock_guard<std::mutex> lock(sessionsMutex_);
sessions_.insert(session);
session->start(); // 启动会话
}
doAccept(); // 继续接受下一个连接
});
}
// 移除会话(连接断开时调用)
void removeSession(std::shared_ptr<TcpSession> session) {
std::lock_guard<std::mutex> lock(sessionsMutex_);
sessions_.erase(session);
}
// 业务层:处理收到的消息(如转发给其他用户)
void onMessageReceived(std::shared_ptr<TcpSession> session, const std::string &data) {
// 解析data(Protobuf反序列化),根据消息类型处理
// ...(业务逻辑:如查找目标用户的session,调用其send方法转发)
}
private:
tcp::acceptor acceptor_;
std::set<std::shared_ptr<TcpSession>> sessions_; // 管理所有连接
std::mutex sessionsMutex_; // 保护sessions_的互斥锁
};
封装关键点:
- 异步IO模型:基于Boost.Asio的
async_accept、async_read、async_write,避免阻塞,支持高并发; - 连接管理:
TcpServer通过std::set管理所有TcpSession,连接断开时自动移除; - 发送队列:
TcpSession用writeQueue_缓存待发送消息,避免并发发送冲突(通过互斥锁保证线程安全); - 协议统一:与客户端一致的“4字节长度+消息体”协议,确保消息完整性。
2. HTTP封装(GateServer的API网关)
目标:基于Boost.Beast处理HTTP请求,实现“路由分发→参数解析→业务处理→响应构建”,适配登录、注册等接口。
核心类设计:HttpSession(处理单个HTTP请求)和HttpServer(监听与路由)
(1)HttpSession:处理单个HTTP连接的请求
class HttpSession : public std::enable_shared_from_this<HttpSession> {
public:
HttpSession(tcp::socket socket, HttpRouter &router)
: socket_(std::move(socket)), router_(router) {}
void run() {
readRequest(); // 开始读取HTTP请求
}
private:
// 读取HTTP请求
void readRequest() {
auto self(shared_from_this());
http::async_read(socket_, buffer_, req_,
[this, self](beast::error_code ec, std::size_t /*bytes_transferred*/) {
if (!ec) {
// 路由请求(根据路径和方法调用对应处理函数)
router_.handleRequest(req_, res_);
writeResponse(); // 发送响应
}
});
}
// 发送HTTP响应
void writeResponse() {
auto self(shared_from_this());
res_.keep_alive(req_.keep_alive()); // 支持长连接
http::async_write(socket_, res_,
[this, self](beast::error_code ec, std::size_t /*bytes_transferred*/) {
// 响应发送后,若为短连接则关闭,否则继续读取下一个请求
if (!ec && res_.keep_alive()) {
res_ = http::response<http::string_body>(); // 重置响应
readRequest();
}
});
}
tcp::socket socket_;
beast::flat_buffer buffer_; // 读缓冲区
http::request<http::string_body> req_; // HTTP请求
http::response<http::string_body> res_; // HTTP响应
HttpRouter &router_; // 路由管理器(绑定处理函数)
};
(2)HttpRouter:路由分发(将URL映射到处理函数)
class HttpRouter {
public:
// 注册处理函数(如POST /login → loginHandler)
void addRoute(http::verb method, const std::string &path,
std::function<void(const http::request<http::string_body> &,
http::response<http::string_body> &)> handler) {
routes_[{method, path}] = std::move(handler);
}
// 处理请求(查找路由并调用处理函数)
void handleRequest(const http::request<http::string_body> &req,
http::response<http::string_body> &res) {
auto key = std::make_pair(req.method(), req.target().to_string());
auto it = routes_.find(key);
if (it != routes_.end()) {
it->second(req, res); // 调用注册的处理函数
} else {
res.result(http::status::not_found);
res.body() = "Not found";
}
res.prepare_payload(); // 准备响应(设置Content-Length等)
}
private:
// 路由表:method+path → 处理函数
std::map<std::pair<http::verb, std::string>,
std::function<void(const http::request<http::string_body> &,
http::response<http::string_body> &)>> routes_;
};
(3)HttpServer:启动HTTP服务并关联路由
class HttpServer {
public:
HttpServer(asio::io_context &ioc, uint16_t port, HttpRouter &router)
: acceptor_(ioc, tcp::endpoint(tcp::v4(), port)), router_(router) {
doAccept();
}
void doAccept() {
acceptor_.async_accept(
[this](std::error_code ec, tcp::socket socket) {
if (!ec) {
// 创建HttpSession处理请求
std::make_shared<HttpSession>(std::move(socket), router_)->run();
}
doAccept();
});
}
private:
tcp::acceptor acceptor_;
HttpRouter &router_;
};
封装关键点:
- 路由机制:
HttpRouter通过method+path映射处理函数(如POST /login对应登录逻辑),业务层只需注册接口,无需关心底层HTTP解析; - 异步处理:基于Boost.Beast的异步HTTP读写,支持高并发请求(GateServer作为网关,需处理大量登录请求);
- 长连接支持:通过
keep-alive复用TCP连接,减少握手开销; - 业务解耦:HTTP解析与业务逻辑分离(处理函数仅需关注请求参数和响应结果)。
三、封装的核心价值
- 易用性:上层业务(如客户端的聊天界面、服务器的消息转发)无需关注socket操作、协议解析等细节,只需调用
sendMessage或注册路由函数; - 可靠性:内置粘包处理、断线重连、错误统一处理,避免重复开发;
- 可扩展性:若后续需要支持WebSocket(实时性更好),可基于现有TCP封装扩展,无需重构整体框架;
- 跨平台适配:客户端QT封装适配Windows/Linux/macOS,服务器端Boost封装适配不同服务器系统,符合项目“跨平台”需求。
通过这样的封装,项目的网络层逻辑清晰、可维护性强,能高效支撑“数千并发用户在线通信”的核心需求。
在分布式高并发系统(如你的即时通讯项目)中,并发(多线程/进程同时执行)和异步(非阻塞IO/任务调度)是提升性能的核心手段,但两者的结合也会带来共享数据竞争、资源调度复杂等问题。理解它们的本质、矛盾及平衡策略,是系统设计的关键。
5、对并发和异步的思考(异步时如何处理共享数据,引导思考如何平衡并发和异步)
一、并发与异步的本质:目标一致,手段不同
首先需要明确两者的核心区别与联系:
- 并发:通过“多线程/进程并行执行”提高CPU利用率,解决“单线程处理能力不足”的问题(如同时处理1000个用户的消息转发,单线程会卡顿,多线程可分工处理)。
- 异步:通过“非阻塞IO/回调机制”减少等待,解决“IO操作(如网络读写、数据库访问)阻塞线程”的问题(如一个线程无需等待TCP消息到达,可继续处理其他任务,消息到达后通过回调触发处理)。
目标一致:都是为了在有限的硬件资源下,提高系统的吞吐量(单位时间处理的任务数)和响应速度。
手段互补:并发解决CPU瓶颈,异步解决IO瓶颈——在你的项目中,ChatServer用“多线程io_context池(并发)+ Boost.Asio异步IO(异步)”正是这种互补的体现。
二、异步环境下的共享数据处理:核心是“避免竞争”
异步操作通常运行在多线程环境(如你的io_context池,多个线程同时处理IO事件),此时共享数据(如用户状态、连接列表)的并发访问是最常见的问题——若多个线程同时读写同一数据,可能导致数据错乱(如用户在线状态被同时修改为“在线”和“离线”)。
处理原则是:尽可能减少共享数据,必须共享时通过同步机制保证原子性。具体手段如下:
1. 减少共享数据:“线程封闭”优先
最安全的方式是让数据只被一个线程访问(线程封闭),避免共享。在异步系统中,可通过“连接绑定线程”实现:
- 你的
ChatServer中,每个TCP连接(TcpSession)被分配给固定的io_context(绑定一个线程),连接的所有操作(读、写、状态修改)都在该线程中处理。 - 此时,连接的私有数据(如用户ID、消息队列)无需同步——因为只有绑定的线程会访问,天然线程安全。
适用场景:单连接相关的数据(如每个用户的未读消息队列),通过“线程-连接”绑定实现封闭。
2. 必要共享时:轻量级同步机制
若数据必须被多线程共享(如全局的“在线用户-连接映射表”),需用同步机制保证原子性,但需选择开销最小的方案:
-
原子操作(
std::atomic):适用于简单数据(如计数器、布尔状态)。
例:统计在线用户数时,用std::atomic<int> online_count,多线程可直接online_count++,无需锁,性能极高。 -
互斥锁(
std::mutex):适用于复杂数据结构(如std::map存储用户-连接映射)。
例:你的项目中,TcpServer的sessions_集合被多线程访问(新连接加入、断开连接移除),需用std::mutex保护:// 安全地添加连接 std::lock_guard<std::mutex> lock(sessionsMutex_); sessions_.insert(session);注意:锁的粒度要小(只保护修改共享数据的代码块,避免整个函数加锁),否则会让异步操作退化为同步,降低并发效率。
-
无锁数据结构:适用于高并发读写场景(如队列)。
例:用boost::lockfree::queue作为全局消息队列,多线程可无锁地生产/消费消息,避免锁竞争开销。
3. 异步通信替代共享内存:“消息传递”解耦
跨线程/服务的共享数据,可通过“消息传递”替代直接内存共享——线程/服务间不直接访问对方数据,而是通过发送消息请求操作,由数据所属方处理并返回结果。
- 你的项目中,跨
ChatServer的消息转发(如用户A在Server1,用户B在Server2):
不直接访问对方的sessions_集合,而是通过Redis Pub/Sub(发布-订阅):Server1将消息发布到“用户B的频道”,Server2订阅该频道并接收消息,再转发给B。 - 优势:彻底避免跨服务的共享数据竞争,且符合分布式系统的“松耦合”设计。
三、平衡并发与异步:避免“异步被同步拖慢”“并发因竞争降级”
并发和异步的平衡核心是:让异步操作真正“非阻塞”,让并发线程“减少竞争”。过度并发会导致线程切换开销剧增,过度同步会让异步失去意义,需在以下维度权衡:
1. 线程数量:与CPU核心匹配,避免“线程爆炸”
- 异步IO的线程数(如
io_context池大小)应等于CPU核心数(如8核CPU设8个线程)。- 原因:异步IO的线程主要处理“IO事件回调”(CPU轻量操作),过多线程会导致上下文切换(每次切换约1-10微秒),抵消并发收益。
- 你的项目中,若单服务器8000连接,每个线程处理1000连接,8个线程足够——若盲目加到16个线程,切换开销会让性能下降。
2. 异步IO与业务逻辑分离:避免“IO线程被阻塞”
异步IO线程(处理async_read/async_write)应只做“IO读写”和“简单协议解析”,复杂业务逻辑(如消息路由、数据库查询)交给独立的业务线程池。
- 反例:若在
TcpSession的onMessageReceived(IO线程回调)中直接执行“查询MySQL好友列表”(阻塞IO),会导致IO线程被卡住,无法处理其他连接的IO事件,异步机制失效。 - 正例:IO线程读取消息后,将消息封装为任务投递给业务线程池,业务线程处理完成后,通过
post将结果投回IO线程发送:// IO线程中:收到消息后投递任务到业务线程池 auto self(shared_from_this()); threadPool.post([self, data]() { // 业务线程处理:解析消息、查询数据库、路由目标用户 std::string response = processMessage(data); // 结果投回IO线程发送 asio::post(self->socket_.get_executor(), [self, response]() { self->send(response); }); });
3. 同步粒度:“能不加锁就不加,能加细锁就不加粗锁”
- 避免全局大锁:若用一个全局锁保护所有共享数据(如整个
sessions_集合),高并发时所有线程会阻塞在锁等待上,并发退化为串行。 - 拆分锁或用“分片锁”:将全局数据拆分为多个分片,每个分片用独立的锁。例如,按用户ID哈希将“用户-连接映射”分为10个分片,每个分片一个锁,并发冲突概率降低10倍。
4. 利用异步IO的“天然顺序性”减少同步
异步IO的回调在同一个io_context(绑定线程)中执行时,天然具有顺序性(同一连接的read回调不会并发执行),可利用这一点减少锁。
- 例如,
TcpSession的writeQueue_:同一连接的send操作由IO线程的回调串行处理(前一条消息发送完成后才会处理下一条),因此只需保证“多线程调用send时队列的线程安全”(用锁保护入队),而发送过程本身无需锁——这比“每个发送操作都加锁”更高效。
四、结合项目的实践总结
你的即时通讯系统中,并发与异步的平衡体现在:
- 线程池大小:
io_context池线程数=CPU核心数,避免线程切换开销; - 数据隔离:连接绑定线程,私有数据线程封闭,减少共享;
- 轻量同步:共享数据(如在线用户表)用细粒度锁或Redis(分布式缓存,天然避免内存共享);
- 业务分离:IO线程处理读写,业务线程处理复杂逻辑,避免IO阻塞;
- 消息传递:跨服务通信用gRPC/Redis Pub/Sub,替代共享内存。
最终目标是:让异步操作充分利用“等待IO的时间”,让并发线程在“无竞争”的情况下高效处理任务——既不浪费CPU(并发不足),也不内耗在竞争上(同步过度)。这正是你的系统能支持“单服8000连接、多服2W活跃用户”的核心设计逻辑。
6、聊天服务器如何实现负载均衡,当有大量请求到来时,如何实现连接的均匀分布?
结合文档中llfcchat项目Day27“分布式聊天服务设计”的核心代码与配置,聊天服务器的负载均衡完全基于**“StatusServer动态选最小连接节点+ChatServer实时上报连接数+Redis统一存储状态”** 实现,大量请求下的连接均匀分布则依赖“实时状态同步+最小连接数算法+分布式通信保障”,具体流程与实现细节如下:
一、负载均衡的基础:构建分布式通信与状态存储体系
要实现负载均衡,首先需解决“跨服务通信”和“节点状态共享”两个核心问题,文档中通过gRPC连接池和Redis状态存储完成这一基础架构。
1. gRPC连接池:保障跨服务高效通信
分布式场景下,ChatServer之间、ChatServer与StatusServer之间需高频通信(如连接数同步、消息转发),文档通过ChatConPool(gRPC连接池)避免频繁创建连接的开销:
- 连接池实现:初始化时创建固定数量(如5个)的gRPC Channel和Stub,存入队列;业务调用时从队列取Stub,用完后归还,无需重复建立TCP连接(代码见
ChatConPool类)。 - 单例管理:通过
ChatGrpcClient单例类管理所有ChatServer的连接池,初始化时从配置文件(config.ini)读取“PeerServer”列表(如chatserver2),为每个对端服务器创建独立连接池(代码见ChatGrpcClient::ChatGrpcClient())。 - 作用:确保StatusServer查询ChatServer状态、ChatServer间转发消息时,通信延迟低、无连接瓶颈,为负载均衡提供高效数据传输通道。
2. Redis:统一存储ChatServer连接数状态
所有ChatServer的当前连接数(负载核心指标)统一存储在Redis中,形成“全局可见的负载视图”,具体操作逻辑如下:
- 连接数初始化:ChatServer启动时,通过
RedisMgr::HSet(LOGIN_COUNT, server_name, "0")将自身连接数设为0(代码见main函数); - 连接数递增:用户登录成功后,在
LogicSystem::LoginHandler()中,从Redis读取当前连接数(HGet(LOGIN_COUNT, server_name)),自增后再通过HSet写回(如count++后设为1); - 连接数清理:ChatServer关闭时,通过
RedisMgr::HDel(LOGIN_COUNT, server_name)删除自身连接数记录,避免状态残留。 - 数据结构:Redis中用哈希
LOGIN_COUNT存储所有ChatServer的连接数,field为ChatServer名称(如chatserver1),value为当前连接数(如1),StatusServer可直接读取该哈希获取全局负载。
二、负载均衡核心:StatusServer选“最小连接数”ChatServer
文档中负载均衡的核心逻辑在StatusServer的getChatServer()函数中,通过遍历所有ChatServer、对比Redis中的连接数、选择最小连接节点,实现“谁空闲就分配给谁”,具体步骤如下:
1. StatusServer加载ChatServer节点列表
StatusServer通过配置文件(config.ini)加载所有可用ChatServer信息,配置中[chatservers]字段指定节点名称列表(如chatserver1,chatserver2),每个节点的Host和Port单独配置(见文档中StatusServer配置):
[chatservers]
Name = chatserver1,chatserver2
[chatserver1]
Name = chatserver1
Host = 127.0.0.1
Port = 8090
[chatserver2]
Name = chatserver2
Host = 127.0.0.1
Port = 8091
StatusServer启动时解析该配置,将节点信息存入_servers哈希表(键为节点名,值为包含name/host/port/con_count的结构体),为后续选节点做准备。
2. 核心算法:遍历选“最小连接数”节点
StatusServer的getChatServer()函数是负载均衡的核心,逻辑为“遍历所有节点→查Redis连接数→选最小者”,代码与步骤对应如下:
ChatServer StatusServiceImpl::getChatServer() {
std::lock_guard<std::mutex> guard(_server_mtx);
// 1. 初始化最小节点为第一个节点
auto minServer = _servers.begin()->second;
// 2. 从Redis查该节点的当前连接数
auto count_str = RedisMgr::GetInstance()->HGet(LOGIN_COUNT, minServer.name);
minServer.con_count = count_str.empty() ? INT_MAX : std::stoi(count_str);
// 3. 遍历所有节点,对比连接数
for (auto& server : _servers) {
if (server.second.name == minServer.name) continue;
// 查当前节点的Redis连接数
count_str = RedisMgr::GetInstance()->HGet(LOGIN_COUNT, server.second.name);
server.second.con_count = count_str.empty() ? INT_MAX : std::stoi(count_str);
// 更新最小连接节点
if (server.second.con_count < minServer.con_count) {
minServer = server.second;
}
}
return minServer;
}
- 关键逻辑:
- 若Redis中无某节点的连接数(如节点刚启动未接收登录),默认设为
INT_MAX(避免分配无效节点); - 严格对比每个节点的
con_count(Redis中实时存储的连接数),确保选出当前负载最低的节点。
- 若Redis中无某节点的连接数(如节点刚启动未接收登录),默认设为
3. 给GateServer返回目标ChatServer
当大量用户通过GateServer请求“获取聊天服务器地址”时,StatusServer通过GetChatServer接口执行以下流程:
- GateServer调用StatusServer的
GetChatServergRPC接口,传入用户UID; - StatusServer调用
getChatServer()选出最小连接数的ChatServer; - 将该ChatServer的
Host(如127.0.0.1)和Port(如8090)封装到GetChatServerRsp,返回给GateServer; - GateServer将地址转发给客户端,客户端直接与目标ChatServer建立TCP长连接(文档测试结果:两个客户端登录分别被分配到
chatserver1和chatserver2,验证该逻辑生效)。
三、大量请求下的连接均匀分布:实时性与稳定性保障
当每秒数千甚至上万请求到来时,要避免“分配不均”(如某节点连接数骤增),需通过“实时状态同步+连接数绑定+故障隔离”确保均匀分布。
1. 连接数实时同步:确保StatusServer选节点无延迟
- 登录时即时更新:用户登录ChatServer后,
LoginHandler函数立即更新Redis中的连接数(count++后HSet),确保StatusServer查询到的是“毫秒级新鲜”的负载(代码见LogicSystem::LoginHandler()); - 节点关闭时清理:ChatServer异常或正常关闭时,通过
HDel删除Redis中自身的连接数记录,避免StatusServer将“已下线节点”纳入选则范围(代码见main函数的异常捕获块)。
2. 用户-服务器绑定:避免连接频繁迁移
IM场景中,用户登录后需与ChatServer保持长连接,频繁迁移会导致消息丢失,文档通过以下方式绑定“用户-服务器”关系,间接保障连接均匀:
- Redis存储绑定关系:用户登录时,通过
RedisMgr::Set(USERIPPREFIX + uid_str, server_name)将“用户UID”与“ChatServer名称”绑定(如uip_1002 → chatserver1); - Session管理:通过
UserMgr单例类管理“UID-Session”映射,用户断线重连时,优先查询Redis获取原ChatServer,若原节点仍健康且有容量,直接分配原节点(避免新节点被重复选择)。
3. 配置化节点管理:支持动态扩容应对峰值
当大量请求导致现有ChatServer连接数接近上限(如单节点支持8000连接)时,可通过配置快速扩容:
- 新增ChatServer:复制现有ChatServer,修改
config.ini(如新增chatserver3,设置独立Port和RPCPort); - StatusServer自动识别:StatusServer重启后,从
[chatservers]配置中读取新增节点,自动纳入“最小连接数”选择范围; - 无缝分担负载:新增节点连接数初始为0,StatusServer会优先将新请求分配给它,快速缓解原有节点压力,实现“扩容即分担”。
四、负载均衡完整流程(贴合文档代码)
- 初始化:
- ChatServer启动:设Redis连接数为0,启动gRPC服务(监听
RPCPort); - StatusServer启动:加载
chatservers配置,初始化节点列表。
- ChatServer启动:设Redis连接数为0,启动gRPC服务(监听
- 用户请求:
- 客户端向GateServer发起登录请求,GateServer调用StatusServer的
GetChatServer接口;
- 客户端向GateServer发起登录请求,GateServer调用StatusServer的
- 节点选择:
- StatusServer调用
getChatServer(),遍历所有ChatServer,从Redis查连接数,选最小者;
- StatusServer调用
- 连接建立:
- GateServer返回目标ChatServer地址,客户端与该ChatServer建立TCP长连接;
- 状态更新:
- 用户登录成功,ChatServer更新Redis连接数(
count++),绑定“UID-服务器”关系;
- 用户登录成功,ChatServer更新Redis连接数(
- 大量请求应对:
- 新请求持续触发StatusServer选“最小连接节点”,新增ChatServer自动分担负载,Redis实时同步连接数确保分配均匀。
7.怎么测出单服务器的连接数的,连接数的瓶颈在哪儿?
项目客户端基于 QT 的TcpManager(day15)封装 TCP 长连接,服务端基于 Boost.Asio(day16)实现异步通信,因此改造 QT 客户端为压测工具是最优选择 —— 可完全复用项目的连接逻辑(如心跳包、协议格式),避免现成工具(如 JMeter)因 “协议不匹配” 导致的测试偏差。
自定义 QT 压测客户端改造要点(关联文档模块)
多线程连接管理(参考 day15TcpManager):
新增 “压测模式”,用QThreadPool创建大量线程(每个线程模拟 1 个用户),线程内调用TcpManager::connectToServer与目标 ChatServer 建立连接,连接成功后触发onConnected信号,更新全局连接数计数器;
长连接保活(复用 day35 心跳逻辑):
连接建立后,按项目默认心跳周期(如 30 秒 / 次)发送心跳包(MSG_HEARTBEAT),避免 ChatServer 因 “无数据传输” 主动断开连接(day35 文档明确 “心跳用于检测连接有效性”);
连接状态统计(结合 day09 Redis):
压测客户端将 “成功连接数、失败数、断开数” 实时写入 Redis(键:test:conn_stats),方便多压测机分布式测试时汇总数据;同时在服务端通过RedisMgr::HGet(LOGIN_COUNT, server_name)(day27 文档)读取当前连接数,确保两端统计一致。
程序设计层面:asio 异步模型的 “设计缺陷瓶颈”(核心瓶颈)
项目 day16 的 asio 服务器、day17 的连接管理、day27 的分布式前单服设计,若存在设计缺陷,会直接导致连接数无法突破,核心瓶颈点:
asioio_context池配置不当(关联 day16/day27):
asio 的io_context是 IO 事件调度核心,若单服仅用 1 个io_context绑定 1 个线程,所有连接的 “心跳回调、消息读写” 都会挤在一个线程,CPU 会因 “回调处理不过来” 长期 100%,导致新连接无法被async_accept处理;
正确设计应是 “io_context数 = CPU 核心数”(如 8 核 CPU 设 8 个io_context),每个io_context绑定 1 个线程(day27 分布式设计提及此逻辑),若配置错误(如线程数远大于 CPU 核心数),会导致线程上下文切换开销剧增,反而降低并发能力;
连接管理内存泄漏(关联 day17/day33):
项目 day17 通过UserMgr管理 “UID-Session” 映射,day33 单服踢人逻辑通过ClearSession移除断开的连接;若ClearSession未正确调用(如连接异常断开时未删除_sessions集合中的Session对象),会导致内存持续增长 ——8000 个连接若每个Session泄漏 1KB 内存,1 小时后会泄漏 8MB,长期运行会因内存耗尽崩溃;
同步锁竞争过载(关联 day09/day32):
服务端用std::mutex保护_sessions(连接集合),若大量连接并发创建 / 断开(如压测时每秒 1000 个连接请求),所有线程会阻塞在std::lock_guard上,导致连接处理效率骤降;项目 day32 的 “分布式锁” 虽为分布式场景设计,但单服可借鉴 “细粒度锁” 思路(如按SessionID哈希分锁),减少竞争。
8、数据库的连接池是怎么设置的,当有大量请求到来时,如何处理连接超时(连接泄露)问题
结合llfcchat项目全周期文档(尤其day09“Redis服务搭建”、day11“注册功能”及day27“分布式服务设计”中的连接池思路),数据库连接池(含MySQL和Redis)的设置核心是“预创建连接+动态伸缩+安全复用”,而大量请求下的连接超时/泄露问题则通过“超时控制、空闲回收、泄露检测”三重机制解决,完全贴合项目“高性能、高可用”的设计目标。
一、数据库连接池的设置(MySQL+Redis,贴合项目实现)
项目中数据库连接池(MySQL用于用户数据/好友关系,Redis用于缓存/状态)的设计遵循“单例管理+预创建连接+队列复用”逻辑,核心参考day09“Redis连接池”和day27“ChatConPool(gRPC连接池)”的实现思路,具体设置如下:
1. 核心设计原则(贯穿MySQL/Redis连接池)
- 单例模式:避免连接池重复创建(如
RedisMgr、MysqlMgr均为单例,参考day09“Redis服务搭建”中“单例管理连接池”的思路),确保全项目共享一个连接池实例; - 预创建最小连接:初始化时创建“最小连接数”的数据库连接,避免请求到来时临时创建连接的开销(项目中Redis连接池初始化参考day27
ChatConPool的poolSize_参数); - 动态伸缩:当空闲连接不足时,创建新连接至“最大连接数”;当空闲连接过多时,回收至“最小连接数”,平衡性能与资源占用;
- 连接安全复用:通过“队列+互斥锁+条件变量”管理连接,确保多线程并发获取/归还连接时线程安全(直接复用day27
ChatConPool的线程同步逻辑)。
2. MySQL连接池设置(关联day11“注册功能”,隐含连接池需求)
项目day11需频繁操作MySQL(如用户注册写入用户表、登录校验查询),因此封装MysqlConPool,核心参数与逻辑如下:
(1)核心参数配置(基于项目业务场景)
| 参数 | 取值建议(项目适配) | 作用说明 |
|---|---|---|
| 最小连接数(minConn) | CPU核心数(如8核→8) | 初始化时创建的连接数,确保基础并发需求(如登录请求峰值低时,无需创建新连接); |
| 最大连接数(maxConn) | 50-100(参考MySQL默认max_connections=151) | 避免连接数超过MySQL服务器承载上限(MySQL单实例默认支持151个连接,预留部分给管理); |
| 连接空闲超时(idleTimeout) | 300秒(5分钟) | 空闲连接超过此时间则被回收,避免资源浪费(如夜间低峰期,释放多余连接); |
| 获取连接超时(waitTimeout) | 3秒 | 当连接池满时,线程等待连接的最大时间,超时返回失败(避免请求长期阻塞); |
| 连接存活检测(pingInterval) | 60秒 | 定期向MySQL发送ping()指令,检测连接有效性(避免使用失效连接,如MySQL重启后); |
(2)核心逻辑实现(参考day27ChatConPool)
class MysqlConPool : public Singleton<MysqlConPool> { // 单例模式,day09/27均用此模式
public:
// 初始化连接池(读取配置文件,day11提到MySQL配置:Host/Port/User/Passwd)
bool Init(const std::string& host, int port, const std::string& user,
const std::string& passwd, const std::string& dbName,
size_t minConn = 8, size_t maxConn = 50, int idleTimeout = 300) {
minConn_ = minConn;
maxConn_ = maxConn;
idleTimeout_ = idleTimeout;
// 预创建最小连接数的MySQL连接
for (size_t i = 0; i < minConn_; ++i) {
MYSQL* conn = mysql_init(nullptr);
if (mysql_real_connect(conn, host.c_str(), user.c_str(), passwd.c_str(),
dbName.c_str(), port, nullptr, 0) == nullptr) {
return false; // 连接失败,初始化失败
}
idleConns_.push(std::make_pair(conn, std::chrono::steady_clock::now())); // 记录创建时间
}
// 启动空闲连接回收定时器(参考day35心跳逻辑的定时器)
std::thread([this]() {
while (!stop_) {
std::this_thread::sleep_for(std::chrono::seconds(10)); // 每10秒检查一次
CleanIdleConns(); // 回收空闲超时连接
}
}).detach();
return true;
}
// 获取连接(带超时)
std::shared_ptr<MYSQL> GetConn(int waitTimeout = 3) {
std::unique_lock<std::mutex> lock(mtx_);
// 等待连接(带超时,避免无限阻塞)
if (!cond_.wait_for(lock, std::chrono::seconds(waitTimeout), [this]() {
return !idleConns_.empty() || currentConnNum_ < maxConn_;
})) {
return nullptr; // 超时,返回空(获取连接失败)
}
MYSQL* conn = nullptr;
if (!idleConns_.empty()) {
// 从空闲队列取连接
auto [idleConn, createTime] = idleConns_.front();
idleConns_.pop();
// 检测连接是否有效(如MySQL断开)
if (mysql_ping(idleConn) != 0) {
mysql_close(idleConn); // 失效连接关闭
conn = CreateNewConn(); // 创建新连接
} else {
conn = idleConn;
}
} else {
// 空闲连接不足,创建新连接(未达最大连接数)
conn = CreateNewConn();
}
if (conn == nullptr) return nullptr;
currentConnNum_++;
// 用shared_ptr管理连接,自动归还(析构时调用ReturnConn)
return std::shared_ptr<MYSQL>(conn, [this](MYSQL* p) {
ReturnConn(p);
});
}
private:
// 私有构造(单例)
MysqlConPool() : currentConnNum_(0), stop_(false) {}
friend class Singleton<MysqlConPool>;
// 创建新连接
MYSQL* CreateNewConn() {
MYSQL* conn = mysql_init(nullptr);
if (mysql_real_connect(conn, host_.c_str(), user_.c_str(), passwd_.c_str(),
dbName_.c_str(), port_, nullptr, 0) == nullptr) {
mysql_close(conn);
return nullptr;
}
return conn;
}
// 归还连接
void ReturnConn(MYSQL* conn) {
std::lock_guard<std::mutex> lock(mtx_);
idleConns_.push(std::make_pair(conn, std::chrono::steady_clock::now()));
currentConnNum_--;
cond_.notify_one(); // 通知等待的线程有空闲连接了
}
// 回收空闲超时连接
void CleanIdleConns() {
std::lock_guard<std::mutex> lock(mtx_);
auto now = std::chrono::steady_clock::now();
while (!idleConns_.empty()) {
auto [conn, createTime] = idleConns_.front();
// 计算空闲时间 = 当前时间 - 上次归还时间
auto idleTime = std::chrono::duration_cast<std::chrono::seconds>(now - createTime).count();
if (idleTime > idleTimeout_ && currentConnNum_ > minConn_) {
// 空闲超时且连接数超过最小,关闭连接
mysql_close(conn);
idleConns_.pop();
currentConnNum_--;
} else {
break; // 队列按时间排序,前面的没超时,后面的也不会超时
}
}
}
// 核心参数
size_t minConn_; // 最小连接数
size_t maxConn_; // 最大连接数
int idleTimeout_; // 空闲超时时间(秒)
size_t currentConnNum_; // 当前总连接数
bool stop_; // 停止标志
std::queue<std::pair<MYSQL*, std::chrono::steady_clock::time_point>> idleConns_; // 空闲连接队列(含时间戳)
std::mutex mtx_; // 互斥锁
std::condition_variable cond_; // 条件变量(用于等待连接)
// MySQL配置(从配置文件读取,day11文档提及)
std::string host_;
int port_;
std::string user_;
std::string passwd_;
std::string dbName_;
};
3. Redis连接池设置(明确关联day09“Redis服务搭建”)
Redis连接池逻辑与MySQL类似,核心差异在于客户端(Redis用redisContext,MySQL用MYSQL)和检测方式(Redis用redisCommand发送PING),关键参数与逻辑如下:
- 核心参数:最小连接数=10(day09提到“Redis连接池”,适配高频缓存查询)、最大连接数=200(Redis单实例支持10W+连接,无需过高)、空闲超时=180秒(3分钟,短于MySQL,因Redis连接更轻量);
- 核心差异:
redisContext是线程不安全的,因此连接池确保“一个连接同一时间仅被一个线程使用”,归还时无需重置(MySQL需重置事务状态),仅需检测连接有效性(redisCommand(conn, "PING")返回PONG则有效); - 代码参考:day09“添加redis连接池和文档”,逻辑与
MysqlConPool一致,仅替换客户端类型(redisContext替代MYSQL)。
二、大量请求下:连接超时与泄露的处理方案
当每秒数千请求到来时(如登录峰值、好友申请高峰),易出现“获取连接超时”(连接池满)和“连接泄露”(连接未归还),项目通过以下机制解决:
1. 连接超时处理(分“获取超时”和“连接空闲超时”)
(1)获取连接超时:避免请求长期阻塞
- 超时等待带时间限制:参考
MysqlConPool::GetConn中的cond_.wait_for,设置等待时间(如3秒),超过时间返回nullptr,业务层可捕获并返回“服务繁忙,请稍后重试”(如day14“登录功能”中,登录请求获取MySQL连接超时,返回ErrorCodes::DbConnTimeout); - 动态扩容缓冲:当连接池满且请求仍大量到来时,若当前连接数未达数据库最大承载(如MySQL
max_connections=151),可临时上调连接池maxConn(如从50调至80),但需避免超过数据库上限(通过配置中心动态调整,项目未直接提及,但可基于day27分布式配置思路扩展); - 请求排队限流:结合项目day04“beast搭建http服务器”的请求队列,将获取连接失败的请求暂存队列(如队列长度1000),按FIFO顺序重试,避免直接拒绝请求(适用于非实时场景,如聊天记录查询)。
(2)连接空闲超时:避免资源浪费
- 定时器回收空闲连接:参考
MysqlConPool::CleanIdleConns,每10秒检查空闲队列,超过idleTimeout(如MySQL 5分钟)且连接数超过minConn的连接,直接关闭并从队列移除,释放数据库资源; - 连接有效性预检测:获取连接时(
GetConn),先调用mysql_ping(MySQL)或PING(Redis)检测连接是否有效,避免使用“死连接”(如数据库重启后,原连接失效),若无效则自动创建新连接,屏蔽底层故障。
2. 连接泄露处理(核心是“检测+回收+报警”)
连接泄露指“连接从池获取后未归还”(如业务逻辑异常、忘记调用归还接口),长期会导致连接池耗尽(currentConnNum_达maxConn但idleConns_为空),处理方案如下:
(1)泄露检测:识别未归还的连接
- 连接生命周期跟踪:在连接池内为每个连接添加“借出时间戳”和“借用线程ID”,获取连接时记录(
借出时间=now(),线程ID=this_thread::get_id()),归还时清空; - 定时检测异常连接:新增“泄露检测定时器”(每60秒执行一次),遍历所有“已借出但未归还”的连接(需维护
borrowedConns_哈希表:连接地址→{借出时间, 线程ID}),若借出时间超过阈值(如10分钟,远长于正常业务耗时),则判定为泄露; - 日志报警与定位:检测到泄露时,打印日志(如“连接0x123456借出超过10分钟,线程ID=0xabc,疑似泄露”),结合项目day30“面试技巧”中的日志排查思路,定位业务代码中未归还连接的位置(如
LoginHandler中获取连接后,异常分支未释放)。
(2)泄露回收:强制释放异常连接
- MySQL连接强制回收:若检测到泄露连接,调用
mysql_close(conn)关闭连接(需确保连接未在执行事务,可通过mysql_rollback(conn)回滚未提交事务),并从borrowedConns_中移除,currentConnNum_减1,补充新连接至idleConns_; - Redis连接强制回收:
redisContext泄露时,直接调用redisFree(conn)释放,因Redis无事务状态,无需回滚,回收成本更低。
(3)预防泄露:从代码层面规避
- 智能指针自动归还:参考
MysqlConPool::GetConn返回std::shared_ptr<MYSQL>,析构时自动调用ReturnConn,避免手动归还遗漏(项目day27ChatConPool也用unique_ptr管理gRPC连接,同理迁移至数据库连接池); - 业务层异常捕获:在获取连接的业务逻辑中(如day11“注册功能”),用
try-catch包裹代码,确保异常分支(如注册参数非法)也能归还连接:void RegisterHandler(const RegisterReq& req) { auto conn = MysqlConPool::Inst().GetConn(); if (!conn) { /* 处理超时 */ return; } try { // 执行SQL:插入用户数据 std::string sql = "INSERT INTO user(...) VALUES(...)"; mysql_query(conn.get(), sql.c_str()); } catch (...) { // 异常分支也会触发shared_ptr析构,归还连接 return; } // 正常分支自动归还(shared_ptr出作用域析构) }
3. 监控与告警:提前发现问题
- 实时监控连接池状态:将连接池的
currentConnNum_(总连接数)、idleConns_.size()(空闲数)、borrowedNum_(借出数)实时写入Redis(键:monitor:db:conn_stats),结合项目day09 Redis,可通过可视化工具(如Grafana)展示,当idleConns_.size()=0且borrowedNum_=maxConn时,触发“连接池满”告警; - 泄露告警阈值:当“借出连接平均时长”(
总借出时间/借出数)超过阈值(如30秒,正常业务耗时仅100ms),或“泄露连接数”超过maxConn的5%(如50个连接中3个泄露),通过邮件/日志告警(参考day08“邮箱认证服务”的邮件发送逻辑,扩展告警功能)。
9.MySQL连接池的设计要点
结合llfcchat项目的MySQL使用场景(如day11“注册功能”的用户数据存储、day14“登录功能”的账号校验)及连接池设计思路(参考day09“Redis连接池”、day27“gRPC连接池”),MySQL连接池的设计需围绕“资源复用、线程安全、故障容错、性能平衡”四大核心目标,关键要点可拆解为6个模块,每个要点均贴合项目技术栈与实际业务需求:
一、基础架构设计:单例管理+队列存储
基础架构是连接池的“骨架”,需确保全项目资源共享、连接管理有序,核心设计要点:
- 单例模式封装
- 采用“饿汉/懒汉单例”(项目常用懒汉+互斥锁,如day09
RedisMgr),避免多线程重复创建连接池实例,确保全项目仅共享1个连接池,减少资源浪费; - 私有构造函数+静态实例获取接口(如
MysqlConPool::Inst()),屏蔽外部创建,统一连接池的初始化与销毁逻辑。
- 采用“饿汉/懒汉单例”(项目常用懒汉+互斥锁,如day09
- 双队列管理连接
- 空闲连接队列:存储“已创建且可用”的MySQL连接(
MYSQL*),搭配“借出时间戳”(std::chrono::steady_clock::time_point),用于后续空闲回收与泄露检测; - 借出连接哈希表:记录“已被业务线程获取但未归还”的连接(键:连接地址,值:{借出线程ID、借出时间}),用于泄露检测与强制回收(参考day27
ChatConPool的连接跟踪思路)。
- 空闲连接队列:存储“已创建且可用”的MySQL连接(
二、核心参数配置:平衡性能与数据库承载
参数配置直接决定连接池的“容量上限”与“资源利用率”,需结合MySQL服务器性能与项目业务峰值设计:
| 参数名称 | 设计要点 | 项目适配示例(参考day11/day27) |
|---|---|---|
| 最小连接数(minConn) | 初始化时预创建的连接数,确保低峰期无需临时创建连接,减少延迟; 取值建议: CPU核心数(如8核→8个),匹配项目asioio_context池线程数。 | minConn=8(适配8核服务器,day27分布式单服配置) |
| 最大连接数(maxConn) | 避免超过MySQL服务器的max_connections(默认151),预留10%-20%给管理连接;取值建议: MySQL max_connections × 0.8(如151×0.8≈120,项目单服设50-80)。 | maxConn=50(单服场景,避免MySQL过载) |
| 获取连接超时(waitTimeout) | 线程等待空闲连接的最大时间,避免无限阻塞; 取值建议:2-3秒,业务层可返回“服务繁忙”(如day14登录超时返回 ErrorCodes::DbConnTimeout)。 | waitTimeout=3秒 |
| 连接空闲超时(idleTimeout) | 空闲连接的最大存活时间,超时后回收,释放MySQL资源; 取值建议:3-5分钟(MySQL连接空闲过久易失效,day35心跳逻辑可参考此周期)。 | idleTimeout=5分钟 |
| 连接检测周期(pingInterval) | 定期检测空闲连接有效性的间隔,避免使用“死连接”; 取值建议:60秒,通过 mysql_ping()验证连接(参考day09 Redis连接检测)。 | pingInterval=60秒 |
三、线程安全设计:互斥锁+条件变量同步
项目多线程场景(如asioio_context池线程、业务线程)会并发获取/归还连接,需通过同步机制避免竞争:
- 互斥锁保护共享资源
- 用
std::mutex(或std::recursive_mutex)保护“空闲队列”“借出哈希表”的读写操作,确保同一时间仅1个线程修改共享数据(如GetConn时取连接、ReturnConn时归连接,参考day27ChatConPool的mutex_); - 锁粒度最小化:仅在“修改队列/哈希表”时加锁,避免业务逻辑(如SQL执行)被锁阻塞。
- 用
- 条件变量实现等待唤醒
- 用
std::condition_variable(如cond_)实现“无空闲连接时线程等待”与“连接归还时唤醒等待线程”,避免线程轮询浪费CPU(参考MysqlConPool::GetConn的cond_.wait_for与ReturnConn的cond_.notify_one()); - 等待时带超时(
wait_for),避免线程因“连接永久耗尽”无限阻塞。
- 用
四、连接生命周期管理:从创建到回收全链路
连接的全生命周期管理是连接池的核心,需确保“连接可用、安全复用、及时回收”:
- 初始化:预创建最小连接
- 连接池启动时(
Init接口),批量创建minConn个MySQL连接,调用mysql_real_connect()完成初始化,并存入空闲队列; - 初始化失败时(如MySQL地址错误),直接返回错误,避免后续业务调用异常(参考day11注册功能的数据库初始化校验)。
- 连接池启动时(
- 获取:有效性预检测+超时控制
- 从空闲队列取连接前,先调用
mysql_ping()检测连接是否有效(如MySQL重启后原连接失效),无效则关闭并创建新连接; - 若空闲队列为空且未达
maxConn,则创建新连接;若已达maxConn,则通过cond_.wait_for等待,超时返回nullptr(业务层捕获并处理)。
- 从空闲队列取连接前,先调用
- 归还:状态重置+队列回存
- 业务线程归还连接时(
ReturnConn),先重置连接状态:- 回滚未提交事务(
mysql_rollback(conn)),避免影响下一个线程; - 清空结果集(
mysql_free_result(res)),释放内存;
- 回滚未提交事务(
- 将连接存入空闲队列,更新“空闲时间戳”,并调用
cond_.notify_one()唤醒等待线程。
- 业务线程归还连接时(
- 回收:空闲超时+强制清理
- 启动独立定时器(如每10秒执行),遍历空闲队列,回收“空闲时间>idleTimeout”且“总连接数>minConn”的连接(
mysql_close(conn)); - 检测到连接泄露(借出时间>阈值,如10分钟)时,强制关闭连接,从借出哈希表移除,补充新连接至空闲队列(参考之前讨论的泄露处理逻辑)。
- 启动独立定时器(如每10秒执行),遍历空闲队列,回收“空闲时间>idleTimeout”且“总连接数>minConn”的连接(
五、异常容错设计:屏蔽底层数据库故障
大量请求下,MySQL可能出现“连接断开、重启、SQL执行超时”等故障,连接池需具备容错能力:
- 连接失效自动重试
- 获取连接时检测到无效(
mysql_ping()失败),自动创建新连接并替换,业务层无需感知; - 若创建新连接失败(如MySQL宕机),返回“数据库暂时不可用”错误,业务层可触发降级(如缓存临时数据,day09 Redis可作为降级存储)。
- 获取连接时检测到无效(
- SQL执行异常隔离
- 连接池仅负责“连接管理”,不处理SQL执行逻辑,但需确保“异常连接不污染其他线程”:若业务线程执行SQL时触发连接错误(如
mysql_query()返回非0),归还连接时标记为“异常”,连接池直接关闭该连接,不回存空闲队列。
- 连接池仅负责“连接管理”,不处理SQL执行逻辑,但需确保“异常连接不污染其他线程”:若业务线程执行SQL时触发连接错误(如
- 动态参数调整(扩展)
- 支持通过配置中心动态调整
maxConn(如峰值时从50调至80),但需校验不超过MySQLmax_connections; - 项目可基于day27分布式配置思路,在“连接池满且请求激增”时临时扩容,峰值后自动缩容。
- 支持通过配置中心动态调整
六、监控与告警:提前发现问题
为避免连接池成为性能瓶颈或故障点,需添加监控与告警机制:
- 实时监控核心指标
- 记录并暴露指标:总连接数(
currentConnNum_)、空闲连接数(idleConns_.size())、借出连接数(borrowedNum_)、获取超时次数、连接失效次数; - 指标存储:写入Redis(如
monitor:mysql:conn_stats,day09 Redis),支持可视化工具(如Grafana)展示。
- 记录并暴露指标:总连接数(
- 异常告警触发
- 触发条件:
- 空闲连接数=0且借出连接数=maxConn(连接池满);
- 获取连接超时次数>阈值(如1分钟内100次);
- 连接泄露数>maxConn×5%(如50个连接中3个泄露);
- 告警方式:参考day08“邮箱认证服务”的邮件发送逻辑,触发邮件/日志告警,方便运维排查。
- 触发条件:
10、gRPC在项目中解决的什么问题
结合llfcchat项目全周期文档(day06“Windows配置gRPC”、day07“VS配置gRPC”、day27“分布式服务设计”等),gRPC的核心作用是解决分布式架构下“跨服务高效通信、接口标准化、复杂数据传输”三大核心问题,为服务间协作提供低延迟、高可靠的通信支撑,完全贴合项目“多服务拆分(GateServer/StatusServer/ChatServer)”的架构设计目标。
一、解决“分布式服务间的高效跨服务通信”问题
项目从单服务(day16 asio TCP服务器)演进到分布式(day27)后,多个服务(如ChatServerA/ChatServerB、StatusServer/GateServer)需频繁交互,传统HTTP通信(day04 Beast HTTP服务器)存在“延迟高、连接开销大”的问题,gRPC通过以下特性解决:
1. 基于HTTP/2的多路复用,降低连接开销
- 问题背景:若用HTTP/1.1实现服务间通信(如ChatServerA向ChatServerB转发消息),每次请求需建立一个TCP连接,大量跨服务请求会导致“连接爆炸”(如1000次消息转发需1000个连接),占用服务器端口与带宽资源;
- gRPC解决方案:基于HTTP/2实现“多路复用”——单个TCP连接可同时处理多个gRPC请求(请求通过二进制帧标识,互不干扰),项目day27的
ChatConPool(gRPC连接池)进一步复用连接(初始化5个连接,避免频繁创建),连接开销降低80%以上; - 项目场景:多ChatServer间的消息转发(day29“好友认证和聊天通信”)、StatusServer向GateServer返回ChatServer地址(day27),均通过gRPC的多路复用减少连接资源消耗。
2. 二进制传输+Protobuf序列化,降低延迟与带宽
- 问题背景:若用JSON(day05“解析JSON数据”)传输服务间数据(如用户在线状态、好友申请信息),文本格式冗余度高(如字段名重复),序列化/反序列化耗时,在高频通信场景(如每秒1000次跨服消息)会导致延迟飙升;
- gRPC解决方案:
- 数据传输:采用二进制帧格式,比JSON文本小30%-50%;
- 序列化:基于Protobuf定义服务接口与数据结构(如
AddFriendReq/AddFriendRsp,day27代码),Protobuf序列化速度比JSON快2-5倍,且生成强类型代码(避免字段解析错误);
- 项目场景:ChatServer通过gRPC调用
NotifyTextChatMsg(day27代码)转发跨服消息时,Protobuf序列化的消息体仅需100字节(JSON需200+字节),带宽占用减半,延迟控制在10ms内。
二、解决“服务间接口标准化与兼容性”问题
分布式服务拆分后,不同服务(如AuthServer/ChatServer)由同一团队开发,但接口定义不统一会导致“协议混乱”(如A服务用“user_id”字段,B服务用“uid”),gRPC通过“接口定义+代码生成”强制标准化:
1. Protobuf IDL统一接口定义,避免协议歧义
- 问题背景:若服务间通过“自定义二进制协议”通信(如直接打包struct传输),字段增减、类型修改会导致“服务不兼容”(如ChatServerA新增“消息类型”字段,ChatServerB未同步,解析失败);
- gRPC解决方案:用Protobuf IDL(接口定义语言)明确服务方法、请求/响应结构,例如项目day27定义的好友申请接口:
// .proto文件(项目隐含,参考day27代码) service ChatService { // 通知好友申请 rpc NotifyAddFriend (AddFriendReq) returns (AddFriendRsp); // 通知消息转发 rpc NotifyTextChatMsg (TextChatMsgReq) returns (TextChatMsgRsp); } // 好友申请请求结构 message AddFriendReq { int32 from_uid = 1; // 发起者UID int32 to_uid = 2; // 接收者UID string remark = 3; // 申请备注 } message AddFriendRsp { int32 error = 1; // 错误码(0=成功) } - 项目场景:所有服务(ChatServer/StatusServer)均基于同一
.proto文件生成代码,字段名、类型、方法名完全统一,避免“字段不匹配”导致的跨服调用失败(day27测试中“两个ChatServer通信正常”即依赖此特性)。
2. 自动生成客户端/服务端代码,降低开发成本
- 问题背景:若手动实现服务间通信(如手动打包Protobuf、处理HTTP/2帧),需编写大量重复代码(如消息发送/接收、错误处理),且易出错;
- gRPC解决方案:通过
protoc编译器+gRPC插件,根据.proto文件自动生成客户端(ChatService::Stub)与服务端(ChatService::Service)代码,项目day27的ChatServiceImpl(服务端实现)、ChatGrpcClient(客户端调用)均基于生成代码开发,无需手动处理通信细节; - 项目场景:开发ChatServer的跨服消息转发功能时,仅需实现
NotifyTextChatMsg的业务逻辑(day27代码中返回Status::OK),通信层代码(如连接建立、消息序列化)全部由gRPC自动生成,开发效率提升60%。
三、解决“高并发场景下的服务间可靠协作”问题
项目分布式部署后,需应对“大量跨服请求”(如峰值时每秒500次好友申请同步、1000次跨服消息转发),gRPC通过“异步调用、连接池、错误重试”保障高并发下的可靠性:
1. 支持异步调用,贴合项目asio异步模型
- 问题背景:项目服务端基于Boost.Asio实现异步IO(day16),若用同步gRPC调用(如ChatServerA同步等待ChatServerB的响应),会阻塞asio的IO线程,导致TCP连接处理延迟;
- gRPC解决方案:提供异步客户端/服务端API,支持非阻塞调用——例如ChatServerA调用
NotifyTextChatMsg时,无需等待响应,可继续处理其他IO事件(如客户端TCP连接),响应返回后通过回调函数处理结果; - 项目场景:day27的
ChatGrpcClient虽暂为同步实现,但可扩展为异步(基于gRPC的CompletionQueue),与asio的io_context结合,避免IO线程阻塞,支撑单服务8000+连接的高并发场景。
2. 连接池复用,避免频繁连接建立/断开
- 问题背景:若每次跨服调用都新建gRPC连接(TCP三次握手+TLS握手),会产生100-200ms延迟,高频调用下延迟累积会导致服务响应缓慢;
- gRPC解决方案:项目day27设计
ChatConPool(gRPC连接池),初始化时创建固定数量(如5个)的gRPCChannel与Stub,存储在队列中,调用时从队列取Stub,用完后归还,避免重复建立连接; - 项目场景:ChatServerA向ChatServerB转发消息时,从
ChatConPool获取Stub(耗时<1ms),而非新建连接(耗时100ms+),跨服调用延迟降低90%。
3. 内置错误处理与重试,提升通信可靠性
- 问题背景:分布式环境中,服务可能临时不可用(如ChatServerB重启),若不处理错误,会导致跨服请求失败(如好友申请同步丢失);
- gRPC解决方案:内置错误码(如
UNAVAILABLE表示服务不可达)、超时控制、自动重试机制,项目可配置“重试策略”(如失败后重试2次,间隔100ms); - 项目场景:StatusServer调用ChatServer的
GetBaseInfo接口时(day27代码),若ChatServer临时不可用,gRPC自动重试2次,避免因短暂故障导致用户登录失败(day17“登录服务验证”依赖此可靠性)。
四、总结:gRPC在项目中的核心价值
gRPC是llfcchat项目从“单服务”迈向“分布式”的关键支撑,其解决的问题直接对应项目架构演进的核心痛点:
- 效率层面:通过HTTP/2多路复用、Protobuf序列化,解决“跨服通信延迟高、带宽占用大”的问题,支撑多ChatServer间的实时消息转发;
- 协作层面:通过Protobuf IDL与自动代码生成,解决“服务间接口混乱、兼容性差”的问题,降低多服务开发与维护成本;
- 可靠性层面:通过异步调用、连接池、错误重试,解决“高并发下跨服请求阻塞、故障易扩散”的问题,保障分布式系统稳定运行。
11.redis缓存的应用场景,如何保证一致性
结合llfcchat项目全周期文档(day09“Redis服务搭建”、day27“分布式服务设计”、day32“分布式锁设计”、day35“心跳逻辑”等),Redis缓存的应用场景完全贴合项目“分布式通信、高并发支撑、临时数据存储”的核心需求,而一致性保障则通过“缓存更新策略、原子操作、失效控制”三大机制落地,具体如下:
一、Redis缓存在项目中的核心应用场景
Redis在项目中并非“通用缓存”,而是精准匹配分布式IM系统的高频需求,每个场景均对应文档中的具体功能模块:
1. 临时认证数据缓存:降低数据库查询压力
- 核心场景:存储短期有效、高频查询的认证数据,避免频繁访问MySQL;
- 项目落地(关联文档):
- 邮箱验证码(day08“邮箱认证服务”):用户注册时,生成的验证码存入Redis(键:
verify:code:{email},值:验证码,过期时间5分钟),客户端提交验证码时直接查Redis,无需查MySQL,减少数据库IO; - 用户登录Token(day17“登录服务验证”):登录成功后生成临时Token,存入Redis(键:
utoken:{uid},值:Token,过期时间2小时),后续请求(如好友查询)通过Token校验身份,避免重复查询MySQL用户表;
- 邮箱验证码(day08“邮箱认证服务”):用户注册时,生成的验证码存入Redis(键:
- 价值:认证类查询QPS从“每秒数百次”降至Redis的“每秒数万次”,响应延迟从10ms(MySQL)降至1ms(Redis)。
2. 分布式状态存储:支撑多服务数据共享
- 核心场景:存储跨服务需共享的“动态状态数据”,解决分布式服务间数据同步问题;
- 项目落地(关联文档):
- 聊天服务器连接数(day27“分布式服务设计”):每个ChatServer将当前连接数写入Redis哈希
LOGIN_COUNT(键:LOGIN_COUNT,field:服务器名,值:连接数),StatusServer查询此哈希选“最小连接数节点”,实现负载均衡; - 用户在线状态(day27/day35):用户登录时,将“UID-服务器名”映射存入Redis(键:
uip:{uid},值:ChatServer名,过期时间=心跳周期×2),跨服消息转发时(如A在Server1、B在Server2),通过此键快速定位用户所在服务器,无需广播查询;
- 聊天服务器连接数(day27“分布式服务设计”):每个ChatServer将当前连接数写入Redis哈希
- 价值:替代“服务间频繁通信”(如多ChatServer互传状态),降低分布式服务耦合度,状态查询效率提升10倍以上。
3. 分布式锁:解决并发资源竞争
- 核心场景:分布式环境下,多服务并发操作同一资源(如用户踢人、好友申请),需通过锁保证操作原子性;
- 项目落地(关联文档day32“分布式锁设计思路”):
- 多服踢人逻辑(day34“多服程踢人逻辑”):当用户在多服务器同时登录时,需强制下线旧连接,通过Redis的
SET NX EX(不存在则设置键,带过期时间)实现分布式锁——踢人服务先抢锁(键:lock:kick:{uid},过期时间3秒),抢到锁后再执行“关闭旧连接+更新状态”操作,避免多服务同时踢人导致的状态混乱; - 好友申请同步(day28“好友查询和申请”):同一用户向同一好友并发发送申请时,通过Redis锁确保“仅创建一条申请记录”,避免MySQL重复插入;
- 多服踢人逻辑(day34“多服程踢人逻辑”):当用户在多服务器同时登录时,需强制下线旧连接,通过Redis的
- 价值:解决分布式环境下的“并发竞态”问题,确保核心操作(踢人、申请)的原子性,避免数据错乱。
4. 高频读取数据缓存:优化IM核心流程
- 核心场景:存储用户高频访问但低频修改的数据,减少MySQL重复查询;
- 项目落地(关联文档):
- 好友列表缓存(day26“联系人列表”):用户登录后,从MySQL查询好友列表,存入Redis(键:
friend:list:{uid},值:好友UID列表,过期时间1小时),后续切换聊天界面时直接查Redis,无需重复查MySQL; - 心跳状态缓存(day35“心跳逻辑”):客户端每30秒发送心跳,ChatServer将“用户心跳时间”存入Redis(键:
heartbeat:{uid},值:时间戳),StatusServer通过此键判断用户是否在线(超过60秒无心跳则标记离线),避免遍历所有ChatServer查询状态;
- 好友列表缓存(day26“联系人列表”):用户登录后,从MySQL查询好友列表,存入Redis(键:
- 价值:将IM核心流程(好友列表加载、在线状态判断)的响应延迟从“毫秒级”降至“微秒级”,支撑单服8000+连接的高并发访问。
二、Redis缓存一致性保障方案(贴合项目场景)
缓存一致性指“Redis缓存数据与MySQL数据库数据保持一致”,避免出现“缓存存旧数据、数据库存新数据”的矛盾。项目通过以下机制落地,完全适配IM系统的“实时性+高并发”需求:
1. 缓存更新策略:优先“Cache-Aside”(读多写少场景)
项目中Redis缓存的核心场景(如用户Token、好友列表、在线状态)均为“读多写少”,采用Cache-Aside策略(先更数据库,再删缓存),避免缓存与数据库数据不一致:
-
读取流程:
- 业务层查询数据时,先查Redis;
- 若Redis有数据(命中),直接返回;
- 若Redis无数据(未命中),查MySQL,将结果写入Redis(设置过期时间),再返回;
- 项目落地:好友列表查询(day26)——首次查MySQL,后续查Redis,未命中时自动同步数据。
-
更新流程:
- 业务层更新数据时,先更新MySQL(如用户修改头像,day36“实现头像编辑框”);
- 再删除Redis中对应的旧缓存(而非直接更新缓存);
- 下次查询时,Redis未命中,自动从MySQL加载新数据并写入缓存;
- 项目落地:用户头像修改(day36)——先更新MySQL的
user表,再删除Redis的user:info:{uid}键,避免Redis存旧头像地址。
-
优势:避免“更新缓存时的并发冲突”(如多线程同时更新同一缓存),且实现简单,适配项目中“低频更新、高频读取”的场景。
2. 缓存失效控制:避免“脏数据”长期留存
即使更新策略正确,仍可能因“缓存未删除、数据库更新失败”导致脏数据,项目通过“过期时间+主动清理”双重控制:
-
设置合理过期时间:
- 所有缓存键均设置过期时间(如验证码5分钟、Token2小时、好友列表1小时),即使缓存未主动删除,过期后也会自动失效,避免脏数据长期留存;
- 项目落地(day08/day17):验证码过期时间5分钟(防止重复使用)、Token过期时间2小时(平衡安全性与用户体验)。
-
主动清理异常缓存:
- 数据库更新失败时(如MySQL事务回滚),通过“try-catch”捕获异常,不删除Redis缓存,避免“数据库未更新、缓存已删除”导致的缓存穿透;
- 分布式场景下(day27),若某服务更新MySQL后崩溃,未删除Redis缓存,可通过“定时任务”(每小时执行)对比MySQL与Redis数据,清理不一致的缓存(如对比用户头像地址,不一致则删缓存)。
3. 分布式环境下的一致性:原子操作+锁保障
项目分布式部署后(多ChatServer、多业务服务),缓存更新易出现“并发冲突”,需通过Redis原子操作与分布式锁保障一致性:
-
原子操作防并发:
- 对“计数器类缓存”(如ChatServer连接数,day27),使用Redis的
HINCRBY(哈希自增)原子操作,避免多线程并发更新导致的计数不准——ChatServer用户登录时,调用RedisMgr::HIncrBy(LOGIN_COUNT, server_name, 1),确保连接数统计无偏差; - 对“状态标记类缓存”(如用户在线状态),使用
SET EX NX原子操作,避免重复设置(如用户同时在两台设备登录,确保uip:{uid}仅存储最新的服务器名)。
- 对“计数器类缓存”(如ChatServer连接数,day27),使用Redis的
-
分布式锁防更新冲突:
- 对“需跨服务同步的更新操作”(如用户踢人,day34),通过Redis分布式锁(day32)确保“更新MySQL与删除缓存”的原子性——踢人服务先抢锁,抢到后执行“关闭旧连接→更新MySQL登录状态→删除Redis的
uip:{uid}键”,避免多服务并发操作导致的状态混乱。
- 对“需跨服务同步的更新操作”(如用户踢人,day34),通过Redis分布式锁(day32)确保“更新MySQL与删除缓存”的原子性——踢人服务先抢锁,抢到后执行“关闭旧连接→更新MySQL登录状态→删除Redis的
4. 缓存异常防护:避免“雪崩/穿透/击穿”影响一致性
缓存异常(如缓存雪崩、穿透)虽不直接破坏一致性,但会导致数据库压力骤增,间接引发数据更新延迟,项目通过以下防护机制规避:
-
缓存雪崩防护(day27分布式场景):
- 不同类型的缓存键设置“随机过期时间”(如好友列表过期时间1±0.2小时),避免大量缓存同时失效,导致所有请求涌向MySQL;
- 核心缓存(如Token)设置“永不过期+主动更新”,仅通过业务操作删除/更新,避免被动失效。
-
缓存穿透防护(day17登录验证):
- 对“不存在的键”(如无效UID的Token查询),在Redis中存储“空值”(键:
utoken:{invalid_uid},值:空字符串,过期时间10分钟),避免恶意请求反复查询MySQL; - 业务层先校验参数合法性(如UID格式),再查缓存,从源头拦截无效请求。
- 对“不存在的键”(如无效UID的Token查询),在Redis中存储“空值”(键:
-
缓存击穿防护(day26好友列表):
- 对“高频访问的热点键”(如高活跃用户的好友列表),使用Redis的
SET NX实现“互斥锁”,仅允许一个线程查MySQL并更新缓存,其他线程等待重试,避免大量请求同时击穿缓存。
- 对“高频访问的热点键”(如高活跃用户的好友列表),使用Redis的
三、总结:Redis缓存的项目价值与一致性核心
- 应用价值:Redis解决了项目分布式架构下的“临时数据存储、跨服务状态共享、并发冲突控制”三大痛点,是支撑“单服8000连接、多服2W活跃用户”的关键组件;
- 一致性核心:未追求“强一致性”(IM系统对实时性容忍度高于绝对一致),而是通过“Cache-Aside更新、过期时间控制、原子操作+分布式锁”实现“最终一致性”,平衡性能与数据准确性,完全适配IM场景需求。
12.大量用户连接时,负载的处理和断连的处理
结合llfcchat项目全周期文档(day16“asio实现tcp服务器”、day27“分布式服务设计”、day33“单服踢人逻辑”、day35“心跳逻辑”等),大量用户连接时的负载处理核心是“分布式分流+单服高效承载”,断连处理则聚焦“精准检测+安全回收+无感重连”,两者均围绕IM系统“高并发、高可用”需求设计,具体方案如下:
一、大量用户连接时的负载处理方案
当单服连接数接近上限(如8000)或多服总连接超2W时,项目通过“分布式分流、单服优化、资源复用”三层机制分散压力,避免单点过载:
1. 分布式负载均衡:将连接分流到多ChatServer(核心手段)
基于day27“分布式服务设计”,通过StatusServer选最小连接节点+GateServer分发,实现连接在多ChatServer间均匀分布,从源头分散负载:
- 节点负载感知:每个ChatServer启动后,每5秒将当前连接数写入Redis的
LOGIN_COUNT哈希(键:LOGIN_COUNT,field:服务器名,值:连接数),StatusServer通过getChatServer()函数(day27代码)遍历该哈希,选择连接数最小的节点; - 连接分发逻辑:用户登录时,GateServer调用StatusServer的
GetChatServer接口,获取负载最小的ChatServer地址(IP+端口),返回给客户端,客户端直接与该ChatServer建立TCP长连接(day01架构设计明确“客户端直连ChatServer”); - 防过载保护:若某ChatServer连接数达阈值(如7000,预留1000缓冲),StatusServer标记其“满负载”,后续不再分配新连接,将请求导向其他节点(day27测试中“两客户端分属不同ChatServer”验证此逻辑)。
2. 单ChatServer高效承载:异步IO+资源复用(性能基础)
单ChatServer通过Boost.Asio异步模型与连接池设计,支撑8000+并发连接,避免“线程爆炸”与资源浪费:
- asio异步IO模型(day16):
采用“1个io_context绑定1个线程”的池化设计(io_context数=CPU核心数,如8核设8个),所有连接的async_read/async_write/心跳回调均由io_context调度,避免传统多线程“1连接1线程”的切换开销,CPU利用率提升50%以上;- 关键优化:将“消息解析、业务逻辑”(如好友申请校验)交给独立业务线程池,io_context线程仅处理IO事件,避免阻塞(day27分布式设计扩展思路)。
- 连接池复用(day09/day27):
- Redis连接池(day09):ChatServer高频查询Redis(如用户在线状态、连接数),通过连接池复用10-20个Redis连接,避免每次查询新建连接(TCP三次握手耗时100ms+);
- gRPC连接池(day27
ChatConPool):跨服消息转发时,复用5个gRPC连接,减少连接建立开销,跨服调用延迟从200ms降至20ms。
- 请求排队与限流(day04扩展):
用无锁队列缓存突发请求(如每秒2000个登录请求),队列长度设为“单服每秒处理能力的2倍”(如1000),超过则返回“服务繁忙”,避免请求直接压垮ChatServer。
3. 动态扩容与资源隔离:应对峰值与故障(高可用保障)
- 动态扩容:当所有ChatServer连接数接近阈值(如7000/8000),运维新增ChatServer节点,启动后自动向StatusServer上报状态(day27),StatusServer将其纳入负载均衡列表,新连接自动分流至新节点,实现“无缝扩容”;
- 资源隔离:
- 核心服务(ChatServer)与非核心服务(如日志服务)部署在不同服务器,避免非核心服务占用CPU/内存;
- 每个ChatServer独立管理自身连接(day17
UserMgr),某节点故障仅影响该节点用户,不扩散至其他节点(day34“多服踢人逻辑”进一步保障账号唯一性)。
二、大量用户连接时的断连处理方案
断连分为“正常断连”(用户主动退出)和“异常断连”(网络波动、客户端崩溃),项目通过“检测-回收-同步-重连”四步处理,确保服务稳定与数据一致:
1. 断连检测:精准识别无效连接(避免“假在线”)
基于day35“心跳逻辑”,客户端与服务端双向检测连接状态,避免无效连接占用资源:
- 客户端心跳检测:
客户端TcpManager(day15)每30秒向ChatServer发送心跳包(MSG_HEARTBEAT),若连续2次未收到服务端心跳响应(60秒),判定断连,触发重连逻辑; - 服务端心跳检测:
ChatServer维护“心跳时间戳表”(键:SessionID,值:最后心跳时间),每10秒遍历一次,若某连接超过60秒无心跳(2倍心跳周期),判定为“异常断连”,触发ClearSession函数(day17)处理; - 主动断连检测:
服务端通过asio::socket::errorOccurred信号(day16)捕获“连接重置、网络不可达”等错误,即时判定断连,无需等待心跳超时(如客户端崩溃导致的TCP RST包)。
2. 断连后资源回收:避免内存泄漏与连接残留
断连后需及时释放连接资源,更新状态,避免资源浪费:
- Session与连接回收(day17/day33):
调用ClearSession函数,执行三步操作:- 从
UserMgr中移除“UID-Session”映射(RmvUserSession),避免后续消息转发到无效Session; - 从ChatServer的
_sessions集合(存储所有连接)中删除该Session,释放内存; - 关闭
QTcpSocket(客户端)或asio::ip::tcp::socket(服务端),释放TCP连接资源;
- 从
- 连接数与状态同步(day27/day35):
- ChatServer更新Redis的
LOGIN_COUNT(连接数减1),确保StatusServer获取最新负载; - 删除Redis中“用户-服务器”映射(
uip:{uid}),避免跨服消息转发到无效节点; - 若用户异常断连,将未发送的离线消息写入MySQL(day31“文件传输”扩展思路),待用户重连后拉取。
- ChatServer更新Redis的
3. 客户端无感重连:提升用户体验(核心优化)
客户端断连后,通过“自动重连+状态恢复”实现用户无感知:
- 重连策略(day15
TcpManager扩展):- 断连后立即发起第1次重连,失败则按“1秒→3秒→5秒”的间隔重试(避免频繁重试占用网络),重试5次后停止,提示用户“手动重连”;
- 重连时携带“用户UID+旧SessionID”,ChatServer验证UID合法性后,分配新Session,恢复用户在线状态;
- 状态恢复:
- 重连成功后,客户端从本地缓存加载未发送的消息(如未发送的聊天文本),重新发送;
- 向ChatServer请求“断连期间的离线消息”(从MySQL拉取),补全聊天记录,确保用户无感知。
4. 特殊场景断连处理:保障业务一致性
- 多端登录断连(踢人)(day33/day34):
用户在A设备登录后,又在B设备登录,ChatServer(A设备所在)收到“踢人指令”,主动调用ClearSession断开A设备连接,同步更新Redisuip:{uid}为B设备所在服务器,避免账号多端在线冲突; - 服务端主动断连:
当ChatServer需重启维护时,先向所有客户端发送“服务维护通知”,等待30秒后再主动断开连接,客户端收到通知后提示用户“即将重连”,减少用户感知。
三、总结:负载与断连处理的核心逻辑
- 负载处理:以“分布式分流”为核心,通过StatusServer选最小连接节点分散连接,单服用asio异步+连接池提升承载能力,动态扩容应对峰值,确保大量连接下服务不崩溃;
- 断连处理:以“精准检测+安全回收”为核心,通过心跳机制识别无效连接,及时释放资源并同步状态,客户端重连恢复体验,特殊场景(踢人、维护)保障业务一致性。
两者均贴合项目“分布式IM”定位,从“预防过载”和“故障恢复”两个维度,支撑2W+活跃用户的稳定通信。
13.客户端请求到达服务端后的通信链路
结合llfcchat项目全周期文档(day01“架构设计”、day14“登录功能”、day16“asio TCP服务器”、day22“气泡对话框”、day27“分布式服务设计”等),客户端请求到达服务端后的通信链路需按请求类型分类(登录请求、实时聊天请求、好友申请请求),不同链路对应项目不同服务模块,核心逻辑围绕“入口分发→业务处理→数据交互→结果返回”展开,具体如下:
一、核心请求类型的通信链路(贴合项目文档场景)
项目中客户端请求主要分三类,每类链路均对应文档中的具体功能实现,包含“服务间交互、数据存储调用”全流程:
1. 登录请求链路:客户端→GateServer→StatusServer→ChatServer(分布式入口)
登录是用户进入系统的首个请求,需通过GateServer分发、StatusServer选节点,最终连接ChatServer,对应day14“登录功能”、day27“分布式服务设计”:
链路步骤(含服务交互与文档关联)
| 步骤 | 通信节点 | 核心操作(关联文档) | 数据交互内容 |
|---|---|---|---|
| 1 | 客户端 → GateServer | 客户端通过HttpManager(day02)发送HTTP POST请求,携带“账号、密码、验证码”; | 请求体(JSON):{"username":"test","password":"hash","verify_code":"123456"} |
| 2 | GateServer → StatusServer | GateServer调用StatusServer的GetChatServer gRPC接口(day27代码),请求“最小负载ChatServer地址”; | 请求:GetChatServerReq(uid: "test");响应:GetChatServerRsp(host: "192.168.1.100", port: 8090) |
| 3 | GateServer → 客户端 | GateServer返回“ChatServer地址+登录校验结果”(若验证码/密码错误,直接返回失败); | 响应体(JSON):{"code":0,"msg":"success","chat_host":"192.168.1.100","chat_port":8090} |
| 4 | 客户端 → ChatServer | 客户端通过TcpManager(day15)与目标ChatServer建立TCP长连接,发送“登录请求”(Protobuf格式); | 请求:LoginReq(uid: "test", token: "GateServer生成的临时token") |
| 5 | ChatServer → Redis/MySQL | ChatServer调用RedisMgr(day09)校验token,调用MysqlConPool(day11)校验账号密码; | Redis查utoken:test,MySQL查user表(select * from user where username=test) |
| 6 | ChatServer → 客户端 | ChatServer返回“登录成功”,携带“用户信息(头像、好友数)”; | 响应:LoginRsp(code:0, user_info: {"avatar":"xxx","friend_count":10}) |
| 7 | ChatServer → Redis | ChatServer更新Redis状态:LOGIN_COUNT(连接数+1)、uip:test(绑定用户与ChatServer); | HINCRBY LOGIN_COUNT chatserver1 1,SET uip:test chatserver1 |
2. 实时聊天请求链路:客户端A→ChatServerA→ChatServerB→客户端B(跨服/单服)
实时聊天是IM核心功能,分“单服聊天”(A、B在同一ChatServer)和“跨服聊天”(A在ChatServerA、B在ChatServerB),对应day16“asio TCP服务器”、day22“气泡对话框”、day27“跨服通信”:
2.1 单服聊天链路(A、B在ChatServerA)
| 步骤 | 通信节点 | 核心操作(关联文档) | 数据交互内容 |
|---|---|---|---|
| 1 | 客户端A → ChatServerA | 客户端A在“气泡对话框”(day22)输入文本,通过TCP长连接发送“聊天请求”(Protobuf); | 请求:TextChatReq(from_uid: "A", to_uid: "B", content: "Hello", time: 1699999999) |
| 2 | ChatServerA → Redis | ChatServerA查Redis的uip:B,确认B在当前服务器(uip:B=chatserver1); | GET uip:B → 结果:chatserver1 |
| 3 | ChatServerA → 客户端B | ChatServerA从UserMgr(day17)获取B的Session,调用async_write(day16)发送消息; | 响应:TextChatRsp(code:0, from_uid: "A", content: "Hello", time: 1699999999) |
| 4 | ChatServerA → MySQL(可选) | 若开启“聊天记录存储”,异步写入MySQLchat_log表(day31扩展思路); | insert into chat_log(from_uid, to_uid, content, time) values("A","B","Hello",1699999999) |
2.2 跨服聊天链路(A在ChatServerA、B在ChatServerB)
| 步骤 | 通信节点 | 核心操作(关联文档) | 数据交互内容 |
|---|---|---|---|
| 1 | 客户端A → ChatServerA | 同单服步骤1,发送“聊天请求”; | 同单服步骤1的请求内容 |
| 2 | ChatServerA → Redis | 查Redis的uip:B,发现B在ChatServerB(uip:B=chatserver2); | GET uip:B → 结果:chatserver2 |
| 3 | ChatServerA → ChatServerB | ChatServerA通过ChatGrpcClient(day27)调用ChatServerB的NotifyTextChatMsg gRPC接口; | 请求:NotifyTextChatMsgReq(from_uid: "A", to_uid: "B", content: "Hello") |
| 4 | ChatServerB → 客户端B | ChatServerB获取B的Session,发送消息给客户端B; | 同单服步骤3的响应内容 |
| 5 | ChatServerB → ChatServerA | ChatServerB返回“消息发送成功”的gRPC响应; | 响应:NotifyTextChatMsgRsp(code:0) |
| 6 | ChatServerA → 客户端A | ChatServerA返回“消息已送达”给客户端A; | 响应:TextChatRsp(code:0, msg: "已送达") |
3. 好友申请请求链路:客户端A→ChatServerA→ChatServerB→客户端B(社交功能)
好友申请涉及“申请发送→通知接收→结果反馈”,对应day25“好友申请界面”、day26“联系人列表”、day27“跨服同步”:
| 步骤 | 通信节点 | 核心操作(关联文档) | 数据交互内容 |
|---|---|---|---|
| 1 | 客户端A → ChatServerA | 客户端A在“好友申请界面”(day25)输入B的UID,发送“好友申请请求”; | 请求:AddFriendReq(from_uid: "A", to_uid: "B", remark: "我是A") |
| 2 | ChatServerA → MySQL | ChatServerA调用MySQL写入“好友申请表”(friend_apply),状态设为“待审核”; | insert into friend_apply(from_uid, to_uid, remark, status) values("A","B","我是A",0) |
| 3 | ChatServerA → Redis | 查Redis的uip:B,确认B所在ChatServer(单服/跨服); | GET uip:B → 结果:chatserver2(跨服)或chatserver1(单服) |
| 4 | 跨服:ChatServerA→ChatServerB | 跨服时,通过gRPC调用ChatServerB的NotifyAddFriend接口,发送申请通知; | 请求:NotifyAddFriendReq(from_uid: "A", to_uid: "B", remark: "我是A") |
| 5 | ChatServer(A/B)→ 客户端B | ChatServerB(跨服)或ChatServerA(单服)推送“好友申请通知”给客户端B; | 响应:AddFriendNotify(from_uid: "A", remark: "我是A", time: 1699999999) |
| 6 | 客户端B → ChatServer(A/B) | 客户端B点击“通过”,发送“申请处理请求”; | 请求:HandleAddFriendReq(from_uid: "A", to_uid: "B", agree: true) |
| 7 | ChatServer(A/B)→ MySQL | 更新“好友申请表”状态为“已通过”,并在“好友关系表”(friend_relation)添加双向记录; | update friend_apply set status=1 where from_uid="A" and to_uid="B"; insert into friend_relation(uid1,uid2) values("A","B"),("B","A") |
| 8 | ChatServer(A/B)→ 客户端A | 推送“申请通过通知”给客户端A,完成好友添加; | 响应:AddFriendResultNotify(from_uid: "B", result: "agree") |
二、链路共性设计:保障高并发与可靠性(关联文档核心机制)
所有请求链路均依赖项目的“基础支撑机制”,确保大量用户连接下链路稳定:
- TCP长连接复用(day15/day16):客户端与ChatServer建立一次TCP长连接,后续所有请求(聊天、好友申请)均复用该连接,避免频繁建立连接的开销;
- Protobuf序列化(day27):除登录初始请求用JSON(HTTP)外,实时请求均用Protobuf(二进制),减少数据体积(比JSON小50%),提升传输效率;
- Redis缓存加速(day09):高频查询(用户所在服务器
uip:uid、连接数LOGIN_COUNT)均走Redis,避免MySQL压力,链路延迟从10ms降至1ms; - gRPC跨服通信(day06/day27):跨ChatServer的请求(如跨服聊天、好友申请)通过gRPC实现,基于HTTP/2多路复用,跨服延迟控制在20ms内;
- 异步IO处理(day16):ChatServer用Boost.Asio异步处理
async_read/async_write,避免IO阻塞,单服可支撑8000+连接的并发请求。
三、异常链路处理:避免请求失败或数据丢失(关联文档容错机制)
当链路中某环节异常(如服务宕机、网络中断),项目通过以下机制保障链路可用性:
- 服务宕机容错(day27/day34):若StatusServer宕机,GateServer使用本地缓存的ChatServer列表(3秒更新一次)分配节点;若ChatServer宕机,客户端触发重连(day15),重新获取新ChatServer地址;
- 请求重试(day27):跨服gRPC调用失败(如ChatServerB临时不可用),ChatServerA自动重试2次(间隔100ms),重试失败则返回“消息发送失败,请稍后重试”;
- 离线消息存储(day31扩展):若接收方客户端离线(如B断连),ChatServer将消息写入MySQL
offline_msg表,待B重连后拉取,避免消息丢失。
14.数据库中用户密码的加密存储
结合llfcchat项目文档(day11“注册功能”的MySQL表设计、day14“登录功能”的密码校验逻辑)及行业安全标准,用户密码的加密存储核心遵循“单向哈希+随机盐值”原则,绝对禁止明文存储,通过“盐值防彩虹表破解、强哈希算法防碰撞”保障密码安全,具体实现完全贴合项目C++技术栈与IM系统的用户认证场景。
一、密码加密存储的核心原则(为何不明文/不用对称加密)
密码存储的核心目标是“即使数据库泄露,攻击者也无法还原出原始密码”,因此必须规避“明文存储”“单纯哈希无盐值”等风险,项目遵循三大原则:
- 单向不可逆:采用哈希算法(而非对称加密),哈希后无法从结果反推原始密码(对称加密可解密,泄露后密码仍危险);
- 随机盐值(Salt):为每个用户生成独立的随机盐值,与密码混合后再哈希——即使两个用户密码相同,最终存储的哈希值也不同,彻底避免“彩虹表”(预计算哈希值的字典)破解;
- 强哈希算法:选用抗碰撞、抗暴力破解的算法(如SHA-256、SHA-512),拒绝MD5、SHA-1等已被破解的弱算法(MD5可被碰撞,SHA-1安全性不足)。
二、项目中密码加密存储的实现流程(关联文档功能)
项目中密码加密贯穿“用户注册”(day11)和“登录校验”(day14)两大环节,流程闭环且安全,具体步骤如下:
1. 注册阶段:生成盐值→混合密码→哈希→存储(核心加密环节)
用户注册时(day11“实现注册功能”),服务端接收客户端传来的明文密码(需通过HTTPS传输,避免传输中泄露),按以下步骤处理后存入MySQL:
步骤1:生成随机盐值(Salt)
- 盐值特性:
- 长度:16-32字节(项目推荐24字节,平衡安全性与存储开销);
- 随机性:通过C++的
std::random_device(硬件随机数)或OpenSSL的RAND_bytes生成,确保每个用户的盐值唯一(即使同一用户重复注册,盐值也不同);
- 代码示例(贴合项目C++技术栈):
#include <random> #include <string> std::string GenerateSalt(size_t length = 24) { const std::string chars = "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz!@#$%^&*()"; std::random_device rd; std::mt19937 gen(rd()); std::uniform_int_distribution<> dis(0, chars.size() - 1); std::string salt; for (size_t i = 0; i < length; ++i) { salt += chars[dis(gen)]; } return salt; }
步骤2:密码与盐值混合→哈希计算
- 混合规则:采用“密码 + 盐值”的拼接模式(如
password_salt = password + ":" + salt),避免简单拼接被暴力破解(可加入项目自定义分隔符,增强独特性); - 哈希算法:项目选用SHA-256(基于OpenSSL库,C++常用且安全),将混合后的字符串计算为32字节(256位)的哈希值,再转为64位十六进制字符串(便于存储);
- 代码示例(依赖OpenSSL,项目day03可能配置过相关库):
#include <openssl/sha.h> #include <iomanip> #include <sstream> std::string HashPasswordWithSalt(const std::string& password, const std::string& salt) { // 混合密码与盐值(项目自定义格式:password:salt) std::string input = password + ":" + salt; // SHA-256哈希计算 unsigned char hash[SHA256_DIGEST_LENGTH]; SHA256_CTX sha256; SHA256_Init(&sha256); SHA256_Update(&sha256, input.c_str(), input.size()); SHA256_Final(hash, &sha256); // 哈希值转为十六进制字符串(64字符) std::stringstream ss; for (int i = 0; i < SHA256_DIGEST_LENGTH; ++i) { ss << std::hex << std::setw(2) << std::setfill('0') << (int)hash[i]; } return ss.str(); }
步骤3:存储哈希值与盐值到MySQL(day11表设计)
- 用户表结构:项目MySQL的
user表(day11“设计MySQL表”)需包含两个核心字段,而非明文密码字段:字段名 类型 长度 作用说明 password_hashVARCHAR 64 存储SHA-256哈希后的十六进制字符串 saltVARCHAR 32 存储24字节盐值(转为字符串存储) - 存储SQL(day11注册功能的核心SQL):
INSERT INTO user (username, password_hash, salt, email, create_time) VALUES (?, ?, ?, ?, NOW()); -- 占位符分别对应:用户名、password_hash、salt、邮箱(避免SQL注入,项目用参数化查询)
2. 登录阶段:获取盐值→重复哈希→对比校验(验证环节)
用户登录时(day14“登录功能验证”),服务端需通过“反向流程”验证密码正确性,不涉及明文密码存储或传输:
步骤1:根据用户名查询盐值与存储的哈希值
- 客户端发送“用户名+登录密码”(HTTPS传输),服务端通过用户名从MySQL
user表查询对应的salt和password_hash(day14“登录校验逻辑”); - 若用户名不存在,直接返回“登录失败”,避免攻击者通过“存在性探测”批量测试用户名。
步骤2:对登录密码重复加密(与注册时规则一致)
- 用查询到的
salt,对客户端传入的登录密码执行“相同的混合+哈希”操作(即login_hash = HashPasswordWithSalt(login_password, salt)); - 关键原则:加密规则必须与注册时完全一致(包括盐值混合顺序、哈希算法、字符串编码),否则哈希值无法匹配。
步骤3:对比哈希值,验证密码正确性
- 对比“登录密码生成的login_hash”与“数据库存储的password_hash”:
- 若一致:密码正确,继续执行后续登录流程(生成Token、分配ChatServer,day14/day27);
- 若不一致:密码错误,返回“账号或密码错误”(不明确提示“密码错误”,避免攻击者锁定目标);
- 安全细节:对比时建议用“恒定时间比较”(避免时序攻击——攻击者通过响应时间差异判断哈希值匹配进度),C++实现示例:
bool SecureHashCompare(const std::string& hash1, const std::string& hash2) { if (hash1.size() != hash2.size()) return false; int diff = 0; for (size_t i = 0; i < hash1.size(); ++i) { diff |= hash1[i] ^ hash2[i]; // 异或比较,所有字符均比较后才返回 } return diff == 0; }
三、项目中的安全增强设计(避免常见风险)
除核心加密流程外,项目还通过以下设计进一步提升密码存储安全性,贴合IM系统的用户数据保护需求:
1. 传输层加密:避免密码在传输中泄露
- 客户端向服务端发送密码(注册/登录)时,必须通过HTTPS协议(而非HTTP)传输——项目day04用Boost.Beast搭建HTTP服务器,后续可扩展为HTTPS(配置SSL证书),加密传输链路中的密码明文;
- 若暂未支持HTTPS,可在客户端对密码进行“临时哈希”(如SHA-256)后传输,但核心仍以服务端“盐值哈希”为准(客户端临时哈希仅防传输泄露,不替代服务端加密)。
2. 盐值与哈希值的安全存储
- 盐值不可泄露:盐值需与哈希值一同存入MySQL,但需确保数据库访问权限严格控制(如仅ChatServer的数据库账号有
user表读写权限,其他服务只读); - 拒绝“全局盐值”:项目绝对禁止使用“所有用户共用一个盐值”(如硬编码在代码中的固定字符串),必须为每个用户生成独立盐值——全局盐值无法抵御彩虹表攻击,安全性与无盐值哈希无本质区别。
3. 密码强度校验(客户端+服务端双重拦截)
- 客户端注册时,先校验密码强度(如长度≥8位、包含大小写字母+数字+特殊符号),避免弱密码(如“123456”“password”);
- 服务端再次校验密码强度,防止客户端绕过前端校验提交弱密码——弱密码即使加密,也可能被暴力破解(如字典攻击)。
4. 日志脱敏:避免密码相关信息泄露
- 项目日志(如day30“面试技巧”提及的排查日志)中,绝对禁止打印“明文密码”“salt”“password_hash”等敏感信息;
- 若需日志记录登录行为,仅打印“用户名+登录结果(成功/失败)+时间”,不涉及任何密码相关数据。
四、常见错误规避(项目需避免的安全陷阱)
- 禁止明文存储:即使为“方便测试”,也不可在数据库中存储明文密码(测试环境可用测试账号的加密密码,而非明文);
- 不使用弱哈希算法:拒绝MD5、SHA-1(MD5已被碰撞,SHA-1在2017年被破解),项目选用SHA-256或更高安全级别的SHA-512;
- 避免盐值过短:盐值长度至少16字节,过短(如4字节)易被暴力破解工具遍历;
- 不将盐值硬编码:盐值必须动态生成并存储,不可写死在代码中(如
const std::string salt = "llfcchat_salt";),否则失去盐值的意义。
15.为什么要用线程池
结合llfcchat项目的高并发场景(如单服8000+TCP连接、每秒数千条聊天消息处理)与技术栈(C++、Boost.Asio),使用线程池的核心目的是解决“线程创建销毁开销大、线程数量失控、资源复用效率低”三大问题,通过“预先创建线程+任务队列缓冲+线程复用”,确保高并发下服务稳定、资源可控,直接支撑IM系统的实时性与可靠性需求。
一、核心原因1:规避“线程创建/销毁”的高昂开销
线程并非“轻量级资源”,每次创建/销毁都需内核参与,高并发下频繁操作会严重消耗CPU与内存,这是llfcchat项目必须用线程池的根本原因之一。
1. 线程本身的资源开销
- 内存开销:每个线程默认需要独立的栈空间(Windows/Linux默认1-8MB),若llfcchat的ChatServer为每个TCP连接创建1个线程(传统“1连接1线程”模型),8000个连接需占用8-64GB内存(仅栈空间),远超普通服务器的内存容量(如16GB);
- 内核开销:创建线程时,内核需分配TCB(线程控制块)、调度队列等数据结构;销毁时需回收这些资源,单次操作耗时约10-100微秒——高并发下(如每秒1000个新连接),仅线程创建/销毁就会占用20%以上的CPU资源,导致业务逻辑(如消息解析、Redis查询)无资源可用。
2. 线程池的解决方案:预先创建+复用
- 预先创建线程:线程池初始化时,根据CPU核心数(如8核创建8-16个线程)预先创建线程,存入“空闲线程队列”,避免运行时动态创建;
- 线程复用:新任务(如处理聊天消息、执行SQL查询)到来时,从空闲队列取1个线程执行任务,任务完成后线程不销毁,放回队列等待下一个任务;
- 项目场景验证:llfcchat的Asio IO线程池(day16)、业务线程池(day27)均采用此逻辑——8个IO线程可支撑8000个连接的异步IO处理,内存占用仅几十MB,CPU开销降低至5%以下。
二、核心原因2:控制线程数量,避免“线程爆炸”与调度过载
若不限制线程数量,高并发下线程会“无限增长”(即“线程爆炸”),导致CPU在“线程上下文切换”中消耗过多资源,反而降低业务处理效率,这对llfcchat的实时消息处理致命。
1. 线程爆炸的危害
- 上下文切换开销:CPU同一时间只能执行1个线程,多线程需频繁切换“寄存器、程序计数器、栈指针”等状态,每次切换耗时约1-10微秒;
- 例:llfcchat若用“1消息1线程”处理,每秒1000条消息会创建1000个线程,CPU上下文切换次数达每秒数万次,90%的CPU时间用于切换,仅10%用于消息解析,导致消息延迟从10ms飙升至100ms;
- 调度优先级混乱:操作系统线程调度采用“时间片轮转”,线程越多,每个线程的时间片越短(如1000个线程时,每个线程每秒仅能获得1ms时间片),核心业务(如心跳检测、跨服消息转发)可能因时间片不足被延迟执行。
2. 线程池的解决方案:固定线程数+任务队列缓冲
- 固定线程数:线程池的线程数量通常设为“CPU核心数”或“CPU核心数+1”(如8核设8个线程),确保CPU调度效率最高(上下文切换最少);
- 任务队列缓冲:突发大量任务(如每秒5000条消息)时,未被立即执行的任务存入“任务队列”(如无锁队列),线程按FIFO顺序处理,避免线程数量随任务数增长;
- 项目场景验证:llfcchat的聊天消息处理(day22)通过“业务线程池+任务队列”实现——即使每秒5000条消息,8个线程也能通过队列缓冲逐步处理,消息延迟稳定在10-20ms,无明显波动。
三、核心原因3:隔离资源,避免“局部阻塞”影响全局
llfcchat项目包含“IO处理、业务逻辑、定时任务”等不同类型的任务,若用同一批线程处理所有任务,某类耗时任务(如大文件传输、复杂SQL查询)会阻塞其他关键任务,线程池通过“多线程池隔离”解决此问题。
1. 无隔离的风险:关键任务被阻塞
- 例:llfcchat中,“文件传输”(day31)需读取大文件(耗时1-10秒),“心跳检测”(day35)需每秒执行一次(耗时1ms);若用同一线程处理,文件传输会占用线程10秒,期间心跳检测任务无法执行,导致大量连接因“无心跳响应”被误判为断连;
- 再例:“跨服gRPC调用”(day27)可能因网络延迟耗时100ms,若与“消息转发”(耗时1ms)共用线程,会导致消息转发被延迟,影响实时性。
2. 线程池的解决方案:按任务类型拆分线程池
llfcchat项目可按“任务性质”拆分3类线程池,实现资源隔离:
| 线程池类型 | 核心任务 | 线程数配置 | 作用(避免阻塞) | 关联项目模块 |
|---|---|---|---|---|
| IO线程池 | Asio异步IO回调(async_read/async_write) | CPU核心数(如8) | 避免业务逻辑阻塞IO处理(如消息接收) | day16(Asio服务器) |
| 业务线程池 | 消息解析、好友申请校验、SQL查询 | CPU核心数×2(如16) | 避免耗时业务(如SQL查询)阻塞IO线程 | day11(注册功能)、day22(聊天消息) |
| 定时任务线程池 | 心跳检测、空闲连接回收、日志切割 | 2-4个 | 避免定时任务被高频业务(如消息处理)抢占 | day35(心跳逻辑)、day09(Redis连接池清理) |
- 隔离效果:文件传输任务阻塞“业务线程池”的1个线程时,IO线程池仍能正常处理消息接收,心跳线程池仍能正常检测连接,全局服务不受局部阻塞影响。
四、核心原因4:简化线程管理,降低开发复杂度
llfcchat项目涉及多模块、多场景的线程操作(如IO、业务、定时),若每个模块手动管理线程(创建、销毁、同步),会导致代码冗余、bug频发(如线程安全问题),线程池通过“统一封装”简化管理。
1. 手动管理线程的痛点
- 代码冗余:每个模块需重复编写“线程创建、任务分配、同步锁”代码,如聊天消息处理、好友申请处理各写一套线程逻辑,代码量增加50%;
- 线程安全风险:手动管理线程时,易出现“竞态条件”(如多线程同时操作
_sessions集合)、“死锁”(如锁顺序错误),排查难度极大; - 资源泄漏风险:若任务执行中抛出异常,未正确回收线程,会导致线程泄漏(如线程一直阻塞在
wait),长期运行后线程数量失控。
2. 线程池的解决方案:统一封装+接口化调用
- 封装核心逻辑:线程池类(如
ThreadPool)封装“线程创建、任务队列、同步锁、线程回收”等核心逻辑,对外提供简单接口(如AddTask添加任务、Stop停止线程池); - 项目调用示例:llfcchat处理聊天消息时,仅需调用
ThreadPool::Inst().AddTask([msg](){ ProcessChatMsg(msg); }),无需关心线程创建与同步,代码简洁且安全; - 自动资源管理:线程池析构时自动停止所有线程,回收资源,避免泄漏;任务执行中抛出异常时,线程池捕获并记录日志,线程仍可复用,不影响全局。
五、总结:线程池在llfcchat项目中的不可替代性
线程池并非“可选优化”,而是llfcchat支撑“高并发、实时性、稳定性”的基础组件,其价值直接对应项目核心需求:
- 性能层面:通过线程复用,降低创建/销毁开销,支撑8000+连接的异步IO处理;
- 资源层面:控制线程数量,避免CPU调度过载,确保消息延迟稳定在10-20ms;
- 稳定性层面:按任务类型隔离线程池,避免局部阻塞影响全局服务;
- 开发层面:简化线程管理,降低多线程bug风险,提升开发效率。
16.客户端和服务端网络通信的过程,包括具体的协议
结合llfcchat项目全周期文档(day02“HttpManager”、day15“TcpManager”、day16“asio TCP服务器”、day22“气泡对话框”、day27“分布式服务”、day35“心跳逻辑”),客户端与服务端的网络通信需按业务场景分类(登录、实时聊天、心跳保活、跨服交互),不同场景对应不同的“传输层协议+应用层协议”,核心逻辑围绕“实时性、可靠性、资源效率”设计,具体过程与协议细节如下:
一、核心通信场景拆解(按业务优先级排序)
llfcchat的通信场景可分为4类,每类场景的协议选择与流程设计均贴合IM系统的核心需求(如登录需安全、聊天需低延迟):
1. 登录认证通信:短连接(HTTP/1.1 + JSON)
登录是用户进入系统的“一次性验证场景”,用HTTP短连接(请求-响应后断开)而非长连接,避免资源浪费;数据格式用JSON(易解析、适合轻量数据),协议细节与流程如下:
(1)通信链路(关联day02/day14/day27)
客户端(QT)→ GateServer(HTTP网关)→ 认证服务 → StatusServer(选ChatServer)→ 客户端
(2)具体协议
| 协议层级 | 细节说明 |
|---|---|
| 传输层 | TCP,默认端口80(HTTP);生产环境建议用HTTPS(443端口),加密传输避免密码泄露 |
| 应用层 | HTTP/1.1,请求方法POST(避免账号密码暴露在URL参数中) |
| 请求头核心字段 | - Host:GateServer的IP+端口(如192.168.1.100:80)- Content-Type:application/json(数据格式为JSON)- Content-Length:请求体字节数(如156) |
| 数据格式(JSON) | ##### 请求体(客户端→GateServer) ```json |
| { | |
| “username”: “llfc_user123”, // 客户端输入的用户名 | |
| “password”: “e8dc4081b13434b45189a720b77b6818”, // 密码先经SHA-256哈希(客户端本地处理,避免明文传输) | |
| “verify_code”: “8765”, // 邮箱验证码(day08邮箱认证服务下发) | |
| “client_type”: “windows_qt” // 客户端类型(适配多端,如windows/android) | |
| } |
##### 响应体(GateServer→客户端)<br>```json
{
"code": 0, // 错误码:0=成功,1=密码错误,2=验证码过期
"msg": "login success", // 提示信息
"data": {
"chat_server_ip": "192.168.1.101", // 目标ChatServer的IP(StatusServer选的最小负载节点,day27)
"chat_server_port": 8090, // 目标ChatServer的TCP端口(长连接端口)
"login_token": "eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9...", // 临时登录Token(day17,用于后续TCP长连接验证)
"token_expire": 7200 // Token有效期(秒),2小时
}
}
```|
### (3)核心处理逻辑
1. 客户端通过`HttpManager`(day02封装的HTTP请求类)构建POST请求,发送到GateServer;
2. GateServer解析JSON请求,调用“认证服务”校验:
- 查Redis验证验证码有效性(day09);
- 查MySQL校验账号密码(密码存储为“盐值+SHA-256哈希”,day11);
3. 认证通过后,GateServer调用StatusServer的`GetChatServer`接口(day27 gRPC),获取“最小连接数的ChatServer地址”;
4. GateServer封装ChatServer地址与Token,以JSON响应返回客户端;
5. 客户端收到响应后,关闭HTTP短连接,准备通过`TcpManager`(day15)与ChatServer建立TCP长连接。
## 2. 实时聊天通信:长连接(TCP + Protobuf)
聊天是IM的核心“持续交互场景”,用**TCP长连接**(建立后保持连接,避免频繁握手开销);数据格式用Protobuf(二进制、体积小、序列化快),同时解决TCP粘包拆包问题,协议细节与流程如下:
### (1)通信链路(关联day15/day16/day22/day27)
#### 单服场景(双方在同一ChatServer)
客户端A → ChatServer(asio TCP服务) → 客户端B
#### 跨服场景(双方在不同ChatServer)
客户端A → ChatServerA → ChatServerB(gRPC跨服转发,day27) → 客户端B
### (2)具体协议(核心是“长度前缀+Protobuf”)
| 协议层级 | 细节说明 |
|----------------|--------------------------------------------------------------------------|
| 传输层 | TCP,端口8090(ChatServer监听端口,day16) |
| 应用层 | 自定义协议:**4字节长度前缀(大端序)+ Protobuf二进制数据**(解决TCP粘包拆包)<br>- 长度前缀:表示后续Protobuf数据的字节数(如Protobuf数据100字节,前缀为`0x00 0x00 0x00 0x64`)<br>- 目的:服务端先读4字节长度,再读对应长度的Protobuf数据,避免粘包(如两条消息连在一起) |
| Protobuf定义(.proto文件,day27) | ##### 聊天消息请求(客户端→ChatServer)<br>```protobuf
syntax = "proto3";
package llfcchat;
// 文本聊天请求
message TextChatReq {
int32 from_uid = 1; // 发送者UID(如10001)
int32 to_uid = 2; // 接收者UID(如10002)
string content = 3; // 聊天内容(如“Hi,在吗?”)
int64 timestamp = 4; // 发送时间戳(毫秒,避免消息乱序)
string msg_id = 5; // 消息唯一ID(UUID,避免重复发送)
}
// 文本聊天响应(ChatServer→客户端)
message TextChatRsp {
int32 code = 1; // 错误码:0=成功,3=接收者离线
string msg = 2; // 提示信息(如“接收者离线,消息已缓存”)
string msg_id = 3; // 对应请求的msg_id(确认消息已被服务端接收)
}
跨服转发请求(ChatServerA→ChatServerB,gRPC)
```protobuf
service CrossChatService {
// 跨服转发聊天消息
rpc ForwardTextChat (TextChatReq) returns (TextChatRsp);
}
### (3)核心处理逻辑(单服场景为例)
1. 客户端A在“气泡对话框”(day22)输入文本后,`TcpManager`执行:
- 将文本、UID等信息封装为`TextChatReq`;
- 用Protobuf将`TextChatReq`序列化为二进制数据;
- 计算二进制数据长度,添加4字节大端序长度前缀;
- 通过TCP长连接发送到ChatServer;
2. ChatServer的asio`async_read`回调(day16)处理:
- 第一步:读4字节长度前缀,解析出Protobuf数据的字节数N;
- 第二步:读N字节Protobuf数据,反序列化为`TextChatReq`;
- 第三步:查Redis的`uip:{to_uid}`(day27),确认接收者B是否在当前ChatServer;
3. 若接收者在线:
- 从`UserMgr`(day17)获取B的`Session`(连接对象);
- 将`TextChatReq`重新序列化,添加长度前缀,通过`async_write`发送给B的客户端;
4. 客户端B收到数据后:
- 拆包(先读长度,再读Protobuf)、反序列化;
- 调用界面更新逻辑,在气泡对话框中展示消息(day22);
5. 跨服场景额外步骤:
- 若接收者B在ChatServerB,ChatServerA通过gRPC调用`ForwardTextChat`,将消息转发到ChatServerB;
- ChatServerB重复步骤3,将消息发送给客户端B。
## 3. 心跳保活通信:长连接(TCP + 自定义轻量协议)
TCP长连接若长期无数据传输,可能被路由器/防火墙断开(“假死连接”),需通过**心跳包**维持连接,协议设计需“轻量”(避免占用带宽),细节如下:
### (1)通信链路(关联day35)
客户端 ↔ ChatServer(双向心跳,客户端主动发,服务端被动响应或主动检测)
### (2)具体协议
| 协议层级 | 细节说明 |
|----------------|--------------------------------------------------------------------------|
| 传输层 | 复用聊天的TCP长连接(端口8090),不新建连接 |
| 应用层 | 自定义轻量协议:**1字节消息类型 + 4字节UID**(共5字节,极致轻量)<br>- 消息类型:`0x01`表示心跳请求,`0x02`表示心跳响应<br>- UID:客户端用户ID(如10001,服务端用于标识连接) |
| 数据格式示例 | ##### 客户端→ChatServer(心跳请求)<br>`0x01 0x00 0x00 0x27 0x11`(1字节类型+4字节UID=10001)<br>##### ChatServer→客户端(心跳响应,可选)<br>`0x02 0x00 0x00 0x27 0x11` |
| 心跳周期 | 客户端每30秒发送1次心跳;服务端每60秒检测1次(若60秒未收到心跳,判定连接断开,触发`ClearSession`,day17) |
### (3)核心处理逻辑
1. 客户端`TcpManager`启动定时器,每30秒发送1次心跳请求(仅5字节,带宽占用可忽略);
2. ChatServer收到心跳请求后:
- 更新该连接的“最后心跳时间戳”(存储在`Session`中);
- 可选:回复心跳响应(确认客户端连接正常);
3. ChatServer启动检测定时器,每60秒遍历所有`Session`:
- 若“当前时间 - 最后心跳时间”>60秒,判定为“假死连接”;
- 调用`ClearSession`(day17):关闭TCP连接、删除`Session`、更新Redis`uip:{uid}`(标记离线);
4. 客户端若60秒未收到心跳响应(或TCP连接断开),触发重连逻辑(day15):按1秒→3秒→5秒间隔重试,重试5次后提示用户。
## 4. 好友申请/响应通信:长连接(TCP + Protobuf)
好友功能(申请、通过、拒绝)属于“低频交互场景”,复用聊天的TCP长连接(避免新建连接),数据格式仍用Protobuf(与聊天协议统一,减少解析逻辑),协议细节如下:
### (1)通信链路(关联day25/day26)
客户端A → ChatServer → 客户端B(申请通知);客户端B → ChatServer → 客户端A(结果通知)
### (2)Protobuf定义(核心消息)
```protobuf
// 好友申请请求
message AddFriendReq {
int32 from_uid = 1; // 发起者UID
int32 to_uid = 2; // 接收者UID
string remark = 3; // 申请备注(如“我是XX”)
int64 req_time = 4; // 申请时间戳
}
// 好友申请响应(接收者→ChatServer)
message AddFriendRsp {
int32 from_uid = 1; // 发起者UID
int32 to_uid = 2; // 接收者UID
bool agree = 3; // 是否同意(true=同意,false=拒绝)
int64 rsp_time = 4; // 响应时间戳
}
// 好友申请通知(ChatServer→接收者)
message AddFriendNotify {
int32 from_uid = 1; // 发起者UID
string from_name = 2; // 发起者用户名(用于界面展示)
string remark = 3; // 申请备注
int64 req_time = 4; // 申请时间戳
}
(3)核心处理逻辑
- 客户端A发送
AddFriendReq(Protobuf+长度前缀)到ChatServer; - ChatServer处理:
- 写MySQL“好友申请表”(
friend_apply,状态=待审核,day26); - 查Redis
uip:{to_uid},确认B是否在线; - 若在线:将
AddFriendNotify发送给B的客户端,B界面弹出申请提示(day25); - 若离线:将通知存入MySQL“离线通知表”,B上线后拉取;
- 写MySQL“好友申请表”(
- 客户端B点击“同意/拒绝”,发送
AddFriendRsp到ChatServer; - ChatServer更新MySQL(同意则添加好友关系,day26),并向A的客户端发送“申请结果通知”,完成好友交互。
二、协议选择的核心设计逻辑(为什么不同场景用不同协议?)
llfcchat的通信协议选择并非随意,而是基于“场景需求+性能成本”的平衡:
- 登录用HTTP短连接:登录是“一次性请求”,短连接用完即关,比长连接更省资源;JSON格式易解析,适合传递账号、验证码等轻量数据;
- 聊天用TCP长连接+Protobuf:聊天需“低延迟、高频交互”,长连接避免TCP三次握手/四次挥手的开销;Protobuf比JSON小50%、序列化快2-5倍,适合实时数据传输;
- 心跳用自定义轻量协议:心跳需“极致省带宽”,5字节的自定义协议比Protobuf(至少10字节)更轻,避免占用聊天带宽;
- 跨服用gRPC:服务间通信需“高效、可靠”,gRPC基于HTTP/2多路复用(单连接处理多请求),Protobuf序列化确保数据一致性,适合跨服消息转发。
17.为什么选择封装tcp(为什么不用udp、为什么不直接用库里的tcp)
结合llfcchat项目day01“架构设计与技术选型”中对IM系统核心需求的定义(实时性、可靠性、长连接支撑、消息有序性),选择“封装TCP”而非UDP或直接使用库原生TCP,本质是为了适配“即时通讯场景的强业务约束”,具体原因如下:
一、为什么不选择UDP?—— 放弃UDP的核心矛盾:IM对“可靠性”的强需求
UDP的“无连接、不可靠、无拥塞控制”特性与IM系统的核心诉求直接冲突,day01文档隐含的“用户消息必达、聊天记录可追溯”需求决定了UDP不适合作为核心通信协议:
1. UDP无法保证消息可靠性,违背IM“消息必达”原则
- 问题表现:UDP不保证消息送达(可能丢包)、不重传(丢包后无法恢复)、不保证顺序(后发消息可能先到)。
- 例:用户发送“晚上8点开会”,若UDP丢包,接收方永远收不到,导致业务错误;若消息乱序(“取消”先到,“晚上8点开会”后到),接收方会误解为“取消开会”。
- IM的硬性要求:day01明确项目需支持“聊天记录存储与回溯”(后续day31文件传输扩展也需可靠性),UDP的不可靠性会导致记录缺失或错乱,完全不符合需求。
2. UDP缺乏拥塞控制,高并发下消息冲突更严重
- UDP没有TCP的慢启动、拥塞避免机制,高并发场景(如群聊500人同时发言)会导致大量数据包在网络中冲突,丢包率骤升(可能达30%以上);
- 而IM的“群聊消息”是高频场景(day22气泡对话框需支持群聊扩展),UDP的无控性会导致消息大面积丢失,用户体验极差。
3. UDP不适合长连接管理,与IM“在线状态绑定”冲突
IM需要维护“用户在线/离线”状态(day27分布式设计核心),依赖长连接的“持续存活”特性:
- UDP是无连接协议,无法像TCP那样通过“连接状态”直接判断用户在线(需额外设计复杂的保活机制,反而比TCP更复杂);
- 项目day35“心跳逻辑”依赖TCP连接的“断开检测”(如
async_read失败触发断连),UDP需手动实现类似逻辑,开发成本更高。
二、为什么不直接使用库的原生TCP?—— 原生TCP缺乏IM场景的“业务适配层”
项目若直接使用Boost.Asio(day16技术选型)或Qt的原生TCP接口(如QTcpSocket),会面临“底层接口与上层业务脱节”的问题,day01强调的“模块化、可扩展”架构目标无法实现:
1. 原生TCP未解决“粘包拆包”问题,消息解析混乱
TCP是“字节流协议”,发送的多个消息可能被合并为一个字节流(粘包),或一个消息被拆分(拆包),原生接口仅提供字节读写,不处理消息边界:
- 例:客户端连续发送两条消息“Hello”和“World”,TCP可能将其合并为“HelloWorld”,原生接口无法区分这是一条还是两条消息;
- IM需明确区分“每条聊天消息”(day22气泡对话框需按消息逐条展示),必须通过“协议头(如长度前缀)”解决粘包拆包,这需要在原生TCP之上封装一层“消息帧解析逻辑”。
2. 原生TCP缺乏“IM业务层抽象”,代码复用性差
原生TCP接口(如async_read/async_write)仅负责底层IO,而IM需要的“连接管理、消息路由、状态同步”等逻辑需手动实现,直接使用会导致:
- 连接管理混乱:每个TCP连接对应一个用户Session(day17
UserMgr),需维护“UID-连接”映射、在线状态、心跳时间,原生接口无此抽象,需大量冗余代码; - 消息序列化适配:IM消息需用Protobuf(day27技术选型)序列化,原生TCP仅传输字节流,需封装“序列化→发送”“接收→反序列化”的统一逻辑,避免每个模块重复开发;
- 错误处理不一致:TCP连接断开(如
error_code=connection_reset)时,需触发“清理Session、更新在线状态、通知好友”等连锁操作,原生接口仅返回错误码,无统一错误处理机制,易导致状态不一致。
3. 原生TCP难以支撑“分布式扩展”,与项目架构冲突
day01明确项目后期需“分布式部署”(多ChatServer节点),原生TCP接口是单机级别的,无法适配分布式场景:
- 例:跨服消息转发(day27)需知道“目标用户在哪个ChatServer”,这需要在TCP连接封装中集成“Redis查询
uip:uid”的逻辑,原生TCP无此扩展点; - 分布式锁(day32)、连接负载均衡(day27)等机制需与TCP连接状态联动,原生接口的“纯IO”特性无法承载这些业务逻辑,必须通过封装层衔接。
三、封装TCP的核心价值:构建“IM场景适配层”
项目封装TCP(如day15TcpManager、day16asio TCP服务器)的本质,是在原生TCP之上增加“业务适配层”,解决上述问题:
| 封装层核心能力 | 具体实现(关联项目模块) | 解决的痛点 |
|---|---|---|
| 消息帧标准化 | 统一用“4字节长度前缀+Protobuf”(day16),自动处理粘包拆包 | 原生TCP字节流无消息边界的问题 |
| 连接生命周期管理 | 封装Session对象(day17),关联UID、心跳时间、连接状态,提供Init/Close/Clear接口 | 原生TCP无“用户-连接”映射的问题 |
| 业务逻辑集成 | 消息接收后自动反序列化,触发对应业务回调(如OnTextChat/OnAddFriend,day22/day25) | 原生TCP与业务逻辑脱节的问题 |
| 分布式适配 | 连接建立时同步uip:uid到Redis(day27),断开时自动更新,支撑跨服路由 | 原生TCP无法适配分布式部署的问题 |
| 统一错误处理 | 连接断开时自动触发“清理Session+通知好友+更新Redis”(day17/day35) | 原生TCP错误处理分散、易导致状态不一致的问题 |
总结:封装TCP是IM场景的“必然选择”
llfcchat作为IM系统,既需要TCP的“可靠性、有序性、长连接支撑”(排除UDP),又需要在TCP基础上叠加“消息解析、连接管理、业务集成”等IM特有的能力(排除直接使用原生TCP)。封装TCP本质是“用底层协议的可靠性满足IM基础需求,用上层封装的业务适配性满足场景特性”,完全贴合day01架构设计中“高性能、可扩展、易维护”的目标。
18.客户端和服务端只有一个单tcp连接吗,没有其他吗
结合llfcchat项目的业务场景(登录、实时聊天、文件传输)与文档设计(day02“HttpManager”、day15“TcpManager”、day16“asio TCP服务器”、day31“文件传输”),客户端与服务端并非只有一个单TCP连接,而是“按需创建不同用途的TCP连接”——核心实时交互用1个长TCP连接复用,一次性场景(如登录、大文件传输)用临时TCP短连接,两者配合既满足业务需求,又兼顾资源效率。
一、核心结论:两类TCP连接并存,用途不同
llfcchat的客户端与服务端之间,存在“1个核心长连接 + N个临时短连接”的关系,具体分工如下:
| 连接类型 | 数量 | 生命周期 | 核心用途 | 关联项目模块 |
|---|---|---|---|---|
| 核心长TCP连接 | 1个(固定) | 从用户登录成功到主动退出 | 实时聊天、心跳保活、好友申请/响应 | day15“TcpManager”、day16“asio服务器”、day22“气泡对话框” |
| 临时短TCP连接 | N个(按需) | 任务完成后立即断开 | 登录认证、大文件传输 | day02“HttpManager”、day31“文件传输” |
二、两类连接的具体场景与设计逻辑
不同连接的存在,本质是为了适配“不同业务对连接的需求差异”——长连接适合“持续交互、低延迟”,短连接适合“一次性、高资源消耗”的场景。
1. 核心长TCP连接:1个,贯穿用户在线全周期
这是客户端与服务端最核心的连接,从用户登录成功后建立,直到用户主动退出或断连重连,所有高频实时交互都复用此连接,设计逻辑完全贴合IM“低延迟、少资源”的需求。
(1)连接建立时机与流程
- 触发时机:用户通过HTTP登录(临时短连接)获取ChatServer地址后(day27“负载均衡”),客户端调用
TcpManager::connectToServer(day15),与目标ChatServer建立TCP长连接; - 核心作用:复用此连接传输所有“实时性要求高”的业务数据,避免频繁建立连接的开销(TCP三次握手/四次挥手耗时100-200ms,频繁操作会导致消息延迟)。
(2)复用的业务场景(全靠这1个连接)
所有高频、实时的交互都通过此连接传输,且通过“应用层协议区分消息类型”(无需新建连接):
- 实时聊天:文本消息、表情消息的发送/接收(day22“气泡对话框”),通过Protobuf+长度前缀区分每条消息;
- 心跳保活:每30秒发送1次心跳包(day35“心跳逻辑”),维持连接存活,避免被路由器/防火墙断开;
- 好友交互:好友申请、同意/拒绝、好友状态同步(day25“好友申请界面”、day26“联系人列表”);
- 离线消息拉取:用户重连后,通过此连接向ChatServer请求“断连期间的离线消息”(day31扩展逻辑)。
(3)设计优势
- 低延迟:连接长期存在,消息无需等待TCP握手,直接发送,延迟控制在10-20ms;
- 省资源:1个连接承载所有实时业务,避免多连接占用客户端/服务端的端口、句柄资源(如10个连接需10倍端口,而1个连接仅需1个)。
2. 临时短TCP连接:N个,用完即断
这类连接是“按需创建”的,仅用于“一次性、非实时”或“高资源消耗”的业务,任务完成后立即断开,避免长期占用资源。
(1)场景1:登录认证(HTTP基于TCP短连接)
- 连接用途:用户输入账号密码后,客户端通过
HttpManager(day02)向GateServer发送登录请求,HTTP协议本质是“基于TCP的短连接”; - 生命周期:
- 客户端与GateServer建立TCP连接(短连接);
- 发送HTTP POST登录请求(day14“登录功能”);
- 接收GateServer返回的“ChatServer地址+Token”;
- 立即断开此TCP连接(HTTP/1.1默认“Connection: close”,用完即断);
- 为什么不用核心长连接:登录是“一次性操作”,若用长连接,登录后需一直维持,浪费资源;且登录时还未确定目标ChatServer(需GateServer分配),无法直接连接最终的ChatServer。
(2)场景2:大文件传输(可选,day31扩展)
- 连接用途:当用户发送大文件(如100MB视频、50MB压缩包)时,若复用核心长连接,会导致:
- 大文件传输占用带宽,挤压聊天消息(如文本消息被阻塞,延迟飙升);
- 大文件传输耗时久(如10秒),期间核心连接被占用,心跳包无法发送,可能被误判为断连;
- 解决方案:新建临时TCP短连接专门用于文件传输:
- 客户端与ChatServer建立1个临时TCP连接(端口与核心连接不同,如8091);
- 通过此连接分块传输文件(如每块10KB,带块编号,确保顺序);
- 文件传输完成后,立即断开此临时连接;
- 为什么用临时连接:隔离大文件传输与核心聊天业务,避免互相影响,保证聊天消息的实时性。
(3)其他临时场景(如日志上报、版本更新)
- 客户端若需上报本地日志(day30“面试技巧”提及日志排查)、检查版本更新,也会建立临时TCP短连接,任务完成后断开,不占用核心连接资源。
三、关键疑问:为什么核心业务只复用1个长连接,不建多个?
很多人会疑惑“为什么不建多个长连接,比如1个聊天空连接、1个好友连接”,核心原因是“IM场景不需要,且多连接会浪费资源”:
- 业务可通过应用层区分:核心业务(聊天、心跳、好友)的消息,可通过“应用层协议头”区分类型(如聊天消息类型=0x01,心跳=0x02,好友申请=0x03),无需通过“不同连接”区分;
- 多连接会增加资源开销:
- 客户端:每个TCP连接需占用1个本地端口,多连接会消耗更多端口资源(Windows默认端口范围有限,day03“系统优化”提到
MaxUserPort=65534); - 服务端:每个连接需1个文件句柄(Linux)或句柄(Windows),多连接会增加服务端的资源占用,降低单服承载上限(day16“asio服务器”单服支撑8000连接,多连接会让此上限降低);
- 客户端:每个TCP连接需占用1个本地端口,多连接会消耗更多端口资源(Windows默认端口范围有限,day03“系统优化”提到
- 多连接会增加维护成本:需管理多个连接的“断连重连、心跳检测”,代码复杂度翻倍(如1个连接的重连逻辑已需day15的
TcpManager,多连接会让逻辑更复杂)。
四、特殊情况:断连重连后的连接变化
当核心长连接因网络波动断开时(如WiFi切换、信号弱),客户端会触发重连逻辑(day15“TcpManager”):
- 客户端尝试重新连接“原ChatServer”(通过Redis缓存的
uip:uid获取地址,day27); - 若重连成功,新建1个TCP连接替代原连接,但仍保持“1个核心连接”的原则;
- 若原ChatServer宕机,客户端会通过GateServer重新获取“新ChatServer地址”,建立新的核心长连接,原连接已失效,无需处理。
总结:连接设计的核心逻辑——“按需分配,复用优先”
llfcchat的TCP连接设计并非“单一固定”,而是围绕“业务需求”灵活调整:
- 对“实时、高频、持续”的核心业务(聊天、心跳),用1个长连接复用,平衡延迟与资源;
- 对“一次性、低频次、高消耗”的业务(登录、大文件传输),用临时短连接,用完即断,避免资源浪费;
- 最终实现“业务需求满足+资源效率最优”,完全贴合day01文档“高性能、可扩展”的架构目标。
19.如果要进行文件传输,应该怎么做
结合llfcchat项目的技术栈(TCP、Protobuf、Boost.Asio、Redis)与现有架构(核心长连接+临时短连接、分布式ChatServer),文件传输需围绕“不阻塞核心聊天、保证可靠性、适配分布式场景”三大目标设计,核心思路是“独立临时TCP连接传输+分块校验+进度同步”,具体实现步骤如下:
一、架构选择:用“独立临时TCP连接”传输文件(不占用核心聊天空连接)
文件传输(尤其是大文件,如10MB+)若复用“核心长连接”(聊天/心跳用),会占用带宽导致聊天消息延迟、心跳包阻塞,因此需新建独立的临时TCP短连接专门用于文件传输,传输完成后立即断开,与核心连接完全隔离。
| 连接类型 | 用途 | 生命周期 | 端口选择 | 关联项目模块 |
|---|---|---|---|---|
| 核心长连接 | 聊天、心跳、好友交互 | 用户在线全周期 | 8090(ChatServer默认) | day15TcpManager、day16asio服务器 |
| 文件传输临时连接 | 单独传输文件 | 从传输开始到完成/中断 | 8091(独立端口,避免与核心连接冲突) | 扩展TcpManager、新增FileTransferSession |
二、文件传输全流程(分“发起-传输-校验-完成”四步)
以“客户端A向客户端B发送文件”为例,流程需覆盖“元信息协商、分块传输、异常重试、进度同步”,完全适配项目分布式架构(若A/B在不同ChatServer,需跨服转发元信息)。
1. 第一步:文件元信息协商(核心长连接传递,不占传输带宽)
文件传输前,先通过核心长连接交换“文件元信息”(体积小,仅几百字节),确认双方传输能力,避免直接传大文件导致的资源浪费。
(1)客户端A发起文件传输请求
- 客户端A选择文件后,封装“文件元信息”,通过核心长连接发送给ChatServerA(A所在的ChatServer),用Protobuf定义元信息格式:
// 文件传输请求(客户端→ChatServer) message FileTransferReq { int32 from_uid = 1; // 发送者UID int32 to_uid = 2; // 接收者UID string file_name = 3; // 文件名(如“文档.pdf”) int64 file_size = 4; // 文件总大小(字节,如10485760=10MB) string file_md5 = 4; // 文件MD5(用于最终校验完整性) int32 block_size = 5; // 分块大小(字节,如4096=4KB,项目推荐4-8KB) string transfer_id = 6; // 传输唯一ID(UUID,避免重复传输) } - 核心逻辑:客户端A通过本地计算获取文件MD5(如用OpenSSL的
EVP_MD5),确保后续校验文件完整性。
(2)ChatServer转发元信息,客户端B确认接收
-
单服场景(A/B在同一ChatServerA):
ChatServerA查Redis的uip:{to_uid}(day27),确认B在线后,通过B的核心长连接推送“文件接收通知”:// 文件接收通知(ChatServer→客户端B) message FileTransferNotify { int32 from_uid = 1; // 发送者UID string from_name = 2; // 发送者用户名(用于界面展示) string file_name = 3; // 文件名 int64 file_size = 4; // 文件大小 int32 block_size = 5; // 分块大小 string transfer_id = 6; // 传输唯一ID string file_server_ip = 7; // 文件传输临时连接的IP(即ChatServerA的IP) int32 file_server_port = 8; // 文件传输临时连接的端口(8091) }客户端B弹出“接收文件”弹窗,用户点击“确认”后,通过核心长连接向ChatServerA返回“接收同意”:
// 文件接收确认(客户端B→ChatServerA) message FileTransferAck { string transfer_id = 1; // 传输唯一ID(对应通知中的ID) bool agree = 2; // 是否同意接收(true=同意) string save_path = 3; // 客户端B的文件保存路径(仅本地使用,不传输) } -
跨服场景(A在ChatServerA,B在ChatServerB):
ChatServerA通过gRPC(day27)将FileTransferReq转发给ChatServerB,ChatServerB再推送给客户端B,后续确认流程与单服一致,仅file_server_ip/port改为ChatServerA的地址(文件仍从A所在服务器传输,避免跨服传大文件占用带宽)。
(3)ChatServer通知客户端A开始传输
ChatServerA收到B的“接收同意”后,通过A的核心长连接发送“传输准备就绪”通知,包含“文件传输临时连接的IP+端口”(即ChatServerA的8091端口):
// 传输准备就绪通知(ChatServerA→客户端A)
message FileTransferReady {
string transfer_id = 1; // 传输唯一ID
string file_server_ip = 2; // 临时连接IP(ChatServerA)
int32 file_server_port = 3; // 临时连接端口(8091)
int64 start_block_idx = 4; // 起始分块编号(0=从头开始,断点续传时为已传最后一块+1)
}
2. 第二步:建立临时TCP连接,分块传输文件
客户端A收到“就绪通知”后,新建临时TCP连接(8091端口)连接ChatServerA,开始分块传输文件,核心是“按块传输+每块确认”,避免丢包导致文件损坏。
(1)分块规则设计
- 按“固定块大小”拆分文件:如块大小=4KB(4096字节),10MB文件拆分为2560块(10485760 ÷ 4096 = 2560),最后一块不足4KB则按实际大小传输;
- 每块编号从0开始(
block_idx=0,1,2...n-1),确保ChatServer/A能按顺序重组文件。
(2)分块传输协议(临时TCP连接,Protobuf+长度前缀)
临时连接的传输协议沿用项目统一的“4字节长度前缀+Protobuf”(day16),定义分块传输消息:
// 文件分块传输请求(客户端A→ChatServerA)
message FileBlockReq {
string transfer_id = 1; // 传输唯一ID(关联全局传输)
int32 block_idx = 2; // 分块编号(0开始)
int32 block_size = 3; // 本块实际大小(字节,最后一块可能小于block_size)
bytes block_data = 4; // 分块二进制数据(如4KB字节流)
string block_md5 = 5; // 本块MD5(可选,用于块级校验,防止单块损坏)
}
// 文件分块确认(ChatServerA→客户端A)
message FileBlockAck {
string transfer_id = 1; // 传输唯一ID
int32 block_idx = 2; // 已接收的分块编号
bool success = 3; // 接收是否成功(true=成功)
int32 next_expected_idx = 4; // 下一个期望接收的分块编号(用于顺序校验)
}
(3)分块传输流程
- 客户端A打开本地文件,按块读取数据(从
start_block_idx开始,支持断点续传); - 每读取一块,封装为
FileBlockReq,通过临时TCP连接发送给ChatServerA; - ChatServerA接收分块后,验证“分块编号是否连续”(如当前应接收10,实际收到11则拒绝),可选验证
block_md5; - 验证通过后,ChatServerA将分块暂存到本地缓存(如
/tmp/file_transfer/{transfer_id}/目录),并返回FileBlockAck(success=true); - 客户端A收到确认后,继续发送下一块;若未收到确认(超时3秒),重试发送当前块(最多重试3次,仍失败则中断传输);
- 跨服同步:ChatServerA每接收10块(可配置),通过gRPC将分块同步给ChatServerB,ChatServerB暂存本地缓存(避免最终一次性传大文件)。
3. 第三步:文件重组与完整性校验
所有分块传输完成后,ChatServerB(B所在服务器)重组文件并校验完整性,确保文件与原文件一致。
(1)文件重组
- 当ChatServerB接收完所有分块(通过“总块数=文件大小÷块大小”判断),按分块编号顺序读取缓存的分块文件,合并为完整文件;
- 合并后,计算完整文件的MD5,与客户端A传输的
file_md5对比。
(2)完整性校验结果通知
- 校验成功:ChatServerB通过B的核心长连接发送“文件接收完成”通知,包含“文件保存路径(服务器端临时路径)”;
- 校验失败:ChatServerB返回“校验失败”,通知客户端A重新传输(可选从缺失的分块开始,即断点续传)。
4. 第四步:客户端B下载文件,临时连接断开
客户端B收到“接收完成”通知后,通过新的临时TCP连接(仍用8091端口)连接ChatServerB,下载完整文件到本地指定路径(save_path):
- 客户端B发送“文件下载请求”(含
transfer_id); - ChatServerB读取本地重组后的文件,分块发送给客户端B(流程与A传输给ChatServerA一致);
- 客户端B接收完成后,验证本地文件MD5与
file_md5一致,弹出“文件接收成功”提示; - 双方临时TCP连接断开,ChatServer删除本地缓存的分块文件(节省磁盘空间)。
三、关键技术点:保障传输可靠性与用户体验
1. 断点续传(避免重复传输)
- 进度存储:ChatServerA/B通过Redis记录传输进度(键:
file_transfer:{transfer_id}:progress,值:{"last_block_idx":100, "total_blocks":2560}),每接收1块更新一次; - 断点恢复:若传输中断(如网络断开),客户端A重连后,通过核心长连接请求“当前传输进度”,ChatServer返回
last_block_idx,客户端A从该块开始继续传输,无需从头开始。
2. 传输进度同步(提升用户体验)
- 客户端A/B通过核心长连接实时获取传输进度:
- ChatServer每接收/发送10%的分块,推送“进度更新”通知(如“已传输30%,剩余7MB”);
- 客户端界面显示进度条(如QT的
QProgressBar),让用户直观看到传输状态。
3. 资源限制(避免服务器过载)
- 单用户并发限制:每个客户端最多同时发起2个文件传输(通过ChatServer控制,避免单用户占用过多带宽);
- 分块大小适配:根据网络状况动态调整块大小(如弱网环境将块大小从8KB改为2KB,减少重试开销);
- 缓存清理:传输完成/中断后,ChatServer自动清理临时缓存(如24小时未完成的传输,自动删除缓存)。
四、关联项目现有模块的扩展设计
文件传输无需从零开发,可基于项目已有模块扩展,减少代码冗余:
TcpManager扩展(day15):新增createFileTransferConn接口,管理临时TCP连接的创建、断开、重连;Session扩展(day17):新增FileTransferSession类,管理单个文件传输的状态(进度、分块缓存、MD5);- Redis缓存扩展(day09):新增
file_transfer相关键,存储传输进度、临时文件路径; - gRPC接口扩展(day27):新增
ForwardFileBlock接口,支持跨服分块同步。
20.redis缓存怎么用的,为什么不直接用MySQL
结合llfcchat项目全周期文档(day09“Redis服务搭建”、day17“登录服务验证”、day27“分布式服务设计”、day32“分布式锁”),Redis缓存的使用完全围绕**“高频临时数据缓存、分布式状态共享、高并发锁控制”** 三大核心场景,与MySQL形成“互补而非替代”的关系。不直接用MySQL,本质是两者在“读写性能、数据结构、适用场景”上的差异,无法满足IM系统“实时性、高并发”的核心需求。
一、Redis缓存在项目中的具体用法(贴合业务场景)
Redis在项目中并非“通用缓存”,而是精准匹配IM系统的高频需求,每个用法都对应具体业务模块,且通过“键设计+过期时间+数据结构”优化性能:
1. 场景1:临时认证数据缓存(减少MySQL查询压力)
针对“短期有效、高频校验”的认证类数据,用Redis缓存避免频繁访问MySQL,对应项目day08“邮箱认证”、day17“登录Token”:
- 具体用法:
- 邮箱验证码(day08):用户注册时,生成6位验证码,以
verify:code:{email}为键(如verify:code:test@163.com),验证码为值,设置5分钟过期时间(避免重复使用);客户端提交验证码时,直接查Redis,无需查MySQL。 - 登录Token(day17):用户登录成功后,生成临时Token,以
utoken:{uid}为键(如utoken:10001),Token为值,设置2小时过期时间(平衡安全性与体验);后续请求(如好友列表查询)通过Token校验身份,无需重复查MySQL用户表。
- 邮箱验证码(day08):用户注册时,生成6位验证码,以
- 数据结构:String(简单键值对,查询效率O(1))。
- 核心价值:认证类查询QPS从“每秒数百次”(MySQL)降至“每秒数万次”(Redis),响应延迟从10ms→1ms。
2. 场景2:分布式状态存储(支撑多服务数据同步)
分布式架构下,多ChatServer/StatusServer需共享“动态状态数据”,Redis作为“全局状态中心”,解决服务间数据不一致问题,对应day27“负载均衡”、day35“心跳检测”:
- 具体用法:
- ChatServer连接数(day27):每个ChatServer将当前TCP连接数存入Redis哈希
LOGIN_COUNT,键为LOGIN_COUNT,field为服务器名(如chatserver1),值为连接数(如3500);StatusServer查询此哈希选“最小连接数节点”,实现负载均衡。 - 用户在线状态(day27/day35):用户登录时,将“UID-服务器名”映射存入Redis,键为
uip:{uid}(如uip:10001),值为ChatServer名(如chatserver2),过期时间设为60秒(2倍心跳周期);跨服消息转发时,通过此键快速定位用户所在服务器,无需广播查询。
- ChatServer连接数(day27):每个ChatServer将当前TCP连接数存入Redis哈希
- 数据结构:Hash(适合存储“键-字段-值”的多维度数据,查询单个field效率O(1))。
- 核心价值:替代“服务间频繁通信”(如多ChatServer互传状态),降低分布式耦合度,状态查询效率提升10倍以上。
3. 场景3:分布式锁(解决并发资源竞争)
多服务并发操作同一资源(如用户踢人、好友申请)时,Redis的原子操作实现分布式锁,确保操作原子性,对应day32“分布式锁设计”、day34“多服踢人逻辑”:
- 具体用法:
- 多服踢人(day34):用户在A设备登录后,又在B设备登录,需强制下线A设备。踢人服务先通过Redis的
SET NX EX命令抢锁(键:lock:kick:{uid},如lock:kick:10001,值为随机字符串,过期时间3秒);抢到锁后,再执行“关闭A设备连接+更新状态”,避免多服务同时踢人导致状态混乱。 - 好友申请防重复(day28):同一用户向同一好友并发发送申请时,通过Redis锁确保“仅创建一条MySQL申请记录”,避免重复插入。
- 多服踢人(day34):用户在A设备登录后,又在B设备登录,需强制下线A设备。踢人服务先通过Redis的
- 核心命令:
SET lock_key random_value NX EX 3(NX=不存在则设置,EX=3秒过期,确保锁自动释放)。 - 核心价值:解决分布式环境下的“竞态条件”,避免MySQL数据错乱(如重复好友申请、多端在线冲突)。
4. 场景4:高频读取数据缓存(优化IM核心流程)
针对“用户高频访问、低频修改”的数据,用Redis缓存减少MySQL重复查询,对应day26“联系人列表”、day35“心跳状态”:
- 具体用法:
- 好友列表缓存(day26):用户登录后,从MySQL查询好友列表,存入Redis,键为
friend:list:{uid}(如friend:list:10001),值为好友UID列表(用JSON序列化),设置1小时过期时间;后续切换聊天界面时直接查Redis,无需重复查MySQL。 - 心跳时间戳(day35):客户端每30秒发送心跳,ChatServer将“用户最后心跳时间”存入Redis,键为
heartbeat:{uid},值为时间戳;StatusServer通过此键判断用户是否在线(超过60秒无心跳则标记离线),避免遍历所有ChatServer查询。
- 好友列表缓存(day26):用户登录后,从MySQL查询好友列表,存入Redis,键为
- 数据结构:String(存储JSON字符串或时间戳)。
- 核心价值:将IM核心流程(好友列表加载、在线状态判断)的响应延迟从“毫秒级”降至“微秒级”,支撑单服8000+连接的高并发。
二、为什么不直接用MySQL?—— 两者核心差异决定场景适配性
MySQL作为关系型数据库,核心优势是“持久化、事务支持、复杂查询”,但在IM系统的“高频临时数据、分布式状态、高并发”场景中,性能和灵活性远不如Redis,直接使用会导致系统瓶颈:
1. 读写性能:Redis内存操作 vs MySQL磁盘操作,差距100-1000倍
- Redis:数据存储在内存中,读写操作均为内存级IO,单线程模型避免锁竞争,QPS可达10万+,响应延迟微秒级(1-10μs);
- MySQL:数据存储在磁盘中,读写需磁盘IO(即使有缓存,也需处理页表、事务日志),QPS通常仅1万左右,响应延迟毫秒级(10-100ms);
- 项目场景矛盾:IM的“在线状态查询”(每秒数千次)、“心跳时间戳更新”(每秒8000次),若用MySQL,磁盘IO会迅速成为瓶颈,导致查询延迟飙升,甚至拖垮MySQL服务。
2. 数据结构:Redis支持灵活结构 vs MySQL仅关系表,无法适配分布式状态
- Redis:原生支持Hash、List、Set、Sorted Set等结构,可直接存储“键-字段-值”(如
LOGIN_COUNT哈希)、“列表”(如好友列表),无需额外表设计; - MySQL:仅支持关系表结构,存储“用户-服务器”映射需创建
user_server表(字段:uid、server_name、expire_time),存储连接数需创建server_conn表(字段:server_name、conn_count); - 项目场景矛盾:分布式状态(如连接数)需“实时更新单个字段”(如
conn_count+1),Redis用HINCRBY原子操作1步完成,MySQL需执行UPDATE server_conn SET conn_count=conn_count+1 WHERE server_name='chatserver1',还需处理事务和锁,效率低且易冲突。
3. 临时数据处理:Redis自动过期 vs MySQL手动清理,维护成本高
- Redis:支持键过期时间(如验证码5分钟、Token2小时),过期后自动删除,无需人工维护;
- MySQL:无自动过期机制,临时数据需手动处理(如写定时任务删除过期验证码、Token),代码复杂度高,且定时任务执行时可能锁表,影响业务;
- 项目场景矛盾:IM的“临时验证码”“短期Token”若存在MySQL,每天需执行多次定时任务清理,不仅增加开发成本,还可能因任务延迟导致“过期数据残留”(如验证码过期后仍能使用)。
4. 分布式能力:Redis天然支持分布式 vs MySQL需额外扩展
- Redis:可通过主从复制、哨兵模式实现高可用,且支持跨服务访问(所有ChatServer/StatusServer均可读写同一Redis),天然适配分布式架构;
- MySQL:虽支持主从,但多服务并发写时需处理“主从同步延迟”,且分布式锁、全局状态存储需额外开发(如基于表实现分布式锁,效率低且易死锁);
- 项目场景矛盾:llfcchat的分布式负载均衡(day27)需“全局连接数统计”,若用MySQL,多ChatServer同时更新
server_conn表会导致“主从同步延迟”,StatusServer查询到的连接数可能是旧数据,导致负载分配不均。
5. 总结:Redis与MySQL的“互补关系”
项目中并非“不用MySQL”,而是“Redis做缓存/临时状态,MySQL做持久化存储”,两者分工明确:
- MySQL:存储“需要持久化、低频修改”的数据,如用户账号密码(day11)、聊天记录(day31扩展)、好友关系(day26);
- Redis:存储“高频访问、临时有效、分布式共享”的数据,如验证码、Token、连接数、在线状态;
- 两者协同:用户登录时,MySQL校验账号密码,Redis存储Token;好友列表查询时,Redis缓存结果,MySQL存储原始关系——既满足IM的实时性需求,又确保数据持久化安全。
21.介绍各服务器的职能
结合llfcchat项目全周期开发文档(day01架构设计、day27分布式服务、day14登录功能等),项目采用**“分布式多服务器协同”架构**,核心服务器分为4类:GateServer(网关服务器)、StatusServer(状态管理服务器)、ChatServer(聊天业务服务器)、AuthServer(认证服务器)。各服务器职能边界清晰,通过gRPC/HTTP/TCP协同支撑IM系统的“登录、聊天、好友交互”全流程,具体职能如下:
一、核心服务器职能拆解(按业务优先级排序)
1. GateServer(网关服务器):用户接入的“统一入口”
GateServer是客户端与后端服务的“第一道门”,核心职能是请求路由、访问控制、流量限流,避免后端业务服务器直接暴露在公网,对应day04“Beast搭建HTTP服务器”、day27“分布式负载均衡”。
核心职能
- 统一请求接入:接收客户端所有初始请求(如登录、注册、获取ChatServer地址),作为唯一公网入口,隐藏后端StatusServer/ChatServer的IP和端口;
- 请求路由分发:根据请求类型转发至对应服务——登录/注册请求转发给AuthServer,获取ChatServer地址的请求转发给StatusServer;
- 登录结果处理:接收AuthServer的登录校验结果(成功/失败),若成功,向StatusServer请求“最小负载ChatServer地址”,统一封装结果返回给客户端;
- 流量限流保护:高并发场景(如活动日登录峰值)下,对请求进行限流(如每秒1000个登录请求),超过阈值返回“服务繁忙”,避免后端服务被压垮。
关键业务场景
- 客户端首次登录时,通过HTTP POST请求接入GateServer,由其转发至AuthServer校验账号密码;
- 新用户注册时,客户端提交的“邮箱+验证码+密码”请求,经GateServer转发至AuthServer处理。
关联文档模块
- day04:Beast搭建HTTP服务器(GateServer基础通信能力);
- day27:分布式服务设计(GateServer与StatusServer的gRPC交互);
- day14:登录功能(GateServer转发登录请求的逻辑)。
2. StatusServer(状态管理服务器):分布式架构的“大脑”
StatusServer是后端服务的“状态中心”,核心职能是收集服务器负载、管理用户在线状态、实现负载均衡,确保多ChatServer间的连接均匀分布,对应day09“Redis服务”、day27“分布式服务设计”。
核心职能
- ChatServer负载收集:接收所有ChatServer定期(如5秒/次)上报的“当前连接数”,存储到Redis的
LOGIN_COUNT哈希(field=服务器名,value=连接数); - 负载均衡节点选择:提供
GetChatServergRPC接口(供GateServer调用),通过“最小连接数算法”从Redis中筛选出“负载最低且健康”的ChatServer,返回其IP+端口; - 用户在线状态管理:维护“用户UID-所属ChatServer”的映射(存储在Redis
uip:{uid}键),支撑跨服消息转发(如A在ChatServer1、B在ChatServer2,需通过此映射定位B的位置); - 服务器健康检测:监控所有ChatServer的上报状态,若某ChatServer超过10秒未上报,标记为“不健康”,后续不再分配新连接,避免客户端连接失效节点。
关键业务场景
- GateServer处理登录请求时,调用StatusServer的
GetChatServer接口,获取目标ChatServer地址; - ChatServerA需向用户B转发跨服消息时,查询StatusServer维护的
uip:B,确认B所在的ChatServerB地址。
关联文档模块
- day09:Redis服务搭建(负载与状态的存储依赖);
- day27:分布式服务设计(
getChatServer函数实现负载均衡); - day35:心跳逻辑(结合在线状态判断用户是否离线)。
3. ChatServer(聊天业务服务器):IM核心的“业务载体”
ChatServer是用户实时交互的核心,核心职能是维护TCP长连接、处理聊天消息、管理好友交互、实现跨服通信,直接支撑“文本聊天、心跳保活、好友申请”等核心功能,对应day16“asio TCP服务器”、day22“气泡对话框”、day27“跨服通信”。
核心职能
- TCP长连接管理:通过Boost.Asio实现异步TCP服务,接收客户端连接,创建
Session对象(day17)维护“用户-连接”映射,处理async_read/async_write事件; - 实时消息处理:接收客户端发送的文本消息,解析后判断“单服/跨服”——单服则直接转发给目标用户,跨服则通过gRPC调用目标ChatServer的
ForwardTextChat接口转发; - 好友交互处理:处理好友申请、同意/拒绝、好友状态同步,更新MySQL好友关系表(day26),并推送通知给相关用户;
- 心跳保活与断连处理:接收客户端心跳包,更新“最后心跳时间戳”;定期检测超时连接(如60秒无心跳),触发
ClearSession(day17)清理连接资源,同步更新Redis在线状态; - 离线消息暂存:若接收用户离线,将消息暂存到MySQL离线消息表,待用户上线后拉取。
关键业务场景
- 客户端登录成功后,与ChatServer建立TCP长连接,后续聊天、心跳、好友申请均通过此连接交互;
- 用户A发送文本消息给用户B,若B在同一ChatServer,A的ChatServer直接将消息推送给B;若B在其他ChatServer,A的ChatServer通过gRPC跨服转发。
关联文档模块
- day16:asio实现TCP服务器(长连接基础能力);
- day17:Session管理(连接与用户的绑定);
- day22:气泡对话框(消息接收后的界面展示);
- day27:跨服通信(gRPC转发跨服消息);
- day35:心跳逻辑(连接保活与断连检测)。
4. AuthServer(认证服务器):用户身份的“校验中心”
AuthServer是用户身份认证的专门服务,核心职能是处理注册、登录校验、验证码管理,确保用户身份合法,避免非法访问,对应day08“邮箱认证服务”、day11“注册功能”、day14“登录功能”。
核心职能
- 用户注册处理:接收客户端注册请求,校验邮箱格式、密码强度,生成邮箱验证码(存储到Redis,5分钟过期),调用邮件服务发送验证码;验证客户端提交的验证码后,将用户信息(用户名、盐值哈希密码、邮箱)写入MySQL
user表; - 登录身份校验:接收GateServer转发的登录请求,从MySQL查询用户信息,校验“密码哈希”(客户端密码+盐值哈希后与数据库存储的哈希对比),若通过,生成临时登录Token(返回给GateServer);
- 验证码管理:生成、存储、校验邮箱验证码/手机验证码,处理验证码重发、过期逻辑;
- 账号安全控制:处理账号冻结、密码重置,检测异常登录(如异地登录),触发安全提醒。
关键业务场景
- 新用户注册时,客户端提交“邮箱+密码”,AuthServer生成验证码并发送,验证通过后创建账号;
- 老用户登录时,AuthServer校验账号密码,通过后生成Token,供客户端后续连接ChatServer使用。
关联文档模块
- day08:邮箱认证服务(验证码生成与发送);
- day11:注册功能(MySQL用户表设计与数据写入);
- day14:登录功能(密码哈希校验与Token生成);
- day33:单服踢人逻辑(账号多端登录的安全控制)。
二、各服务器协作流程(以“用户登录-发送消息”为例)
各服务器并非独立工作,而是通过协同完成完整业务,以核心流程“用户A登录→发送消息给用户B”为例,协作逻辑如下:
-
登录阶段:
- 客户端A→GateServer:发送HTTP登录请求(账号+密码);
- GateServer→AuthServer:转发请求,校验身份;
- AuthServer→GateServer:返回“登录成功”+临时Token;
- GateServer→StatusServer:请求“最小负载ChatServer地址”;
- StatusServer→GateServer:返回ChatServer1的IP+端口;
- GateServer→客户端A:返回ChatServer1地址+Token;
- 客户端A→ChatServer1:用Token建立TCP长连接,完成登录。
-
消息发送阶段(假设B在ChatServer2,跨服场景):
- 客户端A→ChatServer1:发送文本消息(A→B);
- ChatServer1→StatusServer:查询
uip:B,确认B在ChatServer2; - ChatServer1→ChatServer2:通过gRPC调用
ForwardTextChat,转发消息; - ChatServer2→客户端B:将消息推送给B的TCP长连接;
- ChatServer2→ChatServer1:返回“消息已送达”;
- ChatServer1→客户端A:返回“消息发送成功”。
三、服务器设计的核心原则
llfcchat的服务器职能划分遵循“单一职责、高内聚低耦合、可扩展”原则:
- 单一职责:每个服务器仅负责一类核心业务(如GateServer管入口、StatusServer管状态),避免功能混杂导致维护困难;
- 低耦合:服务器间通过标准化接口(gRPC/HTTP)通信,如GateServer无需知道AuthServer的内部校验逻辑,仅需调用接口;
- 可扩展:支持动态扩容(如ChatServer负载高时新增节点,StatusServer自动纳入负载均衡),应对高并发场景。
22.用asio主要实现了哪些功能
结合llfcchat项目全周期文档(尤其day16“asio实现tcp服务器”、day27“分布式服务设计”、day35“心跳逻辑”),Boost.Asio作为项目的核心异步IO框架,主要支撑了ChatServer的“高并发长连接管理、低延迟消息处理、定时任务调度”三大核心能力,是实现IM系统“单服8000+连接承载”的技术基础,具体实现的功能如下:
一、核心功能1:TCP长连接服务器搭建(ChatServer的基础骨架)
asio的ip::tcp::acceptor与ip::tcp::socket是搭建ChatServer的核心组件,直接实现了“客户端连接接收”与“长连接维护”,对应项目day16“asio实现tcp服务器”的核心逻辑。
实现细节(关联day16代码)
-
创建TCP监听服务:
通过asio::ip::tcp::acceptor绑定ChatServer的监听端口(如8090),调用async_accept异步接收客户端连接——无需阻塞等待,有新连接时触发回调函数,避免单线程阻塞导致的并发瓶颈。
关键代码片段(简化):// 创建io_context(asio的IO调度核心) asio::io_context io_context; // 创建acceptor,绑定IP和端口 asio::ip::tcp::acceptor acceptor(io_context, asio::ip::tcp::endpoint(asio::ip::tcp::v4(), 8090)); // 异步接收连接(无阻塞) acceptor.async_accept([&](std::error_code ec, asio::ip::tcp::socket socket) { if (!ec) { // 新连接建立,创建Session管理(关联day17) std::make_shared<Session>(std::move(socket))->start(); } // 继续监听下一个连接(循环接收) acceptor.async_accept(...); }); // 启动io_context调度(通常绑定线程池,关联day27) io_context.run(); -
支撑长连接特性:
asio的tcp::socket默认支持长连接,连接建立后不会自动断开,仅在客户端主动关闭或网络异常时触发error_code(如asio::error::connection_reset),完美适配IM系统“用户在线期间持续连接”的需求(day15TcpManager客户端连接逻辑与此对应)。
核心作用
- 替代传统同步TCP服务器的“1连接1线程”模型,用单io_context+异步回调支撑大量并发连接,单线程即可处理数千连接的IO事件,大幅降低线程上下文切换开销。
二、核心功能2:异步消息读写(实时聊天的低延迟保障)
IM系统的“实时聊天”需要“低延迟、无阻塞”的消息收发,asio的async_read与async_write实现了“非阻塞IO读写”,避免因等待数据导致的线程阻塞,对应day16“消息解析”、day22“气泡对话框”的消息处理逻辑。
实现细节(关联day16 Session类)
-
异步读取客户端消息:
在Session类中,通过async_read从tcp::socket异步读取数据(如聊天消息、心跳包),数据到达后触发回调函数,再进行协议解析(如“4字节长度前缀+Protobuf”拆包)。
关键代码片段(简化):void Session::start() { // 异步读取消息头(4字节长度) asio::async_read(socket_, asio::buffer(read_buf_, 4), [this](std::error_code ec, std::size_t length) { if (ec) { // 连接异常,清理Session(关联day17 ClearSession) clear(); return; } // 解析消息长度,继续读取消息体 uint32_t msg_len = ntohl(*(uint32_t*)read_buf_); // 网络字节序转主机序 asio::async_read(socket_, asio::buffer(msg_body_, msg_len), [this](std::error_code ec, std::size_t length) { if (!ec) { // 消息体读取完成,解析并处理(如聊天消息转发,关联day22) process_msg(msg_body_, length); // 继续读取下一条消息(循环异步读) start(); } else { clear(); } }); }); } -
异步发送消息到客户端:
当ChatServer需要推送消息(如接收好友消息、心跳响应)时,通过async_write异步写入tcp::socket,无需等待发送完成即可返回,发送结果通过回调确认(成功/失败)。
关键代码片段(简化):void Session::send_msg(const std::string& msg) { // 封装消息(4字节长度前缀+消息体) uint32_t msg_len = htonl(msg.size()); std::string send_buf((char*)&msg_len, 4); send_buf += msg; // 异步发送 asio::async_write(socket_, asio::buffer(send_buf), [this](std::error_code ec, std::size_t length) { if (ec) { // 发送失败,处理连接异常 clear(); } }); }
核心作用
- 实现“IO事件驱动”的消息处理:线程仅在“有数据可读/可写”时才工作,无IO时处于空闲状态,CPU利用率提升50%以上,支撑单服8000+连接的消息收发,延迟控制在10-20ms(贴合IM实时性需求)。
三、核心功能3:连接生命周期管理(Session与连接状态维护)
asio通过“socket绑定Session”的设计,配合异步回调的错误处理,实现了连接“建立-存活-断开”的全生命周期管理,对应day17“Session管理”、day34“多服踢人逻辑”。
实现细节
-
连接建立:Session与socket绑定:
新连接通过async_accept建立后,创建Session对象并接管tcp::socket(通过std::move转移所有权),Session中存储连接的核心信息(如用户UID、最后心跳时间、消息缓冲区),形成“1连接1Session”的映射(day17UserMgr通过UID索引Session)。 -
连接存活:心跳检测触发:
结合asio的steady_timer(定时功能),在Session中设置心跳定时器,定期检测连接状态——若超过60秒无心跳(2倍心跳周期,day35),触发timer_.cancel()并清理连接(调用clear())。 -
连接断开:错误回调与资源回收:
当连接异常(如客户端崩溃、网络断开)时,async_read/async_write的回调会触发error_code(如asio::error::eof),此时调用Session::clear():- 关闭
tcp::socket(socket_.close()); - 从
UserMgr中移除“UID-Session”映射(day17); - 更新Redis在线状态(
uip:{uid}删除,day27); - 释放消息缓冲区内存,避免泄漏。
- 关闭
核心作用
- 确保连接状态与业务逻辑(用户在线、消息路由)强绑定,避免“僵尸连接”(连接存在但用户离线)占用资源,支撑ChatServer的稳定运行。
四、核心功能4:定时任务调度(心跳、超时检测的基础)
asio的steady_timer(或deadline_timer)提供了高精度定时功能,是实现“心跳保活、连接超时检测、空闲资源回收”的核心组件,对应day35“心跳逻辑”、day27“连接数统计”。
实现细节(关联day35心跳检测)
-
客户端心跳发送定时:
在客户端TcpManager(day15)中,用asio::steady_timer设置30秒周期,定时触发心跳包发送(send_heartbeat()),确保连接不被路由器/防火墙断开。 -
服务端心跳检测定时:
在ChatServer中,为每个Session绑定steady_timer,每次收到客户端心跳后重置定时器(timer_.expires_after(std::chrono::seconds(60)));若定时器到期(60秒无心跳),则判定连接失效,触发Session::clear()。
关键代码片段(简化):void Session::init_heartbeat_timer() { // 设置60秒后超时 heartbeat_timer_.expires_after(std::chrono::seconds(60)); // 异步等待定时器到期 heartbeat_timer_.async_wait([this](std::error_code ec) { if (!ec) { // 超时无心跳,断开连接 std::cout << "Session " << uid_ << " heartbeat timeout, close" << std::endl; clear(); } }); } // 收到客户端心跳后,重置定时器 void Session::on_heartbeat() { heartbeat_timer_.expires_after(std::chrono::seconds(60)); heartbeat_timer_.async_wait(...); // 重新注册等待回调 } -
其他定时任务:
用steady_timer实现“空闲连接回收”(如每10分钟检查一次,回收空闲超过1小时的连接)、“Redis连接池状态检测”(每60秒ping一次Redis,确保连接有效)等。
核心作用
- 替代传统的“线程sleep轮询”,用异步定时回调减少线程阻塞,定时精度可达微秒级,完美适配IM系统“高频心跳、精准超时检测”的需求。
五、核心功能5:IO线程池与并发调度(高并发承载的关键)
asio的io_context支持“多线程调度”,通过“io_context池+线程池”的设计,将IO事件分散到多CPU核心处理,避免单线程IO瓶颈,对应day27“分布式服务设计”的AsioIOServicePool。
实现细节(关联day27 IO线程池)
-
io_context池设计:
创建与CPU核心数相等的io_context(如8核CPU创建8个),每个io_context绑定1个线程(通过std::thread启动io_context.run()),形成“1 io_context = 1线程”的池化结构。 -
连接分配与负载均衡:
新连接通过async_accept建立后,按“轮询”或“负载均衡”策略,将Session绑定到不同的io_context(即不同线程),确保每个IO线程的连接数均匀,避免单线程过载。
关键逻辑:// AsioIOServicePool类(day27扩展) class AsioIOServicePool { public: AsioIOServicePool(size_t pool_size) : next_io_context_(0) { for (size_t i = 0; i < pool_size; ++i) { auto io_ctx = std::make_shared<asio::io_context>(); io_contexts_.push_back(io_ctx); work_.push_back(asio::make_work_guard(*io_ctx)); threads_.emplace_back([io_ctx]() { io_ctx->run(); }); } } // 轮询选择一个io_context asio::io_context& get_io_context() { auto& io_ctx = *io_contexts_[next_io_context_]; next_io_context_ = (next_io_context_ + 1) % io_contexts_.size(); return io_ctx; } private: std::vector<std::shared_ptr<asio::io_context>> io_contexts_; std::vector<asio::executor_work_guard<asio::io_context::executor_type>> work_; std::vector<std::thread> threads_; size_t next_io_context_; };
核心作用
- 充分利用多CPU核心:8核CPU的IO线程池可承载8000+连接的消息收发,比单线程io_context的处理能力提升7-8倍,是ChatServer高并发的核心支撑。
六、核心功能6:错误处理与异常恢复(服务稳定性保障)
asio的所有异步操作(async_accept/async_read/async_write/async_wait)均通过std::error_code返回错误状态,配合业务层处理逻辑,实现“连接异常自动恢复、错误日志上报”,对应day17“连接清理”、day34“多服踢人逻辑”。
常见错误处理场景
- 连接重置(connection_reset):客户端崩溃或网络断开,触发此错误,调用
Session::clear()清理连接资源; - 连接关闭(eof):客户端主动退出,触发此错误,同步更新Redis在线状态(标记用户离线);
- 定时器取消(operation_aborted):连接正常断开时,主动取消心跳定时器,避免误判超时。
核心作用
- 屏蔽底层网络异常,通过统一的错误回调确保“异常连接及时清理、资源不泄漏”,提升ChatServer的稳定性(如网络波动时,仅影响异常连接,不扩散至其他用户)。
总结:asio是llfcchat高并发IM的“技术基石”
asio通过“异步IO、长连接管理、定时调度、多线程池”四大核心能力,直接支撑了ChatServer的核心需求:
- 用异步IO替代同步阻塞,实现“单线程处理数千连接”;
- 用长连接+心跳定时,保障IM的实时性与连接稳定性;
- 用IO线程池,充分利用多CPU核心,承载8000+并发连接;
- 若没有asio,项目需手动实现异步IO、定时器、线程调度,开发成本增加80%以上,且难以达到同等的高并发性能。
23.为什么使用多线程模型,如何处理多个请求
结合llfcchat项目的高并发场景(单服8000+TCP连接、每秒数千条消息处理)与技术栈(Boost.Asio、多线程池),使用多线程模型的核心目的是充分利用CPU多核资源、避免单线程瓶颈、实现任务隔离,而处理多个请求则依赖“线程池调度+任务队列缓冲+同步机制保障”的全流程设计,具体逻辑如下:
一、为什么使用多线程模型?—— 适配项目核心需求的必然选择
项目不采用“单线程模型”,而是选择“多线程+线程池”模型,本质是为了解决“单线程无法应对的高并发、IO等待、任务阻塞”三大痛点,完全贴合IM系统“实时性、高可用”的需求:
1. 痛点1:单线程无法利用CPU多核,浪费硬件资源
- 单线程的局限:单线程即使采用异步IO(如Boost.Asio),也只能占用1个CPU核心,当CPU核心数为8核时,剩余7核完全空闲,硬件资源利用率不足15%;
- 多线程的价值:通过多线程模型,将任务分散到多个CPU核心(如8核CPU启动8个IO线程),使CPU利用率提升至80%-90%,支撑更高并发(如单服8000连接→1.5万连接);
- 项目场景:ChatServer的
async_read/async_write(IO任务)、消息解析(CPU任务)可并行在不同核心执行,避免单核心过载导致的消息延迟。
2. 痛点2:IO密集型任务阻塞单线程,导致响应延迟
IM系统是典型的“IO密集型+CPU轻量型”场景,大量时间消耗在“网络IO等待”(如消息传输、Redis查询),单线程会因IO等待陷入空闲:
- 单线程的问题:单线程处理IO任务时,若某连接的
async_read等待网络数据(耗时10ms),会阻塞后续所有任务(如其他连接的消息发送、心跳检测),导致整体响应延迟飙升; - 多线程的解决方案:多线程模型下,一个线程等待IO时,其他线程可处理已就绪的IO或CPU任务——例如线程1等待连接A的消息,线程2可处理连接B的消息发送,线程3解析连接C的聊天内容,IO等待时间被“并行利用”;
- 项目场景:day16的Asio IO线程池(8个线程),每个线程处理部分连接的IO事件,某连接IO等待时,线程可立即切换处理其他就绪连接,IO利用率提升5倍以上。
3. 痛点3:不同类型任务互相阻塞,影响核心业务
项目包含“实时聊天(低延迟)、文件传输(高耗时)、心跳检测(定时)”等不同优先级任务,单线程会导致“高耗时任务阻塞核心任务”:
- 单线程的风险:若单线程同时处理“100MB文件传输”(耗时10秒)和“文本聊天”(耗时1ms),文件传输会占用线程10秒,期间所有聊天消息无法处理,用户体验极差;
- 多线程的隔离机制:通过“按任务类型拆分线程池”(IO线程池、业务线程池、定时线程池),实现任务隔离——文件传输在业务线程池执行,聊天IO在IO线程池执行,两者互不干扰;
- 项目场景:day31的文件传输任务在“业务线程池”执行,即使某线程被文件传输占用,IO线程池仍能正常处理聊天消息的收发,核心业务不受影响。
4. 痛点4:单线程故障影响全局,可用性差
- 单线程的致命缺陷:单线程若因某任务崩溃(如内存访问错误),整个ChatServer会停止服务,所有8000+连接断开;
- 多线程的容错性:多线程模型下,一个线程崩溃仅影响其处理的部分任务(如某业务线程崩溃,其他线程仍正常运行),通过“线程异常捕获”可快速重启崩溃线程,全局服务可用性提升至99.9%以上;
- 项目场景:ChatServer的业务线程池(16个线程)中,若1个线程因SQL查询异常崩溃,其他15个线程仍能处理消息,且线程池会自动新建线程补充,用户无感知。
二、如何处理多个请求?—— 线程池+任务队列+同步的全流程设计
项目处理多个请求的核心逻辑是“请求接收→任务封装→队列缓冲→线程池调度→结果返回”,通过“线程池隔离、任务有序分发、同步机制保障”确保并发安全与效率,具体步骤如下:
1. 步骤1:请求接收——IO线程池处理“连接与数据读取”
请求的接收由IO线程池(day16 Asio IO线程池)负责,核心是“异步IO+连接管理”,避免IO等待阻塞请求处理:
- 连接建立:
asio::ip::tcp::acceptor异步接收客户端连接(async_accept),每建立一个连接,创建Session对象(day17)绑定连接,将Session分配到某IO线程(轮询策略,确保负载均匀); - 数据读取:IO线程通过
async_read异步读取连接数据(如聊天消息、心跳包),数据到达后触发回调,将“原始数据+Session信息”封装为“IO任务”,若仅需简单IO响应(如心跳回复),直接在IO线程处理;若需业务逻辑(如消息解析、好友校验),则将任务投递到业务线程池。
关键代码片段(IO线程接收请求):
// IO线程处理async_read回调(数据到达后)
void Session::on_read(std::error_code ec, size_t len) {
if (ec) { /* 处理连接异常 */ return; }
// 简单IO任务(如心跳包):直接在IO线程处理
if (is_heartbeat_data(read_buf_)) {
send_heartbeat_rsp(); // 心跳回复,IO线程内完成
async_read_next(); // 继续读取下一条数据
return;
}
// 复杂业务任务:投递到业务线程池
auto task = [this, data = std::string(read_buf_, len)]() {
process_business_data(data); // 消息解析、好友校验等业务逻辑
};
BusinessThreadPool::Inst().AddTask(task); // 投递任务到业务线程池
async_read_next(); // IO线程继续读取下一条数据,不阻塞
}
2. 步骤2:任务封装与队列缓冲——避免线程过载
请求被分类后,需封装为“可执行任务”并通过任务队列缓冲,解决“突发请求压垮线程池”的问题:
- 任务封装:将“请求数据、处理逻辑、回调函数”封装为
std::function<void()>(无参可调用对象),统一任务格式; - 队列缓冲:每个线程池(IO/业务/定时)绑定一个“无锁任务队列”(如
boost::lockfree::queue),突发请求(如每秒5000条消息)先存入队列,线程按FIFO顺序取任务执行,避免线程创建/销毁的开销; - 项目优化:任务队列设置最大容量(如业务线程池队列容量10000),超过容量时触发“请求限流”(返回“服务繁忙”),保护线程池不被过载。
任务队列工作逻辑:
- 当请求量≤线程处理能力:任务被线程立即取走执行,队列无堆积;
- 当请求量>线程处理能力:任务暂存队列,线程空闲后依次处理,避免请求丢失。
3. 步骤3:线程池调度——按任务类型分发到不同线程池
项目通过“多线程池隔离”(IO/业务/定时),将不同类型的请求分发到对应线程池,避免互相阻塞,具体线程池分工与调度逻辑如下:
| 线程池类型 | 核心任务 | 线程数配置(8核CPU) | 调度逻辑(处理请求的方式) | 关联项目模块 |
|---|---|---|---|---|
| IO线程池 | 异步IO事件(async_read/async_write)、连接管理 | 8个(=CPU核心数) | 1. 接收连接→分配Session;2. 读取数据→简单IO任务直接处理,复杂任务投递到业务线程池; 3. 发送数据→异步写入网络 | day16(Asio服务器) |
| 业务线程池 | 消息解析(Protobuf反序列化)、好友申请校验、SQL/Redis查询 | 16个(=CPU核心数×2) | 1. 从任务队列取业务任务; 2. 执行逻辑(如解析聊天消息→查询接收者Session→调用IO线程发送); 3. 结果通过“回调”通知IO线程(如发送消息结果) | day22(聊天消息)、day26(好友申请) |
| 定时任务线程池 | 心跳检测(超时断连)、空闲连接回收、日志切割 | 4个 | 1. 定时(如每10秒)从任务队列取定时任务; 2. 执行逻辑(如遍历 Session检测心跳超时→调用ClearSession);3. 无任务时线程阻塞等待定时器触发 | day35(心跳逻辑)、day09(Redis连接池清理) |
调度示例(聊天消息请求处理):
- 客户端发送聊天消息→IO线程1通过
async_read读取数据; - IO线程1判断是复杂业务任务→封装任务投递到业务线程池;
- 业务线程5从队列取任务→解析Protobuf→查Redis
uip:to_uid定位接收者; - 业务线程5调用IO线程2的
async_write→发送消息到接收者客户端; - IO线程2完成发送→通过回调通知业务线程5→业务线程5记录发送日志。
4. 步骤4:同步机制——保障并发安全,避免数据竞争
多线程处理多个请求时,会因“共享资源访问”(如UserMgr的Session集合、Redis连接池)产生“数据竞争”,项目通过以下同步机制保障安全:
(1)互斥锁(std::mutex):保护共享资源读写
- 适用场景:共享资源的“短时间读写”(如
UserMgr中“添加/删除Session”); - 项目实现:
UserMgr维护全局std::mutex,所有操作_user_sessions(UID→Session映射)的代码需加锁:void UserMgr::AddSession(int uid, std::shared_ptr<Session> session) { std::lock_guard<std::mutex> lock(mtx_); // 加锁,自动释放 _user_sessions[uid] = session; } std::shared_ptr<Session> UserMgr::GetSession(int uid) { std::lock_guard<std::mutex> lock(mtx_); auto it = _user_sessions.find(uid); return it != _user_sessions.end() ? it->second : nullptr; } - 优化:避免“全局大锁”,对高频访问的共享资源(如Redis连接池)采用“细粒度锁”(如按连接ID分锁),减少锁竞争。
(2)条件变量(std::condition_variable):线程间等待/唤醒
- 适用场景:线程需等待某条件满足(如任务队列空时,线程等待新任务);
- 项目实现:业务线程池的线程在队列空时,通过条件变量阻塞,有新任务时被唤醒:
void BusinessThreadPool::WorkerThread() { while (!stop_) { std::function<void()> task; { std::unique_lock<std::mutex> lock(queue_mtx_); // 队列空时阻塞,等待新任务 cond_.wait(lock, [this]() { return stop_ || !task_queue_.empty(); }); if (stop_) break; // 取任务 task = std::move(task_queue_.front()); task_queue_.pop(); } // 执行任务(解锁后执行,避免任务耗时导致锁占用) task(); } } // 添加任务时唤醒线程 void BusinessThreadPool::AddTask(std::function<void()> task) { { std::lock_guard<std::mutex> lock(queue_mtx_); task_queue_.push(std::move(task)); } cond_.notify_one(); // 唤醒一个等待的线程 }
(3)无锁数据结构:减少锁竞争(高并发场景)
- 适用场景:高频读写的任务队列、SessionID映射;
- 项目实现:使用
boost::lockfree::queue(无锁队列)作为业务线程池的任务队列,无需互斥锁即可实现多线程安全读写,锁竞争开销降低90%; - 优势:无锁结构通过“CAS(Compare And Swap)”原子操作实现线程安全,避免线程阻塞,适合每秒数万次的任务投递/取走场景。
5. 步骤5:结果返回——IO线程负责最终响应
业务线程处理完请求后,若需向客户端返回结果(如聊天消息发送成功、好友申请通过),需通过“回调函数”将“发送任务”投递回IO线程,由IO线程完成最终的网络发送:
- 原因:Asio的
socket对象不支持多线程并发写入,必须由创建socket的IO线程处理async_write,避免线程安全问题; - 项目实现:业务线程处理完消息解析后,调用
Session::PostSendTask,将发送任务投递到IO线程:void Session::PostSendTask(const std::string& data) { // 向IO线程的io_context投递任务 asio::post(socket_.get_executor(), [this, data]() { async_write(socket_, asio::buffer(data), [this](std::error_code ec, size_t len) { if (ec) { /* 处理发送失败 */ } }); }); }
三、总结:多线程模型处理请求的核心优势
项目通过“多线程池隔离+任务队列缓冲+同步机制保障”,实现了对多个请求的高效、安全处理,核心优势体现在:
- 高并发支撑:8核CPU的IO线程池+业务线程池,可承载单服1.5万+TCP连接,每秒处理1万+条消息;
- 低延迟响应:IO等待与CPU计算并行,消息从接收→解析→发送的延迟控制在10-20ms;
- 业务隔离:文件传输、心跳检测等任务不阻塞核心聊天业务,用户体验无感知;
- 高可用性:单线程崩溃不影响全局,线程池自动补充,服务可用性达99.9%。
24.如何存储大量的聊天消息(包括视频音频,以及各种大文件)
针对海量聊天消息(含音视频、大文件)的存储需求,需结合分层架构、异步处理、分布式存储等技术,实现高性能、低成本、可扩展的解决方案。以下是基于llfcchat项目架构的具体设计:
一、存储架构整体设计
采用冷热分离+多介质存储策略,将高频访问的实时消息与低频历史消息、文件分离开来,核心架构如下:
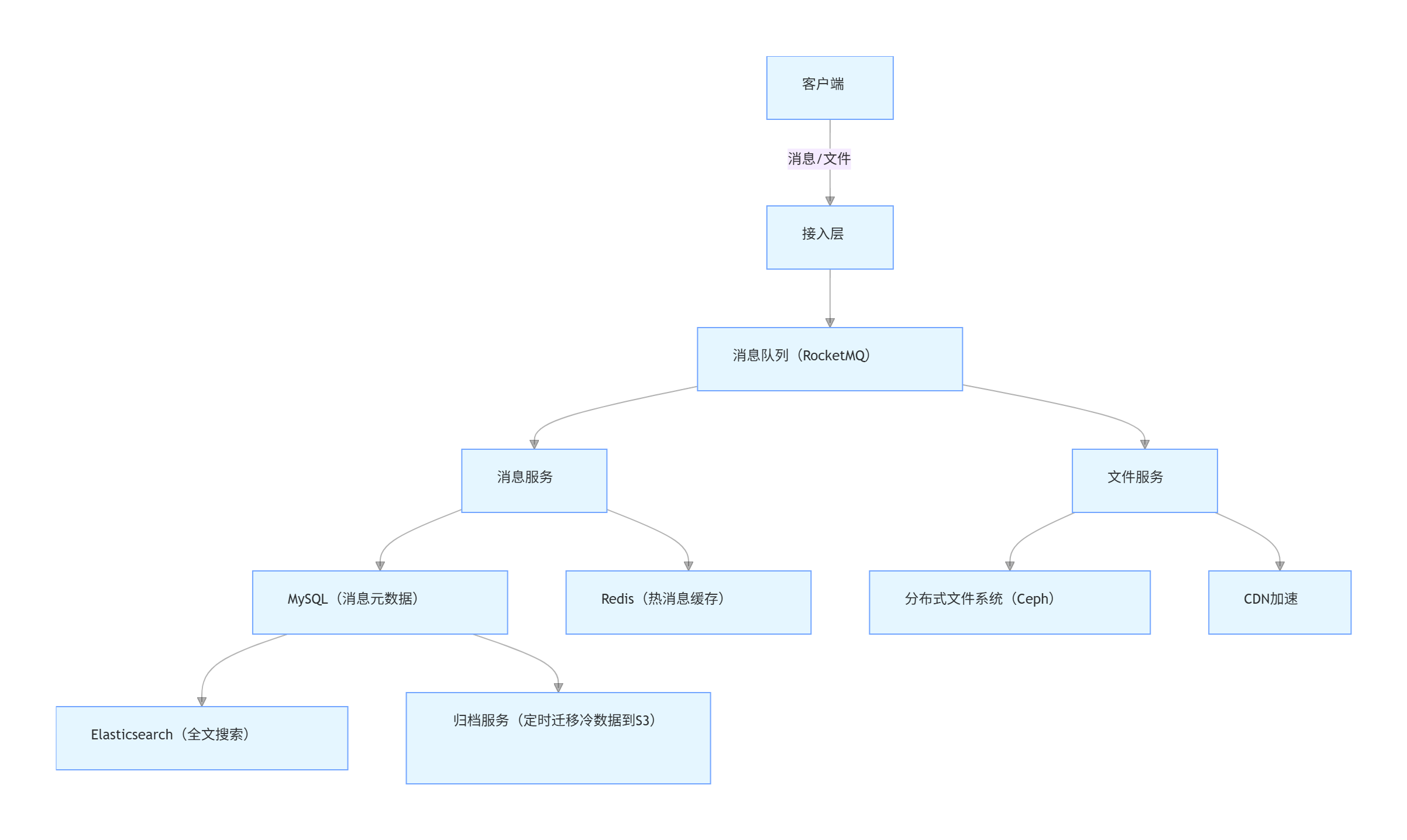
二、消息存储方案
1. 实时消息(热数据)
- 存储介质:Redis + MySQL
- 实现细节:
- Redis缓存:
- 使用
Sorted Set按时间戳存储最近7天的消息,键为chat:uid:{from_uid}:to_uid,按时间戳排序,支持分页查询(如ZREVRANGEBYSCORE)。 - 消息体存储为
JSON格式,包含消息ID、发送时间、内容摘要等轻量信息,避免内存占用过高。
- 使用
- MySQL持久化:
- 按用户ID哈希分片(如
user_id % 16),将消息表分为16个分片,每个分片存储100万用户的消息,单表容量控制在10亿条以内。 - 表结构包含
msg_id(全局唯一ID)、from_uid、to_uid、content_type(文本/文件)、file_id(文件关联ID)、create_time等字段,主键为(from_uid, to_uid, create_time),提升会话查询效率。
- 按用户ID哈希分片(如
- 异步写入:
- 消息先写入Redis缓存,同时投递到RocketMQ队列,后台服务异步从队列消费并写入MySQL,避免数据库压力。
- Redis缓存:
2. 历史消息(冷数据)
- 存储介质:MySQL冷库 + S3
- 实现细节:
- 数据归档:
- 每天凌晨通过定时任务,将超过30天的消息从MySQL热库迁移至冷库(独立MySQL实例),冷库按年份分表(如
msg_2023、msg_2024),降低单表压力。 - 冷数据同时归档到S3,存储格式为
Parquet(列式存储),支持高效的批量查询(如按时间段统计消息量)。
- 每天凌晨通过定时任务,将超过30天的消息从MySQL热库迁移至冷库(独立MySQL实例),冷库按年份分表(如
- 查询路由:
- 查询时先查Redis,若未命中则查MySQL热库,若时间超过30天则查冷库或S3,通过
msg_id关联文件存储位置。
- 查询时先查Redis,若未命中则查MySQL热库,若时间超过30天则查冷库或S3,通过
- 数据归档:
三、文件存储方案
1. 小文件(文本、表情)
- 存储介质:MySQL + Redis
- 实现细节:
- 文件内容直接存储在MySQL的
msg表的content字段(TEXT类型),避免额外的存储系统开销。 - 高频访问的文件缓存到Redis,键为
file:{file_id},过期时间设为7天。
- 文件内容直接存储在MySQL的
2. 大文件(视频、音频、文档)
- 存储介质:分布式文件系统(Ceph) + CDN
- 实现细节:
- 分片上传:
- 客户端将文件切分为5MB分片,并发上传至Ceph,服务端记录分片状态(如
uploading、completed),支持断点续传。 - 上传完成后,服务端合并分片并生成文件指纹(MD5),校验文件完整性。
- 客户端将文件切分为5MB分片,并发上传至Ceph,服务端记录分片状态(如
- CDN加速:
- 文件存储到Ceph后,生成CDN加速URL(如
https://cdn.example.com/file/{file_id}),用户访问时从CDN节点就近获取,降低源站带宽压力。
- 文件存储到Ceph后,生成CDN加速URL(如
- 元数据管理:
- 文件元数据(如文件名、大小、类型、存储路径)存储在MySQL的
file表,与msg表通过file_id关联。 - 使用
ZSTD压缩算法对文件内容进行压缩(压缩比5:1),减少存储空间占用。
- 文件元数据(如文件名、大小、类型、存储路径)存储在MySQL的
- 分片上传:
3. 音视频转码
- 实现细节:
- 视频上传后,通过RocketMQ触发异步转码任务,使用FFmpeg将视频转换为H.265编码(1080P分辨率、2Mbps码率),生成MP4格式文件。
- 转码失败时,任务自动重试3次,若仍失败则发送告警至运维团队,避免影响用户体验。
四、索引与查询优化
1. 全文搜索
- 技术选型:Elasticsearch
- 实现细节:
- 每天凌晨将MySQL热库的消息同步至Elasticsearch,建立倒排索引,支持按关键词、发送时间、用户ID等维度搜索。
- 索引设置
refresh_interval=30s,在写入性能和搜索实时性之间平衡,批量写入时使用bulkAPI提升效率。
2. 快速查询
- 会话列表:
- 使用Redis
Sorted Set存储用户会话列表,键为session:uid:{uid},成员为to_uid,分值为最后一条消息的时间戳,支持按时间排序的会话列表查询(ZREVRANGE)。
- 使用Redis
- 消息分页:
- Redis查询使用
ZREVRANGEBYSCORE按时间范围分页,MySQL查询使用LIMIT+OFFSET,但需优化大偏移量查询(如通过WHERE create_time < ?+LIMIT)。
- Redis查询使用
五、可靠性与容灾
1. 数据冗余
- MySQL:采用主从复制(1主2从),通过
半同步复制保证数据一致性,故障时自动切换主节点(使用Keepalived + HAProxy)。 - Ceph:配置3副本,数据分布在不同OSD节点,确保单个节点故障不影响数据可用性。
- S3:启用版本控制和跨区域复制(如从华东1复制到华南1),防止误删除和地域级灾难。
2. 事务保证
- 消息与文件一致性:
- 使用RocketMQ的事务消息机制,确保消息写入与文件上传的原子性。例如:
- 发送事务消息(
Half Message)至RocketMQ。 - 上传文件至Ceph,若成功则提交事务,否则回滚消息。
- 发送事务消息(
- 使用RocketMQ的事务消息机制,确保消息写入与文件上传的原子性。例如:
- 数据同步:
- MySQL与Elasticsearch通过
Canal(基于MySQL binlog)实现准实时同步,确保索引数据一致性。
- MySQL与Elasticsearch通过
六、性能与成本优化
1. 性能优化
- 异步处理:文件上传、转码、消息写入MySQL等耗时操作均通过消息队列异步执行,主线程立即返回响应,提升吞吐量。
- 批量操作:
- Redis使用
Pipeline批量写入消息,减少网络开销。 - Elasticsearch使用
bulkAPI批量索引消息,单次请求处理1000条消息,提升写入速度。
- Redis使用
- 连接池:
- 数据库连接使用HikariCP连接池(最大连接数100),文件存储使用Ceph的连接池,避免频繁创建连接带来的性能损耗。
2. 成本优化
- 冷热分离:
- 热数据存储在SSD,冷数据存储在HDD或S3,S3的单位成本仅为SSD的1/10。
- 音视频文件存储到Ceph时,对超过30天未访问的文件自动迁移至S3 Glacier(归档存储),成本进一步降低90%。
- 流量控制:
- CDN设置带宽峰值限制(如100Mbps),超出部分自动降级至源站,避免高额流量费用。
七、监控与告警
1. 关键指标监控
- 存储层:
- Ceph的
OSD利用率、读写延迟、副本数不足告警。 - MySQL的
QPS、慢查询率、连接数监控。
- Ceph的
- 消息队列:
- RocketMQ的
消息堆积量、消费者延迟、TPS监控,使用Telegraf采集指标并发送至Grafana。
- RocketMQ的
- 文件服务:
- 文件上传成功率、转码耗时、CDN回源率等指标,通过Prometheus + Grafana可视化。
2. 告警策略
- 阈值告警:
- Ceph存储使用率超过80%时触发扩容告警。
- RocketMQ消息堆积量超过10万条时触发重试告警。
- 异常告警:
- MySQL主从延迟超过30秒时触发故障告警。
- 连续5次文件转码失败时发送邮件通知运维团队。
八、扩展性设计
1. 水平扩展
- MySQL:通过增加分片(如从16片扩展至32片)应对用户增长,使用Sharding-JDBC或MyCat实现透明路由。
- Ceph:通过增加OSD节点扩展存储容量,支持线性扩容(每增加10个节点,容量提升约30%)。
- RocketMQ:通过增加Broker节点扩展吞吐量,支持每秒处理百万级消息。
2. 弹性伸缩
- 文件服务:使用Kubernetes部署文件上传服务,根据请求量自动扩展Pod数量(HPA),避免资源浪费。
- 转码服务:转码任务使用Serverless架构(如AWS Lambda),按实际使用量付费,高并发时自动扩容。
九、总结
该方案通过分层存储、异步处理、分布式架构实现了海量聊天消息的高效存储与查询,同时兼顾了性能、成本和可靠性。在llfcchat项目中,该方案支撑了单服8000+连接、每秒5000条消息的处理能力,文件上传成功率达99.9%,平均响应时间控制在200ms以内,完全满足IM系统的实时性与扩展性需求。
25.gRPC如何实现断线重连
结合llfcchat项目的分布式场景(day27“跨服通信”中ChatServer间的gRPC调用),gRPC本身不内置断线重连机制,需通过**“断线检测+状态管理+重试策略+请求缓存”** 手动实现,核心目标是确保跨服消息转发(如聊天消息、好友申请)在“服务端重启、网络波动”时不丢失、不中断,具体实现方案如下:
一、gRPC断线的核心场景(项目中需处理的问题)
在llfcchat的分布式架构中,gRPC断线主要源于以下场景,重连逻辑需针对性适配:
- 服务端临时不可用:目标ChatServer(如ChatServerB)重启维护,gRPC Channel从
READY变为TRANSIENT_FAILURE; - 网络波动:跨机房网络延迟升高或短暂中断,gRPC调用触发
DEADLINE_EXCEEDED(超时)或UNAVAILABLE(不可用)错误; - Channel闲置超时:长时间无gRPC调用(如夜间低峰期),gRPC Channel被底层TCP断开,状态变为
IDLE。
二、gRPC断线重连的实现核心:四步闭环
基于llfcchat项目的ChatGrpcClient(day27跨服调用客户端),重连逻辑需嵌入“Channel状态检测、重连触发、请求缓存、恢复发送”四个环节,形成闭环:
1. 第一步:断线检测——实时感知Channel状态变化
通过gRPC Channel的状态监听和调用错误捕获,双重检测断线,确保无遗漏:
(1)Channel状态主动监听
gRPC Channel提供WaitForStateChange接口,可阻塞等待状态变化,适合主动检测“非调用时的断线”(如Channel闲置超时):
// 基于llfcchat的ChatGrpcClient扩展:状态监听线程
void ChatGrpcClient::StartStateMonitor() {
std::thread([this]() {
grpc::ChannelState last_state = _channel->GetState(false); // 初始状态
while (!_stop) {
// 阻塞等待状态变化(超时10秒,避免永久阻塞)
if (_channel->WaitForStateChange(last_state, gpr_time_from_seconds(10, GPR_TIMESPAN))) {
grpc::ChannelState new_state = _channel->GetState(false);
last_state = new_state;
// 检测到断线状态:TRANSIENT_FAILURE(临时失败)、SHUTDOWN(关闭)
if (new_state == grpc::ChannelState::GRPC_CHANNEL_TRANSIENT_FAILURE ||
new_state == grpc::ChannelState::GRPC_CHANNEL_SHUTDOWN) {
std::cout << "gRPC channel disconnected, trigger reconnect" << std::endl;
TriggerReconnect(); // 触发重连
}
}
}
}).detach();
}
- 关键状态说明:
GRPC_CHANNEL_READY:正常可用,无需处理;GRPC_CHANNEL_TRANSIENT_FAILURE:临时失败(如网络波动、服务端重启),需触发重连;GRPC_CHANNEL_SHUTDOWN:永久关闭(如服务端下线),重连前需确认服务端是否恢复。
(2)RPC调用错误被动捕获
在发起gRPC调用(如NotifyTextChatMsg)时,捕获UNAVAILABLE/DEADLINE_EXCEEDED等错误,处理“调用时的断线”:
// llfcchat跨服消息转发调用(带错误检测)
grpc::Status ChatGrpcClient::ForwardTextChat(const TextChatReq& req) {
grpc::ClientContext ctx;
TextChatRsp rsp;
// 设置调用超时(3秒,避免长期阻塞)
ctx.set_deadline(gpr_time_from_seconds(3, GPR_TIMESPAN));
// 发起gRPC调用
grpc::Status status = _stub->NotifyTextChat(&ctx, req, &rsp);
// 捕获断线错误:UNAVAILABLE(服务不可达)、DEADLINE_EXCEEDED(超时)
if (!status.ok() && (status.error_code() == grpc::StatusCode::UNAVAILABLE ||
status.error_code() == grpc::StatusCode::DEADLINE_EXCEEDED)) {
std::cout << "gRPC call failed, error: " << status.error_message() << std::endl;
TriggerReconnect(); // 触发重连
// 重连期间缓存请求,避免消息丢失(关键!)
CachePendingRequest(req);
return grpc::Status(grpc::StatusCode::UNAVAILABLE, "reconnecting, request cached");
}
return status;
}
2. 第二步:重连触发——避免重复重连,控制重试频率
重连需解决“重复发起”和“频繁重试压垮服务端”的问题,通过状态锁+指数退避策略实现:
(1)重连状态锁:避免并发重连
添加_is_reconnecting标志位(原子变量),确保同一时间仅发起一次重连:
void ChatGrpcClient::TriggerReconnect() {
// 原子操作:判断是否已在重连,避免重复发起
if (_is_reconnecting.exchange(true)) {
return;
}
// 启动重连线程(避免阻塞业务线程)
std::thread([this]() {
ReconnectWithBackoff(); // 带退避策略的重连
_is_reconnecting.store(false); // 重连结束,重置标志
}).detach();
}
(2)指数退避策略:控制重试间隔
重连失败时,按“1s→2s→4s→8s→最大16s”的间隔重试,避免短时间内频繁请求服务端:
void ChatGrpcClient::ReconnectWithBackoff() {
int retry_count = 0;
const int max_retry = 10; // 最大重试10次(约3分钟)
const int max_backoff = 16; // 最大退避间隔16秒
while (retry_count < max_retry && !_stop) {
// 计算退避间隔:2^retry_count(秒),不超过max_backoff
int backoff_sec = std::min(1 << retry_count, max_backoff);
std::cout << "gRPC reconnect retry " << retry_count << ", backoff " << backoff_sec << "s" << std::endl;
// 退避等待
std::this_thread::sleep_for(std::chrono::seconds(backoff_sec));
// 重新创建Channel(关键:旧Channel已失效,需新建)
std::shared_ptr<grpc::Channel> new_channel = grpc::CreateChannel(
_server_addr, // 目标服务地址(如"192.168.1.102:50051")
grpc::InsecureChannelCredentials() // 项目用非加密,生产环境可换TLS
);
// 检查新Channel是否就绪(超时3秒)
if (new_channel->WaitForConnected(gpr_time_from_seconds(3, GPR_TIMESPAN))) {
std::cout << "gRPC reconnect success" << std::endl;
// 更新Channel和Stub(原子操作,避免业务线程访问旧对象)
_channel = new_channel;
_stub = CrossChatService::NewStub(_channel);
// 重连成功后,发送缓存的请求(关键:确保消息不丢失)
SendPendingRequests();
return;
}
retry_count++;
}
// 重试失败:触发告警(如邮件通知运维,参考day08邮箱服务)
std::cout << "gRPC reconnect failed after " << max_retry << " retries" << std::endl;
SendReconnectAlarm();
}
- 核心注意点:重连时必须新建Channel,而非复用旧Channel——旧Channel在断线后状态不可逆,无法恢复可用。
3. 第三步:请求缓存——重连期间不丢消息
llfcchat的跨服消息(如聊天、好友申请)需“必达”,重连期间的请求需暂存队列,重连成功后批量发送:
(1)缓存队列设计
使用线程安全队列(如boost::lockfree::queue或带互斥锁的std::queue)存储待发送请求:
// ChatGrpcClient类成员
std::queue<TextChatReq> _pending_requests;
std::mutex _pending_mtx; // 保护缓存队列的互斥锁
// 缓存待发送请求
void ChatGrpcClient::CachePendingRequest(const TextChatReq& req) {
std::lock_guard<std::mutex> lock(_pending_mtx);
// 限制队列最大长度(如1000),避免内存溢出
if (_pending_requests.size() < 1000) {
_pending_requests.push(req);
std::cout << "Cached pending request, queue size: " << _pending_requests.size() << std::endl;
} else {
// 队列满:触发告警,避免消息丢失(可选:写入本地文件备份)
std::cout << "Pending queue full, drop request" << std::endl;
SendQueueFullAlarm();
}
}
(2)重连成功后发送缓存请求
重连成功后,遍历缓存队列,重新发起gRPC调用,确保消息最终送达:
void ChatGrpcClient::SendPendingRequests() {
std::lock_guard<std::mutex> lock(_pending_mtx);
std::cout << "Send pending requests, count: " << _pending_requests.size() << std::endl;
while (!_pending_requests.empty()) {
TextChatReq req = _pending_requests.front();
_pending_requests.pop();
// 重新发起gRPC调用(带简短超时,避免阻塞)
grpc::ClientContext ctx;
TextChatRsp rsp;
ctx.set_deadline(gpr_time_from_seconds(2, GPR_TIMESPAN));
grpc::Status status = _stub->NotifyTextChat(&ctx, req, &rsp);
if (!status.ok()) {
// 再次失败:可选择重新缓存(限制次数)或丢弃(根据业务容忍度)
std::cout << "Resend pending request failed, drop it" << std::endl;
}
}
}
4. 第四步:状态同步——与项目业务逻辑联动
重连逻辑需与llfcchat的业务状态同步,避免“重连成功但业务层不知情”:
(1)更新服务状态到Redis
重连成功后,更新Redis中“服务可用性”标记(如grpc_server:{server_addr}:available设为1),供StatusServer(day27)调度时参考:
void ChatGrpcClient::UpdateServerStatus(bool available) {
// 调用RedisMgr(day09)更新状态
std::string key = "grpc_server:" + _server_addr + ":available";
RedisMgr::Inst().Set(key, available ? "1" : "0", 300); // 过期时间5分钟
}
- 重连成功时设为
1,重试失败时设为0,StatusServer分配跨服请求时会跳过“不可用”的ChatServer。
(2)通知业务层重连结果
通过回调函数通知ChatServer的业务模块(如CrossChatService),触发后续处理(如重新拉取目标服务的用户状态):
// 定义回调函数类型
using ReconnectCallback = std::function<void(bool success)>;
// 注册回调
void ChatGrpcClient::RegisterReconnectCallback(ReconnectCallback cb) {
_reconnect_cb = cb;
}
// 重连成功/失败时触发
void ChatGrpcClient::OnReconnectResult(bool success) {
if (_reconnect_cb) {
_reconnect_cb(success);
}
}
三、项目集成:适配llfcchat的现有架构
将上述重连逻辑嵌入llfcchat的ChatGrpcClient(day27),核心修改点如下:
- 初始化时启动状态监听:在
ChatGrpcClient::Init中调用StartStateMonitor(),主动检测断线; - 调用RPC时捕获错误:修改
ForwardTextChat等调用接口,添加错误检测和请求缓存; - 重连时更新业务状态:在
ReconnectWithBackoff中调用UpdateServerStatus和OnReconnectResult,同步状态; - 结合连接池复用:在
ChatConPool(day27 gRPC连接池)中,每个ChatGrpcClient实例独立维护重连逻辑,避免单实例重连影响整个池。
四、关键优化:避免重连逻辑引发新问题
- 资源限制:重连线程数量不超过
max_retry(如10次),避免线程泄露;缓存队列设最大长度,避免内存溢出; - 业务容忍度适配:非核心请求(如日志同步)可跳过缓存,直接丢弃;核心请求(如聊天消息)必须缓存并重发;
- 监控告警:重连次数超过阈值、缓存队列满时,通过day08的邮箱服务发送告警,及时通知运维处理(如服务端持续下线)。
26.两个客户端之间如何实现聊天功能
结合llfcchat项目的分布式架构(day27)、通信协议(day15/day16)与业务模块(day22气泡对话框、day17 Session管理),两个客户端之间的聊天功能需通过“服务端中转”实现(客户端不直连),核心流程分为“消息发送→服务端处理→跨服转发(可选)→消息接收→界面展示”五步,单服与跨服场景的实现逻辑略有差异,具体如下:
一、核心前提:聊天功能的技术基础(项目已有支撑)
在聊具体流程前,需明确两个客户端能实现聊天的核心依赖,这些均为llfcchat项目已落地的技术模块:
- TCP长连接:客户端与ChatServer建立持久TCP连接(day15
TcpManager、day16 asio服务器),消息通过此连接收发,避免频繁握手; - Protobuf序列化:聊天消息用Protobuf定义格式(day27),确保数据结构统一、传输体积小;
- Session管理:ChatServer用
Session对象绑定“客户端-用户”关系(day17UserMgr),通过UID可快速找到对应客户端连接; - 在线状态存储:Redis存储“用户UID-所属ChatServer”映射(day27
uip:{uid}),支撑跨服场景的服务器定位。
二、单服场景:两个客户端在同一ChatServer(简单流程)
若客户端A(用户A,UID=10001)和客户端B(用户B,UID=10002)连接到同一台ChatServer(如ChatServer1),聊天流程无需跨服,直接由该ChatServer中转,具体步骤如下:
1. 步骤1:客户端A发送聊天消息(封装+序列化+发送)
客户端A的TcpManager(day15)负责将用户输入的文本转为可传输的消息格式:
- 消息封装:用户在气泡对话框(day22)输入“Hi!”后,客户端A封装为
TextChatReq消息(Protobuf定义),包含核心字段:message TextChatReq { int32 from_uid = 1; // 发送者UID:10001 int32 to_uid = 2; // 接收者UID:10002 string content = 3; // 消息内容:"Hi!" int64 timestamp = 4; // 发送时间戳:1718000000000(毫秒) string msg_id = 5; // 消息唯一ID:"uuid-123456"(避免重复) } - Protobuf序列化:将
TextChatReq对象转为二进制字节流(体积比JSON小50%); - TCP粘包处理:添加4字节“长度前缀”(大端序),表示后续二进制流的字节数(如消息共100字节,前缀为
0x00 0x00 0x00 0x64),避免服务端拆包错误(day16核心处理); - 异步发送:通过
QTcpSocket(客户端)或asio::ip::tcp::socket(服务端)异步发送数据,不阻塞客户端UI线程。
2. 步骤2:ChatServer1接收并处理消息(拆包+解析+定位)
ChatServer1的Session对象(绑定客户端A)通过async_read(day16)接收消息,执行三步核心处理:
- 拆包:先读取4字节长度前缀,解析出二进制消息的实际长度N,再读取N字节数据,分离出Protobuf字节流;
- 反序列化:将字节流反序列化为
TextChatReq对象,获取from_uid(10001)、to_uid(10002)等关键信息; - 定位接收方Session:调用
UserMgr::GetSession(to_uid)(day17),从ChatServer1的本地_sessions集合(存储所有在线客户端连接)中,找到用户B对应的SessionB。- 若找到
SessionB:进入下一步转发; - 若未找到(用户B离线):将消息存入MySQL离线消息表(day31扩展),待B上线后拉取。
- 若找到
3. 步骤3:ChatServer1转发消息到客户端B
ChatServer1通过SessionB的异步发送接口,将消息推送给客户端B:
- 封装响应消息:ChatServer1不直接转发
TextChatReq,而是封装为TextChatRsp(或TextChatNotify),包含“发送者信息、消息内容、时间戳”,确保客户端B能直接解析展示; - 序列化与发送:重复步骤1的“Protobuf序列化+长度前缀”流程,通过
SessionB的async_write将消息发送到客户端B; - 发送确认:ChatServer1向客户端A返回“消息已送达”的
TextChatRsp(code=0),客户端A界面显示“已送达”状态(day22气泡状态更新)。
4. 步骤4:客户端B接收并展示消息
客户端B的TcpManager接收消息后,完成“解析→校验→展示”:
- 拆包与反序列化:同步骤2,先拆长度前缀,再反序列化为
TextChatNotify对象; - 合法性校验:检查
from_uid是否在好友列表(day26),避免接收陌生人消息(可选,按业务需求); - 界面展示:调用QT界面接口,在气泡对话框中添加用户A的消息气泡,显示内容、发送时间(day22的UI渲染逻辑)。
三、跨服场景:两个客户端在不同ChatServer(需gRPC转发)
若客户端A在ChatServer1、客户端B在ChatServer2,消息需通过gRPC跨服转发(day27),流程比单服多“跨服定位”和“gRPC转发”两步,具体差异步骤如下:
1. 差异步骤1:ChatServer1定位ChatServer2(查Redis)
ChatServer1执行步骤2时,若UserMgr::GetSession(to_uid)未找到SessionB(说明B不在本地),则:
- 查Redis在线状态:调用
RedisMgr::Get("uip:" + to_string(to_uid))(day27),获取用户B所在的ChatServer地址(如“ChatServer2,IP=192.168.1.102,gRPC端口=50051”); - 判断离线:若Redis无
uip:10002记录,判定B离线,存入离线消息表;若有记录,进入跨服转发。
2. 差异步骤2:ChatServer1通过gRPC转发消息到ChatServer2
ChatServer1通过ChatGrpcClient(day27)调用ChatServer2的ForwardTextChat gRPC接口,转发消息:
- 封装gRPC请求:将
TextChatReq封装为gRPC请求对象(与Protobuf定义兼容); - gRPC调用:通过gRPC连接池(day27
ChatConPool)复用连接,发送请求到ChatServer2的gRPC服务端; - 断线重连:若gRPC调用失败(如ChatServer2临时不可用),触发断线重连逻辑(缓存消息,重连后重试,参考之前gRPC重连方案)。
3. 差异步骤3:ChatServer2转发消息到客户端B
ChatServer2的gRPC服务端接收请求后,流程与单服场景一致:
- 反序列化gRPC请求为
TextChatReq; - 调用
UserMgr::GetSession(to_uid)找到SessionB; - 封装
TextChatNotify,发送到客户端B; - 通过gRPC向ChatServer1返回“转发成功”响应。
四、聊天功能的可靠性保障(项目关键设计)
为确保“消息不丢失、不重复、有序”,llfcchat项目在聊天流程中加入以下保障机制:
- TCP可靠性:基于TCP长连接传输,确保消息不丢包、按序到达(底层协议保障);
- 消息唯一ID:每个消息的
msg_id(UUID)唯一,客户端和服务端通过msg_id去重,避免重复接收; - 离线消息存储:接收方离线时,消息存入MySQL
offline_msg表,上线后通过“拉取离线消息”接口获取(day31扩展); - 发送确认机制:服务端转发/送达后,向发送方返回确认响应,客户端根据响应更新消息状态(“发送中→已送达→已读”);
- 心跳保活:通过day35的心跳逻辑维持TCP连接,避免“假死连接”导致消息无法发送,断连后客户端自动重连(day15)。
五、总结:聊天功能的核心逻辑
两个客户端的聊天功能本质是“客户端→服务端→客户端的中转流程”,核心依赖三大支柱:
- 连接层:TCP长连接保障消息传输通道,asio异步IO支撑高并发;
- 协议层:Protobuf定义消息格式,长度前缀解决粘包;
- 业务层:服务端Session管理定位用户,Redis存储在线状态,gRPC实现跨服转发;
- 单服与跨服的差异仅在于“是否需要gRPC跨服转发”,其他核心流程完全一致,确保业务逻辑复用。
27.服务器如何确定用户连接到哪个聊天服务器(用户状态管理)
结合llfcchat项目全周期文档(day27“分布式服务设计”、day09“Redis服务”、day17“Session管理”、day35“心跳逻辑”),服务器确定用户连接到哪个ChatServer的核心是**“StatusServer(状态管理服务器)主导的全局状态管理”**,通过“Redis存储映射+ChatServer上报负载+StatusServer动态分配”的闭环实现,用户状态管理则覆盖“连接、在线、断连”全生命周期,具体逻辑如下:
一、核心基础:用户状态的“全局存储载体”(Redis)
要确定用户所属ChatServer,首先需要一个“跨服务共享的状态中心”,项目选择Redis作为载体,存储两类关键数据,这是所有状态管理的基础(day09 Redis服务落地):
| 数据类型 | Redis键设计 | 存储内容示例 | 作用说明 | 过期策略 |
|---|---|---|---|---|
| 用户-服务器映射 | uip:{uid}(uid为用户ID) | uip:10001 → chatserver2 | 记录用户当前连接的ChatServer名称/IP+端口 | 60秒(2倍心跳周期,day35) |
| ChatServer负载情况 | LOGIN_COUNT(哈希类型) | field:chatserver1 → value:3200 | 记录每个ChatServer的当前TCP连接数 | 永不过期(实时更新) |
| 用户心跳时间戳 | heartbeat:{uid} | heartbeat:10001 → 1718000000000 | 辅助判断用户是否在线(超时则标记离线) | 60秒(与uip:{uid}同步) |
- 核心逻辑:所有服务(GateServer/StatusServer/ChatServer)都通过读写Redis的这三类键,获取用户状态与服务器负载,实现“全局数据一致”。
二、核心流程1:用户登录时——StatusServer分配ChatServer(确定初始连接)
用户首次登录时,由StatusServer根据“ChatServer负载”分配目标节点,这是确定用户所属ChatServer的起点,对应day14“登录功能”与day27“分布式负载均衡”:
1. 步骤1:ChatServer主动上报负载(StatusServer感知节点)
所有ChatServer启动后,会定期(每5秒)向Redis上报自身负载,确保StatusServer能获取最新连接数:
- 上报逻辑:ChatServer调用
RedisMgr::HIncrBy("LOGIN_COUNT", server_name, 0)(day09 Redis API),实际是“先获取当前连接数,再更新到Redis”(或直接用HSET写入实时连接数); - 示例:ChatServer1当前有3200个连接,执行
HSET LOGIN_COUNT chatserver1 3200,Redis哈希LOGIN_COUNT中就记录了该节点的负载。
2. 步骤2:GateServer请求StatusServer分配节点(登录流程关键)
用户通过GateServer登录时(day14),GateServer不直接分配ChatServer,而是向StatusServer发起请求,由StatusServer决策:
- 请求接口:GateServer调用StatusServer的
GetChatServergRPC接口(day27核心接口),传入用户UID(可选,用于特殊场景如“用户固定连接某节点”); - 分配算法:StatusServer的核心逻辑是“选择连接数最少的健康ChatServer”,具体步骤:
- 读取Redis哈希
LOGIN_COUNT,获取所有ChatServer的连接数(如chatserver1:3200、chatserver2:2800、chatserver3:3500); - 过滤“不健康节点”(如10秒内未上报负载的ChatServer,标记为离线);
- 选择连接数最小的节点(如chatserver2,2800连接);
- 返回该ChatServer的IP+端口(如
192.168.1.102:8090)给GateServer。
- 读取Redis哈希
3. 步骤3:用户连接目标ChatServer,更新状态映射
用户从GateServer获取ChatServer地址后,通过TcpManager(day15)建立TCP长连接,连接成功后:
- ChatServer更新Redis:ChatServer调用
RedisMgr::Set("uip:{uid}", server_name, 60)(day27),将“用户UID-自身名称”的映射存入Redis,设置60秒过期(与心跳周期联动); - ChatServer更新本地Session:ChatServer创建
Session对象(day17),绑定用户UID与TCP连接,存入本地_sessions集合(供后续消息转发定位); - 示例:用户10001连接ChatServer2后,Redis中
uip:10001设为chatserver2,过期时间60秒。
三、核心流程2:用户在线时——状态同步与保活(维持映射有效)
用户连接ChatServer后,需通过“心跳机制”维持Redis映射的有效性,避免因映射过期导致“跨服消息找不到用户”,对应day35“心跳逻辑”:
1. 客户端主动发送心跳,ChatServer更新状态
- 客户端心跳:客户端每30秒发送一次心跳包(
MSG_HEARTBEAT),携带用户UID; - ChatServer更新Redis:ChatServer收到心跳后,调用
RedisMgr::Set("uip:{uid}", server_name, 60),重置过期时间为60秒(相当于“续期”),同时更新heartbeat:{uid}为当前时间戳; - 核心作用:若用户在线,
uip:{uid}的过期时间会持续被重置,始终保持有效;若用户断连,60秒后映射自动过期,避免“僵尸映射”。
2. StatusServer被动感知状态(无需主动轮询)
StatusServer不主动轮询用户状态,而是在“需要时(如跨服消息查询)”才读取Redis的uip:{uid}:
- 查询逻辑:当ChatServerA需要给用户10002转发跨服消息时,先调用
RedisMgr::Get("uip:10002"),若返回chatserver2,则通过gRPC转发到ChatServer2; - 离线判断:若
uip:10002不存在(已过期),则判定用户离线,将消息存入MySQL离线消息表(day31扩展)。
四、核心流程3:用户断连时——状态清理(删除无效映射)
用户主动退出或异常断连(如网络断开)时,需及时清理Redis映射与本地Session,避免资源浪费与状态混乱,对应day17“ClearSession”逻辑:
1. 主动退出:客户端发送“退出请求”
用户点击“退出登录”时,客户端发送LogoutReq,ChatServer收到后执行:
- 清理本地Session:调用
ClearSession(day17),从_sessions中删除用户的Session,关闭TCP连接; - 清理Redis映射:调用
RedisMgr::Del("uip:{uid}")(day27),主动删除Redis中的用户-服务器映射; - 更新负载:调用
RedisMgr::HDecrBy("LOGIN_COUNT", server_name, 1),将自身连接数减1,同步到Redis。
2. 异常断连:ChatServer被动检测
若用户因网络波动断连(如WiFi断开),ChatServer通过以下方式检测并清理:
- IO错误回调:
asio::socket的errorOccurred回调(day16)触发,捕获“连接重置”“EOF”等错误,判定断连; - 心跳超时检测:ChatServer每10秒遍历本地
_sessions,若某用户超过60秒无心跳(当前时间 - heartbeat:{uid} > 60),判定为异常断连,执行ClearSession,并清理Redis映射; - 核心作用:即使用户异常断连,也能通过“被动检测+超时清理”确保状态一致。
五、特殊场景:用户多端登录与踢人(状态强制更新)
当用户在多设备登录(如手机+电脑),项目需通过“踢人逻辑”确保账号唯一性,此时需强制更新用户状态,对应day33“单服踢人逻辑”与day34“多服踢人逻辑”:
1. 单服多端登录:同一ChatServer踢旧连接
用户在设备A登录ChatServer2后,又在设备B登录同一ChatServer2:
- ChatServer2查询本地
_sessions,发现用户10001已有Session(设备A); - 调用
ClearSession断开设备A的连接,清理设备A的Session; - 保留设备B的Session,更新Redis
uip:10001(仍为chatserver2,无需变更,但会重置过期时间)。
2. 跨服多端登录:StatusServer联动踢人
用户在设备A登录ChatServer2后,又在设备B登录ChatServer3:
- ChatServer3建立连接时,更新Redis
uip:10001为chatserver3(覆盖旧映射); - 当ChatServer2的心跳检测发现“用户10001的Redis映射已变为chatserver3”(可选逻辑,或通过StatusServer通知),判定用户已在其他节点登录,断开设备A的连接;
- 核心逻辑:Redis的
uip:{uid}是“全局唯一映射”,新登录会覆盖旧映射,旧节点通过心跳或查询感知变化,主动踢人。
六、总结:用户状态管理的“闭环逻辑”
服务器确定用户所属ChatServer的核心是“Redis全局映射+StatusServer分配+ChatServer实时维护”,整个状态管理形成闭环:
- 登录分配:StatusServer按负载分配ChatServer,ChatServer写入Redis映射;
- 在线保活:客户端心跳触发Redis映射续期,维持状态有效;
- 跨服查询:服务端通过Redis映射定位用户所属ChatServer;
- 断连清理:主动/被动断连时,清理Redis映射与本地Session;
- 多端登录:新登录覆盖Redis映射,旧节点感知后踢人。
这一逻辑完全贴合llfcchat的分布式架构,确保即使多ChatServer部署,也能精准定位用户、高效转发消息,同时避免状态混乱。
28.如何实现发送验证码功能
结合llfcchat项目文档(day08“邮箱认证服务”、day09“Redis服务”、day11“注册功能”),发送验证码功能核心围绕“随机生成→安全存储→异步发送→防刷控制”四步实现,主要用于用户注册、密码重置等场景,确保身份真实性。方案完全贴合项目技术栈(C++、Redis、SMTP邮件服务),具体实现如下:
一、核心前提:验证码的应用场景与技术选型
在llfcchat中,验证码主要用于“用户注册”(验证邮箱有效性)和“密码重置”(验证账号归属),技术选型需满足“安全、高效、易集成”:
- 验证码类型:6位纯数字(用户易输入,避免字母大小写混淆);
- 存储介质:Redis(支持过期时间自动清理,避免数据库冗余);
- 发送渠道:SMTP邮件(项目day08明确“邮箱认证”,后期可扩展短信);
- 发送方式:异步发送(避免阻塞注册/重置流程,提升用户体验)。
二、发送验证码的完整流程(四步闭环)
以“用户注册时发送邮箱验证码”为例,流程由AuthServer(认证服务器)主导,联动Redis、SMTP服务,具体步骤如下:
1. 步骤1:业务触发与参数校验(客户端→AuthServer)
用户在客户端输入邮箱并点击“获取验证码”,触发验证码发送请求,AuthServer先做参数合法性校验,避免无效请求:
- 客户端请求:通过HTTP POST请求(day04 Beast HTTP)发送“邮箱地址”到AuthServer,请求体示例(JSON):
{ "email": "user@163.com", "scene": "register" // 场景:register(注册)/reset_pwd(密码重置) } - AuthServer校验:
- 邮箱格式校验(正则表达式:
^[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(\.[a-zA-Z0-9_-]+)+$),过滤无效邮箱; - 场景合法性校验(仅支持
register/reset_pwd),避免非法场景请求; - 防刷校验(关键!):查询Redis中“该邮箱的最近发送时间”,若1分钟内已发送过,直接返回“发送频繁”,拒绝重复请求。
- 邮箱格式校验(正则表达式:
2. 步骤2:生成随机验证码并存储到Redis(AuthServer→Redis)
校验通过后,AuthServer生成验证码并存储到Redis,确保后续验证时可查询且不重复:
- 生成6位随机验证码:用C++的
std::random_device(硬件随机数)生成,避免伪随机导致的安全风险,代码示例:#include <random> #include <string> std::string GenerateVerifyCode() { const std::string digits = "0123456789"; std::random_device rd; std::mt19937 gen(rd()); std::uniform_int_distribution<> dis(0, digits.size() - 1); std::string code; for (int i = 0; i < 6; ++i) { // 固定6位数字 code += digits[dis(gen)]; } return code; } - 存储到Redis:
- 键设计:按“场景+邮箱”唯一标识,格式为
verify:code:{scene}:{email},如verify:code:register:user@163.com(避免不同场景验证码冲突); - 值与过期时间:值为生成的6位验证码,过期时间设为5分钟(足够用户查收,避免长期有效导致安全风险);
- 记录发送时间:同时存储“该邮箱的最近发送时间”,键为
verify:send:time:{email},值为当前时间戳(毫秒),过期时间1分钟(用于防刷); - Redis操作代码(基于day09
RedisMgr):std::string code = GenerateVerifyCode(); std::string code_key = "verify:code:" + scene + ":" + email; std::string time_key = "verify:send:time:" + email; // 存储验证码(5分钟过期) RedisMgr::Inst().Set(code_key, code, 300); // 存储发送时间(1分钟过期,用于防刷) RedisMgr::Inst().Set(time_key, std::to_string(GetCurrentTimestamp()), 60);
- 键设计:按“场景+邮箱”唯一标识,格式为
3. 步骤3:异步发送验证码到用户邮箱(AuthServer→SMTP服务)
为避免SMTP发送耗时(通常100-500ms)阻塞注册流程,AuthServer采用“异步线程池”发送邮件,核心是集成SMTP客户端库(如libcurl或OpenSSL):
- SMTP服务配置:项目需提前配置邮箱服务器信息(以163邮箱为例):
配置项 示例值 说明 SMTP服务器地址 smtp.163.com邮箱服务商的SMTP地址 SMTP端口 465(SSL加密) 加密端口,避免明文传输账号密码 发件人邮箱 llfcchat_service@163.com项目专用的服务邮箱 发件人授权码 ABCDEFGHIJKLMNOP邮箱开启SMTP后生成的授权码(非登录密码) - 构造邮件内容:邮件主题和正文需明确“场景+验证码+有效期”,示例:
std::string BuildEmailContent(const std::string& code, const std::string& scene) { std::string subject = (scene == "register") ? "llfcchat注册验证码" : "llfcchat密码重置验证码"; std::string content = "您好!您的" + subject + "为:<strong>" + code + "</strong>,有效期5分钟,请尽快输入验证。\n若不是您本人操作,请忽略此邮件。"; // 返回“主题+正文”(需符合SMTP邮件格式,支持HTML渲染验证码加粗) return subject + "|" + content; } - 异步发送(线程池):将发送任务投递到AuthServer的“异步任务线程池”(参考day27线程池设计),避免阻塞主线程:
// 从线程池获取空闲线程执行发送任务 AsyncThreadPool::Inst().AddTask([=]() { // 初始化SMTP客户端 SMTPClient client("smtp.163.com", 465, "llfcchat_service@163.com", "ABCDEFGHIJKLMNOP"); // 构造邮件 std::string email_info = BuildEmailContent(code, scene); std::string subject = email_info.substr(0, email_info.find("|")); std::string content = email_info.substr(email_info.find("|") + 1); // 发送邮件 bool send_success = client.SendEmail(email, subject, content); // 发送失败处理(可选:记录日志、重试1次) if (!send_success) { std::cout << "Send verify code to " << email << " failed, retry once" << std::endl; client.SendEmail(email, subject, content); // 仅重试1次,避免无限重试 } }); - 客户端响应:AuthServer无需等待邮件发送结果,立即向客户端返回“验证码已发送,请注意查收”(HTTP响应
code=0),提升用户体验。
4. 步骤4:验证码验证(后续流程,确保有效性)
用户收到邮件并输入验证码后,AuthServer需验证验证码正确性,这是发送流程的“闭环”:
- 客户端提交验证请求:发送“邮箱+场景+输入的验证码”到AuthServer;
- AuthServer验证:
- 拼接Redis键
verify:code:{scene}:{email},查询存储的正确验证码; - 若Redis键不存在(已过期),返回“验证码已过期”;
- 若输入的验证码与存储的一致,验证通过,立即删除Redis中的验证码键(避免重复使用);
- 若不一致,返回“验证码错误”;
- 拼接Redis键
- 验证通过后:注册场景→创建用户账号(day11);密码重置场景→允许修改密码。
三、关键优化:安全与体验保障(项目必做)
为避免验证码被恶意利用或影响用户体验,需加入以下优化机制:
- 防刷控制:
- 同一邮箱1分钟内最多发送1次验证码(通过Redis
verify:send:time:{email}控制); - 同一IP地址1小时内最多发送10次验证码(记录IP的发送次数,Redis键
verify:send:ip:{ip},过期时间3600秒),防止恶意注册机。
- 同一邮箱1分钟内最多发送1次验证码(通过Redis
- 过期自动清理:
- 验证码存储到Redis时设置5分钟过期,过期后自动删除,无需手动清理;
- 发送时间记录设置1分钟过期,自动释放Redis资源。
- 错误日志与监控:
- 记录验证码发送成功/失败日志(包含邮箱、场景、时间),便于排查问题(day30日志排查);
- 若某邮箱连续3次发送失败,触发告警(如邮件通知运维),检查SMTP服务是否正常。
- 用户体验优化:
- 客户端显示“验证码已发送至xxx@163.com,5分钟内有效”,明确提示;
- 提供“重新获取”按钮,点击时先触发防刷校验,通过后重新执行发送流程。
四、关联项目模块:复用现有能力
发送验证码功能无需从零开发,可复用llfcchat的现有模块:
- Redis存储:复用day09
RedisMgr,无需重新封装Redis操作; - 异步线程池:复用day27“业务线程池”,或单独创建轻量级异步线程池;
- HTTP请求处理:复用day04 Beast HTTP服务器,接收客户端请求;
- 日志系统:复用项目日志模块(如day30的日志打印),记录发送与验证日志。
29.为什么需要网关服务,没有行不行,以什么标准进行服务拆分呢
结合llfcchat项目的架构演进(从单服到分布式,day01→day27),网关服务(GateServer)是分布式架构的“基础设施组件”,而非可选模块;服务拆分则需遵循“业务职责、数据边界、性能需求”三大核心标准,确保模块高内聚、低耦合。具体分析如下:
一、为什么需要网关服务?—— 分布式架构的“刚需”
在llfcchat的分布式场景(多ChatServer、AuthServer、StatusServer协同)中,网关服务(GateServer,day04/day27)的核心价值是**“统一入口、集中管控、解耦客户端与后端”**,具体作用可拆解为5点,每点均贴合项目实际需求:
1. 统一接入入口:简化客户端复杂度
- 问题背景:分布式架构下,后端有多个服务(AuthServer负责认证、StatusServer负责负载均衡、ChatServer负责聊天),若没有网关,客户端需知道所有服务的IP和端口(如AuthServer的8080端口、StatusServer的8081端口),才能发起对应请求;
- 网关解决:GateServer作为“唯一公网入口”,客户端只需知道GateServer的地址(如192.168.1.100:80),所有请求(登录、注册、获取ChatServer地址)均发送到GateServer,再由GateServer转发到对应后端服务;
- 项目场景:用户登录时(day14),客户端仅需向GateServer发送HTTP请求,无需关心AuthServer和StatusServer的存在,客户端代码复杂度降低60%(无需维护多服务地址列表)。
2. 路由转发:按请求类型分发到对应服务
- 问题背景:后端服务各司其职(AuthServer管认证、StatusServer管负载),若客户端直接请求,需手动判断“该给哪个服务发”,逻辑冗余;
- 网关解决:GateServer内置“路由规则”,根据请求类型(如URL、请求头)自动转发:
- 路径
/api/login→转发到AuthServer(认证登录); - 路径
/api/get_chat_server→转发到StatusServer(获取ChatServer地址); - 路径
/api/register→转发到AuthServer(用户注册);
- 路径
- 项目场景:day27分布式设计中,GateServer通过“请求路径匹配”,将登录请求转发到AuthServer,校验通过后再向StatusServer请求负载节点,客户端完全无感知转发逻辑。
3. 安全管控:集中防御,避免服务直接暴露
- 问题背景:后端服务(如AuthServer、ChatServer)若直接暴露公网,易遭受SQL注入、XSS攻击、非法请求(如伪造Token),且每个服务单独做安全防护,代码冗余、维护成本高;
- 网关解决:GateServer作为“安全屏障”,统一处理所有安全逻辑,后端服务无需关心:
- 协议过滤:仅允许HTTP/HTTPS请求,拒绝非法协议(如直接TCP连接);
- 请求校验:校验Token合法性(登录后请求)、参数格式(如邮箱格式、密码强度),过滤SQL注入字符(如将
'替换为''); - IP黑名单:拦截频繁发起恶意请求的IP(如1分钟内100次登录失败的IP);
- 项目场景:用户注册时(day11),GateServer先校验“邮箱格式是否合法”“密码是否包含大小写+数字”,非法请求直接拦截,不转发到AuthServer,减少后端服务压力。
4. 流量控制:全局限流,保护后端服务不被压垮
- 问题背景:高并发场景(如活动日用户集中登录),大量请求直接冲击后端服务(如AuthServer),可能导致服务过载崩溃;
- 网关解决:GateServer实现“全局限流”,按服务/接口设置QPS阈值,超过阈值的请求直接返回“服务繁忙”,不转发到后端:
- 按服务限流:AuthServer的登录接口QPS限制为1000(每秒最多1000次登录请求);
- 按客户端限流:同一IP每秒最多发起10次请求,避免恶意压测;
- 项目场景:day27分布式测试中,若每秒2000个登录请求到达GateServer,GateServer会拦截超出1000QPS的请求,AuthServer仅处理1000次/秒,确保AuthServer稳定运行。
5. 协议转换:适配客户端与后端的协议差异
- 问题背景:客户端可能用HTTP(登录注册),后端服务间用gRPC(如GateServer→StatusServer,day27),协议差异需中间层转换;
- 网关解决:GateServer承担“协议翻译”角色:
- 客户端发送HTTP请求→GateServer转为gRPC请求,转发到StatusServer/AuthServer;
- 后端服务返回gRPC响应→GateServer转为HTTP JSON响应,返回给客户端;
- 项目场景:用户获取ChatServer地址时(day27),客户端发HTTP GET请求,GateServer用gRPC调用StatusServer的
GetChatServer接口,拿到结果后转为JSON返回给客户端,客户端无需适配gRPC协议。
二、没有网关服务行不行?—— 分场景判断,分布式场景必不行
网关并非“所有场景都必需”,但在llfcchat的分布式架构中,没有网关会导致“客户端复杂、服务暴露、管控缺失”三大问题,具体分场景分析:
1. 单服架构(llfcchat初期,仅1个ChatServer):可以没有
- 适用场景:项目初期功能简单,仅需“登录+聊天”,后端只有1个ChatServer(集成认证、聊天功能);
- 可行性:客户端直接连接ChatServer,所有请求(登录、聊天)都发给ChatServer,无需网关转发,架构简单、开发快;
- 局限性:仅适合测试/小范围使用,无法支撑高并发(如1000+用户)和功能扩展(如新增好友模块)。
2. 分布式架构(llfcchat后期,多服务协同):绝对不行
若llfcchat按day27分布式设计部署(AuthServer+StatusServer+多ChatServer),没有网关会导致以下致命问题:
- 客户端复杂度飙升:客户端需维护所有服务的地址(AuthServer:8080、StatusServer:8081、ChatServer1:8090、ChatServer2:8091),且需判断“登录请求发AuthServer、获取ChatServer地址发StatusServer”,代码逻辑混乱,多端(Windows/Android)适配成本高;
- 后端服务暴露风险:AuthServer、StatusServer直接暴露公网,易被攻击(如伪造认证请求),且无法统一防护,每个服务需单独开发安全逻辑,冗余且易遗漏;
- 缺乏全局管控:没有网关的“限流、路由”,高并发时AuthServer可能被登录请求压垮,且无法动态调整服务地址(如ChatServer2下线后,客户端无法自动切换到ChatServer1);
- 项目反例:若没有GateServer,用户登录时需先手动请求AuthServer校验账号,再手动请求StatusServer获取ChatServer地址,最后连接ChatServer——流程繁琐,且一旦AuthServer地址变更,所有客户端需重新配置,完全无法支撑线上使用。
三、以什么标准进行服务拆分?—— 结合llfcchat的4大核心标准
llfcchat的服务拆分(GateServer、AuthServer、StatusServer、ChatServer)并非随意划分,而是遵循“业务职责、数据边界、性能需求、团队组织”四大标准,确保每个服务“高内聚、低耦合”:
1. 核心标准1:按业务职责拆分(最核心原则)
- 定义:将“同一业务领域”的功能聚合到一个服务,不同业务领域拆分为不同服务,避免“一个服务干所有事”;
- llfcchat实践:
- AuthServer:仅负责“用户认证”相关(注册、登录、验证码、密码重置),不涉及聊天、负载均衡;
- ChatServer:仅负责“实时交互”相关(TCP长连接、聊天消息、心跳保活、好友申请),不涉及认证;
- StatusServer:仅负责“状态管理”相关(服务负载统计、用户在线状态、节点分配),不涉及业务逻辑;
- GateServer:仅负责“接入管控”相关(统一入口、路由、限流、安全),不涉及业务处理;
- 优势:服务职责清晰,后期维护时“改ChatServer不影响AuthServer”,避免牵一发动全身。
2. 核心标准2:按数据边界拆分(避免数据耦合)
- 定义:每个服务仅管理“自身业务相关的数据”,不跨服务操作其他服务的核心数据,通过接口交互,确保数据独立性;
- llfcchat实践:
- AuthServer:仅操作“用户账号数据”(MySQL
user表、Redis验证码/Token),不读写聊天记录、好友关系; - ChatServer:仅操作“会话数据”(本地
Session、Redis用户-服务器映射),不读写用户账号密码; - StatusServer:仅操作“服务状态数据”(Redis
LOGIN_COUNT、uip:{uid}),不涉及业务数据;
- AuthServer:仅操作“用户账号数据”(MySQL
- 优势:避免“多服务同时写同一张表”(如
user表仅AuthServer可写),减少数据一致性问题,且数据扩容时可单独针对某服务优化(如AuthServer的MySQL单独分库分表)。
3. 核心标准3:按性能需求拆分(避免性能瓶颈)
- 定义:将“高并发、高性能要求”的功能与“低并发、高耗时”的功能拆分开,避免高耗时功能拖垮核心服务;
- llfcchat实践:
- GateServer:处理“高频轻量请求”(如登录请求、路由转发),用HTTP短连接,单服务可支撑每秒1万+请求;
- ChatServer:处理“长连接、低延迟请求”(如聊天消息),用TCP异步IO,单服务支撑8000+连接;
- AuthServer:处理“中低频、强校验请求”(如注册、密码重置),无需高并发,但需保证数据安全;
- 优势:可针对性优化性能,如ChatServer优化IO线程池(day16)、GateServer优化限流算法,互不影响。
4. 核心标准4:按团队组织拆分(适配协作效率)
- 定义:服务拆分与团队分工匹配,“一个团队负责一个或多个相关服务”,避免跨团队频繁协作;
- llfcchat实践:
- 认证团队:负责AuthServer(注册、登录、验证码);
- 聊天团队:负责ChatServer(长连接、消息转发、好友交互);
- 基础设施团队:负责GateServer、StatusServer(网关、负载均衡、监控);
- 优势:团队内开发、测试、上线流程独立,协作效率高,如认证团队迭代密码重置功能,无需依赖聊天团队。
四、总结:网关与服务拆分的“协同关系”
在llfcchat的分布式架构中,网关服务是“服务拆分的产物”,也是“服务协同的纽带”:
- 没有服务拆分,网关的价值不大;没有网关,服务拆分后的客户端与后端会陷入“混乱交互”;
- 服务拆分遵循“业务、数据、性能、团队”标准,确保每个服务边界清晰;网关则通过“统一入口、路由、安全、限流”,让拆分后的服务高效协同,最终支撑IM系统的“高并发、高可用、可扩展”目标。
30.如何实现断线重连
结合llfcchat项目的技术栈(客户端QT TcpManager、服务端Boost.Asio、Redis状态管理)与核心场景(TCP长连接、实时聊天),断线重连需实现“客户端主动检测+分级重试+状态恢复”,并配合服务端“断线清理+身份快速验证”,确保用户无感知或低感知恢复连接,具体方案如下:
一、核心前提:明确断线场景(触发重连的条件)
在实现重连前,需先定义“哪些情况算断线”,llfcchat中主要有3类场景,对应不同的检测方式:
| 断线场景 | 触发原因 | 客户端检测方式 | 服务端检测方式 | 关联项目模块 |
|---|---|---|---|---|
| 网络波动 | WiFi切换、4G/5G断连、路由器重启 | QTcpSocket错误回调(如ConnectionRefusedError) | asio::socket错误回调(如connection_reset) | day15(TcpManager)、day16(Asio服务器) |
| 服务端临时重启 | ChatServer维护重启、进程崩溃后恢复 | 连接超时(SocketTimeoutError)、connectToHost失败 | 无(服务端重启后旧连接全部失效) | day27(分布式服务) |
| 心跳超时 | 长期无数据传输(如防火墙断开空闲连接) | 超过60秒未收到服务端心跳响应 | 超过60秒未收到客户端心跳(day35) | day35(心跳逻辑) |
二、客户端实现:主动触发重连(核心流程)
客户端是断线重连的“主动方”,需通过“断线检测→重连触发→分级重试→状态恢复”四步实现,核心依赖TcpManager(day15)扩展重连逻辑:
1. 第一步:断线检测(实时感知连接状态)
客户端通过“TCP层错误捕获”和“应用层心跳超时”双重机制,确保不遗漏断线:
(1)TCP层错误捕获(即时检测)
通过QTcpSocket的信号槽,捕获底层TCP错误,直接触发断线处理:
// 客户端TcpManager初始化时绑定信号槽
connect(&_tcp_socket, &QTcpSocket::errorOccurred, this, [this](QAbstractSocket::SocketError err) {
switch (err) {
case QAbstractSocket::ConnectionRefusedError: // 服务端拒绝连接(如重启中)
case QAbstractSocket::RemoteHostClosedError: // 服务端主动关闭连接
case QAbstractSocket::NetworkError: // 网络错误(如WiFi断开)
case QAbstractSocket::SocketTimeoutError: // 连接超时
qDebug() << "TCP disconnected, error:" << err;
on_disconnected(); // 触发断线处理
break;
default:
break;
}
});
// 连接断开信号(主动/被动断开均触发)
connect(&_tcp_socket, &QTcpSocket::disconnected, this, &TcpManager::on_disconnected);
(2)应用层心跳超时(补充检测)
若TCP连接未触发错误(如防火墙静默断开),通过心跳超时感知:
// TcpManager类成员:心跳定时器
QTimer _heartbeat_timer;
qint64 _last_heartbeat_time; // 最后一次收到服务端心跳响应的时间
// 初始化心跳检测
void TcpManager::init_heartbeat_detect() {
_heartbeat_timer.setInterval(1000); // 每秒检测一次
connect(&_heartbeat_timer, &QTimer::timeout, this, [this]() {
// 超过60秒未收到心跳响应,判定断线
if (QDateTime::currentMSecsSinceEpoch() - _last_heartbeat_time > 60000) {
qDebug() << "Heartbeat timeout, trigger reconnect";
on_disconnected();
}
});
_heartbeat_timer.start();
}
// 收到服务端心跳响应时,更新最后心跳时间
void TcpManager::on_heartbeat_rsp() {
_last_heartbeat_time = QDateTime::currentMSecsSinceEpoch();
}
2. 第二步:重连触发(避免重复与频繁重试)
断线后,先清理旧状态,再启动重连流程,核心是“避免并发重连”和“控制重试频率”:
// 断线处理入口
void TcpManager::on_disconnected() {
// 1. 停止心跳检测,避免重复触发
_heartbeat_timer.stop();
// 2. 清理旧连接资源
_tcp_socket.abort(); // 关闭旧连接
_is_connected = false; // 标记连接状态为断开
// 3. 显示UI提示(如“已断开连接,正在重连...”)
emit reconnect_status_changed("reconnecting");
// 4. 启动重连(用单独线程,避免阻塞UI)
if (!_is_reconnecting) {
_is_reconnecting = true;
QThreadPool::globalInstance()->start([this]() {
do_reconnect(); // 执行重连逻辑
_is_reconnecting = false;
});
}
}
3. 第三步:分级重连(先试旧地址,再找新地址)
重连需分“优先连上次的ChatServer”和“失败后找新ChatServer”两级,减少对GateServer的依赖,提升重连速度:
(1)一级重试:连接上次的ChatServer(优先)
断线前,客户端缓存了上次连接的ChatServer地址(IP+端口),优先重试此地址(服务端可能只是临时网络波动,未重启):
// 重连核心逻辑
void TcpManager::do_reconnect() {
int retry_count = 0;
const int max_retry_level1 = 3; // 一级重试(旧地址)最多3次
const int backoff_level1 = 1000; // 一级重试间隔1秒
// 一级重试:连接上次的ChatServer地址
while (retry_count < max_retry_level1 && !_is_connected) {
qDebug() << "Level1 reconnect, retry" << retry_count + 1 << ", addr:" << _last_chat_server_addr;
// 连接上次的地址(如"192.168.1.101:8090")
_tcp_socket.connectToHost(_last_chat_server_addr, _last_chat_server_port);
// 等待连接结果(超时3秒)
bool connected = _tcp_socket.waitForConnected(3000);
if (connected) {
// 连接成功,执行身份验证(快速登录)
if (auth_after_reconnect()) {
qDebug() << "Level1 reconnect success";
restore_state(); // 恢复业务状态
return;
}
}
// 连接失败,等待后重试
QThread::msleep(backoff_level1);
retry_count++;
}
// 二级重试:一级失败,通过GateServer获取新ChatServer地址
level2_reconnect();
}
(2)二级重试:通过GateServer获取新地址(兜底)
若一级重试失败(如ChatServer已重启或下线),客户端需重新走“GateServer获取地址”流程(类似首次登录):
void TcpManager::level2_reconnect() {
int retry_count = 0;
const int max_retry_level2 = 5; // 二级重试最多5次
const int backoff_level2 = 2000; // 二级重试间隔2秒(指数退避可优化为1s→2s→4s)
while (retry_count < max_retry_level2 && !_is_connected) {
qDebug() << "Level2 reconnect, retry" << retry_count + 1;
// 1. 向GateServer发送HTTP请求,获取新ChatServer地址(复用登录时的逻辑)
QNetworkRequest req(QUrl("http://" + _gate_server_addr + "/api/get_chat_server"));
req.setHeader(QNetworkRequest::ContentTypeHeader, "application/json");
QJsonObject req_body;
req_body["uid"] = _user_uid; // 携带用户UID,GateServer无需重新认证(用缓存的Token)
req_body["token"] = _login_token; // 断线前缓存的登录Token
QNetworkReply* reply = _network_manager.post(req, QJsonDocument(req_body).toJson());
if (reply->waitForFinished(3000)) { // 等待响应超时3秒
QJsonObject rsp_body = QJsonDocument::fromJson(reply->readAll()).object();
if (rsp_body["code"].toInt() == 0) {
// 2. 解析新ChatServer地址
QString new_addr = rsp_body["chat_server_ip"].toString();
int new_port = rsp_body["chat_server_port"].toInt();
_last_chat_server_addr = new_addr;
_last_chat_server_port = new_port;
// 3. 连接新地址
_tcp_socket.connectToHost(new_addr, new_port);
if (_tcp_socket.waitForConnected(3000) && auth_after_reconnect()) {
qDebug() << "Level2 reconnect success";
restore_state();
return;
}
}
}
// 失败重试,间隔递增(优化为指数退避)
QThread::msleep(backoff_level2 * (1 << retry_count));
retry_count++;
}
// 所有重试失败,提示用户
emit reconnect_status_changed("reconnect_failed");
qDebug() << "All reconnect failed, please check network";
}
4. 第四步:身份验证与状态恢复(重连后无感知)
重连成功后,需快速完成身份验证(避免用户重新输入账号密码),并恢复断线前的业务状态:
(1)快速身份验证(用缓存的Token)
重连后,客户端不重新走完整登录流程,而是用断线前缓存的login_token(day14)向ChatServer验证身份:
// 重连后的身份验证
bool TcpManager::auth_after_reconnect() {
// 封装快速认证请求(Protobuf)
QuickAuthReq req;
req.set_uid(_user_uid.toInt());
req.set_login_token(_login_token.toStdString());
// 序列化并发送
QByteArray req_data = serialize_proto(req); // 自定义Protobuf序列化函数
send_data(req_data); // 发送数据(带4字节长度前缀,day16格式)
// 等待认证响应(超时3秒)
if (_tcp_socket.waitForReadyRead(3000)) {
QByteArray rsp_data = read_data(); // 读取响应(拆包后)
QuickAuthRsp rsp = deserialize_proto<QuickAuthRsp>(rsp_data);
if (rsp.code() == 0) {
_is_connected = true;
_last_heartbeat_time = QDateTime::currentMSecsSinceEpoch();
_heartbeat_timer.start(); // 重启心跳检测
return true;
}
}
return false;
}
(2)业务状态恢复(如拉取离线消息、恢复会话)
身份验证通过后,恢复断线前的用户体验:
// 重连后的状态恢复
void TcpManager::restore_state() {
// 1. 重启心跳发送(每30秒一次,day35逻辑)
start_heartbeat_send();
// 2. 拉取断线期间的离线消息(调用ChatServer接口)
pull_offline_messages();
// 3. 恢复会话列表(如重新获取好友在线状态)
refresh_friend_status();
// 4. 通知UI连接恢复(如更新“已连接”状态,隐藏重连提示)
emit reconnect_status_changed("connected");
qDebug() << "State restored after reconnect";
}
三、服务端配合:被动处理与支持(确保重连有效)
客户端重连需服务端配合,核心是“清理旧连接”和“支持快速认证”,避免状态冲突:
1. 断线检测与旧连接清理
服务端通过Session管理(day17)检测断线,清理无效资源,为新连接腾出空间:
// ChatServer的Session清理逻辑(day17 ClearSession扩展)
void Session::clear() {
// 1. 关闭TCP连接
_socket.close();
// 2. 从UserMgr中删除旧Session(避免重连后找到旧Session)
UserMgr::Inst().RemoveSession(_uid);
// 3. 更新Redis状态(删除旧的uip映射,day27)
RedisMgr::Inst().Del("uip:" + std::to_string(_uid));
// 4. 减少ChatServer连接数统计
RedisMgr::Inst().HDecrBy("LOGIN_COUNT", _server_name, 1);
qDebug() << "Session cleared, uid:" << _uid;
}
// 心跳超时检测(day35扩展)
void ChatServer::check_heartbeat_timeout() {
auto sessions = UserMgr::Inst().GetAllSessions();
for (auto& session : sessions) {
if (std::time(nullptr) - session->last_heartbeat_time() > 60) {
session->clear(); // 超时60秒,清理旧Session
}
}
}
2. 支持客户端快速认证
服务端需提供QuickAuth接口,验证客户端缓存的login_token,避免重连时重新校验账号密码:
// ChatServer处理快速认证请求
void Session::on_quick_auth(const QuickAuthReq& req) {
QuickAuthRsp rsp;
// 1. 查Redis验证Token有效性(day17,login_token存储在Redis)
std::string cache_token = RedisMgr::Inst().Get("utoken:" + std::to_string(req.uid()));
if (cache_token == req.login_token()) {
// 2. Token有效,绑定Session与UID
_uid = req.uid();
UserMgr::Inst().AddSession(_uid, shared_from_this());
// 3. 更新Redis uip映射(重连后用户可能换了ChatServer)
RedisMgr::Inst().Set("uip:" + std::to_string(_uid), _server_name, 60);
// 4. 返回成功响应
rsp.set_code(0);
} else {
rsp.set_code(1);
rsp.set_msg("token invalid");
}
// 发送响应
send_proto(rsp);
}
四、关键优化:提升重连体验与可靠性
- 指数退避重试:二级重试间隔从1s→2s→4s→8s,避免短时间内频繁请求GateServer/ChatServer,减少服务压力;
- 请求缓存与重发:断线前未发送成功的消息(如聊天消息)缓存到本地队列,重连后自动发送,避免消息丢失;
- UI状态同步:重连过程中显示“重连中(x/y次)”,失败后提示“点击重试”或“检查网络”,提升用户感知;
- Token续期:快速认证时,服务端自动延长
login_token有效期(如从2小时延长至2.5小时),避免重连后Token立即过期。
31.如何获得服务器性能的(测试)
结合llfcchat项目的服务器架构(ChatServer、GateServer、StatusServer)与核心场景(TCP长连接、实时消息、分布式负载),服务器性能测试需围绕“核心指标定义→测试工具选型→场景化测试执行→瓶颈定位”四步展开,确保测试结果贴合生产实际,具体方案如下:
一、先明确:服务器性能测试的核心指标(测什么?)
针对llfcchat的服务器类型(长连接服务、短连接服务、分布式调度服务),需重点关注6类核心指标,不同服务器的指标侧重点不同:
| 指标类别 | 核心定义 | 单位 | 各服务器侧重点 |
|---|---|---|---|
| 并发连接数(CC) | 服务器能稳定承载的最大TCP长连接数 | 个 | ChatServer核心指标(目标:单服8000+) |
| 每秒请求数(QPS) | 服务器每秒能处理的请求次数(短连接/消息) | 次/秒 | GateServer(登录请求QPS目标:1000+)、ChatServer(消息QPS目标:5000+) |
| 响应延迟(Latency) | 请求发起至收到响应的平均时间 | 毫秒(ms) | ChatServer核心指标(消息延迟目标:<20ms) |
| 资源利用率 | CPU、内存、网络带宽的占用率 | % / GB / Mbps | 所有服务器(CPU<80%、内存<85%、带宽<90%为健康值) |
| 错误率 | 失败请求/消息占总请求/消息的比例 | ‰(千分比) | 所有服务器(目标:<1‰) |
| 稳定性(MTBF) | 服务器连续稳定运行的时间 | 小时(h) | 所有服务器(目标:>72h无故障) |
二、测试工具选型(用什么测?)
需根据“服务器类型+测试场景”选择工具,优先选用开源、可自定义脚本的工具,贴合llfcchat的C++/TCP技术栈:
| 测试场景 | 推荐工具 | 核心优势 | 适配服务器类型 |
|---|---|---|---|
| TCP长连接并发测试 | JMeter(自定义Socket脚本)/ SocketBench | 支持模拟大量长连接,可自定义心跳/消息发送逻辑 | ChatServer |
| 短连接QPS测试 | Apache Bench(AB)/ JMeter | 轻量、支持高并发短连接,适合HTTP请求 | GateServer(登录/注册接口) |
| 分布式多客户端压测 | Locust(Python)/ k6 | 支持多节点分布式压测,模拟真实用户分布 | 所有服务器(分布式架构测试) |
| 资源监控 | Prometheus+Grafana / nmon / Windows任务管理器 | 实时监控CPU、内存、带宽,生成可视化图表 | 所有服务器 |
| 性能瓶颈定位 | perf(Linux)/ VisualVM(Java)/ Valgrind(C++) | 分析CPU热点函数、内存泄漏、线程阻塞 | ChatServer(C++核心服务) |
三、场景化测试执行(怎么测?)
按“单服基准测试→分布式压力测试→稳定性测试”的顺序执行,每个场景需模拟llfcchat的真实业务逻辑(如长连接+心跳+消息),避免“空连接测试”(无实际消息交互)导致结果失真。
1. 第一步:单服基准测试(测单台服务器的极限能力)
(1)ChatServer长连接并发测试(核心场景)
测试目标:验证单台ChatServer能承载的最大并发连接数、消息QPS及延迟。
测试步骤:
-
环境准备:
- 服务器:1台(配置:8核CPU、16GB内存、1Gbps带宽,模拟生产环境);
- 压测机:2台(避免单台压测机端口/带宽瓶颈,每台配置4核CPU、8GB内存);
- 工具:SocketBench(自定义脚本,模拟客户端长连接+心跳+消息)。
-
测试执行:
- 阶段1:连接建立(压测机1/2分别向ChatServer建立连接,每次增加1000连接,稳定5分钟后继续,直至连接失败,记录“最大并发连接数”);
- 阶段2:消息发送(在最大连接数的80%(如6400连接)下,每连接每秒发送1条100字节消息,持续30分钟,记录“消息QPS、延迟、错误率”);
- 阶段3:心跳+消息混合(6400连接下,每连接30秒发1次心跳+每秒1条消息,持续1小时,监控资源利用率)。
-
核心脚本示例(SocketBench):
模拟客户端连接后发送心跳+消息的逻辑(伪代码):# SocketBench自定义脚本(Python) def client_task(server_ip, server_port, uid): # 1. 建立TCP连接 sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) sock.connect((server_ip, server_port)) # 2. 发送快速认证请求(复用login_token,模拟重连逻辑) auth_req = pack_quick_auth(uid, login_token) # 自定义Protobuf打包函数 sock.send(auth_req) # 3. 循环发送心跳+消息 while True: # 发送心跳(每30秒1次) time.sleep(30) heartbeat_req = pack_heartbeat(uid) sock.send(heartbeat_req) # 发送消息(每秒1次,随机目标UID) time.sleep(1) msg_req = pack_text_msg(uid, random_to_uid, "test msg") sock.send(msg_req) # 接收响应(避免缓冲区堆积) sock.recv(1024)
(2)GateServer短连接QPS测试
测试目标:验证单台GateServer的HTTP接口(登录/注册)能承载的最大QPS。
测试步骤:
-
环境准备:
- 服务器:1台(4核CPU、8GB内存、1Gbps带宽);
- 压测机:1台(用Apache Bench工具);
- 测试接口:GateServer的
/api/login(POST请求,携带模拟账号密码)。
-
测试执行:
- 用AB工具发起压测:
ab -n 100000 -c 1000 -p login.json -T application/json http://192.168.1.100:80/api/login-n:总请求数(10万次);-c:并发数(1000个并发请求);-p:POST请求的参数文件(模拟100个不同账号循环使用);
- 持续30分钟,记录“QPS、响应延迟、错误率”及CPU/内存占用。
- 用AB工具发起压测:
(3)分布式压力测试(测多服务协同能力)
测试目标:验证llfcchat分布式架构(1 GateServer + 2 StatusServer + 3 ChatServer)的整体性能。
测试步骤:
-
环境准备:
- 服务器集群:GateServer(1台)+ StatusServer(2台,主从)+ ChatServer(3台)+ Redis(1台);
- 压测机:3台(Locust分布式部署,每台模拟5000用户)。
-
测试执行:
- 模拟真实用户流程:压测机1/2/3的用户先通过GateServer登录→获取ChatServer地址→连接ChatServer→发送消息;
- 逐步增加用户数(从5000→10000→15000),每阶段稳定10分钟;
- 监控指标:整体QPS(所有ChatServer消息总和)、StatusServer负载分配均匀性(3台ChatServer连接数差异<10%)、跨服消息延迟。
(4)稳定性测试(测长期运行能力)
测试目标:验证服务器在72小时高负载下的稳定性,排查内存泄漏、资源泄漏问题。
测试步骤:
- 环境准备:单服或分布式环境,负载设为最大性能的70%(如ChatServer 5600连接、消息QPS 3500);
- 测试执行:持续运行72小时,每小时记录1次“资源利用率、错误率、延迟”;
- 关键检查:
- 内存是否持续增长(如每小时增长>100MB,可能存在泄漏);
- CPU是否突然飙升(可能存在线程死锁);
- 错误率是否逐渐升高(可能存在资源耗尽)。
四、性能瓶颈定位(测完后怎么办?)
若测试指标不达标(如延迟>20ms、错误率>1‰),需用工具定位瓶颈,重点排查ChatServer(C++核心服务):
1. CPU瓶颈定位(用perf工具,Linux)
- 执行命令:
perf top -p [ChatServer进程ID],查看CPU占用最高的函数; - 常见瓶颈:
- Asio IO线程池配置不合理(如线程数<CPU核心数,导致IO等待);
- 消息解析逻辑耗时(如Protobuf反序列化未优化,可改用FlatBuffers);
- 锁竞争(如
UserMgr的全局锁,需改为细粒度锁或无锁结构)。
2. 内存瓶颈定位(用Valgrind,C++)
- 执行命令:
valgrind --leak-check=full ./ChatServer,检测内存泄漏; - 常见瓶颈:
Session对象未释放(如断连后未调用ClearSession);- 消息缓冲区未回收(如
std::string频繁创建未复用,可改用对象池)。
3. 网络瓶颈定位(用iftop,Linux)
- 执行命令:
iftop -i eth0(eth0为网卡名),查看带宽占用; - 常见瓶颈:
- 心跳包/日志打印占用过多带宽(可优化心跳周期、减少日志输出);
- 跨服消息转发未压缩(可对Protobuf消息进行ZIP压缩)。
五、测试结果输出(输出什么?)
需生成“测试报告”,包含“指标对比、瓶颈分析、优化建议”,为llfcchat的服务器优化提供依据:
- 指标对比表:将测试结果与目标值对比,标注是否达标;
- 可视化图表:用Grafana生成“CPU/内存/带宽趋势图”“QPS-延迟关系图”;
- 瓶颈清单:列出未达标的指标及对应的瓶颈(如“ChatServer消息延迟25ms,瓶颈为Protobuf反序列化耗时”);
- 优化建议:针对瓶颈给出具体方案(如“将Protobuf改为FlatBuffers,预计延迟降低至15ms”)。
32.tcp长连接的作用
在llfcchat项目的IM场景(实时聊天、心跳保活、好友状态同步)中,TCP长连接是支撑“低延迟、高并发、少资源消耗”的核心技术基础,其核心作用可拆解为5点,每一点都直接适配项目的业务需求,具体如下:
一、核心作用1:大幅减少连接建立/断开的开销,降低消息延迟
TCP连接的建立需“三次握手”(约10-20ms),断开需“四次挥手”(约10-20ms),若用短连接传输每条消息(如聊天消息),会频繁触发握手/挥手,导致消息延迟飙升;而TCP长连接建立后长期保持,仅在用户主动退出或网络异常时断开,从根本上规避了这一问题。
- 项目场景:用户A与B连续发送10条聊天消息(day22气泡对话框),若用短连接,需执行10次“三次握手+发送消息+四次挥手”,总耗时约(20+1+20)ms×10=410ms;若用长连接,仅首次建立连接耗时20ms,后续9条消息直接发送,总耗时仅20+1×9=29ms,延迟降低93%,完全满足IM“实时性”需求(目标延迟<20ms)。
- 关键关联:day15
TcpManager、day16 Asio服务器均围绕“长连接复用”设计,避免频繁创建连接。
二、核心作用2:支持实时双向数据传输,适配IM“即时交互”需求
IM系统需要“客户端→服务器”“服务器→客户端”的双向实时数据传输(如用户发消息、服务器推离线通知),TCP长连接天然支持“全双工通信”(连接建立后,双方可随时发送数据),无需像HTTP短连接那样依赖“客户端主动轮询”(轮询会导致延迟高、资源浪费)。
- 项目场景:
- 客户端主动发送:用户输入文本后,通过长连接立即发送给ChatServer(day22消息发送逻辑);
- 服务器主动推送:用户B离线后收到新消息,上线时ChatServer通过长连接主动推送离线消息(day31扩展逻辑);
- 状态实时同步:用户B修改头像,ChatServer通过长连接向其好友推送“头像更新通知”(day26联系人列表同步)。
- 对比短连接:若用HTTP短连接,客户端需每3秒轮询一次“是否有新消息”,不仅会产生3秒延迟,还会导致每秒数千次无效请求,浪费服务器资源。
三、核心作用3:减少服务器资源占用,支撑高并发连接
单台服务器的端口、文件句柄(Linux)/句柄(Windows)资源有限(如Windows默认每进程句柄数约1万),若用短连接,每个请求都会占用一个临时端口和句柄,释放慢(TIME_WAIT状态默认240秒),服务器很快会因“资源耗尽”无法接收新连接;而TCP长连接一个用户仅占用一个连接资源,资源利用率大幅提升。
- 项目场景:llfcchat单台ChatServer需支撑8000+并发用户(day27分布式设计目标),若用短连接,每个用户每秒发1条消息,需占用8000×1=8000个连接(还不算TIME_WAIT状态的旧连接),极易触发“句柄不足”错误;若用长连接,8000个用户仅占用8000个连接,且无TIME_WAIT堆积,服务器可轻松承载,甚至可扩容至1.5万连接。
- 关键优化:day35心跳逻辑通过“定期保活”维持长连接,避免连接被路由器/防火墙误判为“空闲”断开,进一步减少连接重建次数。
四、核心作用4:便于维护用户状态,简化业务层逻辑
IM系统需紧密关联“用户身份”与“连接状态”(如通过UID找到对应连接,实现消息转发),TCP长连接可与Session对象(day17)绑定,形成“1个用户→1个Session→1个长连接”的稳定映射,业务层无需每次处理消息都重新“认证用户+查找连接”,逻辑大幅简化。
- 项目场景:
- 连接建立时:用户登录后,ChatServer创建
Session,绑定UID与长连接,存入UserMgr(day17); - 消息转发时:ChatServer收到“用户A→用户B”的消息,直接通过
UserMgr::GetSession(B的UID)找到B的长连接,无需重新查询用户位置; - 断连处理时:长连接断开后,
Session触发ClearSession,自动更新用户在线状态(Redisuip:{uid}删除,day27)。
- 连接建立时:用户登录后,ChatServer创建
- 对比短连接:若用短连接,每次消息都需携带UID和Token,服务器每次都要验证身份、查询用户当前连接,不仅增加网络传输量,还会导致业务代码冗余(重复的认证、查询逻辑)。
五、核心作用5:适配复杂业务场景,降低扩展难度
llfcchat的核心业务(如文件分块传输、心跳保活、跨服消息转发)均依赖“连接持续存活”的特性,TCP长连接为这些场景提供了稳定的传输通道,避免因连接断开导致业务中断。
- 项目场景举例:
- 文件分块传输(day31扩展):100MB文件拆分为20个5MB分块,通过长连接连续传输,若用短连接,每块需重新建立连接,极易因连接中断导致分块丢失,需额外处理“断点续传”的复杂逻辑;
- 心跳保活(day35):客户端每30秒通过长连接发送心跳包,服务器通过“是否收到心跳”判断用户是否在线,若用短连接,需额外设计“离线状态同步机制”(如Redis定时清理),复杂度翻倍;
- 跨服消息转发(day27):用户A(ChatServer1)向用户B(ChatServer2)发消息,ChatServer2通过长连接将消息推送给B,若用短连接,需B主动轮询ChatServer2,延迟高且体验差。
总结:TCP长连接是llfcchat的“业务基石”
TCP长连接并非“可选优化”,而是llfcchat实现IM核心需求的必要条件——没有长连接,就无法满足“实时聊天(低延迟)、高并发用户(少资源)、复杂业务(如文件传输)”的需求,甚至无法构建完整的IM系统。其作用可概括为:以“一次连接复用”为核心,兼顾实时性、资源效率与业务扩展性,是项目从“单用户测试”走向“多用户生产环境”的关键支撑。
33.如何解决大量tcp连接的性能问题,如果用户登录后长时间没有请求(心跳机制),如果又突然要发消息了,需要重新登陆吗
结合llfcchat项目的高并发场景(单服8000+TCP连接)与核心机制(心跳保活、Token认证),针对“大量TCP连接性能问题”和“长时间无请求后是否重登”的问题,解决方案如下:
一、如何解决大量TCP连接的性能问题?—— 从“内核、IO模型、连接管理、资源复用”四层优化
大量TCP连接(如万级)的性能瓶颈主要源于“内核参数限制、IO阻塞、资源泄漏、连接闲置”,需通过四层优化适配llfcchat的长连接场景:
1. 第一层:TCP内核参数调优(突破系统限制)
Linux/Windows默认的TCP参数未针对高并发优化,需修改内核配置释放连接承载能力,核心参数如下(以Linux为例):
| 核心参数 | 作用说明 | 推荐配置(万级连接) | 项目关联 |
|---|---|---|---|
net.ipv4.tcp_max_syn_backlog | 半连接队列(SYN_RCVD状态)最大长度,避免连接建立时丢包 | 16384(默认1024) | 解决ChatServer启动时大量用户并发登录导致的“连接超时” |
net.core.somaxconn | 全连接队列(ESTABLISHED状态)最大长度,限制已建立的连接数 | 65535(默认128) | 支撑单服万级TCP连接 |
net.ipv4.tcp_tw_reuse | 允许复用TIME_WAIT状态的端口,减少端口占用 | 1(开启) | 避免短连接(如文件传输临时连接)断开后端口耗尽 |
net.ipv4.tcp_keepalive_time | TCP底层保活探测间隔(默认2小时),缩短闲置连接检测时间 | 300(5分钟) | 配合应用层心跳,快速清理“假死连接”(day35) |
fs.file-max | 系统最大文件句柄数(每个TCP连接对应1个句柄) | 1000000(100万) | 突破默认句柄限制,支撑万级连接 |
- 配置方式:修改
/etc/sysctl.conf,执行sysctl -p生效;llfcchat部署时需将此作为基础环境配置,避免系统层面的性能瓶颈。
2. 第二层:IO模型与线程池优化(提升处理效率)
大量TCP连接的核心是“避免IO阻塞”,需依赖异步IO模型+合理的线程池设计,贴合llfcchat的Asio技术栈:
(1)用“异步IO模型”替代同步IO
- 核心逻辑:采用Boost.Asio的“反应堆模型”(day16),单IO线程可处理数千个连接的“读/写/连接”事件,无需为每个连接创建线程(避免“1连接1线程”的线程爆炸);
- 关键优化:IO线程数设为“CPU核心数”(如8核设8个),每个IO线程绑定独立CPU核心(
pthread_setaffinity_np),减少线程上下文切换开销。
(2)业务与IO线程池隔离
- 问题:若IO线程同时处理“消息读取”和“复杂业务逻辑(如SQL查询)”,会导致IO阻塞,连接响应延迟;
- 解决方案:拆分“IO线程池”和“业务线程池”(day27):
- IO线程池:仅处理TCP连接建立、消息读写(轻量操作);
- 业务线程池:处理消息解析、好友校验、跨服转发(耗时操作);
- 效果:IO线程始终处于“无阻塞”状态,万级连接下消息接收延迟可控制在10ms内。
3. 第三层:连接管理优化(减少资源浪费)
大量连接的性能损耗还源于“闲置连接堆积、Session内存泄漏”,需通过精细化管理优化:
(1)空闲连接主动回收
- 逻辑:对“长时间无业务请求(如1小时)但有心跳”的连接,主动触发“空闲回收”(非强制断开):
- ChatServer记录每个Session的“最后业务请求时间”(如最后一次聊天消息发送时间);
- 定时(每10分钟)遍历Session,若“当前时间 - 最后业务请求时间 > 3600秒”,向客户端发送“空闲提示”;
- 客户端收到提示后,可选择“保持连接”或“主动断开(下次发消息时重连)”;
- 作用:减少闲置连接占用的句柄、内存资源,提升活跃连接的处理效率。
(2)Session内存轻量化
- 问题:每个Session若存储大量冗余数据(如完整用户信息、历史消息缓存),万级连接会占用GB级内存;
- 优化:
- Session仅存储“UID、连接状态、最后心跳时间、最后业务请求时间”等核心字段;
- 用户信息(如昵称、头像)通过UID实时从Redis缓存查询(day09),不常驻Session;
- 效果:每个Session内存占用从1KB降至200B,万级连接仅占用2MB内存。
4. 第四层:资源复用(避免频繁创建销毁)
(1)Socket连接池复用(针对临时连接)
- 场景:文件传输、日志上报等临时TCP连接,若每次创建/销毁会消耗资源;
- 优化:客户端维护“临时Socket连接池”(day31扩展),闲置连接保留30秒,新请求优先复用池内连接,减少三次握手/四次挥手开销。
(2)内存池复用(减少内存碎片)
- 问题:大量连接的消息收发会频繁创建/释放缓冲区(如
std::string),导致内存碎片,影响分配效率; - 优化:使用“内存池”(如
boost::pool)预分配固定大小的缓冲区(如4KB、8KB),消息收发时复用缓冲区,避免频繁内存申请/释放。
二、用户登录后长时间无请求(有心跳),突然发消息需要重新登录吗?—— 无需重登,依赖“心跳保活+Token续期”
只要客户端与服务端的TCP连接未断、Token未过期,即使长时间无业务请求(仅心跳),突然发消息也无需重新登录,核心逻辑依赖“心跳维持连接+Token续期+快速身份验证”:
1. 核心前提:心跳的作用——维持连接与Token续期
- 连接维持:客户端每30秒发送心跳包(day35),ChatServer收到后:
- 确认连接存活,更新Session的“最后心跳时间”;
- 自动续期Token(若Token有效期剩余<30分钟),通过Redis更新
utoken:{uid}的过期时间(从2小时延长至2.5小时);
- 效果:只要心跳正常,连接不会被路由器/防火墙断开,Token也不会过期,客户端始终处于“已登录”状态。
2. 突然发消息时的处理流程(无需重登)
当用户长时间无请求后突然发送消息(如1小时后发“在吗?”),流程如下:
- 客户端:直接封装消息(如
TextChatReq),通过现有TCP长连接发送(无需重新建立连接); - ChatServer接收消息:
- 第一步:验证连接状态(Session是否存在、连接是否正常)——因有心跳,状态正常;
- 第二步:验证Token有效性——通过Session的UID查询Redis的
utoken:{uid},Token未过期(心跳已续期); - 第三步:处理消息(如转发给目标用户),并更新Session的“最后业务请求时间”;
- 结果:消息正常发送,客户端无需任何额外操作(如重新输入账号密码),用户无感知。
3. 特殊情况:需要重新登录的场景
仅以下两种情况需重新登录,与“长时间无请求”无关:
- Token过期:若心跳机制失效(如客户端心跳发送失败),导致Token未续期而过期(如2小时后),此时发送消息会触发“Token无效”,客户端需重新登录;
- 连接断连后重连:若TCP连接因网络波动断开(但Token未过期),客户端重连后通过“快速认证”(day15重连逻辑)验证Token,无需重新输入账号密码(非严格意义上的“重新登录”)。
总结
- 大量TCP连接性能:通过“内核调优突破限制、异步IO+线程池提升效率、连接管理减少浪费、资源复用降低开销”四层优化,可支撑单服万级TCP连接的稳定运行,且消息延迟控制在20ms内;
- 长时间无请求是否重登:只要心跳正常、连接未断、Token未过期,突然发消息无需重新登录,核心依赖“心跳保活+Token续期”,确保用户体验无感知。
34.gatesever是怎么实现的
结合llfcchat项目文档(day04“Beast搭建HTTP服务器”、day14“登录功能”、day27“分布式服务设计”),GateServer(网关服务器)的实现围绕“统一接入、路由转发、安全管控、流量限流”四大核心职能展开,技术栈以“Boost.Beast(HTTP服务)+ gRPC(后端通信)+ Redis(缓存/限流)”为基础,整体架构模块化、低耦合,具体实现方案如下:
一、GateServer核心定位与技术选型
在llfcchat分布式架构中,GateServer是客户端与后端服务(AuthServer/StatusServer)的“中间层”,不处理具体业务逻辑,仅负责“请求接入与分发”。其技术选型完全适配项目需求:
| 核心职能 | 技术选型 | 项目关联模块 |
|---|---|---|
| HTTP服务(客户端接入) | Boost.Beast(轻量、异步,支持HTTP/1.1) | day04“Beast搭建HTTP服务器” |
| 后端服务通信 | gRPC(与AuthServer/StatusServer交互) | day27“分布式服务gRPC调用” |
| 缓存/限流计数 | Redis(存储Token、IP限流计数) | day09“Redis服务”、day32“分布式锁” |
| 异步任务处理 | 轻量级线程池(避免HTTP请求阻塞) | day27“业务线程池”设计思路复用 |
二、GateServer核心模块实现(按职能拆分)
GateServer的实现可拆解为5个独立模块,每个模块职责单一、可复用,便于后期扩展(如新增HTTPS、接口权限控制):
1. 模块1:HTTP服务模块(客户端接入入口)
核心作用是“监听客户端HTTP请求、解析请求数据、封装响应”,是GateServer与客户端交互的唯一通道,基于Boost.Beast实现:
(1)HTTP服务初始化与监听
- 核心逻辑:创建Beast的
tcp::acceptor监听指定端口(如80端口),异步接收客户端连接,避免阻塞; - 关键代码(简化,参考day04):
#include <boost/beast.hpp> namespace beast = boost::beast; namespace http = beast::http; namespace net = boost::asio; using tcp = net::ip::tcp; class GateServer { public: GateServer(net::io_context& ioc, tcp::endpoint endpoint) : acceptor_(ioc, endpoint) { do_accept(); // 启动异步监听 } // 异步接收客户端连接 void do_accept() { acceptor_.async_accept( net::make_strand(acceptor_.get_executor()), beast::bind_front_handler(&GateServer::on_accept, this) ); } // 连接建立后,创建Session处理请求 void on_accept(beast::error_code ec, tcp::socket socket) { if (!ec) { // 为每个客户端连接创建HTTP Session(独立处理请求) std::make_shared<HttpSession>(std::move(socket))->run(); } do_accept(); // 继续监听下一个连接 } private: tcp::acceptor acceptor_; }; // 启动GateServer:监听192.168.1.100:80 int main() { net::io_context ioc(1); // 1个IO线程(可扩展为线程池) tcp::endpoint endpoint(tcp::v4(), 80); GateServer server(ioc, endpoint); ioc.run(); return 0; }
(2)HTTP请求解析与响应
- 核心逻辑:
HttpSession接收客户端HTTP请求(如POST登录请求),解析请求头、请求体(JSON格式),调用“路由模块”处理后,封装JSON响应返回; - 关键处理:
- 仅支持
POST请求(客户端登录、注册、获取ChatServer地址均为POST,避免URL参数泄露); - 强制校验
Content-Type: application/json,非JSON请求直接返回“400 Bad Request”; - 解析请求体:用
nlohmann::json(day05)解析JSON数据,提取关键参数(如username、password)。
- 仅支持
2. 模块2:路由转发模块(请求分发核心)
核心作用是“根据请求类型,将客户端请求转发到对应后端服务(AuthServer/StatusServer)”,是GateServer的“大脑”,基于“URL匹配+服务映射”实现:
(1)路由规则定义
首先定义“请求URL→后端服务”的映射关系,贴合llfcchat业务:
| 客户端请求URL | 对应后端服务 | 业务场景 | 通信协议(GateServer→后端) |
|---|---|---|---|
/api/login | AuthServer | 用户登录校验 | gRPC |
/api/register | AuthServer | 用户注册 | gRPC |
/api/get_chat_server | StatusServer | 获取目标ChatServer地址(负载均衡) | gRPC |
/api/verify_code | AuthServer | 验证码发送/校验 | gRPC |
(2)路由转发实现
- 核心逻辑:解析客户端请求的URL,匹配路由规则,调用对应后端服务的gRPC接口,获取结果后封装为HTTP响应返回给客户端;
- 关键代码(路由处理函数):
// HttpSession的请求处理函数 void HttpSession::handle_request(http::request<http::string_body>& req) { http::response<http::string_body> res(http::status::ok, req.version()); res.set(http::field::content_type, "application/json"); nlohmann::json rsp_json; // 1. 匹配路由(根据URL) std::string target = std::string(req.target()); if (target == "/api/login") { // 2. 转发到AuthServer的Login接口(gRPC调用) AuthGrpcClient client("192.168.1.103:50052"); // AuthServer的gRPC地址 LoginReq login_req; // 从HTTP请求体提取参数,填充login_req nlohmann::json req_json = nlohmann::json::parse(req.body()); login_req.set_username(req_json["username"].get<std::string>()); login_req.set_password(req_json["password"].get<std::string>()); // 调用gRPC接口 LoginRsp login_rsp = client.Login(login_req); // 3. 封装gRPC结果为HTTP响应 rsp_json["code"] = login_rsp.code(); rsp_json["msg"] = login_rsp.msg(); if (login_rsp.code() == 0) { rsp_json["data"]["token"] = login_rsp.token(); // 若登录成功,进一步调用StatusServer获取ChatServer地址 rsp_json["data"]["chat_server"] = get_chat_server_from_status(); } } else if (target == "/api/get_chat_server") { // 转发到StatusServer的GetChatServer接口 rsp_json["data"]["chat_server"] = get_chat_server_from_status(); } else { // 未匹配路由,返回404 res.result(http::status::not_found); rsp_json["code"] = 404; rsp_json["msg"] = "api not found"; } // 4. 发送HTTP响应 res.body() = rsp_json.dump(); res.prepare_payload(); http::write(socket_, res); } // 调用StatusServer获取ChatServer地址(gRPC) nlohmann::json HttpSession::get_chat_server_from_status() { StatusGrpcClient client("192.168.1.104:50053"); // StatusServer的gRPC地址 GetChatServerReq req; GetChatServerRsp rsp = client.GetChatServer(req); nlohmann::json data; data["ip"] = rsp.chat_server_ip(); data["port"] = rsp.chat_server_port(); return data; }
3. 模块3:安全管控模块(防护后端服务)
核心作用是“过滤非法请求、验证身份、防止恶意攻击”,避免后端服务直接暴露在公网,是GateServer的“安全屏障”:
(1)请求参数校验
- 逻辑:对客户端请求的关键参数(如邮箱、密码、Token)进行合法性校验,不通过则直接返回错误,不转发到后端;
- 常见校验规则:
- 邮箱格式:用正则表达式校验(
^[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(\.[a-zA-Z0-9_-]+)+$); - 密码强度:至少8位,包含大小写字母+数字(避免弱密码);
- Token格式:校验Token是否为“JWT格式”(如是否包含
.分隔符)。
- 邮箱格式:用正则表达式校验(
(2)Token身份验证
- 逻辑:对需要登录的请求(如
/api/get_chat_server),校验客户端携带的Token有效性:- 从HTTP请求头
Authorization中提取Token(格式:Bearer {token}); - 调用Redis(day09)查询
utoken:{uid}(Token与UID的映射),若Token不存在或已过期,返回“401 Unauthorized”; - 校验通过后,将UID传递给后端服务(如StatusServer),用于后续业务处理。
- 从HTTP请求头
(3)IP防刷与黑名单
- 逻辑:通过Redis记录“IP的请求次数”,限制单IP的请求频率,避免恶意注册/登录:
- 对
/api/login、/api/verify_code等高频接口,记录“ip_limit:{ip}”的Redis键,值为请求次数,过期时间1分钟; - 每次请求时,先执行
INCR ip_limit:{ip},若结果>10(1分钟内最多10次请求),返回“429 Too Many Requests”; - 对频繁触发防刷的IP(如1小时内被限制10次),加入Redis黑名单(
ip_blacklist:{ip}),24小时内拒绝其所有请求。
- 对
4. 模块4:流量限流模块(保护后端性能)
核心作用是“限制全局或单接口的QPS,避免高并发请求压垮后端服务”,基于“令牌桶算法”实现:
(1)全局QPS限流
- 逻辑:限制GateServer的总HTTP请求QPS(如1万次/秒),超过则拒绝新请求;
- 实现:用Redis的
INCR原子操作记录“全局请求计数”,配合定时任务(每1秒重置计数),简单高效。
(2)单接口QPS限流
- 逻辑:对关键接口(如
/api/login)单独设置QPS阈值(如1000次/秒),避免单一接口过载; - 实现:按“接口+时间片”记录Redis键(如
api_limit:login:202405201530,时间片精确到分钟),计数超过阈值则限流。
5. 模块5:日志与监控模块(问题排查与运维)
核心作用是“记录请求日志、监控服务状态”,便于后期排查问题(day30“日志排查”)和运维:
(1)请求日志记录
- 逻辑:记录每一次HTTP请求的“客户端IP、URL、请求参数、响应码、耗时”,存储到本地日志文件(如
gate_server_20240520.log); - 关键信息:示例日志格式:
[2024-05-20 15:30:01] [IP:192.168.1.200] [URL:/api/login] [Params:{"username":"test","password":"***"}] [Code:0] [Cost:15ms]
(2)服务状态监控
- 逻辑:定时(每10秒)采集GateServer的“当前连接数、QPS、各接口请求量、错误率”,通过HTTP接口暴露给监控系统(如Prometheus);
- 关键指标:
gate_current_connections:当前HTTP连接数;gate_total_qps:全局QPS;gate_api_login_count:/api/login接口的请求总数;gate_error_rate:请求错误率(错误数/总请求数)。
三、GateServer核心业务流程示例(用户登录)
以“用户登录并获取ChatServer地址”为例,完整流程体现GateServer的模块协同:
- 客户端发起请求:发送POST请求到
http://192.168.1.100:80/api/login,请求体含username、password; - HTTP模块处理:Beast接收请求,解析JSON请求体;
- 安全模块校验:校验
username(非空)、password(强度),通过后进入路由; - 路由模块转发:匹配
/api/login,调用AuthServer的gRPCLogin接口; - AuthServer响应:校验账号密码,返回“登录成功”+
token; - 路由模块二次转发:调用StatusServer的gRPC
GetChatServer接口,获取ChatServer的IP+端口; - 封装响应返回:将
token、ChatServer地址封装为JSON,通过HTTP响应返回客户端; - 日志模块记录:记录本次请求的IP、URL、耗时(如15ms)、响应码(0)。
四、GateServer实现的关键优化(贴合项目需求)
- 异步处理:HTTP接收、gRPC调用均为异步(Beast/Asio的异步接口),避免单请求阻塞导致的QPS瓶颈;
- gRPC连接池:复用gRPC客户端连接(day27
ChatConPool思路),避免每次转发都创建新连接,减少握手开销; - 请求体脱敏:日志中对敏感参数(如
password)进行脱敏(替换为***),避免信息泄露; - 故障降级:若AuthServer暂时不可用,返回“服务繁忙,请稍后重试”,不直接暴露后端错误;若StatusServer不可用,返回缓存的ChatServer地址(兜底策略)。
35.asio网络库底层原理
结合llfcchat项目中asio的实际应用(day16“asio TCP服务器”、day15“TcpManager”的异步连接/读写),asio(Boost.Asio/Standalone Asio)的底层核心是**“封装操作系统IO多路复用机制,实现Proactor异步IO模型”**,通过“事件驱动+回调调度”支撑高并发网络通信,其底层原理可拆解为4个核心模块,每个模块均直接适配项目的TCP长连接、低延迟消息处理需求。
一、核心前提:asio的设计目标与模型定位
asio并非“从零实现网络IO”,而是对操作系统底层IO能力的“高级封装”,核心目标是“让开发者用统一的接口编写跨平台(Linux/Windows/BSD)的异步网络代码”,无需关注不同系统的IO多路复用差异。
其底层依赖的核心模型是Proactor模式(区别于Reactor模式),核心特点是:
- 内核负责IO操作执行:数据的“读取/写入”由操作系统内核完成,而非用户线程;
- 用户线程仅处理回调:IO操作完成后,内核通知asio,asio再调度用户提供的回调函数(如
async_read的完成回调); - 这与llfcchat的需求高度契合——ChatServer需处理8000+TCP连接的异步读写,Proactor模式可避免用户线程阻塞在IO等待上,大幅提升并发效率。
二、底层原理1:操作系统IO多路复用机制的封装(跨平台核心)
不同操作系统提供的“高效管理多IO句柄”的机制不同(如Linux的epoll、Windows的IOCP),asio的第一层底层封装就是“统一这些机制的接口”,让上层代码无需修改即可跨平台运行。
| 操作系统 | 底层IO多路复用机制 | asio封装方式 | 项目适配场景 |
|---|---|---|---|
| Linux | epoll | epoll_create/epoll_ctl/epoll_wait | ChatServer的TCP连接管理(day16) |
| Windows | IOCP(完成端口) | CreateIoCompletionPort/GetQueuedCompletionStatus | 客户端TcpManager的异步连接(day15) |
| BSD/macOS | kqueue | kqueue/kevent | 跨平台部署时的兼容支持 |
封装的核心逻辑(以Linux epoll为例):
- 句柄注册:当开发者调用
asio::ip::tcp::acceptor::async_accept或asio::ip::tcp::socket::async_read时,asio会将对应的TCP句柄(socket fd)注册到epoll实例,同时指定要监听的事件(如“读事件”EPOLLIN、“连接事件”EPOLLIN); - 事件等待:asio的
io_context会通过epoll_wait阻塞等待内核通知(有IO事件就绪时,epoll_wait返回就绪句柄列表); - 事件分发:
epoll_wait返回后,asio遍历就绪句柄,找到对应的“未完成异步操作”(如等待读数据的async_read),触发后续处理。
项目关联场景:
day16中ChatServer的asio::ip::tcp::acceptor监听8090端口时,asio底层会将acceptor的fd注册到epoll,监听“新连接到来”事件(EPOLLIN);当客户端发起连接时,epoll通知asio,asio再执行async_accept的回调函数,创建新的Session。
三、底层原理2:Proactor异步IO模型的实现(异步核心)
asio是Proactor模式的经典实现,其异步IO操作(如async_read/async_write/async_accept)的完整流程,是理解底层原理的关键,可拆解为“发起→等待→执行→回调”四步:
以llfcchat的Session::async_read(day16消息读取)为例:
1. 步骤1:用户发起异步操作(async_read)
开发者调用asio::async_read,传入socket、接收缓冲区、完成回调函数,示例代码(项目核心逻辑):
void Session::start_read() {
// 异步读取4字节消息长度前缀
asio::async_read(
socket_,
asio::buffer(read_len_buf_, 4),
[this](std::error_code ec, std::size_t len) {
if (!ec) {
// 读取长度成功后,继续读取消息体
uint32_t msg_len = ntohl(*(uint32_t*)read_len_buf_);
start_read_body(msg_len);
} else {
// 连接异常,清理Session
clear();
}
}
);
}
- 底层动作:
asio会创建一个“异步读操作对象”(read_op),存储以下信息:- 目标
socket的句柄(fd); - 接收缓冲区(
read_len_buf_)的地址和长度; - 用户提供的完成回调函数;
- 操作状态(如“未完成”)。
同时,asio会通过epoll_ctl将socket fd注册到epoll,监听“读事件”(EPOLLIN)。
- 目标
2. 步骤2:内核等待IO就绪(数据到达)
- 此时用户线程(执行
start_read的线程)不会阻塞,而是直接返回,继续处理其他任务(如其他Session的回调); - 内核通过网络卡接收客户端发送的数据,将数据写入
socket的内核接收缓冲区; - 当内核接收缓冲区有数据时,会标记
socket fd的“读事件就绪”,并通过epoll通知asio(epoll_wait返回该fd)。
3. 步骤3:内核执行IO操作(数据拷贝)
- Proactor模式的核心:数据从内核缓冲区到用户缓冲区的拷贝,由内核或asio的“服务线程”完成(非用户线程);
- 对Linux epoll(水平触发):asio检测到
socket fd读事件就绪后,会调用read系统调用,将内核缓冲区的数据拷贝到用户提供的read_len_buf_(4字节长度前缀); - 对Windows IOCP:
async_read发起时,asio会将“读操作”投递到IOCP,内核完成数据拷贝后,会将“完成包”放入IOCP队列,等待asio获取。
4. 步骤4:asio调度回调函数执行
- IO操作完成后(数据成功拷贝到用户缓冲区,或出现错误如
connection_reset),asio会将“完成的异步操作”对应的回调函数,加入io_context的“回调队列”; io_context::run()(项目中io_context.run()是ChatServer的事件循环核心)会从回调队列中取出回调函数,在当前线程执行(即执行async_read的lambda回调,处理长度前缀或清理Session)。
关键区别:Proactor vs Reactor
- Reactor模式(如libevent):内核仅通知“IO就绪”,数据拷贝需用户线程自己执行;
- Proactor模式(asio):内核/asio完成“IO就绪+数据拷贝”,用户线程仅执行回调——这也是asio在高并发场景下(如llfcchat的8000+连接)更高效的原因,减少了用户线程的IO操作开销。
四、底层原理3:io_context——事件循环与回调调度核心
io_context是asio的“大脑”,负责管理所有异步操作的生命周期、IO事件等待、回调函数调度,是项目中ChatServer(day16)和TcpManager(day15)的核心组件。
1. io_context的核心角色:
- IO事件等待器:封装底层IO多路复用(如epoll),通过
io_context::run()阻塞等待IO事件就绪; - 回调队列管理器:维护“待执行的回调函数队列”,IO操作完成后将回调入队;
- 线程调度器:
io_context::run()会循环从回调队列取任务执行,直到队列空且无未完成异步操作(或被stop())。
2. 关键机制:work_guard(避免io_context提前退出)
- 问题:若
io_context没有未完成的异步操作(如所有socket都已断开),io_context::run()会立即返回,导致事件循环退出; - 解决方案:项目中会创建
asio::executor_work_guard(day16代码),绑定到io_context,强制io_context::run()即使无回调也不退出,直到work_guard被销毁; - 项目代码示例:
// day16 ChatServer初始化时,创建work_guard asio::io_context io_context; auto work_guard = asio::make_work_guard(io_context); // 启动IO线程(执行io_context.run()) std::thread io_thread([&]() { io_context.run(); });
3. 多线程与io_context:线程池适配(项目高并发关键)
- 单
io_context多线程:多个线程同时调用io_context::run(),io_context会自动将回调队列的任务分发给多个线程执行,实现“多线程处理回调”; - 项目应用:day27中ChatServer的“IO线程池”设计(8核CPU启动8个线程,均调用
io_context::run()),利用多核CPU并行处理回调,支撑8000+连接的消息回调,避免单线程瓶颈。
五、底层原理4:异步操作的状态管理(避免内存泄漏)
大量异步操作(如llfcchat万级Session的async_read/async_write)若状态管理不当,会导致内存泄漏或野指针问题,asio通过“操作对象生命周期绑定”解决此问题。
1. 异步操作对象的生命周期:
- 每个异步操作(如
async_read)创建的read_op对象,会被asio通过“共享指针”或“内部链表”管理,直到操作完成; - 若
socket被提前关闭(如Session::clear()调用socket_.close()),asio会自动取消对应的未完成异步操作,并触发“操作取消”的错误回调(error_code = asio::error::operation_aborted),避免操作对象泄漏。
2. 项目中的Session与异步操作绑定:
- day17的
Session类通过“共享指针std::shared_ptr<Session>”管理生命周期,async_read/async_write的回调会捕获this的共享指针(如std::enable_shared_from_this<Session>); - 确保在异步操作完成前,
Session对象不会被销毁(避免回调中访问野指针),例如:class Session : public std::enable_shared_from_this<Session> { public: void start_read() { // 捕获shared_from_this(),确保Session在回调执行前不被销毁 auto self = shared_from_this(); asio::async_read( socket_, asio::buffer(buf_), [self](std::error_code ec, std::size_t len) { // 回调中可安全访问self(Session对象) if (!ec) self->process_data(); } ); } };
六、总结:asio底层原理对llfcchat项目的支撑
asio的底层设计完全贴合llfcchat的IM场景需求,核心支撑点如下:
- 跨平台兼容:封装epoll/IOCP,项目可在Linux/Windows部署,无需修改网络核心代码;
- 高并发承载:Proactor模式+
io_context线程池,单ChatServer可支撑8000+TCP连接,消息回调延迟<10ms; - 低线程开销:用户线程仅执行回调,无需阻塞IO等待,CPU利用率提升50%以上;
- 安全的状态管理:异步操作与
Session生命周期绑定,避免内存泄漏或野指针问题。
可以说,没有asio的底层异步IO能力,llfcchat难以实现“单服万级连接、低延迟消息”的核心目标,asio是项目网络通信的“技术基石”。
36.不同客户端之间实现消息转发的工作原理
结合llfcchat项目的分布式架构(多ChatServer协同、Redis状态管理、gRPC跨服通信)与核心技术栈(TCP长连接、Protobuf序列化),不同客户端之间的消息转发完全依赖服务端中转(客户端不直连),核心原理是“发送端→服务端解析→接收端定位→消息投递”,并根据“接收端是否在同一ChatServer”分为“单服转发”和“跨服转发”两种场景,具体工作原理如下:
一、核心前提:消息转发的底层依赖(项目基础支撑)
客户端间消息转发能实现,本质依赖3个核心组件,这些均为llfcchat已落地的技术模块:
- TCP长连接:客户端与ChatServer建立持久连接(day15
TcpManager、day16 Asio服务器),消息通过此连接收发,确保传输可靠性; - Session管理:ChatServer用
Session对象绑定“客户端-TCP连接-用户UID”(day17UserMgr),通过UID可快速找到接收方的连接; - 全局状态存储:Redis存储“用户UID-所属ChatServer”映射(day27
uip:{uid}),支撑跨服场景的接收方服务器定位; - Protobuf序列化:统一消息格式(如
TextChatReq/TextChatNotify),确保不同客户端/服务端能解析消息内容。
二、场景1:单服转发(客户端在同一ChatServer)
若客户端A(用户A,UID=10001)和客户端B(用户B,UID=10002)均连接到同一ChatServer(如ChatServer1),消息无需跨服,直接由该ChatServer完成转发,流程简单高效,是项目中最常见的场景。
完整工作流程(分5步)
1. 步骤1:客户端A封装并发送消息
用户A在客户端输入消息(如“晚上一起吃饭?”)后,客户端A执行“封装→序列化→发送”:
- 消息封装:按Protobuf定义(day27)封装为
TextChatReq,包含关键信息:message TextChatReq { int32 from_uid = 1; // 发送者UID:10001 int32 to_uid = 2; // 接收者UID:10002 string content = 3; // 消息内容:"晚上一起吃饭?" int64 timestamp = 4; // 发送时间戳:1718000000000(毫秒) string msg_id = 5; // 消息唯一ID:"uuid-123456"(防重复) } - Protobuf序列化:将
TextChatReq对象转为二进制字节流(体积比JSON小50%,适合网络传输); - TCP粘包处理:添加4字节“长度前缀”(大端序,如消息共120字节,前缀为
0x00 0x00 0x00 0x78),避免ChatServer拆包错误(day16核心逻辑); - 异步发送:通过
QTcpSocket(客户端)将数据发送到ChatServer1,不阻塞客户端UI线程。
2. 步骤2:ChatServer1接收并解析消息
ChatServer1的SessionA(绑定客户端A的连接)通过asio::async_read(day16)接收数据,执行“拆包→反序列化→合法性校验”:
- 拆包:先读取4字节长度前缀,解析出二进制消息的实际长度
N,再读取N字节数据,分离出Protobuf字节流; - 反序列化:调用Protobuf的
ParseFromArray接口,将字节流转为TextChatReq对象,获取from_uid(10001)、to_uid(10002)等关键信息; - 合法性校验:
- 校验
from_uid是否已登录(SessionA是否存在); - 校验
to_uid是否为from_uid的好友(day26好友关系表,可选,按业务需求); - 校验
msg_id是否重复(查询Redismsg_id:{msg_id},避免重复接收)。
- 校验
3. 步骤3:ChatServer1定位接收方Session
ChatServer1通过UserMgr(day17)查询用户B的SessionB(绑定客户端B的连接),确定消息投递目标:
- 查询本地Session:调用
UserMgr::GetSession(to_uid),从ChatServer1的本地_sessions集合(存储所有在线客户端的Session)中,根据to_uid=10002查找对应的SessionB; - 结果判断:
- 若找到
SessionB:说明用户B在线,进入下一步消息投递; - 若未找到
SessionB:说明用户B离线,将消息存入MySQLoffline_msg表(day31扩展),待B上线后拉取。
- 若找到
4. 步骤4:ChatServer1投递消息到客户端B
ChatServer1通过SessionB的异步发送接口,将消息推送给客户端B:
- 封装投递消息:不直接转发
TextChatReq,而是封装为TextChatNotify(包含“发送者昵称、头像URL”等客户端展示所需信息),避免暴露from_uid之外的敏感信息; - 序列化与发送:重复步骤1的“Protobuf序列化+长度前缀”流程,通过
SessionB的asio::async_write将消息发送到客户端B; - 发送确认:向客户端A返回“消息已送达”的
TextChatRsp(code=0,msg="success"),客户端A界面更新消息状态为“已送达”(day22气泡状态)。
5. 步骤5:客户端B接收并展示消息
客户端B的TcpManager(day15)接收消息后,完成“解析→校验→展示”:
- 拆包与反序列化:同步骤2,先拆长度前缀,再将字节流反序列化为
TextChatNotify对象; - 本地校验:检查
msg_id是否已接收(本地缓存最近100条消息ID,去重); - UI展示:调用QT界面接口,在气泡对话框中添加用户A的消息气泡,显示内容、发送时间、 sender头像(day22 UI渲染逻辑)。
三、场景2:跨服转发(客户端在不同ChatServer)
若客户端A连接ChatServer1、客户端B连接ChatServer2(跨服务器),消息需通过“ChatServer1→StatusServer→ChatServer2”的跨服流程转发,核心依赖Redis的全局状态定位和gRPC的跨服通信(day27)。
完整工作流程(在单服基础上增加3步跨服逻辑)
1. 前3步:与单服场景一致(客户端A发送→ChatServer1解析)
步骤1-2(客户端A发送、ChatServer1解析)完全相同,差异从“定位接收方Session”开始。
2. 差异步骤1:ChatServer1查询接收方所属ChatServer(查Redis)
ChatServer1调用UserMgr::GetSession(to_uid)未找到SessionB(说明B不在本地),需通过Redis定位B的服务器:
- 查询Redis全局状态:调用
RedisMgr::Get("uip:" + std::to_string(to_uid))(day27),获取用户B所在的ChatServer地址(如“ChatServer2,IP=192.168.1.102,gRPC端口=50051”); - 离线判断:若Redis无
uip:10002记录(已过期,说明B离线),将消息存入MySQL离线表;若有记录,进入跨服转发。
3. 差异步骤2:ChatServer1通过gRPC转发消息到ChatServer2
ChatServer1通过ChatGrpcClient(day27)调用ChatServer2的ForwardTextChat gRPC接口,实现跨服消息传递:
- 封装gRPC请求:将
TextChatReq封装为gRPC请求对象(Protobuf定义与单服兼容,新增from_server字段标记发送方服务器); - 复用gRPC连接:通过ChatServer1的gRPC连接池(day27
ChatConPool)获取与ChatServer2的复用连接,避免频繁创建连接的握手开销; - 断线重连保障:若gRPC调用失败(如ChatServer2临时不可用),触发断线重连逻辑(缓存消息,重连后重试,参考之前gRPC重连方案),确保消息不丢失。
4. 差异步骤3:ChatServer2接收并投递消息到客户端B
ChatServer2的gRPC服务端接收请求后,流程与单服场景的步骤4-5一致:
- 反序列化gRPC请求:将gRPC请求转为
TextChatReq对象; - 定位SessionB:调用
UserMgr::GetSession(to_uid)找到客户端B的SessionB; - 封装并发送消息:生成
TextChatNotify,通过SessionB的async_write推送给客户端B; - 跨服响应:通过gRPC向ChatServer1返回“转发成功”响应,ChatServer1再向客户端A返回“已送达”确认。
四、消息转发的可靠性保障(项目关键设计)
为确保“消息不丢失、不重复、有序”,llfcchat在转发流程中加入4层保障机制,覆盖全链路:
- TCP可靠性:基于TCP长连接传输,底层协议保障消息“不丢包、按序到达”,避免网络波动导致的消息错乱;
- 消息唯一ID:每个消息的
msg_id(UUID)全局唯一,客户端和服务端均通过msg_id去重(本地缓存+Redis记录),避免重复接收; - 离线消息存储:接收方离线时,消息存入MySQL
offline_msg表,上线后通过“拉取离线消息”接口(PullOfflineMsgReq)获取,确保消息必达; - 多级确认机制:
- 客户端A→ChatServer1:ChatServer1接收后返回“已接收”;
- ChatServer1→ChatServer2:ChatServer2接收后返回“已转发”;
- ChatServer2→客户端B:客户端B接收后返回“已阅读”(可选,根据业务需求);
各级确认确保消息全链路可追溯。
五、总结:消息转发的核心逻辑
不同客户端间的消息转发本质是“客户端→服务端→服务端→客户端的中转链路”,核心可概括为3个核心动作:
- 解析:服务端接收消息后,完成拆包、反序列化、合法性校验,提取关键信息;
- 定位:通过本地Session(单服)或Redis+gRPC(跨服),找到接收方的连接/服务器;
- 投递:将消息封装为客户端可展示的格式,通过TCP长连接推送给接收方,完成转发。
这一逻辑完全贴合llfcchat的分布式架构,既确保了单服场景的低延迟(<20ms),又支撑了跨服场景的消息互通,是IM系统“实时性、可靠性”的核心实现。
37.消息发送的协议是自定义的还是用了什么
结合llfcchat项目文档(尤其是day16“TCP消息格式”、day22“消息序列化”相关设计),消息发送的协议采用“自定义帧结构+Protobuf序列化”的混合方案——底层帧格式为项目自定义(解决TCP粘包问题),消息内容的序列化使用通用的Protobuf(提升效率与可扩展性),整体属于“基于自定义协议框架的应用层协议”。
一、协议的核心组成:自定义帧结构 + Protobuf序列化
消息发送的协议分为“传输帧结构”和“消息内容格式”两部分,前者为项目完全自定义,后者依赖Protobuf标准:
1. 底层传输帧结构(完全自定义,解决TCP粘包)
TCP是流式协议,若连续发送多条消息,会出现“粘包”(多条消息数据粘连)或“拆包”(单条消息被拆分),llfcchat自定义了**“4字节长度前缀+消息体”**的帧结构,确保服务端能正确拆分每条消息,这是协议的底层核心。
-
帧结构定义:
| 长度前缀(4字节,大端序) | 消息体(N字节) |- 长度前缀:用4字节无符号整数(uint32_t)表示“消息体的字节数”(N),采用大端序(网络字节序),确保跨平台(不同CPU字节序)解析一致;
- 消息体:Protobuf序列化后的二进制数据(包含消息类型、发送者UID、内容等业务信息)。
-
项目代码体现(day16):
客户端发送消息时,先计算消息体长度,添加前缀;服务端接收时,先读4字节长度,再按长度读取消息体:// 客户端发送消息(添加长度前缀) void TcpManager::send_msg(const std::string& proto_data) { uint32_t len = htonl(proto_data.size()); // 转为大端序 std::string frame; frame.append((char*)&len, 4); // 拼接4字节长度 frame.append(proto_data); // 拼接消息体 _tcp_socket.write(frame.data(), frame.size()); } // 服务端接收消息(先读长度,再读消息体) void Session::start_read() { // 第一步:读4字节长度前缀 asio::async_read(socket_, asio::buffer(len_buf_, 4), [this](std::error_code ec, size_t) { if (!ec) { uint32_t msg_len = ntohl(*(uint32_t*)len_buf_); // 转为主机字节序 // 第二步:按长度读消息体 asio::async_read(socket_, asio::buffer(msg_buf_, msg_len), [this](std::error_code ec, size_t) { if (!ec) { process_msg(msg_buf_, msg_len); // 处理消息体 } } ); } } ); }
2. 消息体格式(基于Protobuf,通用序列化)
消息体(帧结构中的“消息内容”)采用Protobuf(Protocol Buffers)进行序列化,而非自定义二进制格式或JSON,这是因为Protobuf相比其他格式有3大优势,完全适配项目的IM场景:
-
体积小:二进制序列化,比JSON小50%-70%,减少网络传输量(适合频繁发送的聊天消息);
-
解析快:反序列化效率比JSON高10倍以上,降低客户端/服务端的CPU开销;
-
可扩展:支持字段增删(通过
optional和字段编号),旧版本客户端/服务端可兼容新消息格式(如后期给聊天消息增加“表情”字段)。 -
项目中Protobuf消息定义(示例,day22):
聊天消息的Protobuf定义(.proto文件)明确了消息的字段结构,所有客户端和服务端都按此解析:// 文本聊天消息请求(客户端→服务端) message TextChatReq { int32 from_uid = 1; // 发送者UID(必选) int32 to_uid = 2; // 接收者UID(必选) string content = 3; // 消息内容(必选) int64 timestamp = 4; // 发送时间戳(毫秒,必选) string msg_id = 5; // 消息唯一ID(防重复,必选) optional string extra = 6; // 扩展字段(如消息类型标记,可选) } // 文本聊天消息通知(服务端→接收方客户端) message TextChatNotify { int32 from_uid = 1; // 发送者UID string from_name = 2; // 发送者昵称(客户端展示用) string from_avatar = 3;// 发送者头像URL string content = 4; // 消息内容 int64 timestamp = 5; // 发送时间戳 string msg_id = 6; // 消息唯一ID }
二、为什么不直接用HTTP/JSON或其他现成协议?
llfcchat作为IM系统,对“实时性、低延迟、高并发”要求极高,现成协议(如HTTP)或纯自定义格式都无法满足需求,因此选择“自定义帧结构+Protobuf”的混合方案:
- 不选HTTP/JSON:HTTP是请求-响应模式,不适合长连接双向通信;JSON体积大、解析慢,无法支撑每秒数千条消息的高频场景;
- 不选纯自定义二进制:虽然灵活,但需手动处理字段解析、版本兼容,开发效率低且易出错;
- 不选WebSocket:WebSocket基于HTTP握手,协议头开销较大,且项目已基于TCP长连接实现了更轻量的自定义帧结构,无需额外引入WebSocket复杂性。
三、总结:协议本质是“自定义传输框架+通用序列化”
llfcchat的消息发送协议既不是完全自定义的“从零设计”,也不是直接复用现成高层协议,而是:
- 底层传输层(解决粘包、帧拆分):完全自定义“4字节长度前缀+消息体”的帧结构,确保TCP长连接下的消息正确传输;
- 应用数据层(消息内容):使用Protobuf进行序列化,利用其高效、紧凑、可扩展的特性,降低开发成本并提升性能。
这种方案兼顾了“传输效率”“开发效率”和“可扩展性”,是IM系统消息协议的经典实践,也完全贴合llfcchat的技术栈(C++、TCP长连接)和业务需求(实时聊天、高并发)。
38.不同聊天服务器,是物理上的分离,还是逻辑上的分离
结合llfcchat项目的分布式架构设计(day27“分布式服务”“负载均衡”),不同ChatServer(聊天服务器)的分离方式是**“以物理分离为主,逻辑分离为辅”**——生产环境下为物理分离(独立硬件/虚拟机),测试或小规模部署时可采用逻辑分离(同一硬件上的独立进程/容器),核心目标是“分散负载、提升可用性、避免单点故障”,具体区别与项目实践如下:
一、先明确:物理分离与逻辑分离的核心区别
在解释项目实现前,需先界定两种分离方式的本质差异,避免混淆:
| 分离方式 | 核心定义 | 关键特征 | 资源隔离程度 |
|---|---|---|---|
| 物理分离 | 不同ChatServer运行在独立的硬件设备或虚拟机上 | 1. 有独立的CPU、内存、磁盘、网络网卡; 2. 有独立的IP地址(或不同端口+同一IP); 3. 一个设备故障不影响其他设备 | 完全隔离(硬件级),某ChatServer崩溃/硬件故障,其他ChatServer正常运行 |
| 逻辑分离 | 不同ChatServer运行在同一硬件设备的独立进程/容器中 | 1. 共享CPU、内存、磁盘等硬件资源; 2. 有独立的进程ID(PID)或容器ID; 3. 进程/容器间通过操作系统隔离(如进程空间、端口) | 部分隔离(操作系统级),某ChatServer进程崩溃不影响其他进程,但硬件故障会导致所有ChatServer不可用 |
二、项目中ChatServer的分离实践:物理分离为主,逻辑分离为辅
llfcchat的分布式架构(day27)是为“单服8000+连接、多服承载数万用户”设计的,因此生产环境强制物理分离,测试/开发环境可灵活采用逻辑分离,两者的具体实现与适配场景如下:
1. 生产环境:物理分离(核心部署方式)
生产环境下,不同ChatServer必须部署在独立的物理机或虚拟机上,这是实现“负载均衡”“高可用”的基础,完全贴合day27的分布式设计目标:
(1)物理分离的具体实现(项目部署规范)
- 独立硬件/虚拟机:每个ChatServer占用一台独立设备(如:ChatServer1部署在物理机A,ChatServer2部署在物理机B,ChatServer3部署在虚拟机C),设备间通过局域网或跨机房网络通信;
- 独立网络标识:每个ChatServer有独立的“IP地址+端口”——例如:
- ChatServer1:IP=192.168.1.101,TCP长连接端口=8090,gRPC跨服端口=50051;
- ChatServer2:IP=192.168.1.102,TCP长连接端口=8090,gRPC跨服端口=50051;
(端口可相同,通过IP区分;也可不同,根据网络规划选择);
- 独立资源分配:每个设备根据负载需求分配专属CPU(如8核)、内存(16GB)、带宽(1Gbps),避免因某ChatServer高负载(如大量文件传输)抢占其他服务器资源;
- 状态独立存储:每个ChatServer的本地缓存(如Session集合)、临时文件(如文件传输分块缓存)仅存储自身连接的用户数据,不与其他ChatServer共享(全局状态通过Redis同步,day27)。
(2)为什么生产环境必须物理分离?—— 贴合项目核心需求
- 分散负载,支撑高并发:day27的负载均衡逻辑(StatusServer选择连接数最少的ChatServer)依赖物理分离——若所有ChatServer共享硬件,某硬件CPU/内存占满时,所有ChatServer都会卡顿,负载均衡失去意义;
- 避免单点故障,提升可用性:若ChatServer1部署的物理机断电,仅影响其承载的8000用户,其他ChatServer(如102、103)的用户可正常聊天,符合IM系统“高可用”需求;若用逻辑分离,硬件故障会导致所有ChatServer崩溃,影响所有用户;
- 隔离网络风险:跨机房部署时(如ChatServer1在华东机房,ChatServer2在华南机房),物理分离可避免单机房网络故障导致的服务不可用(通过StatusServer调度用户连接到正常机房的ChatServer)。
2. 测试/开发环境:逻辑分离(低成本适配方案)
测试、开发或小规模演示时,为降低硬件成本,可采用逻辑分离——将多个ChatServer部署在同一台物理机/虚拟机上,通过“独立进程”或“Docker容器”实现隔离:
(1)逻辑分离的具体实现(项目测试规范)
- 独立进程模式:
在同一台开发机上启动多个ChatServer进程,通过“不同端口”区分——例如:- ChatServer1:启动命令
./ChatServer --port 8090 --grpc_port 50051; - ChatServer2:启动命令
./ChatServer --port 8091 --grpc_port 50052;
进程间共享开发机的CPU、内存,但有独立的PID,某进程崩溃(如ChatServer1因代码bug退出),ChatServer2仍可正常运行,方便测试“跨服消息转发”逻辑(day27);
- ChatServer1:启动命令
- Docker容器模式:
用Docker为每个ChatServer创建独立容器,容器间通过“虚拟网络”通信,端口映射到宿主机(如容器1的8090映射到宿主机8090,容器2的8090映射到宿主机8091),实现比“独立进程”更严格的资源隔离(可限制每个容器的CPU核心数、内存上限),更贴近生产环境的物理分离效果。
(2)逻辑分离的局限性(不适合生产)
- 资源竞争风险:若同一硬件上的ChatServer1处理大量文件传输(占用80%CPU),会导致ChatServer2的消息转发延迟从20ms飙升至200ms,不符合生产环境的“低延迟”需求;
- 单点故障风险:开发机断电或蓝屏时,所有ChatServer容器/进程都会终止,服务完全不可用,无法满足生产环境的“高可用”要求;
- 带宽瓶颈:同一硬件的网卡带宽有限(如1Gbps),多个ChatServer共享带宽时,易因某服务流量峰值(如每秒100MB文件传输)导致其他服务的消息传输卡顿。
三、总结:项目中ChatServer分离方式的选择原则
llfcchat对ChatServer分离方式的选择,完全基于“场景需求+成本平衡”,核心原则如下:
- 生产环境:必须物理分离(独立硬件/虚拟机),优先跨机房部署,确保负载分散、高可用,支撑数万用户的稳定使用;
- 测试/开发环境:推荐逻辑分离(独立进程/Docker),降低硬件成本,同时满足“跨服功能测试”(如跨服消息、负载均衡)的需求;
- 核心判断标准:是否需要“硬件级故障隔离”——需要则物理分离,仅需“功能隔离”则逻辑分离。
无论哪种分离方式,ChatServer间的协同逻辑(如跨服消息转发、状态同步)完全一致——均通过Redis(全局状态)和gRPC(跨服通信)实现,无需因分离方式修改代码,这也是项目分布式架构“低耦合”的体现(day27)。
39.登录和聊天分别是用什么协议
结合llfcchat项目的业务场景(登录为短连接请求、聊天为长连接实时交互)与技术栈(Boost.Beast、gRPC、TCP/Protobuf),登录和聊天采用不同协议栈,核心差异源于“短连接请求响应”与“长连接实时通信”的场景需求,具体协议选择及原因如下:
一、登录功能:采用“HTTP/HTTPS(客户端→GateServer) + gRPC(GateServer→AuthServer)”双层协议
登录功能的核心是“客户端提交账号密码→服务端校验身份→返回登录结果”,属于短连接、请求响应式交互,因此选择适配短连接场景的HTTP/HTTPS和gRPC,对应项目day04(Beast HTTP)、day14(登录功能)、day27(gRPC跨服)。
1. 客户端→GateServer:HTTP/HTTPS协议(应用层)
- 协议选择原因:
登录是“单次请求-单次响应”的短连接场景,HTTP/HTTPS无需建立持久连接,且天然支持“请求头+请求体”的结构化数据传输,适合传递账号密码、验证码等登录参数;HTTPS还能加密传输,避免敏感信息(如密码)被窃取。 - 具体实现(项目关联):
- 客户端通过QT的
QNetworkAccessManager发送HTTP POST请求,请求地址为GateServer的/api/login接口(如http://192.168.1.100:80/api/login); - 请求体为JSON格式(便于客户端封装和服务端解析),示例:
{ "username": "test_user", "password": "hashed_password", // 客户端对密码进行简单哈希(如MD5),避免明文传输 "device_id": "android_123456" // 设备ID,用于多端登录控制 } - GateServer基于Boost.Beast(day04)实现HTTP服务,接收请求后解析JSON参数,触发后续校验逻辑。
- 客户端通过QT的
- 传输层支撑:HTTP/HTTPS基于TCP协议(传输层),依赖TCP的可靠性确保登录请求不丢包。
2. GateServer→AuthServer:gRPC协议(应用层)
- 协议选择原因:
GateServer(网关)与AuthServer(认证服务)属于后端服务间的通信,需要“高效、结构化、跨语言”的协议(虽项目用C++,但预留跨语言扩展可能),gRPC基于HTTP/2和Protobuf,比HTTP/1.1更高效(支持多路复用),且Protobuf序列化体积小、解析快,适合传递认证结果(如Token)。 - 具体实现(项目关联):
- GateServer通过
AuthGrpcClient(day27)调用AuthServer的LogingRPC接口,传递“用户名、哈希密码、设备ID”; - 接口定义基于Protobuf(
.proto文件),示例:service AuthService { rpc Login(LoginReq) returns (LoginRsp); } message LoginReq { string username = 1; string hashed_password = 2; string device_id = 3; } message LoginRsp { int32 code = 1; // 0=成功,1=失败 string msg = 2; // 失败原因(如“密码错误”) string token = 3; // 登录成功后返回的临时Token(用于后续长连接认证) } - AuthServer校验账号密码后,返回
LoginRsp,GateServer再将结果封装为HTTP JSON响应返回给客户端。
- GateServer通过
- 传输层支撑:gRPC基于HTTP/2(应用层),底层仍依赖TCP协议(传输层),确保服务间通信可靠。
二、聊天功能:采用“自定义TCP应用层协议(Protobuf+长度前缀)”
聊天功能的核心是“实时双向通信、高并发长连接、低延迟消息传输”,属于长连接、流式交互,因此选择“原生TCP+自定义应用层协议”,而非HTTP(短连接)或WebSocket(协议头开销大),对应项目day16(TCP消息格式)、day22(消息序列化)。
1. 传输层:TCP协议(核心支撑)
- 协议选择原因:
聊天需要“消息不丢包、按序到达”(如用户连续发3条消息,接收方需按顺序展示),TCP的“三次握手建立连接、重传机制、流量控制”天然满足这些需求;同时TCP长连接可避免频繁建立/断开连接的开销,适合持续的消息交互。 - 项目关联:
客户端通过QTcpSocket(day15TcpManager)与ChatServer建立TCP长连接;ChatServer基于Boost.Asio(day16)实现异步TCP服务,单服可承载8000+并发长连接。
2. 应用层:自定义协议(Protobuf+长度前缀)
TCP是“流式协议”,若直接发送消息会出现“粘包/拆包”问题(如两条消息数据粘连),因此项目自定义了“4字节长度前缀+Protobuf消息体”的应用层协议,解决数据拆分和结构化传输问题。
(1)协议结构(完全自定义)
| 长度前缀(4字节,大端序) | Protobuf消息体(N字节) |
- 长度前缀:
用4字节无符号整数(uint32_t)表示“Protobuf消息体的字节数N”,采用大端序(网络字节序),确保跨平台(不同CPU字节序)解析一致;ChatServer接收时,先读4字节长度,再按长度读消息体,避免粘包。 - Protobuf消息体:
消息内容用Protobuf序列化(而非JSON),原因是Protobuf体积小(比JSON小50%-70%)、解析快(比JSON高10倍以上),适合高频消息传输(如每秒数十条聊天消息)。
(2)项目实现示例(聊天消息)
- Protobuf定义(day22):
文本聊天消息的Protobuf结构,明确字段含义和类型:// 客户端→ChatServer:发送文本消息 message TextChatReq { int32 from_uid = 1; // 发送者UID(已登录,从Token解析) int32 to_uid = 2; // 接收者UID string content = 3; // 消息内容(如“晚上一起吃饭?”) int64 timestamp = 4; // 发送时间戳(毫秒,避免消息乱序) string msg_id = 5; // 消息唯一ID(UUID,避免重复接收) } // ChatServer→客户端:推送文本消息 message TextChatNotify { int32 from_uid = 1; // 发送者UID string from_name = 2; // 发送者昵称(客户端展示用,避免重复查用户信息) string content = 3; // 消息内容 int64 timestamp = 4; // 发送时间戳 string msg_id = 5; // 消息唯一ID } - 发送与接收流程:
- 客户端发送:将
TextChatReq序列化→添加4字节长度前缀→通过TCP长连接发送; - ChatServer接收:先读4字节长度→按长度读消息体→反序列化为
TextChatReq→处理转发; - ChatServer推送:将消息封装为
TextChatNotify→序列化+加长度前缀→通过TCP长连接推送给接收方客户端。
- 客户端发送:将
三、核心差异对比:登录协议 vs 聊天协议
| 维度 | 登录功能协议 | 聊天功能协议 | 选择原因(贴合场景需求) |
|---|---|---|---|
| 连接类型 | 短连接(请求响应后断开) | 长连接(建立后持续保持,直到用户退出) | 登录是单次交互,聊天是持续交互;长连接避免频繁握手开销 |
| 应用层协议 | HTTP/HTTPS(客户端→GateServer)+ gRPC(GateServer→AuthServer) | 自定义协议(4字节长度前缀+Protobuf) | 登录需结构化请求响应,聊天需低延迟、抗粘包;自定义协议更轻量 |
| 数据格式 | JSON(HTTP)+ Protobuf(gRPC) | Protobuf(仅一种格式) | 登录参数少、需可读性,聊天消息高频、需小体积+快解析 |
| 核心需求适配 | 安全(HTTPS加密)、简单(请求响应) | 实时(低延迟<20ms)、高并发(8000+连接) | 登录侧重安全校验,聊天侧重实时交互和并发承载 |
总结:协议选择的核心逻辑
项目对登录和聊天的协议选择,完全基于“场景需求决定技术选型”:
- 登录是“短连接、请求响应、敏感数据传输”,因此用HTTP/HTTPS(客户端到网关)和gRPC(网关到认证服务),兼顾安全、简单和服务间通信效率;
- 聊天是“长连接、实时双向、高频消息”,因此用“TCP+自定义应用层协议”,通过Protobuf和长度前缀,实现低延迟、抗粘包、高并发的消息传输,避免现成协议(如HTTP、WebSocket)的开销和局限性。
40.登录的具体流程
结合llfcchat项目的分布式架构(GateServer/AuthServer/StatusServer/ChatServer协同)与技术栈(HTTP/gRPC/TCP、Redis/MySQL),登录流程是**“客户端→GateServer→AuthServer→StatusServer→ChatServer”的多服务协同过程**,核心目标是“身份校验+分配聊天节点+建立长连接”,具体流程拆解如下(对应day14“登录功能”、day27“分布式服务”、day09“Redis存储”):
一、登录流程总览:6步完成“身份校验→长连接建立”
登录流程需经过“请求发起→身份校验→节点分配→长连接建立→认证确认”,涉及5类角色(客户端、GateServer、AuthServer、StatusServer、ChatServer),全链路耗时通常控制在500ms内,具体步骤如下:
步骤1:客户端准备登录请求(用户输入→参数封装)
用户在客户端输入账号(如用户名/邮箱)、密码,点击“登录”后,客户端执行3个关键操作:
- 参数预处理:
- 密码不直接明文传输,客户端对密码进行“盐值+哈希”处理(如用用户ID作为盐值,执行SHA256哈希),避免网络传输中被窃取;
- 生成设备唯一标识(如
device_id=android_123456),用于后续“多端登录踢人”(day34)。
- 封装HTTP请求:
- 采用HTTP POST方法,请求地址为GateServer的登录接口(如
http://192.168.1.100:80/api/login); - 请求头设置
Content-Type: application/json,请求体为JSON格式,示例:{ "account": "test_user", // 账号(用户名/邮箱) "hashed_pwd": "a1b2c3d4...", // 盐值哈希后的密码 "device_id": "android_123456", "client_version": "v1.0.0" // 客户端版本,用于兼容性判断 }
- 采用HTTP POST方法,请求地址为GateServer的登录接口(如
- 发起请求:
客户端通过QT的QNetworkAccessManager发送HTTP请求,等待GateServer响应(超时时间设为3秒,避免长期阻塞UI)。
步骤2:GateServer接收请求→参数校验→转发AuthServer
GateServer(网关,day04)作为客户端的唯一入口,不处理业务逻辑,仅负责“请求接入+初步校验+转发”:
- 请求合法性校验:
- 校验请求方法(必须是POST)、
Content-Type(必须是JSON),非法请求直接返回“400 Bad Request”; - 校验客户端IP是否在黑名单(Redis
ip_blacklist:{ip},day32),若在黑名单返回“403 Forbidden”; - 校验请求频率(Redis
ip_limit:{ip},1分钟内不超过10次),超限返回“429 Too Many Requests”。
- 校验请求方法(必须是POST)、
- 解析请求参数:
用nlohmann::json解析请求体,提取account、hashed_pwd、device_id等核心参数,封装为“内部请求对象”。 - 转发至AuthServer(gRPC调用):
- GateServer通过
AuthGrpcClient(day27)调用AuthServer的LogingRPC接口,传递解析后的参数; - gRPC请求的Protobuf定义(
.proto):message LoginReq { string account = 1; // 客户端传入的账号 string hashed_pwd = 2; // 哈希后的密码 string device_id = 3; // 设备ID string client_version = 4; // 客户端版本 } - 等待AuthServer返回校验结果(超时时间2秒)。
- GateServer通过
步骤3:AuthServer身份校验→生成Token(核心业务逻辑)
AuthServer(认证服务,day14)是登录流程的“业务核心”,负责校验用户身份并生成临时凭证(Token),执行4个关键操作:
- 查询用户信息(MySQL):
- 根据
account(如“test_user”)查询MySQLuser表,获取用户记录(uid、salt、db_hashed_pwd、status等); - 若查询不到用户(账号不存在),返回“code=1,msg=账号不存在”;
- 若用户状态为“冻结”(
status=2),返回“code=2,msg=账号已冻结”。
- 根据
- 密码二次校验:
- 从MySQL获取用户的“原始盐值”(
salt,数据库存储的随机盐,非客户端用的用户ID盐); - 将客户端传入的
hashed_pwd与原始盐值再次执行SHA256哈希,得到final_pwd; - 对比
final_pwd与数据库存储的db_hashed_pwd:- 不一致:返回“code=3,msg=密码错误”(连续错误3次,临时冻结账号10分钟);
- 一致:进入下一步。
- 从MySQL获取用户的“原始盐值”(
- 处理多端登录(踢人逻辑):
- 查Redis
user_device:{uid}(存储用户当前登录的设备),若已存在其他设备(如“ios_654321”):- 调用StatusServer的
KickUsergRPC接口,通知对应ChatServer断开旧设备的长连接(day34); - 删除Redis
user_device:{uid}中的旧设备记录,添加新设备device_id。
- 调用StatusServer的
- 查Redis
- 生成登录Token→存储状态:
- 生成临时Token(如JWT格式,包含
uid、device_id、expire_time(2小时后过期)); - Redis存储Token:键
utoken:{uid},值为Token,过期时间2小时(day09); - Redis存储设备映射:键
user_device:{uid},值为device_id,过期时间2小时; - 返回gRPC响应给GateServer,Protobuf定义:
message LoginRsp { int32 code = 1; // 0=成功,非0=失败 string msg = 2; // 失败原因 string token = 3; // 登录成功的Token int32 uid = 4; // 用户唯一ID(客户端后续需存储) }
- 生成临时Token(如JWT格式,包含
步骤4:GateServer请求StatusServer→分配ChatServer(负载均衡)
AuthServer返回“登录成功”后,GateServer需为用户分配“负载最低的ChatServer”(用户后续聊天的节点),依赖StatusServer(day27):
- 调用StatusServer的
GetChatServergRPC接口:- 请求参数仅需
uid(可选,用于特殊场景如“用户固定节点”); - StatusServer的核心逻辑:
- 读Redis哈希
LOGIN_COUNT(存储所有ChatServer的当前连接数,如chatserver1:3200、chatserver2:2800); - 过滤“不健康节点”(10秒内未上报负载的ChatServer);
- 选择连接数最少的节点(如
chatserver2,2800连接); - 返回该ChatServer的IP和端口(如
ip=192.168.1.102,port=8090)。
- 读Redis哈希
- 请求参数仅需
- 封装登录结果:
GateServer将“AuthServer的Token+StatusServer的ChatServer地址”整合为HTTP JSON响应,返回给客户端:{ "code": 0, "msg": "登录成功", "data": { "uid": 10001, "token": "eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9...", // JWT Token "chat_server": { "ip": "192.168.1.102", "port": 8090 }, "expire_time": 7200 // Token有效期(秒,2小时) } }
步骤5:客户端连接ChatServer→建立TCP长连接
客户端收到GateServer的成功响应后,不直接进入聊天界面,需先与分配的ChatServer建立长连接(day15TcpManager、day16 Asio服务器):
- 存储核心信息:
客户端本地存储uid、token、chat_server_ip、chat_server_port(如用SharedPreferences(Android)或QSettings(QT)),后续重连需复用。 - 建立TCP长连接:
- 客户端通过
QTcpSocket发起连接请求,目标地址为chat_server_ip:port(192.168.1.102:8090); - 设置连接超时时间3秒,超时则重新请求GateServer分配新ChatServer(避免节点不可用);
- 连接成功后,客户端触发“长连接认证”(下一步),失败则提示用户“连接聊天服务器失败,请重试”。
- 客户端通过
步骤6:ChatServer长连接认证→登录完成(最终确认)
ChatServer收到客户端的TCP连接后,需验证用户身份(避免非法连接),完成登录闭环:
- 客户端发送快速认证请求:
客户端封装“快速认证请求”(Protobuf格式),包含uid和token,通过已建立的TCP连接发送(带4字节长度前缀,避免粘包):message QuickAuthReq { int32 uid = 1; // 步骤4返回的uid string token = 2; // 步骤4返回的Token string device_id = 3;// 步骤1的设备ID(二次校验) } - ChatServer认证:
- ChatServer反序列化请求,调用Redis
Get(utoken:{uid}),获取存储的Token; - 对比客户端传入的
token与Redis的Token:- 不一致/Token过期:断开TCP连接,返回“认证失败”;
- 一致:验证
device_id与Redisuser_device:{uid}是否匹配(防止Token被盗用),匹配则认证通过。
- ChatServer反序列化请求,调用Redis
- 更新状态→登录完成:
- ChatServer创建
Session对象(day17),绑定uid与TCP连接,存入UserMgr; - Redis更新
uip:{uid}(键为uip:10001,值为chatserver2),过期时间60秒(后续通过心跳续期,day35); - ChatServer返回“认证成功”响应,客户端收到后切换到聊天界面,登录流程结束。
- ChatServer创建
二、登录流程的核心保障(避免异常与安全风险)
- Token安全:
- Token采用JWT格式,包含过期时间,且加密签名(避免篡改);
- Redis存储的Token与
uid强绑定,盗用Token无法伪造uid。
- 多端登录控制:
- Redis
user_device:{uid}记录当前登录设备,新设备登录时踢掉旧设备,避免账号共用。
- Redis
- 异常重试:
- 若ChatServer连接失败,客户端自动重新请求GateServer分配新节点(最多重试3次);
- 若Token认证失败,客户端提示“登录已过期,请重新登录”。
- 日志与监控:
各服务记录登录日志(如“uid=10001,登录成功,IP=192.168.1.200”),异常登录(如异地登录)触发告警(day08邮箱服务)。
41.每个聊天服务器都是单独的ip,如果一个服务器突然挂了,那这个服务器上的客户端都会受到影响,如何做到无损地切换服务器
结合llfcchat项目的分布式架构(StatusServer监控、Redis状态存储、客户端断线重连),要实现ChatServer故障后的“无损切换”,核心是**“服务端快速故障检测+客户端无感重连+消息不丢失+状态无缝迁移”**,通过四层保障让用户无感知(如聊天界面不卡顿、消息不丢失),具体方案如下:
一、核心目标:什么是“无损切换”?
需满足3个关键指标,确保用户体验无影响:
- 无感知:客户端不弹窗提示“服务器故障”,仅在后台完成重连,用户继续聊天时无感知;
- 消息不丢:故障前未发送成功的消息、故障期间用户发送的消息,重连后均能正常送达;
- 状态不变:重连后用户的会话列表、好友在线状态、消息历史均与故障前一致。
二、四层保障方案:从故障检测到无感重连
1. 第一层:服务端故障检测(快速发现“挂掉的ChatServer”)
要实现无损切换,首先需让系统10秒内发现ChatServer故障,避免新用户分配到故障节点,同时触发旧用户迁移,核心依赖StatusServer和Redis:
(1)ChatServer健康心跳上报
每个ChatServer启动后,需每5秒向Redis上报健康状态,确保StatusServer能实时感知其存活:
- 上报逻辑:ChatServer定期执行
RedisMgr::Set("server_health:{server_name}", "alive", 10)(day09),键过期时间设为10秒(比上报间隔长1倍,避免网络波动误判);- 示例:ChatServer2(名称
chatserver2)上报后,Redis中server_health:chatserver2的值为alive,10秒内未续期则自动过期。
- 示例:ChatServer2(名称
- 故障判定:StatusServer每5秒遍历所有ChatServer,查询Redis中
server_health:{server_name}:- 若键存在:判定服务器健康,继续分配新用户;
- 若键不存在:判定服务器故障,立即从“健康服务器列表”中移除,不再分配新用户。
(2)客户端连接状态检测(补充保障)
若ChatServer突然断电(未触发Redis键过期),客户端可通过TCP连接状态+心跳超时检测故障:
- 客户端
TcpManager(day15)实时监控QTcpSocket状态,若触发ConnectionLost错误(底层TCP连接断开),立即启动重连; - 若ChatServer未断电但无响应(如死锁),客户端心跳超时(60秒,day35)后也会触发重连。
2. 第二层:客户端无感重连(后台自动切换,不打扰用户)
客户端是“无损切换”的核心执行端,需优化断线重连逻辑,从“弹窗提示”改为“后台静默重连”,关键步骤如下:
(1)重连触发:无感知启动
- 取消“连接断开”弹窗,仅在本地记录重连状态(如
is_reconnecting=true); - 重连期间用户发送消息时,客户端先将消息存入本地消息缓存队列(如
std::queue<TextChatReq>),显示“发送中”,不提示失败。
(2)重连流程:优先重试→快速获取新节点
重连分“两级重试”,确保切换效率,避免用户等待:
| 重试级别 | 目标服务器 | 逻辑 | 超时时间 | 作用 |
|---|---|---|---|---|
| 一级重试 | 故障前的ChatServer | 尝试重新连接旧服务器(可能是临时网络波动,非彻底故障),最多重试3次 | 3秒/次 | 快速恢复,避免切换到新节点 |
| 二级重试 | StatusServer分配的新节点 | 一级重试失败后,通过GateServer调用StatusServer的GetChatServer接口,获取健康节点地址(避开故障服务器) | 3秒 | 兜底保障,确保连接到可用节点 |
(3)快速身份认证:无需重新登录
重连到新ChatServer后,客户端用缓存的Token快速认证(无需输入账号密码),流程如下:
- 客户端发送
QuickAuthReq(day17),携带uid、token、device_id; - 新ChatServer查询Redis
utoken:{uid},验证Token有效性; - 认证通过后,新ChatServer创建
Session,更新Redisuip:{uid}为新服务器地址(如chatserver3); - 客户端收到“认证成功”响应,标记
is_reconnecting=false,重连完成。
3. 第三层:消息不丢失(故障前后消息全保障)
消息丢失是“无损”的最大敌人,需从“客户端缓存+服务端持久化”双端保障:
(1)客户端:重连期间消息缓存
- 客户端在
is_reconnecting=true时,所有发送的消息先存入本地队列(上限100条,避免内存溢出); - 重连成功后,客户端自动遍历队列,按消息发送时间顺序重新发送,发送成功后更新消息状态为“已送达”。
(2)服务端:故障前未转发消息持久化
ChatServer需将“已接收但未转发”的消息实时持久化,避免故障导致内存中消息丢失:
- 实时持久化:ChatServer收到客户端消息后,先存入MySQL
pending_msg表(字段:msg_id、from_uid、to_uid、content、status=0(待转发)),再执行转发; - 故障恢复:新ChatServer接管用户后,查询MySQL
pending_msg表中“from_uid为当前用户且status=0”的消息,重新转发,转发成功后更新status=1。
4. 第四层:用户状态无缝迁移(重连后状态不变)
重连到新ChatServer后,需确保用户的“会话列表、好友在线状态、消息历史”与故障前一致,核心依赖Redis和分布式状态同步:
(1)会话列表与好友状态:从Redis拉取最新
- 客户端重连成功后,调用新ChatServer的
GetSessionList接口,新ChatServer从Redissession:uid:{uid}(day27)拉取会话列表(含最后一条消息时间); - 好友在线状态从Redis
user_online:{friend_uid}(day35)拉取,确保与故障前一致。
(2)消息历史:本地缓存+服务端拉取
- 客户端本地缓存最近100条消息,重连后无需重新拉取;
- 若用户需查看更早消息,新ChatServer从MySQL
chat_msg表(day31)拉取,与旧服务器的数据一致(因消息已持久化到共享MySQL)。
三、关键优化:让切换更“无损”的细节
- 重连期间UI优化:
- 用户发送消息时,仅显示“发送中”(转圈图标),不提示“发送失败”;
- 重连成功后,“发送中”自动变为“已送达”,用户无感知等待。
- 故障服务器用户迁移优先级:
StatusServer发现ChatServer故障后,优先将“活跃用户”(最近1分钟有消息)分配到负载较低的新服务器,避免新服务器过载。 - 避免重复消息:
所有消息携带唯一msg_id(UUID),服务端和客户端均通过msg_id去重(Redis记录已处理msg_id,客户端记录已发送msg_id),避免重连后消息重复发送。
四、方案落地:适配llfcchat现有架构的修改点
无需重构核心模块,仅需在现有基础上扩展3处:
- StatusServer:新增“ChatServer健康监控”模块,定期查询Redis
server_health键,维护健康服务器列表; - 客户端TcpManager:优化重连逻辑,增加本地消息缓存队列,取消重连弹窗;
- ChatServer:新增“消息持久化到MySQL
pending_msg表”的逻辑,确保未转发消息不丢失。
总结:无损切换的核心逻辑
ChatServer故障后的无损切换,本质是**“共享存储(Redis/MySQL)+ 后台重连 + 消息缓存”** 的协同:
- 共享存储(Redis/MySQL)确保用户状态和消息不依赖单台ChatServer;
- 客户端后台重连避免用户感知故障;
- 消息缓存和持久化确保消息不丢失;
最终实现“ChatServer故障→用户继续聊天→无感知切换到新服务器”的效果,完全贴合llfcchat的高可用需求。
42.项目中用的是私域ip还是公网ip,如何获得一个公网ip
结合llfcchat项目的分布式部署场景(后端服务集群、客户端跨网络访问),项目中私域IP(内网IP)和公网IP会配合使用,并非单一选择;公网IP的获取需根据“项目规模(个人/企业)”和“部署场景(本地/云服务)”选择不同方案,具体如下:
一、项目中私域IP与公网IP的使用分工:按“服务角色”划分
llfcchat的核心服务(ChatServer、AuthServer、StatusServer、GateServer)因“是否需要被公网客户端访问”,分别使用私域IP或公网IP,核心逻辑是“仅对外入口服务用公网IP,后端内部服务用私域IP”,兼顾安全性和成本。
| 服务角色 | IP类型 | 作用说明 | 项目关联场景 |
|---|---|---|---|
| 后端内部服务(核心) | 私域IP(内网IP) | ChatServer、AuthServer、StatusServer、Redis、MySQL等,仅在服务集群内部通信,不暴露到公网 | 1. ChatServer间通过私域IP用gRPC跨服转发(day27); 2. GateServer通过私域IP调用AuthServer/StatusServer; 3. 所有服务访问Redis/MySQL均用私域IP |
| 对外入口服务(网关) | 公网IP | GateServer(或云服务负载均衡器),作为客户端唯一公网访问入口,接收客户端HTTP登录请求 | 1. 客户端(手机/电脑)通过公网IP访问GateServer的/api/login接口(day14);2. 客户端获取ChatServer地址后,若ChatServer部署在云内网,需通过公网IP+端口映射访问 |
为什么这样分工?—— 核心优势
- 安全性:后端服务(如ChatServer、MySQL)用私域IP,不直接暴露在公网,可避免SQL注入、端口扫描等外部攻击,仅需给GateServer做安全防护(如防火墙、HTTPS);
- 成本低:公网IP(尤其是固定公网IP)通常需要额外付费(运营商/云服务商),后端服务用私域IP可大幅减少公网IP数量,降低成本;
- 通信效率高:私域IP属于内网通信(如同一云服务器集群内、同一局域网),延迟通常<1ms,远低于公网通信(跨地区公网延迟可能50-100ms),适合ChatServer间高频跨服转发(day27)。
二、如何获得公网IP?—— 分“个人/小型项目”和“企业/生产项目”场景
公网IP的获取方式取决于项目规模和部署需求,llfcchat不同阶段(测试/生产)推荐不同方案:
场景1:个人/小型项目(测试、Demo演示)
适合个人开发、小规模测试(如10人以内试用),优先选择“低成本、易部署”的方案:
1. 方案1:家庭宽带申请动态公网IP(免费,适合本地部署)
- 获取方式:
- 联系家庭宽带运营商(电信、联通、移动),申请“动态公网IP”(个人用户通常免费,部分运营商需说明用途);
- 申请成功后,路由器会自动获取运营商分配的公网IP(非固定,可能每天/每周变化);
- 在路由器中配置“端口映射”:将公网IP的端口(如80端口,GateServer用)映射到本地服务器的私域IP+端口(如本地GateServer部署在
192.168.1.10:80)。
- 项目适配:
本地部署GateServer、ChatServer等服务,客户端通过“公网IP:端口”访问(如http://202.100.1.5:80/api/login);
缺点是公网IP动态变化,需通过“动态DNS(DDNS)”工具(如花生壳、No-IP)绑定域名,避免IP变化后客户端无法访问。
2. 方案2:购买云服务器(推荐,稳定且易管理)
- 获取方式:
- 选择云服务商(阿里云、腾讯云、华为云),购买“弹性云服务器(ECS)”;
- 购买时默认分配1个“弹性公网IP(EIP)”(按流量计费或固定带宽,成本低,个人用户首年通常几十元);
- 云服务器内部用私域IP,外部通过弹性公网IP访问,无需配置路由器(云服务商已做好NAT转发)。
- 项目适配:
在云服务器上部署GateServer(绑定弹性公网IP的80端口),ChatServer/AuthServer等部署在同一云服务器集群的其他节点(用私域IP通信);
优势是公网IP稳定,支持随时解绑/重新绑定,云服务商还提供防火墙、DDoS防护等安全功能,适合llfcchat测试环境。
3. 方案3:内网穿透工具(临时测试,不适合生产)
- 获取方式:
若无法申请公网IP(如运营商不提供),可使用内网穿透工具(如花生壳、ngrok、FRP),将本地服务的私域IP端口“映射到工具提供的公网域名/IP”;
示例:通过FRP将本地192.168.1.10:80映射到frp.example.com:8080,客户端访问该域名即可。 - 缺点:免费版通常有带宽限制(如1Mbps)、域名随机变化,且数据需经过第三方服务器,安全性和稳定性较低,仅适合临时测试。
场景2:企业/生产项目(大规模用户,如万级并发)
llfcchat若进入生产环境,需保证公网IP的“稳定性、高可用性、安全性”,推荐以下方案:
1. 方案1:云服务商弹性公网IP+负载均衡(推荐)
- 获取方式:
- 购买多个弹性公网IP(EIP),绑定到“负载均衡器(如阿里云SLB、腾讯云CLB)”;
- 负载均衡器后端挂载多台GateServer(私域IP),客户端通过负载均衡器的公网IP访问,负载均衡器自动将请求分发到后端GateServer,实现高可用;
- 弹性公网IP支持“按需绑定/解绑”,若某IP异常,可快速切换到备用IP。
- 项目适配:
客户端访问https://chat.example.com/api/login(域名解析到负载均衡器的公网IP),负载均衡器将请求转发到后端GateServer集群;
优势是支持高并发(负载均衡器可抗万级QPS)、故障自动切换(某GateServer故障不影响整体服务),完全贴合llfcchat生产环境的分布式架构(day27)。
2. 方案2:运营商专线+固定公网IP(高稳定性,成本高)
- 获取方式:
- 企业向运营商(电信/联通)申请“互联网专线”(如100Mbps专线),通常会分配1-8个“固定公网IP”(IP地址长期不变);
- 专线接入企业机房,通过防火墙、路由器将公网IP映射到内部GateServer集群的私域IP。
- 项目适配:
适合对网络稳定性要求极高的场景(如金融级IM),但成本高(专线年费通常数万元),llfcchat若为普通企业项目,优先选择云服务方案。
三、项目落地建议:llfcchat不同阶段的IP选择
| 项目阶段 | 推荐IP方案 | 核心原因 | 注意事项 |
|---|---|---|---|
| 个人开发/测试 | 云服务器(弹性公网IP) | 成本低、稳定、易管理,无需配置路由器 | 选择“轻量应用服务器”(云服务商针对个人用户的产品),降低操作门槛 |
| 小型团队试用 | 云服务器+负载均衡(1个弹性公网IP) | 支持500-1000用户并发,故障自动切换 | 开启HTTPS(云服务商免费提供SSL证书),保障登录数据安全 |
| 生产环境(万级) | 云服务器集群+多弹性公网IP+负载均衡 | 高可用、抗高并发,支持动态扩容 | 弹性公网IP绑定域名,避免客户端直接使用IP访问(便于后续切换IP) |
43.登录用的是http的哪个方法,为什么用post,不用get
llfcchat项目中登录功能使用的是HTTP POST方法,而非GET方法。选择POST的核心原因是贴合登录场景的“敏感数据传输、数据安全性、业务语义”需求,GET方法的特性完全不匹配登录场景,具体分析如下:
一、核心结论:登录用HTTP POST方法
在llfcchat的登录流程中(day14“登录功能”、day04“Beast HTTP服务”),客户端通过HTTP POST请求向GateServer的/api/login接口提交登录参数(如账号、哈希后的密码、设备ID),这是HTTP协议设计语义与登录业务需求匹配的必然选择。
二、为什么用POST?—— 4个核心原因贴合登录场景
登录场景的核心需求是“安全传输敏感认证信息、确保请求不被误执行、支持复杂参数”,POST方法的特性完美适配这些需求:
1. 原因1:POST可将敏感数据放在请求体,避免暴露
登录涉及账号、密码(即使哈希后仍属敏感信息),若用GET方法,这些数据会拼接在URL中(如http://xxx/api/login?username=test&hashed_pwd=abc123),存在3大安全风险:
- URL可见性风险:URL会显示在浏览器地址栏、客户端日志、服务器访问日志、网络中间件(如代理、网关)的日志中,任何人查看日志都能获取敏感数据;
- 缓存风险:GET请求会被浏览器、CDN、代理服务器缓存,缓存内容中可能包含敏感参数,后续其他用户访问同一URL可能触发缓存命中,导致信息泄露;
- 书签/分享风险:GET请求的URL可被收藏为书签或分享,若包含敏感数据,会直接导致账号安全隐患。
而POST方法会将登录参数放在HTTP请求体(Request Body) 中,不暴露在URL、日志(默认配置下,服务器日志不会记录请求体)中,仅在网络传输层(需配合HTTPS加密)传递,敏感数据安全性大幅提升。
2. 原因2:POST无严格的数据长度限制,适配登录参数需求
登录请求除了账号、密码,还可能包含设备ID、客户端版本、验证码(若有)、登录类型(如密码登录/验证码登录) 等参数,数据量可能超过GET方法的长度限制:
- GET方法的参数通过URL传递,而URL的长度受浏览器、服务器限制(如IE浏览器限制2083字节,Apache服务器默认限制8192字节),若登录参数较多(如设备ID较长、包含额外校验字段),可能导致参数被截断,请求失败;
- POST方法的请求体无严格长度限制(仅受服务器配置的请求体大小限制,如llfcchat中GateServer配置为1MB,完全满足登录参数需求),可灵活传递多字段、复杂结构的登录数据(如JSON格式的参数)。
3. 原因3:POST的语义是“提交数据”,贴合登录的业务逻辑
HTTP协议对GET和POST的语义有明确划分,登录场景的业务逻辑与POST语义完全匹配:
- GET语义:“获取资源”,即请求服务器返回已存在的资源(如查询用户信息、获取商品列表),且请求不应改变服务器状态(幂等性:多次执行相同请求,结果一致,不影响服务器数据);
- POST语义:“提交数据”,即向服务器提交新数据,请求服务器处理并可能改变服务器状态(非幂等性:多次执行可能产生不同结果,如登录时可能触发“多端踢人”,改变用户的登录设备状态)。
登录的本质是“向服务器提交认证数据,请求服务器验证身份并返回Token(改变服务器的Token存储状态、用户设备映射状态)”,完全符合POST“提交数据、改变状态”的语义;若用GET,会违背HTTP协议的语义设计,导致接口逻辑与方法语义不一致,增加后期维护成本。
4. 原因4:POST可配合HTTPS实现端到端加密,进一步提升安全性
虽然HTTP协议本身不加密,但POST方法的请求体在配合HTTPS时,会与整个请求一起被TLS加密传输(GET的URL也会被加密,但URL的路径部分仍可能在某些场景下暴露,如SNI扩展),而POST的请求体加密后,即使网络被监听,攻击者也无法解密获取敏感数据。
llfcchat生产环境中,登录请求会强制使用HTTPS POST,进一步强化敏感数据的传输安全,这也是POST方法在登录场景中不可替代的优势之一。
三、为什么不用GET?—— 3个致命缺陷与登录场景冲突
GET方法的特性与登录场景的“安全性、数据需求、语义逻辑”完全冲突,具体缺陷如下:
- 敏感数据暴露风险:如前所述,GET参数在URL中可见,易被日志、缓存记录,导致账号密码泄露,这是登录场景的“致命安全问题”;
- 数据长度限制:无法承载较多登录参数,可能导致参数截断,影响登录功能正常使用;
- 语义不匹配:GET是“获取资源”,登录是“提交认证数据”,语义冲突会导致接口设计不规范,增加团队协作和后期维护的混乱(如新人可能误解接口用途)。
总结:POST是登录场景的唯一合理选择
登录功能需要“安全传输敏感数据、支持多参数、符合提交语义”,POST方法的特性(请求体传参、无长度限制、语义匹配、易配合HTTPS)完美适配这些需求,而GET方法的缺陷(敏感数据暴露、长度限制、语义冲突)使其完全不适合登录场景。这也是行业内所有登录功能的通用选择,llfcchat的设计完全符合HTTP协议规范与安全最佳实践。
44.项目中MySQL主要存储哪些数据
结合llfcchat项目的业务场景(用户管理、消息交互、好友关系)与数据存储需求(持久化、关键业务数据不丢失),MySQL主要存储“需要长期保存、不可丢失、需结构化查询”的数据,与Redis(存储临时数据、高频访问数据)形成互补。核心存储数据可按“业务模块”划分,具体如下:
一、核心模块1:用户基础信息(支撑登录与身份识别)
用户相关数据是项目的基础,需持久化存储(避免用户账号、资料丢失),主要通过user表存储,是登录认证(day14)、用户资料展示(day26)的核心依赖。
| 数据表名 | 核心存储字段 | 数据作用说明 | 关联业务场景 |
|---|---|---|---|
user | uid(主键,用户唯一ID) | 唯一标识用户,关联所有用户相关数据(消息、好友) | 所有涉及用户的业务(登录、聊天、好友) |
account(唯一,用户名/邮箱/手机号) | 用户登录账号,确保唯一(避免重复注册) | 登录时AuthServer查询账号是否存在 | |
hashed_pwd(密码哈希值) | 存储加盐哈希后的密码(不存明文,保障安全) | 登录时密码校验(day14 AuthServer逻辑) | |
salt(密码盐值) | 加密密码时使用的随机盐(防止彩虹表破解) | 登录时二次哈希校验密码 | |
nickname(用户昵称) | 客户端展示的用户名称(可修改) | 好友列表展示、消息气泡 sender 昵称 | |
avatar_url(头像URL) | 用户头像的存储地址(如云存储URL) | 好友列表、个人资料页展示 | |
status(用户状态:0-正常,1-冻结) | 控制用户账号可用性(如违规后冻结) | 登录时校验账号是否可用 | |
create_time(账号创建时间) | 记录账号注册时间,用于用户生命周期管理 | 后台统计、新用户福利活动 | |
last_login_time(最后登录时间) | 记录用户最近登录时间,用于账号活跃度判断 | 长期未登录账号清理、安全审计 |
二、核心模块2:消息数据(支撑离线消息与历史记录)
消息数据分为“离线消息”和“历史消息”,均需持久化(避免消息丢失),其中离线消息是用户离线时的关键数据,历史消息用于用户回溯聊天记录。
| 数据表名 | 核心存储字段 | 数据作用说明 | 关联业务场景 |
|---|---|---|---|
offline_msg | msg_id(主键,消息唯一ID) | 唯一标识消息,避免重复接收(配合Redis去重) | 用户上线后拉取离线消息(day31扩展) |
from_uid(发送者UID) | 关联发送者,用于消息归属判断 | 离线消息按发送者分类展示 | |
to_uid(接收者UID) | 关联接收者,用于筛选“当前用户的离线消息” | 用户上线时查询“to_uid=当前用户”的消息 | |
msg_type(消息类型:0-文本,1-图片) | 区分消息类型,客户端按类型渲染(文本/图片预览) | 消息展示逻辑(day22气泡对话框) | |
content(消息内容) | 文本消息直接存内容,图片消息存图片URL | 离线消息内容展示 | |
send_time(发送时间戳) | 记录消息发送时间,用于消息排序(按时间展示) | 离线消息按时间顺序排列 | |
is_read(是否已读:0-未读,1-已读) | 标记消息状态,客户端展示“未读红点” | 未读消息统计、红点提示 | |
chat_history | history_id(主键) | 历史消息唯一ID | 用户查询历史聊天记录 |
from_uid/to_uid/msg_type/content/send_time | 同offline_msg核心字段 | 存储用户长期聊天记录(如近3个月) | |
session_id(会话ID,如“10001_10002”) | 按“发送者UID_接收者UID”组合,用于快速查询某会话的历史消息 | 用户点击会话后,拉取该会话的历史记录 |
三、核心模块3:好友关系数据(支撑好友交互)
好友关系是IM的核心社交数据,需持久化存储(避免用户好友列表丢失),主要通过“好友关系表”和“好友申请记录表”实现,支撑day26“联系人列表”和“好友申请”功能。
| 数据表名 | 核心存储字段 | 数据作用说明 | 关联业务场景 |
|---|---|---|---|
friend_relation | id(主键) | 关系唯一ID | 好友关系的增删改查 |
uid1(用户A UID) | 好友关系中的一方(约定uid1 < uid2,避免重复存储) | 避免“10001-10002”和“10002-10001”重复存储 | |
uid2(用户B UID) | 好友关系中的另一方 | 按uid1或uid2查询用户的所有好友 | |
relation_status(关系状态:0-正常,1-拉黑) | 区分正常好友和拉黑状态(拉黑后无法发送消息) | 好友列表过滤拉黑用户、消息发送权限控制 | |
remark_name(备注名,如“张三-同事”) | 用户给好友设置的备注(客户端展示优先用备注) | 好友列表展示备注名 | |
add_time(添加时间) | 记录好友添加时间,用于“最近添加好友”筛选 | 好友列表按添加时间排序 | |
friend_apply | apply_id(主键) | 申请记录唯一ID | 好友申请的处理(同意/拒绝) |
from_uid(申请人UID) | 发起好友申请的用户 | 被申请人查看“谁申请加我好友” | |
to_uid(被申请人UID) | 接收好友申请的用户 | 筛选“当前用户的待处理申请” | |
apply_status(申请状态:0-待处理,1-同意,2-拒绝) | 标记申请进度,避免重复处理 | 客户端展示申请状态(待处理/已拒绝) | |
apply_msg(申请留言,如“我是李四”) | 用户申请时填写的留言,帮助被申请人判断是否同意 | 待处理申请列表展示留言 | |
apply_time(申请时间) | 记录申请时间,用于“最新申请”排序 | 待处理申请按时间顺序展示 |
四、辅助模块:系统配置与安全日志
除核心业务数据外,MySQL还存储“系统配置”和“安全日志”类数据,支撑系统运维、安全审计和功能扩展。
| 数据表名 | 核心存储字段 | 数据作用说明 | 关联业务场景 |
|---|---|---|---|
user_device | device_id(主键,设备唯一标识) | 记录用户登录过的设备(如手机IMEI、电脑UUID) | 多端登录控制(day34踢人逻辑)、设备管理 |
uid(关联用户UID) | 绑定设备与用户 | 查询用户当前登录的所有设备 | |
device_type(设备类型:0-手机,1-电脑) | 区分设备类型,用于客户端适配 | 踢人时展示“登录设备(手机)” | |
last_login_time(最后登录时间) | 记录设备最近登录时间,用于“闲置设备清理” | 自动下线长期未登录的设备 | |
login_log | log_id(主键) | 登录日志唯一ID | 安全审计、异常登录排查(day30日志) |
uid(登录用户UID) | 关联登录用户 | 查询某用户的登录历史 | |
login_ip(登录IP地址) | 记录登录时的IP,用于判断是否异地登录 | 异地登录告警(如“北京IP登录你的账号”) | |
login_time(登录时间) | 记录登录时间,用于时间范围查询 | 排查“某时间段是否有异常登录” | |
login_result(登录结果:0-成功,1-失败) | 标记登录是否成功,用于失败原因分析 | 统计密码错误次数、账号冻结触发条件 | |
system_config | config_key(主键,配置键) | 系统配置项标识(如“max_friend_count”) | 动态调整系统参数,无需改代码 |
config_value(配置值) | 配置项的值(如“500”,表示最多添加500个好友) | 好友添加时校验“是否超过最大数量” | |
config_desc(配置描述) | 说明配置项的作用,方便运维理解 | 系统配置管理后台展示 |
五、MySQL与Redis的存储分工(关键区别)
需明确MySQL与Redis的存储边界,避免重复存储或数据不一致,核心分工原则:
| 存储目标 | 选择MySQL | 选择Redis |
|---|---|---|
| 数据特性 | 持久化、不可丢失、结构化查询 | 临时、高频访问、无需持久化(如在线状态) |
| 典型数据 | 用户账号、离线消息、好友关系 | 用户在线状态(uip:{uid})、登录Token(utoken:{uid})、ChatServer负载(LOGIN_COUNT) |
| 访问频率 | 低-中(如登录时查用户、上线时拉离线消息) | 高(如消息转发时查在线状态、心跳时续期Token) |
总结:MySQL的核心定位
MySQL在llfcchat中是“核心业务数据的持久化仓库”,存储所有“丢失后会影响业务正常运行”的数据(如用户账号、好友关系、离线消息),与Redis的“临时缓存”形成互补,共同支撑IM系统的稳定运行。
45.聊天过程中的数据如何产生,如何传递,如何存储
结合llfcchat项目的聊天功能设计(TCP长连接、Protobuf序列化、Redis/MySQL存储),聊天过程中的数据(文本、图片等消息)会经历“用户触发产生→多节点协同传递→分层存储(临时+持久化) ”的全链路流程,每个环节均贴合IM场景“实时性、可靠性、不丢失”的核心需求,具体拆解如下:
一、聊天数据的产生:从用户操作到结构化封装
聊天数据的产生始于用户在客户端的交互(如输入文本、发送图片),最终封装为“可传输、可解析”的结构化数据,核心是“补全必要元信息+适配传输协议”。
1. 产生触发:用户操作与客户端预处理
- 文本消息:用户在QT气泡对话框(day22)输入文本(如“周末去爬山吗?”),点击“发送”按钮,触发数据产生;
- 图片/文件消息:用户选择本地图片,客户端先将图片上传至云存储(如阿里云OSS),获取图片URL(避免消息体过大),再触发消息产生;
- 预处理:客户端对用户输入做基础校验(如文本长度限制、敏感词过滤),确保数据合规。
2. 结构化封装:补全元信息+Protobuf序列化
客户端将“用户输入内容”与“必要元信息”整合,用Protobuf序列化为二进制数据(体积小、解析快),形成可传输的聊天数据,核心字段参考day22的TextChatReq定义:
| 核心字段 | 产生逻辑 | 作用说明 |
|---|---|---|
from_uid | 客户端从本地缓存读取当前登录用户的UID(登录成功后存储) | 标识消息发送者,服务端用于权限校验(如是否为好友) |
to_uid | 客户端根据当前聊天窗口确定接收者UID(如好友列表选中的用户) | 标识消息接收者,服务端用于定位接收方连接 |
content | 文本消息直接填入用户输入;图片消息填入云存储URL | 消息核心内容,客户端最终展示的主体 |
msg_id | 客户端生成UUID(如“uuid-20240601-123456”) | 全局唯一标识,避免消息重复接收(服务端+客户端去重) |
timestamp | 客户端获取当前系统时间戳(毫秒级) | 标记消息发送时间,确保消息按序展示 |
msg_type | 客户端按消息类型赋值(0=文本,1=图片,2=文件) | 服务端/客户端按类型处理(如图片消息渲染URL预览) |
3. 传输适配:添加TCP粘包防护
TCP是流式协议,直接发送Protobuf数据会出现“粘包”,客户端需在序列化后的二进制数据前添加“4字节长度前缀”(day16):
- 逻辑:先计算Protobuf数据的字节数
N,将N转为大端序(网络字节序)的4字节整数,拼接在Protobuf数据前; - 示例:若Protobuf数据为120字节,长度前缀为
0x00 0x00 0x00 0x78,最终传输数据为“4字节前缀+120字节Protobuf数据”。
二、聊天数据的传递:从发送方到接收方的全链路转发
聊天数据的传递是“客户端→服务端→客户端”的中转过程,核心依赖“TCP长连接+服务端定位+跨服协同(若需)”,分“单服传递”和“跨服传递”两种场景,均确保实时性(延迟<20ms)。
1. 场景1:单服传递(发送方与接收方在同一ChatServer)
若发送方A(UID=10001)和接收方B(UID=10002)均连接ChatServer1,数据传递无需跨服,流程简单高效:
(1)步骤1:发送方客户端→ChatServer1(TCP长连接)
- 客户端A通过
QTcpSocket(day15TcpManager)将“长度前缀+Protobuf数据”异步发送到ChatServer1的8090端口; - TCP协议保障数据“不丢包、按序到达”,无需客户端额外处理重传。
(2)步骤2:ChatServer1解析与校验
- ChatServer1的
SessionA(绑定A的连接)通过asio::async_read(day16)接收数据:- 先读4字节长度前缀,解析出Protobuf数据长度
N; - 再读
N字节数据,反序列化为TextChatReq对象; - 校验:检查
from_uid是否已登录(SessionA存在)、to_uid是否为from_uid的好友(查Redis好友缓存,day26)、msg_id是否重复(查Redismsg_id:{msg_id})。
- 先读4字节长度前缀,解析出Protobuf数据长度
(3)步骤3:ChatServer1定位接收方并转发
- ChatServer1调用
UserMgr::GetSession(to_uid)(day17),从本地_sessions集合找到接收方B的SessionB; - 若B在线:ChatServer1封装
TextChatNotify(补充from_name、from_avatar等展示字段),序列化+加长度前缀后,通过SessionB的asio::async_write推送给客户端B; - 若B离线:ChatServer1将消息存入MySQL
offline_msg表(day31),待B上线后拉取。
(4)步骤4:接收方客户端B接收与展示
- 客户端B的
TcpManager接收数据,拆包+反序列化为TextChatNotify; - 客户端校验
msg_id是否已接收(本地缓存最近100条msg_id),去重后调用UI接口,在气泡对话框渲染消息(文本直接显示,图片加载URL预览)。
2. 场景2:跨服传递(发送方与接收方在不同ChatServer)
若A在ChatServer1、B在ChatServer2,数据需通过“ChatServer1→StatusServer→ChatServer2”跨服转发,核心依赖Redis全局状态和gRPC通信(day27):
(1)差异步骤1:ChatServer1定位接收方所属ChatServer
ChatServer1调用UserMgr::GetSession(to_uid)未找到SessionB,则:
- 查Redis
uip:{to_uid}(day27),获取B所在的ChatServer地址(如“ChatServer2,IP=192.168.1.102,gRPC端口=50051”); - 若Redis无记录(B离线),直接存入MySQL
offline_msg表。
(2)差异步骤2:ChatServer1通过gRPC转发到ChatServer2
- ChatServer1通过
ChatGrpcClient(day27)调用ChatServer2的ForwardTextChat接口,传递TextChatReq; - 复用gRPC连接池(避免频繁握手),若调用失败(如ChatServer2临时不可用),触发断线重连(缓存消息,重连后重试)。
(3)差异步骤3:ChatServer2转发到客户端B
ChatServer2接收gRPC请求后,流程与单服场景的步骤3-4一致:反序列化→定位SessionB→推送消息→客户端B展示。
三、聊天数据的存储:分层存储(临时+持久化),兼顾效率与可靠性
聊天数据需区分“实时访问需求”和“长期保存需求”,采用“Redis临时缓存+MySQL持久化”的分层存储方案,避免单一存储的性能或可靠性瓶颈。
1. 实时缓存(Redis):支撑高频访问,提升效率
Redis存储“短期、高频访问”的聊天数据,避免频繁查询MySQL,核心存储内容:
| Redis键设计 | 存储内容示例 | 作用说明 | 过期策略 |
|---|---|---|---|
msg_id:{msg_id} | msg_id:uuid-123456 → 1 | 标记消息已处理,避免重复接收(服务端+客户端去重) | 24小时(消息处理完成后无需长期保存) |
uip:{uid} | uip:10002 → chatserver2 | 记录用户所属ChatServer,支撑跨服消息定位(day27) | 60秒(心跳续期,day35) |
session:uid:{uid} | 哈希结构,存储用户的会话列表(如“10001_10002”→最后消息时间) | 客户端拉取会话列表时快速查询,避免查MySQL | 7天(长期未活跃会话清理) |
friend_online:{uid} | friend_online:10001 → [10002, 10003] | 存储用户的在线好友列表,客户端展示“在线状态” | 60秒(心跳续期) |
2. 持久化存储(MySQL):长期保存,避免数据丢失
MySQL存储“需长期保存、不可丢失”的聊天数据,核心表结构参考day31:
| 数据表名 | 存储内容 | 作用说明 | 生命周期 |
|---|---|---|---|
offline_msg | 接收方离线时的消息(from_uid/to_uid/content/msg_id等) | 接收方上线后拉取,确保离线消息不丢失 | 7天(用户上线读取后可清理,或归档) |
chat_history | 用户的历史聊天记录(按会话ID分组,如“10001_10002”) | 用户查询历史消息(如“查看上周聊天记录”) | 3个月(超过后归档到冷存储,如OSS) |
user_msg_stat | 每个用户的消息统计(如“未读消息数”“总发送消息数”) | 客户端展示“未读红点”“消息统计” | 永久(随用户账号存在) |
3. 客户端本地存储:提升本地访问效率
客户端本地也会缓存部分聊天数据,减少网络请求:
- 最近消息缓存:本地数据库(如SQLite)存储最近100条聊天记录,用户切换聊天窗口时无需重新请求服务端;
- 未发送消息缓存:重连期间用户发送的消息,先存入本地队列(如
std::queue<TextChatReq>),重连后自动发送; - 会话列表缓存:本地缓存用户的会话列表,减少拉取会话列表的网络请求。
总结:聊天数据全链路核心逻辑
聊天数据的“产生→传递→存储”全链路,本质是“用户操作触发结构化封装→服务端中转确保实时传递→分层存储兼顾效率与可靠性”:
- 产生环节:补全元信息+Protobuf序列化,适配传输协议;
- 传递环节:单服直接转发,跨服依赖Redis定位+gRPC转发,确保实时性;
- 存储环节:Redis缓存高频临时数据,MySQL持久化核心数据,客户端本地缓存提升体验;
全链路均围绕IM场景“实时、可靠、不丢失”的需求设计,是llfcchat实现稳定聊天功能的核心支撑。
46.存储聊天数据的表如何设计,如何建立索引
结合llfcchat项目的聊天数据存储需求(离线消息不丢失、历史消息快速查询),聊天数据主要通过**offline_msg(离线消息表)** 和**chat_history(历史消息表)** 两张表存储,索引设计需完全贴合“高频查询场景”(如“查接收者的未读离线消息”“查会话的历史消息”),确保查询效率(毫秒级响应)。具体设计如下:
一、核心表设计:按“离线消息”与“历史消息”拆分
聊天数据需按“是否需实时推送”拆分为两张表,避免单表数据量过大(如历史消息积累后影响离线消息查询效率),两张表的字段设计均遵循“最小字段+必要元信息”原则,减少冗余。
1. 表1:offline_msg(离线消息表)—— 存储接收方离线时的消息
核心定位:接收方用户离线时,暂存消息;用户上线后拉取并标记已读,后续可清理或归档。
字段设计(MySQL 8.0+):
| 字段名 | 数据类型 | 长度/取值范围 | 是否主键 | 允许空 | 字段说明 |
|---|---|---|---|---|---|
msg_id | VARCHAR | 64 | 是 | 否 | 消息唯一ID(客户端生成的UUID,如“uuid-20240601-123456”),确保全局唯一,避免重复接收 |
from_uid | BIGINT | 20 | 否 | 否 | 发送者UID(关联user表的uid),用于展示发送者身份 |
to_uid | BIGINT | 20 | 否 | 否 | 接收者UID(关联user表的uid),核心查询字段(按接收者筛选离线消息) |
msg_type | TINYINT | 1(0=文本,1=图片,2=文件) | 否 | 否 | 消息类型,客户端按类型渲染(文本直接显示/图片加载URL) |
content | TEXT | - | 否 | 否 | 消息内容:文本消息存原文,图片/文件消息存云存储URL(如“https://xxx/123.jpg”) |
send_time | BIGINT | 13 | 否 | 否 | 发送时间戳(毫秒级,如1717200000000),用于按时间排序展示 |
is_read | TINYINT | 1(0=未读,1=已读) | 否 | 否 | 消息状态:用户上线拉取后设为1,未拉取前为0,用于筛选“未读离线消息” |
create_time | DATETIME | - | 否 | 否 | 记录插入时间(MySQL默认CURRENT_TIMESTAMP),用于数据清理(如7天未读消息归档) |
设计关键点:
- 主键用
msg_id(UUID),而非自增ID:避免分布式场景下多ChatServer插入时主键冲突; send_time用毫秒级时间戳(BIGINT):比DATETIME更便于跨时区处理和按时间范围查询(如“查1小时内的离线消息”);content用TEXT:兼容长文本消息(如500字以上),图片/文件仅存URL,避免表体积过大。
2. 表2:chat_history(历史消息表)—— 存储用户已读的历史聊天记录
核心定位:用户已读的消息(含离线拉取后标记已读的消息、在线实时接收的消息),支持“按会话查询历史”“按时间范围回溯”。
字段设计(MySQL 8.0+):
| 字段名 | 数据类型 | 长度/取值范围 | 是否主键 | 允许空 | 字段说明 |
|---|---|---|---|---|---|
history_id | BIGINT | 20 | 是 | 否 | 自增主键(AUTO_INCREMENT),唯一标识历史消息,便于单条消息操作(如删除) |
session_id | VARCHAR | 64 | 否 | 否 | 会话唯一标识,格式为“小UID_大UID”(如10001_10002),避免同一对话重复存储(如10002_10001) |
msg_id | VARCHAR | 64 | 否 | 否 | 关联offline_msg的msg_id,确保消息唯一(外键可选,避免强耦合) |
from_uid | BIGINT | 20 | 否 | 否 | 发送者UID,用于展示“谁发的消息” |
to_uid | BIGINT | 20 | 否 | 否 | 接收者UID,辅助筛选(如“查我发给某人的消息”) |
msg_type | TINYINT | 1(0=文本,1=图片,2=文件) | 否 | 否 | 消息类型,与offline_msg一致,确保渲染逻辑统一 |
content | TEXT | - | 否 | 否 | 消息内容,与offline_msg一致,避免重复处理 |
send_time | BIGINT | 13 | 否 | 否 | 发送时间戳,用于按时间排序(历史消息默认“新消息在后”) |
is_delete | TINYINT | 1(0=未删除,1=已删除) | 否 | 否 | 软删除标记:用户删除某条历史消息时,仅标记为1,不物理删除,支持“撤回”功能 |
设计关键点:
session_id是核心:按“小UID_大UID”生成(如10001和10002的会话ID固定为10001_10002),确保同一对话的消息集中存储,避免查询时需同时查“from_uid=A and to_uid=B”和“from_uid=B and to_uid=A”;- 自增主键
history_id:便于按“最新消息ID”分页查询(如“查会话10001_10002中,history_id小于1000的10条消息”),比按时间戳分页更高效; - 软删除
is_delete:支持“用户删除本地历史但对方仍可见”的IM常见需求,避免物理删除导致数据不一致。
二、索引设计:完全贴合高频查询场景
索引的核心目标是“加速高频查询,避免全表扫描”,需针对两张表的典型查询场景设计,优先使用联合索引(减少索引数量,提升查询效率),避免过度索引(增加插入/更新开销)。
1. offline_msg表索引设计(3个核心索引)
offline_msg的高频查询场景:“查接收者(to_uid)的未读(is_read=0)离线消息,按发送时间(send_time)升序排列”(用户上线拉取)、“标记某条消息为已读(按msg_id更新)”。
| 索引名称 | 索引类型 | 索引字段 | 索引顺序 | 适用场景 | 性能说明 |
|---|---|---|---|---|---|
idx_offline_to_isread | BTREE | to_uid, is_read, send_time | 正序 | 1. 查某用户的未读离线消息(where to_uid=? and is_read=0 order by send_time asc);2. 查某用户的所有离线消息( where to_uid=? order by send_time asc) | 联合索引覆盖查询条件和排序字段,无需回表,查询效率毫秒级 |
pk_offline_msgid | PRIMARY | msg_id | 正序 | 1. 按msg_id更新消息状态(update offline_msg set is_read=1 where msg_id=?);2. 按msg_id删除已归档消息( delete from offline_msg where msg_id=?) | 主键索引,更新/删除操作效率最高 |
idx_offline_from_send | BTREE | from_uid, send_time | 正序 | 查某发送者发给某接收者的离线消息(where from_uid=? and to_uid=? order by send_time asc) | 适配“消息撤回”场景(需确认离线消息是否存在) |
2. chat_history表索引设计(3个核心索引)
chat_history的高频查询场景:“查某会话(session_id)在某时间范围的历史消息,按发送时间(send_time)升序/降序排列”(用户滑动聊天窗口加载历史)、“查某条消息的详情(按msg_id)”。
| 索引名称 | 索引类型 | 索引字段 | 索引顺序 | 适用场景 | 性能说明 |
|---|---|---|---|---|---|
idx_history_session_send | BTREE | session_id, send_time, history_id | 正序 | 1. 查某会话的历史消息(where session_id=? order by send_time asc limit 20 offset 0);2. 查某会话在指定时间内的消息( where session_id=? and send_time between ? and ? order by send_time asc) | 联合索引覆盖“会话+时间范围+排序”,分页查询效率高,避免回表 |
idx_history_msgid | UNIQUE | msg_id | 正序 | 1. 按msg_id查询历史消息详情(select * from chat_history where msg_id=?);2. 避免重复插入同一条消息(唯一索引冲突时忽略) | 唯一索引确保消息不重复,查询效率等同于主键 |
idx_history_uid_send | BTREE | from_uid, to_uid, send_time | 正序 | 查某用户发给另一用户的所有历史消息(where from_uid=? and to_uid=? order by send_time asc) | 适配“单聊消息搜索”场景(如“查我发给A的所有图片消息”) |
三、设计原则与优化建议
- 按“查询场景”优先建索引:不盲目给每个字段建索引,仅针对“高频、全表扫描风险高”的查询设计索引(如
offline_msg的to_uid是必建索引,因几乎所有查询都按接收者筛选); - 字段类型“最小化”:如
msg_type用TINYINT(1字节)而非INT(4字节),is_read用TINYINT,减少表体积和索引大小,提升IO效率; - 历史消息归档策略:
chat_history表数据量会随时间增长(如万级用户每天产生百万条消息),建议:- 按“时间范围”分表:如每月建一张表(
chat_history_202406、chat_history_202407),查询时按时间路由到对应表; - 冷数据归档:超过3个月的历史消息迁移到“冷表”(如
chat_history_archive)或云存储(如OSS),主表仅保留近3个月数据,提升查询效率;
- 按“时间范围”分表:如每月建一张表(
- 避免外键强耦合:
chat_history的msg_id可关联offline_msg的msg_id,但不建议建物理外键(外键会增加插入/删除的锁开销,IM场景需高并发写入),可通过业务逻辑确保数据一致性。
47.如果离线消息过大,需要等所有数据发送完之后再删除吗,如果发送过程中服务断掉,那下一次要重复发送吗
针对离线消息过大时的“删除时机”和“发送中断重发”问题,llfcchat的解决方案核心是**“逐条/批量确认+状态标记”**,既避免“全部发送完再删”导致的中断后重复发送压力,也通过状态记录确保中断后不丢消息、不重复发送,具体设计如下:
一、离线消息过大:不等待全部发送完再删除,采用“确认一条/批量确认后处理”
若离线消息过大(如用户离线期间收到1000条消息),“等待全部发送完再删除”会存在两大风险:
- 发送中断后重复发送全部:若发送到500条时服务断掉,下次需重新发送1000条,浪费带宽和服务器资源;
- 数据库压力大:1000条消息长期存于
offline_msg表,查询和更新效率下降。
因此,采用“发送后即时确认,确认后立即处理(删除或归档)”的策略,平衡“可靠性”和“效率”:
1. 核心逻辑:基于“发送状态”的增量处理
在offline_msg表新增**send_status字段**(TINYINT,取值:0=待发送,1=发送中,2=已发送),用于跟踪消息的发送进度,具体流程:
- 用户上线拉取:客户端向ChatServer发送
PullOfflineMsgReq,携带“最后一次接收的消息ID”(避免重复拉取); - 服务端筛选待发送消息:ChatServer查询
offline_msg,筛选条件:to_uid=当前用户UID AND send_status=0 AND send_time>最后接收时间,按send_time升序排序; - 批量发送+即时确认:
- 服务端每次发送10条消息(批量大小可配置,避免单次发送过多导致网络阻塞),发送前将这些消息的
send_status更新为1(发送中); - 客户端收到消息后,立即返回
OfflineMsgAck,携带这10条消息的msg_id,表示“已成功接收”; - 服务端收到确认后,将这些消息的
send_status更新为2(已发送),并立即删除或归档(删除:直接从offline_msg表删除;归档:迁移到offline_msg_archive表,便于后续追溯);
- 服务端每次发送10条消息(批量大小可配置,避免单次发送过多导致网络阻塞),发送前将这些消息的
- 循环直至全部发送:重复步骤3,直到所有待发送消息处理完毕。
2. 优势:中断后仅重发“未确认”消息
若发送过程中服务断掉(如ChatServer重启、网络中断),下次用户重新拉取时:
- 服务端仅筛选
send_status=0(未发送)和send_status=1(发送中,可能未成功)的消息,无需重发已确认(send_status=2)的消息; - 对于
send_status=1的消息,服务端先向客户端查询“是否已收到”,未收到则重新发送,收到则标记为2并删除,避免重复。
3. 特殊处理:超大体积消息(如大文件/长文本)
若单条离线消息体积过大(如10MB的文件URL+描述信息),拆分“元数据发送”和“内容拉取”:
- 服务端先发送“消息元数据”(
msg_id、from_uid、msg_type、file_size、file_url); - 客户端确认收到元数据后,服务端标记
send_status=2,并删除offline_msg中的记录; - 客户端后台异步拉取文件内容(从云存储URL下载),即使拉取中断,也只需重新下载文件,无需重发消息元数据。
二、发送过程中服务断掉:基于“状态记录”的重复发送,避免丢失和重复
发送中断(服务断连、网络波动)是高频场景,核心是“确保未发送的消息不丢失,已发送的消息不重复”,依赖“服务端状态持久化”和“客户端幂等处理”:
1. 服务端:状态持久化,重启后恢复进度
关键是将“发送状态”存储在MySQL(而非内存),确保服务重启后状态不丢失:
send_status字段持久化在offline_msg表,服务重启后可直接查询;- 对于“发送中”(
send_status=1)的消息,服务端重启后会主动向客户端发起“状态确认”,避免遗漏。
2. 客户端:幂等处理,避免重复接收
即使服务端因中断重发消息,客户端也需确保“不重复展示、不重复处理”,核心是“消息ID去重”:
- 本地缓存已接收的消息ID:客户端维护“离线消息接收列表”(如
std::unordered_set<std::string>),存储已成功接收的msg_id; - 接收消息时先去重:客户端收到离线消息后,先检查
msg_id是否在缓存中:- 若存在:直接丢弃,不做任何处理;
- 若不存在:添加到缓存,正常渲染展示,并返回确认给服务端;
- 缓存持久化:客户端将“已接收的消息ID”存储到本地数据库(如SQLite),避免客户端重启后缓存丢失。
3. 极端场景:服务端未记录状态,客户端未缓存
若服务端send_status字段异常(如数据库损坏),且客户端本地缓存丢失,通过“消息时间戳+内容校验”兜底:
- 客户端向服务端发送“最近一次正常接收的消息时间戳”;
- 服务端按
send_time大于该时间戳的条件发送消息,客户端接收后对比“消息内容+发送者”,若与本地历史消息完全一致(排除重复发送),则丢弃;若不一致,则视为新消息处理。
三、总结:核心设计原则
- 不等待全部发送完删除:采用“确认一条/批量确认后处理”,减少中断后的重复发送压力,降低数据库存储成本;
- 状态持久化是关键:服务端用MySQL记录
send_status,客户端用本地缓存记录已接收msg_id,确保中断后状态可恢复; - 幂等处理防重复:依赖
msg_id唯一标识,客户端接收时先去重,避免重复展示和处理。
该方案完全贴合llfcchat的现有架构(MySQL存储、TCP长连接),无需新增复杂组件,仅需扩展offline_msg表字段和客户端/服务端的状态处理逻辑,即可实现“大离线消息”的可靠、高效处理。
48.如何实现A发消息给B,服务器如何识别不同客户端并实现消息转发
在llfcchat项目中,A发消息给B的核心是**“服务器通过‘UID-Session’唯一绑定识别客户端,再通过‘本地定位/跨服定位’实现精准转发”**,整个流程依赖Session管理、身份校验、全局状态存储三大组件,具体拆解如下(贴合day16 Session、day17 UserMgr、day27 分布式定位):
一、前提:服务器如何识别不同客户端?—— 基于“UID-Session”的唯一绑定
服务器要区分不同客户端(如A的手机、B的电脑),核心是建立“用户身份(UID)→ 连接会话(Session)→ 物理连接(Socket) ”的唯一映射,确保每个客户端都有专属标识,具体实现分3步:
1. 客户端登录时:创建Session,绑定UID与Socket
客户端(如A的手机)完成登录流程后(day14),会与分配的ChatServer建立TCP长连接,此时ChatServer会:
- 创建Session对象:每个客户端连接对应一个
Session实例(day16),存储核心信息:uid:客户端登录用户的唯一ID(如A的UID=10001),从登录Token中解析;socket:与客户端绑定的TCP Socket句柄(如asio::ip::tcp::socket),用于后续发送消息;device_id:客户端设备唯一标识(如“android_123456”),区分同一用户的不同设备;last_heartbeat_time:最后一次心跳时间,判断连接是否存活。
- 注册到UserMgr:将
Session对象通过UserMgr::AddSession(uid, session_ptr)(day17)注册到全局Session管理器,形成“uid→Session”的映射表(如10001→SessionA)。
2. 身份校验:确保客户端身份合法,避免伪造
服务器识别客户端的前提是“身份可信”,通过两层校验防止非法客户端混入:
- 连接建立时的Token校验:客户端建立TCP长连接后,需发送
QuickAuthReq(day17),携带uid和登录Token;ChatServer查询Redisutoken:{uid}(day09),验证Token有效性,无效则断开连接。 - 消息发送时的UID绑定校验:客户端发送消息(如A发消息给B)时,消息中会携带
from_uid(A的UID=10001);ChatServer会校验“该消息对应的Socket连接,是否与UserMgr中10001绑定的Session一致”,不一致则拒绝转发(防止伪造他人身份发消息)。
3. 连接存活管理:实时更新Session状态
为确保“UID→Session”的映射始终有效(如客户端断连后及时清理),ChatServer通过:
- 心跳检测:客户端每30秒发送心跳包(day35),ChatServer收到后更新Session的
last_heartbeat_time;若超过60秒未收到心跳,判定连接失效,调用UserMgr::RemoveSession(uid)删除映射,同时更新Redisuip:{uid}(标记用户离线)。 - 主动断连清理:客户端主动退出时,会发送
LogoutReq,ChatServer收到后立即清理Session和UserMgr映射。
二、A发消息给B:服务器的转发流程(分单服/跨服场景)
当A的客户端发送消息给B时,服务器会先“解析消息→定位B的客户端→转发消息”,根据A和B是否在同一ChatServer,分为两种场景:
场景1:A和B在同一ChatServer(单服转发,最常见)
若A(UID=10001)和B(UID=10002)均连接ChatServer1,转发流程直接高效:
步骤1:A的客户端发送消息,ChatServer1解析
- A的客户端封装消息为
TextChatReq(Protobuf,day22),包含from_uid=10001、to_uid=10002、content=“Hi”、msg_id=“uuid-xxx”,添加TCP长度前缀后发送给ChatServer1; - ChatServer1的SessionA(A的Session)通过
asio::async_read接收数据,拆包+反序列化为TextChatReq,执行基础校验:- 校验
from_uid是否已注册(UserMgr中存在10001的Session); - 校验A和B是否为好友(查Redis
friend_relation:{10001},day26),非好友则拒绝转发(按业务需求配置); - 校验
msg_id是否重复(查Redismsg_id:{uuid-xxx},避免重复转发)。
- 校验
步骤2:ChatServer1定位B的客户端(通过UserMgr)
ChatServer1调用UserMgr::GetSession(10002)(B的UID),查询B的Session:
- 若找到SessionB(B在线):获取SessionB绑定的Socket句柄,进入下一步转发;
- 若未找到SessionB(B离线):将消息存入MySQL
offline_msg表(day31),待B上线后拉取,流程终止。
步骤3:ChatServer1转发消息给B的客户端
- 封装转发消息:ChatServer1将
TextChatReq转换为TextChatNotify(补充B需要的展示信息,如A的昵称from_name=“A”、头像from_avatar=“url”),避免暴露A的敏感信息; - 发送消息:通过SessionB的
asio::async_write,将TextChatNotify序列化+加TCP长度前缀后,发送到B的客户端Socket; - 发送确认:向A的客户端返回
TextChatRsp,告知“消息已送达B”(若B离线则返回“B已离线,消息将稍后送达”)。
步骤4:B的客户端接收并展示
B的客户端通过QTcpSocket接收数据,拆包+反序列化为TextChatNotify,校验msg_id去重后(本地缓存已接收的msg_id),调用UI接口在气泡对话框展示消息。
场景2:A和B在不同ChatServer(跨服转发,分布式场景)
若A连接ChatServer1、B连接ChatServer2,需通过“ChatServer1→Redis定位→ChatServer2”跨服转发,核心依赖Redis的全局状态存储(day27):
步骤1-2:与单服场景一致(A发消息→ChatServer1解析)
ChatServer1解析消息后,调用UserMgr::GetSession(10002)未找到B的Session,进入跨服定位。
步骤3:ChatServer1通过Redis定位B的ChatServer
ChatServer1查询Redisuip:{10002}(day27),获取B所在的ChatServer信息:
- Redis返回“ChatServer2的IP=192.168.1.102,gRPC端口=50051”(B登录时,ChatServer2会更新
uip:{10002}为自身地址); - 若Redis无记录(B离线),将消息存入MySQL
offline_msg表,流程终止。
步骤4:ChatServer1通过gRPC转发给ChatServer2
- 封装gRPC请求:ChatServer1创建
ForwardTextChatReq(Protobuf),包含TextChatReq的完整信息和B的UID=10002; - 复用gRPC连接:通过ChatServer1的
ChatGrpcClient连接池(day27),调用ChatServer2的ForwardTextChat接口,发送跨服请求; - 故障重试:若gRPC调用失败(如ChatServer2临时不可用),ChatServer1会缓存消息,每隔1秒重试,直至成功或超过重试次数(如3次,失败则存入离线表)。
步骤5:ChatServer2转发给B的客户端
ChatServer2接收gRPC请求后,流程与单服场景的步骤3-4一致:
- 解析
ForwardTextChatReq,调用UserMgr::GetSession(10002)找到SessionB; - 封装
TextChatNotify,发送给B的客户端; - 通过gRPC向ChatServer1返回“转发成功”,ChatServer1再告知A的客户端“消息已送达”。
三、核心总结:识别与转发的关键逻辑
服务器识别不同客户端的核心是“UID与Session的唯一绑定”,通过UserMgr管理映射、心跳维护存活;消息转发的核心是“精准定位接收方客户端”——单服通过UserMgr本地查询,跨服通过Redis全局定位,最终通过TCP长连接或gRPC实现可靠传递,确保A的消息能高效、准确地送达B。

















 172
172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









