




 本文详细探讨了C++和Java中的泛型编程,包括泛型的基本概念、语法、使用场景和细节。在C++中,介绍了函数模板和类模板,以及模板的实例化、特化和分离编译。在Java中,阐述了泛型的引入、语法、使用和通配符的运用。此外,还讨论了泛型和模板在代码复用、类型安全性等方面的优势和潜在问题。
本文详细探讨了C++和Java中的泛型编程,包括泛型的基本概念、语法、使用场景和细节。在C++中,介绍了函数模板和类模板,以及模板的实例化、特化和分离编译。在Java中,阐述了泛型的引入、语法、使用和通配符的运用。此外,还讨论了泛型和模板在代码复用、类型安全性等方面的优势和潜在问题。

请回答C++【C++ 模板plus】
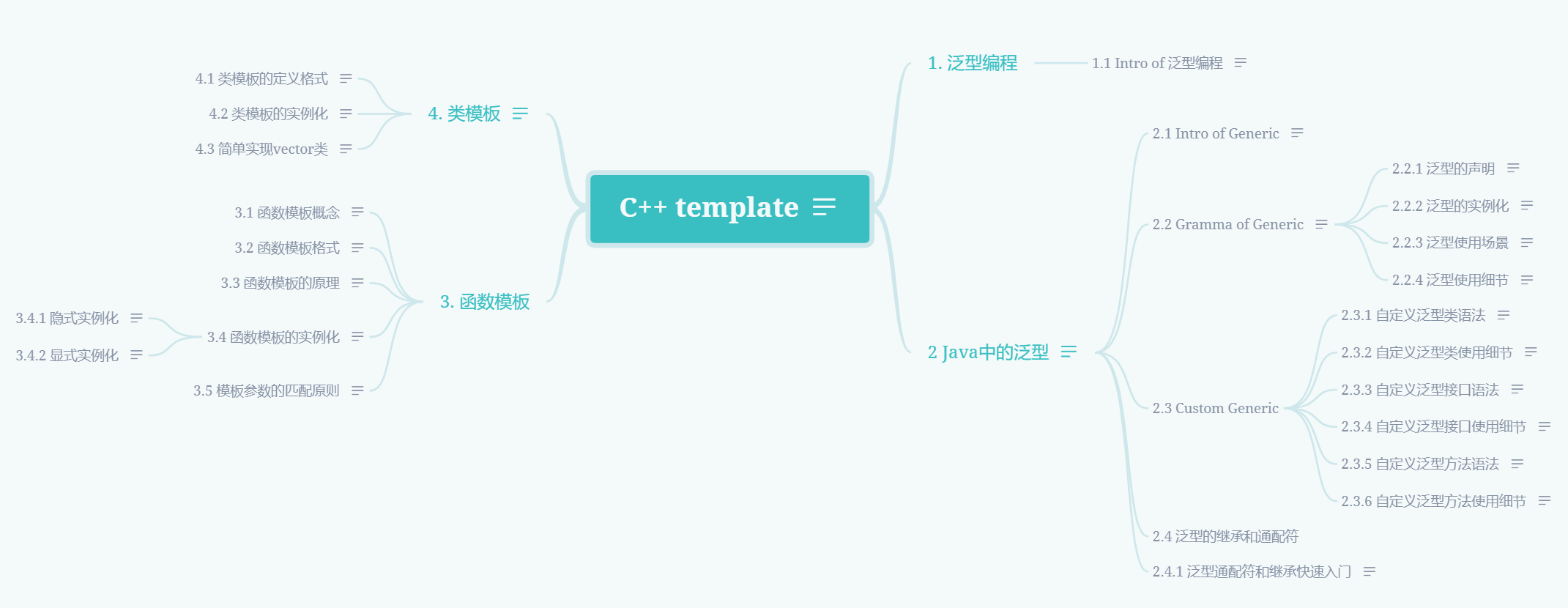
1. 泛型编程
1.1 Intro of 泛型编程
泛型注重解决的还是C语言的缺陷,直接上难以简单实现一个通用的交换函数呢,又不支持重载,很麻烦
void Swap(int& left, int& right)
{
int temp = left;
left = right;
right = temp;
}
void Swap(double& left, double& right)
{
double temp = left;
left = right;
right = temp;
}
void Swap(char& left, char& right)
{
char temp = left;
left = right;
right = temp;
}
仅通过Cpp的重载可以实现吗?
使用函数重载虽然可以实现,但是有一下几个不好的地方:
🍁 重载的函数仅仅只是类型不同,代码的复用率比较低,只要有新类型出现时,就需要增加对应的函数
🍁 代码的可维护性比较低,一个出错可能所有的重载均出错
那能否告诉编译器一个模子,让编译器根据不同的类型利用该模子来生成代码呢?
在C++中,存在这样一个模具,通过给这个模具中填充不同材料(类型),来获得不同材料的铸件(生成具体类型的代码)
泛型编程:编写与类型无关的通用代码,是代码复用的一种手段。模板是泛型编程的基础。、

2 Java中的泛型
老样子回顾一下Java中的泛型
2.1 Intro of Generic
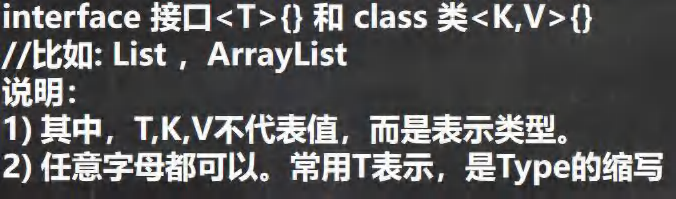
首先泛型在于数据类型的广泛,泛(广泛)型(类型) => Integer, String, Dog
🍁 泛型又称参数化类型,是Jdk5.0出现的新特性,解决数据类型的安全性问题
🍁 在类声明或实例化时只要指定好需要的具体的类型即可。
🍁 Java泛型可以保证如果程序在编译时没有发出警告,运行时就不会产生ClassCastException异常。同时,代码更加简洁、健壮
🍁 泛型的作用是:可以在类声明时通过一个标识表示类中某个属性的类型,或者是某个方法的返回值的类型,或者是参数类型。
2.2 Gramma of Generic
泛型常常和Java中的几个Collection或者Map结合在一起
2.2.1 泛型的声明
2.2.2 泛型的实例化
要在类名后面指定类型参数的值(类型)。
//1.
List<String> strList = new ArrayList<String>():
//2.
Iterator<Customer> iterator = customers.iterator();
2.2.3 泛型使用场景
//使用泛型方式给HashSet 放入3 个学生对象
HashSet<Student> students = new HashSet<Student>();
students.add(new Student("pikachu", 18));
students.add(new Student("Raichu", 28));
students.add(new Student("Pichu", 19));
//遍历
for (Student student : students) {
System.out.println(student);
}
//使用泛型方式给HashMap 放入3 个学生对象
//K -> String V->Student
HashMap<String, Student> hm = new HashMap<String, Student>();
hm.put("milan", new Student("Charmeleon", 38));
hm.put("smith", new Student("Charizard", 48));
hm.put("hsp", new Student("Charmander", 28));
//迭代器EntrySet
Set<Map.Entry<String, Student>> entries = hm.entrySet();
Iterator<Map.Entry<String, Student>> iterator = entries.iterator();
while (iterator.hasNext()) {
Map.Entry<String, Student> next = iterator.next();
System.out.println(next.getKey() + "-" + next.getValue());
}
2.2.4 泛型使用细节
🍁 T,E只能是引用类型,不能是基本数据类型
List<Integer> list = new ArrayList<Integer>();//OK
List<int> list2 = new ArrayList<int>();//错误
🍁 在给泛型指定具体类型后,可以传入该类型或者其子类类型
🍁 泛型使用形式
List<Integer> list1 = new ArrayList<Integer>();
List<Integer> list2 = new ArrayList<>();
List list3 = new ArrayList();//如果我们这样写,默认给它的 泛型是[<E> E就是 Object ]
2.3 Custom Generic
2.3.1 自定义泛型类语法
class 类名 <T, R...>(//表示可以有多个泛型
成员
}
倘若类中这么定义

使用的时候就可以这样使用
Tiger<Double,String,Integer> g1 = new Tiger<>("muzii");
g.setT(10); //OK
//g.setT("yy"); //错误,类型不对
Tiger g2 = new Tiger("john~~");//OK T=Object R=Object M=Object
g2.setT("yy"); //OK ,因为T=Object "yy"=String 是Object 子类
//Tiger 中
public void setR(R r) {//方法使用到泛型
this.r = r;
}
public M getM() {//返回类型可以使用泛型.
return m;
}
2.3.2 自定义泛型类使用细节
🍁 普通成员可以使用泛型(属性、方法)
🍁 方向标识符可以有多个,一般是单个大写字母
🍁 使用泛型的数组,不能初始化
🍁 泛型类的类型,是在创建对象时确定的(因为创建对象时,需要指定确定类型)
🍁 静态方法中不能使用类的泛型,因为静态是和类相关的,在类加载时,对象还没有创建如果静态方法和静态属性使用了泛型,JVM 就无法完成初始化
🍁 如果在创建对象时,没有指定类型,默认为Object
2.3.3 自定义泛型接口语法
interface 接口名<T, R...> {
}
2.3.4 自定义泛型接口使用细节
🍁 接口中,静态成员也不能使用泛型(这个和泛型类规定一样)
🍁 泛型接口的类型,在继承接口或者实现接口时确定
🍁 没有指定类型,默认为Object
//在继承接口指定泛型接口的类型
interface IA extends IUsb<String, Double> {
}
//当我们去实现IA 接口时,因为IA 在继承IUsu 接口时,指定了U 为String R 为Double
//在实现IUsu 接口的方法时,使用String 替换U, 是Double 替换R
class AA implements IA {
@Override
public Double get(String s) {
return null;
}
@Override
public void hi(Double aDouble) {
}
@Override
public void run(Double r1, Double r2, String u1, String u2) {
}
}
//实现接口时,直接指定泛型接口的类型
//给U 指定Integer 给R 指定了Float
//所以,当我们实现IUsb 方法时,会使用Integer 替换U, 使用Float 替换R
class BB implements IUsb<Integer, Float> {
//省略
}
//没有指定类型,默认为Object
//建议直接写成IUsb<Object,Object>
class CC implements IUsb { //等价class CC implements IUsb<Object,Object>
//省略
}
interface IUsb<U, R> {
//U name; 不能这样使用
//普通方法中,可以使用接口泛型
R get(U u);
void hi(R r);
void run(R r1, R r2, U u1, U u2);
//在jdk8 中,可以在接口中,使用默认方法, 也是可以使用泛型
default R method(U u) {
return null;
}
}
2.3.5 自定义泛型方法语法
修饰符 <T,R..> 返回类型方法名(参数列表){
}
2.3.6 自定义泛型方法使用细节
🍁 泛型方法,可以定义在普通类中,也可以定义在泛型类
//泛型方法,可以定义在普通类中, 也可以定义在泛型类中
class Car {//普通类
public void run() {//普通方法
}
//1. <T,R> 就是泛型
//2. 是提供给fly 使用的
public <T, R> void fly(T t, R r) {//泛型方法
}
}
class Fish<T, R> {//泛型类
public void run() {//普通方法
}
public<U,M> void eat(U u, M m) {//泛型方法
}
//1. 下面hi 方法不是泛型方法
//2. 是hi 方法使用了类声明的泛型
public void hi(T t) {
}
//泛型方法,可以使用类声明的泛型,也可以使用自己声明泛型
public<K> void hello(R r, K k) {
}
}
🍁 当泛型方法被调用时,类型会确定
🍁 public void eat(E e) {}修饰符后没有<T,R..> 方法不是泛型方法,而是使用了泛型
2.4 泛型的继承和通配符
2.4.1 泛型通配符和继承快速入门
🍁 泛型不具备继承性
List<Object> list = new ArrayList<String>(0): //不对
🍁 <?> :支持任意泛型类型
🍁 <? extends A>:支持A类以及A类的子类,规定了泛型的上限
🍁 <? super A>:支持A类以及A类的父类,不限于直接父类,规定了泛型的下限
//如果是List<?> c ,可以接受任意的泛型类型
//List<? extends AA> c: 表示上限,可以接受AA 或者AA 子类
//List<? super AA> c: 支持AA 类以及AA 类的父类,不限于直接父类
// ? extends AA 表示上限,可以接受AA 或者AA 子类
public static void printCollection2(List<? extends AA> c) {
for (Object object : c) {
System.out.println(object);
}
}
//说明: List<?> 表示任意的泛型类型都可以接受
public static void printCollection1(List<?> c) {
for (Object object : c) { // 通配符,取出时,就是Object
System.out.println(object);
}
}
// ? super 子类类名AA:支持AA 类以及AA 类的父类,不限于直接父类,
//规定了泛型的下限
public static void printCollection3(List<? super AA> c) {
for (Object object : c) {
System.out.println(object);
}
}
class AA {
}
class BB extends AA {
}
class CC extends BB {
}
3. 函数模板
3.1 函数模板概念
函数模板代表了一个函数家族,该函数模板与类型无关,在使用时被参数化,根据实参类型产生函数的特定类型版本。
3.2 函数模板格式
typename是用来定义模板参数关键字,也可以使用class(切记:不能使用struct代替class)
template<typename T1, typename T2,......,typename Tn>
或者
template<class T1,class T2,......,class Tn>
返回值类型 函数名(参数列表){}
譬如用模板写一个Swap函数
template<class T>
void Swap( T& left, T& right)
{
T temp = left;
left = right;
right = temp;
}
3.3 函数模板的原理
函数模板本身并不是函数,是编译器用使用方式产生特定具体类型函数的模具。本来我们需要写的代码,然后不想写重复给你一个模板,编译器通过模板,帮我们生成了对应数据类型的代码
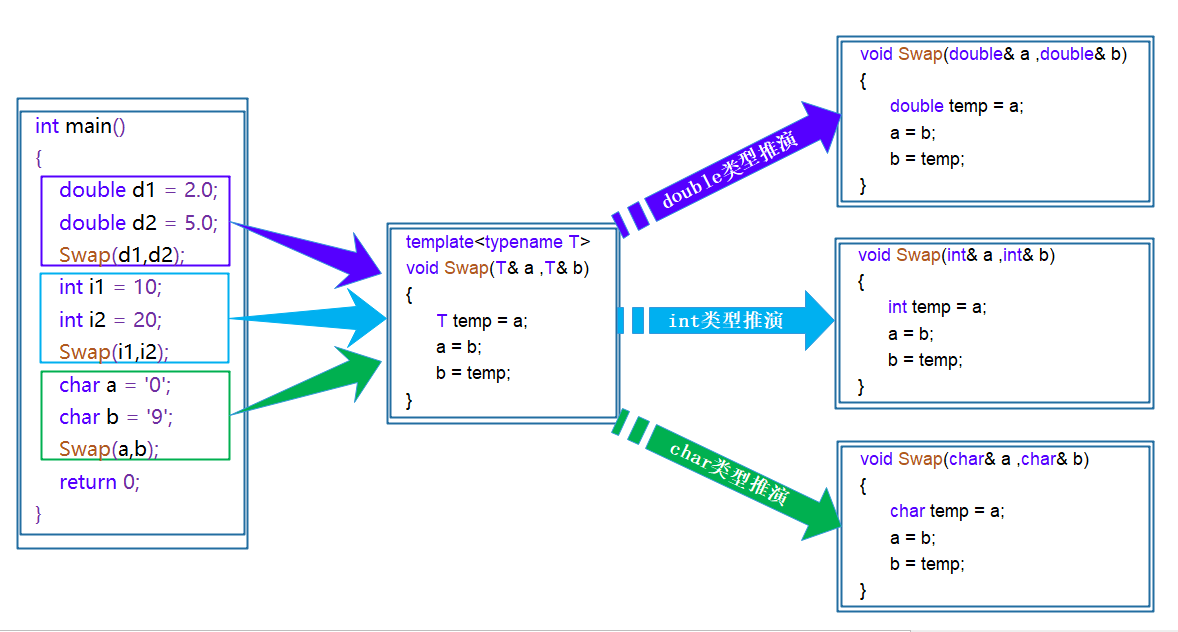
在编译器编译阶段,对于模板函数的使用,编译器需要根据传入的实参类型来推演生成对应类型的函数以供调用。比如:当用double类型使用函数模板时,编译器通过对实参类型的推演,将T确定为double类型,然后产生一份专门处理double类型的代码,对于字符类型也是如此。
3.4 函数模板的实例化
用不同类型的参数使用函数模板时,称为函数模板的实例化。模板参数实例化分为:隐式实例化和显式实例化。
当然像上面的Swap函数,传进去的参数不可以是两个不同类型的参数,因为这是不匹配的,编译器推不出来,直接报错了
3.4.1 隐式实例化
而如果写一个Add函数的话,写了一个Float型和一个Double型的话,编译器会自动调用隐式实例化
template<class T>
T Add(const T& left, const T& right)
{
return left + right;
}
int main()
{
int a = 1, b = 2;
double c = 1.1, d = 2.2;
// 编译器会通过实参推形参的类型T分别为int和double
// 这种方式是隐式实例化
cout << Add(a, b) << endl;
cout << Add(c, d) << endl;
/*
cout << Add(a, c) << endl;//这个不太行
该语句不能通过编译,因为在编译期间,当编译器看到该实例化时,需要推演其实参类型
通过实参a1将T推演为int,通过实参d1将T推演为double类型,但模板参数列表中只有一个T,
编译器无法确定此处到底该将T确定为int 或者 double类型而报错
注意:在模板中,编译器一般不会进行类型转换操作,因为一旦转化出问题,编译器就需要背黑锅
*/
// 此时有两种处理方式:1. 用户自己来强制转化 2. 使用显式实例化
cout << Add(a, (int)c) << endl;
return 0;
}
3.4.2 显式实例化
显式实例化:在函数名后的<>中指定模板参数的实际类型
int main(void)
{
int a = 10;
double b = 20.0;
// 显式实例化
Add<int>(a, b);
return 0;
}
3.5 模板参数的匹配原则
🍁 一个非模板函数可以和一个同名的函数模板同时存在,而且该函数模板还可以被实例化为这个非模板函数
// 专门处理int的加法函数
int Add(int left, int right)
{
return left + right;
}
// 通用加法函数
template<class T>
T Add(T left, T right)
{
return left + right;
}
void Test()
{
Add(1, 2); // 与非模板函数匹配,编译器不需要特化
Add<int>(1, 2); // 调用编译器特化的Add版本
}
🍁 对于非模板函数和同名函数模板,如果其他条件都相同,在调动时会优先调用非模板函数而不会从该模板产生出一个实例。如果模板可以产生一个具有更好匹配的函数, 那么将选择模板
// 专门处理int的加法函数
int Add(int left, int right)
{
return left + right;
}
// 通用加法函数
template<class T1, class T2>
T1 Add(T1 left, T2 right)
{
return left + right;
}
void Test()
{
Add(1, 2); // 与非函数模板类型完全匹配,不需要函数模板实例化
Add(1, 2.0); // 模板函数可以生成更加匹配的版本,编译器根据实参生成更加匹配的Add函数
}
🍁 模板函数不允许自动类型转换,但普通函数可以进行自动类型转换
4. 类模板
类模板和函数模板稍有不同
先思考C语言同样也可以实现为什么还会有类模板,说明C语言还会产生一些问题
//类模板
//typedef int VDataType;
typedef double VDataType;
class vector
{
public:
//略
private:
VDataType* _a;
int _size;
int _capacity;
};
int main()
{
vector v1; // int
vector v2; // double
return 0;
}
这样写的话我想让v1存的是int,v2存的是double,这样不可以只能再写一个vector类,然而这两个类的实现是很像的,还是没能够很好的解决问题
C++利用模板来解决问题
template<class T>
class vector
{
public:
private:
T* _a;
int _size;
int _capacity;
};
4.1 类模板的定义格式
template<class T1, class T2, ..., class Tn>
class 类模板名
{
// 类内成员定义
};
4.2 类模板的实例化
类模板实例化与函数模板实例化不同,类模板实例化需要在类模板名字后跟<>,然后将实例化的类型放在<>中即可,类模板名字不是真正的类,而实例化的结果才是真正的类。
vector<int> v1; // int
vector<double> v2; // double
4.3 简单实现vector类
namespace allen
{
template<class T>
class vector
{
public:
vector()
:_a(nullptr)
, _size(0)
, _capacity(0)
{}
~vector()
{
delete[] _a;
_a = nullptr;
_size = _capacity = 0;
}
//拷贝构造和operator= 涉及深拷贝
void push_back(const T& x)
{
if (_size == _capacity)
{
int newcapacity = (_capacity == 0) ? 4 : _capacity * 2;
T* tmp = new T[newcapacity];
if (_a)
{
memcpy(tmp, _a, sizeof(T)* _size);
delete[] _a;
}
_a = tmp;
_capacity = newcapacity;
}
_a[_size++] = x;
}
//引用返回完成读+写
T& operator[] (size_t pos)
{
assert(pos < _size);
return _a[pos];
}
size_t size()
{
return _size;
}
private:
T* _a;
size_t _size;
size_t _capacity;
};
}
int main()
{
allen::vector<int> v1;
v1.push_back(3);
v1.push_back(4);
for (int i=0;i<v1.size();i++)
{
cout << v1[i] << " ";
}
cout << endl;
allen::vector<double> v2;
v2.push_back(3.1);
v2.push_back(4.2);
for (int i = 0; i < v2.size(); i++)
{
cout << v2[i] << " ";
}
cout << endl;
return 0;
}
小结:
模板不支持分离编译,也就是声明在.h ,定义在.cpp
建议定义在一个文件 xxx.h xxx.hpp
2022-04-12 更新 模板plus
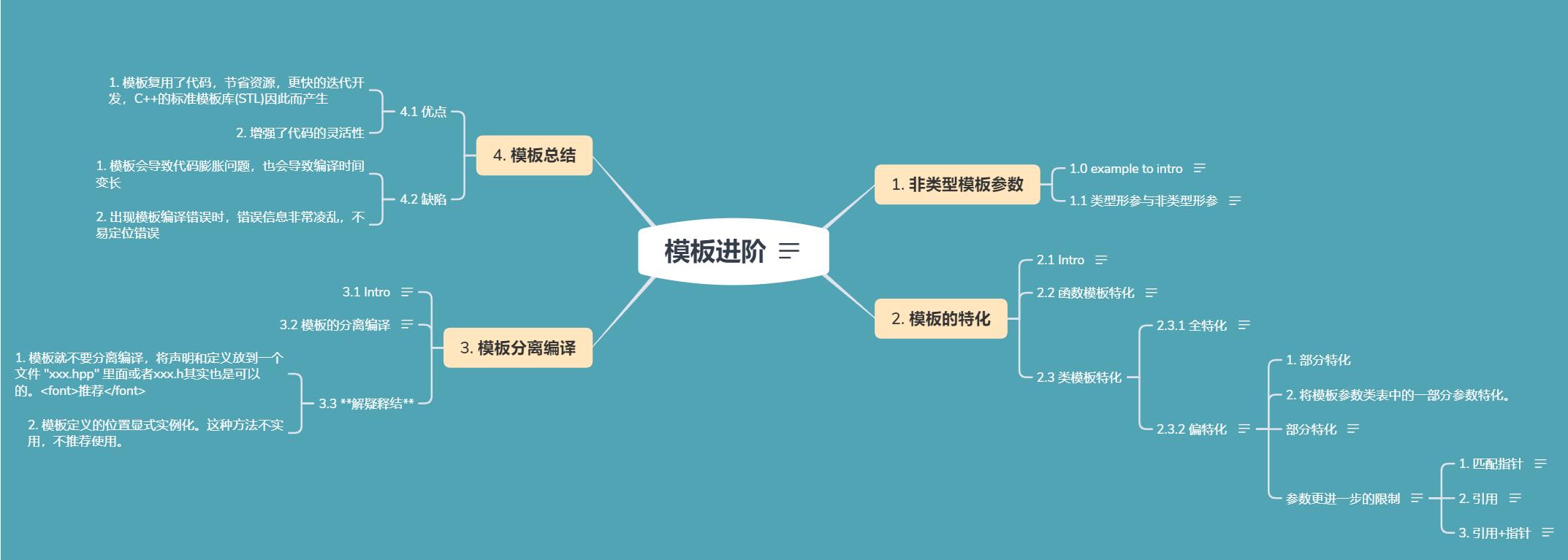
1. 非类型模板参数
1.0 example to intro
template<class T = int>
class Array
{
public:
private:
T _a[N];
};
int main()
{
Array<int> aa1; // 100
Array<int> aa2; // 1000
Array<int> aa3; // 10000
return 0;
}
通过上面的例子引出一个观点,我希望上面的数组其中aa1最多存储100个,aa2最多存储1000个,aa3最多存储10000个
于是c++提供了新的方法
1.1 类型形参与非类型形参
模板参数分类类型形参与非类型形参。
类型形参:出现在模板参数列表中,跟在class或者typename之类的参数类型名称。
非类型形参:就是用一个常量作为类(函数)模板的一个参数,在类(函数)模板中可将该参数当成常量来使用。
非类型模板参数: 这里传入的就是整形常量
template<class T = int, size_t N =10 >
class Array
{
public:
void f()
{
N = 1000; // 不行 会报错
}
private:
T _a[N];
};
int main()
{
Array<int,100> aa1; // 100
Array<int,1000> aa2; // 1000
Array<int,10000> aa3; // 10000
return 0;
}
这里面的N是一个左值,是不能够修改的,所以f()函数会报错,不过我们倒是可以选择缺省,不传就可以选择缺省值
⚠️ 浮点数、类对象以及字符串是不允许作为非类型模板参数的。
⚠️ 非类型的模板参数必须在编译期就能确认结果。
2. 模板的特化
2.1 Intro
之前说过模板的意义是帮我们做重复的事情,我们可以在函数模板和类模板的时候使用
有时候编译器m默认实例化函数模板或者类模板不能正确处理需要逻辑,需要针对一些特殊情况进行
通常情况下,使用模板可以实现一些与类型无关的代码,但对于一些特殊类型的可能会得到一些错误的结
果:
template<class T>
bool IsEqual(const T& left, const T& right)
{
return left == right;
}
// 针对字符串类型要特殊化处理 -- 写一份函数模板的特殊出来
template<class T>
bool IsEqual<const char*>(const char* const& left, const char* const& right)
{
return strcmp(left, right) == 0;
}
如果不单独来一份模板的话就会出现问题,按道理来说其实我想得到的是相等,收到的却是不相等
int main()
{
char p1[] = "hello";
char p2[] = "hello";
cout << IsEqual(p1, p2) << endl;
const char* p3 = "hello";
const char* p4 = "hello";
cout << IsEqual(p3, p4) << endl;
return 0;
}
这里p3和p4指向的是一个同一个常量字符串。C/C++会把常量字符串存储到单独的一个内存区域,当几个指针指向同一个字符串的时候,他们实际会指向同一块内存。但是用相同的常量字符串去初始化不同的数组的时候就会开辟出不同的内存块。所以说当前结果下就是输出0、1,也就是编译器认为p1p2是不同的,而p3p4是相同的
应该使用strcmp去比较字符串,这就是模板的特化
2.2 函数模板特化
函数模板的特化步骤:
🍁 必须要先有一个基础的函数模板
🍁 关键字template后面接一对空的尖括号<>
🍁 函数名后跟一对尖括号,尖括号中指定需要特化的类型
🍁 函数形参表: 必须要和模板函数的基础参数类型完全相同,如果不同编译器可能会报一些奇怪的错误。
template<>
bool IsEqual <const char*>(const char* const& left, const char* const& right)
{
return strcmp(left, right) == 0;
}
bool IsEqual(const char* const& left, const char* const& right)
{
return strcmp(left, right) == 0;
}
上面一种写法采用的是一种规范的标准写法
下面一种方法直接提供了一种情况,专门针对字符串,编译器会优先调用
注意:一般情况下如果函数模板遇到不能处理或者处理有误的类型,为了实现简单通常都是将该函数直接给出。
2.3 类模板特化
2.3.1 全特化
全特化即是将模板参数列表中所有的参数都确定化。
template<class T1, class T2>
class Pikachu
{
public:
Pikachu() { cout << "Pikachu<T1, T2>" << endl; }
private:
T1 _d1;
T2 _d2;
};
// 假设针对T1 T2是 int int想做一些特殊化那么怎么办 ? -- 类模板特化
// -- 全特化
template<>
class Pikachu < int, int >
{
public:
Pikachu() { cout << "Pikachu<int, int>" << endl; }
};
int main()
{
Pikachu<int, int> d1;
Pikachu<int, double> d2;
return 0;
}
由此可以看出特化的本质

2.3.2 偏特化
偏特化有点类似于缺省参数,但是不一定是指定一半的参数,有时候是指定类型
偏特化:任何针对模版参数进一步进行条件限制设计的特化版本。
偏特化有以下两种表现方式:
- 部分特化
- 将模板参数类表中的一部分参数特化。
部分特化
// 将第二个参数特化为int --偏特化
template <class T1>
class Pikachu < T1, int >
{
public:
Pikachu() { cout << "Pikachu<T1, int>" << endl; }
};
编译器原则是匹配参数的时候匹配的是最匹配的那一个
参数更进一步的限制
偏特化并不仅仅是指特化部分参数,而是针对模板参数更进一步的条件限制所设计出来的一个特化版
本。
- 匹配指针
// 偏特化 指定如何模板参数是指针
template <class T1, class T2>
class Pikachu <T1*, T2*>
{
public:
Pikachu() { cout << "Pikachu<T1*, T2*>" << endl; }
};
- 引用
template <class T1, class T2>
class Pikachu < T1&, T2& >
{
public:
Pikachu() { cout << "Pikachu<T1&, T2&>" << endl; }
};
- 引用+指针
template <class T1, class T2>
class Pikachu < T1&, T2* >
{
public:
Pikachu() { cout << "Pikachu<T1&, T2*>" << endl; }
};
偏特化这个是很自由的
3. 模板分离编译
3.1 Intro
一个程序(项目)由若干个源文件共同实现,而每个源文件单独编译生成目标文件,最后将所有目标文件链
接起来形成单一的可执行文件的过程称为分离编译模式。
3.2 模板的分离编译
假如有以下场景,模板的声明与定义分离开,在头文件中进行声明,源文件中完成定义:
// main.cpp
#include"allen.h"
int main()
{
// 函数模板不支持分离编译,报链接错误,为什么?
Add(1, 2);
Add(1.0, 2.0);
return 0;
}
//allen.h
#include <iostream>
using namespace std;
template<class T>
T Add(const T& left, const T& right);
//allen.cpp
#include"allen.h"
template<class T>
T Add(const T& left, const T& right);

编译的时候过了,但是链接的时候没过

分析原因:编译的时候只有声明,没有函数定义,于是在编译时只能确定函数的名称,检查参数匹配等,但是此刻没有函数地址
这就是为什么一个普通的函数是可以支持分离编译的,因为当他编译的是时候就会在符号表中填入地址,链接的时候时找得到的,而函数模板就不会生成对应的符号表,因为根本没有实例化
3.3 解疑释结
- 模板就不要分离编译,将声明和定义放到一个文件 “xxx.hpp” 里面或者xxx.h其实也是可以的。推荐
- 模板定义的位置显式实例化。这种方法不实用,不推荐使用。
4. 模板总结
4.1 优点
- 模板复用了代码,节省资源,更快的迭代开发,C++的标准模板库(STL)因此而产生
- 增强了代码的灵活性
4.2 缺陷
- 模板会导致代码膨胀问题,也会导致编译时间变长
- 出现模板编译错误时,错误信息非常凌乱,不易定位错误



















 549
549

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











