





作者:羽京
一、前言
随着数据中心的飞速发展,高性能网络不断挑战着带宽与时延的极限,网卡带宽从过去的 10 Gb/s 、25 Gb/s 到如今的 100 Gb/s、200 Gb/s 再到下一代的 400Gb/s 网卡,其发展速度已经远大于 CPU 发展的速度。
为了满足高性能网络下的通信需求,阿里云不仅自研了高性能用户态协议栈 (Luna、Solar) ,也大规模使用了 RDMA 技术,以充分利用高性能网络。尤其是在存储和 AI 领域,RDMA 被广泛使用。相比于 Kernel TCP 提供的 Socket 接口,RDMA 的抽象更为复杂,为了更好的使用 RDMA,了解其工作原理和机制是必不可少的。
本文以 NVIDIA (原 Mellanox)的 RDMA 网卡为例,分析其工作原理和软硬件交互的机制。
二、RDMA 是什么
RDMA (Remote Direct Memory Access) 技术全称远程直接内存访问,是为了解决网络传输中服务器端数据处理的延迟而产生的。RDMA 通过网络将数据从一个系统快速移动到另一个系统中,而不需要消耗计算机的处理能力。它消除了内存拷贝和上下文切换的开销,因而能解放内存带宽和 CPU 周期用于提升系统的整体性能。
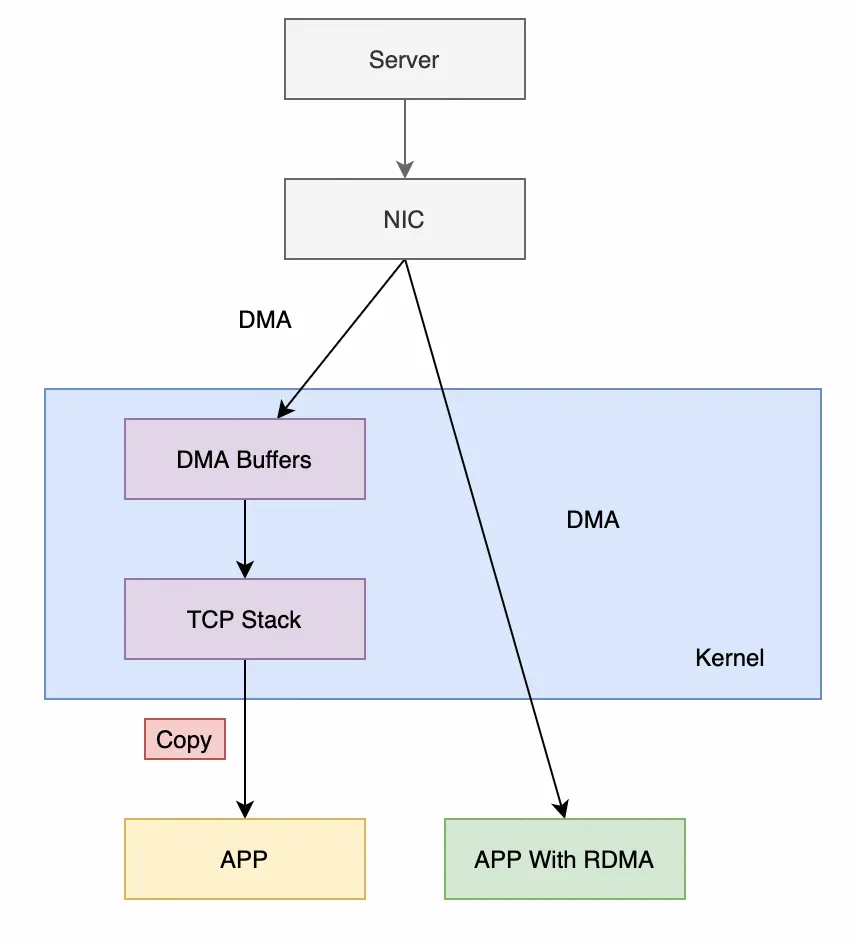
先看看最常见的 Kernel TCP,其收数据的流程主要要经过以下阶段:
-
网卡驱动从内核分配 dma buffer,填入收队列
-
网卡收到数据包,发起 DMA,写入收队列中的 dma buffer
-
网卡产生中断
-
网卡驱动查看收队列,取出 dma buffer,交给协议栈
-
协议栈处理报文
-
操作系统通知用户态程序有可读事件
-
用户态程序准备 buffer,发起系统调用
-
内核拷贝数据至用户态程序的 buffer 中
-
系统调用结束
可以发现,上述流程有三次上下文切换(中断上下文切换、用户态与内核态上下文切换),有一次内存拷贝。虽然内核有一些优化手段,比如通过 NAPI 机制减少中断数量,但是在高性能场景下, Kernel TCP 的延迟和吞吐的表现依然不佳。
使用 RDMA 技术后,收数据的主要流程变为(以 send/recv 为例):
1)用户态程序分配 buffer,填入收队列
2)网卡收到数据包,发起 DMA,写入收队列中的 buffer
3)网卡产生完成事件(可以不产生中断)
4)用户态程序 polling 完成事件
5)用户态程序处理 buffer
上述流程没有上下文切换,没有数据拷贝,没有协议栈的处理逻辑(卸载到了 RDMA 网卡内),也没有内核的参与。CPU 可以专注处理数据和业务逻辑,不用花大量的 cycles 去处理协议栈和内存拷贝。
三、RDMA 的软件架构
从上述分析可以看出,RDMA 和传统的内核协议栈是完全独立的,因此其软件架构也与内核协议栈很不一样,包含以下部分:
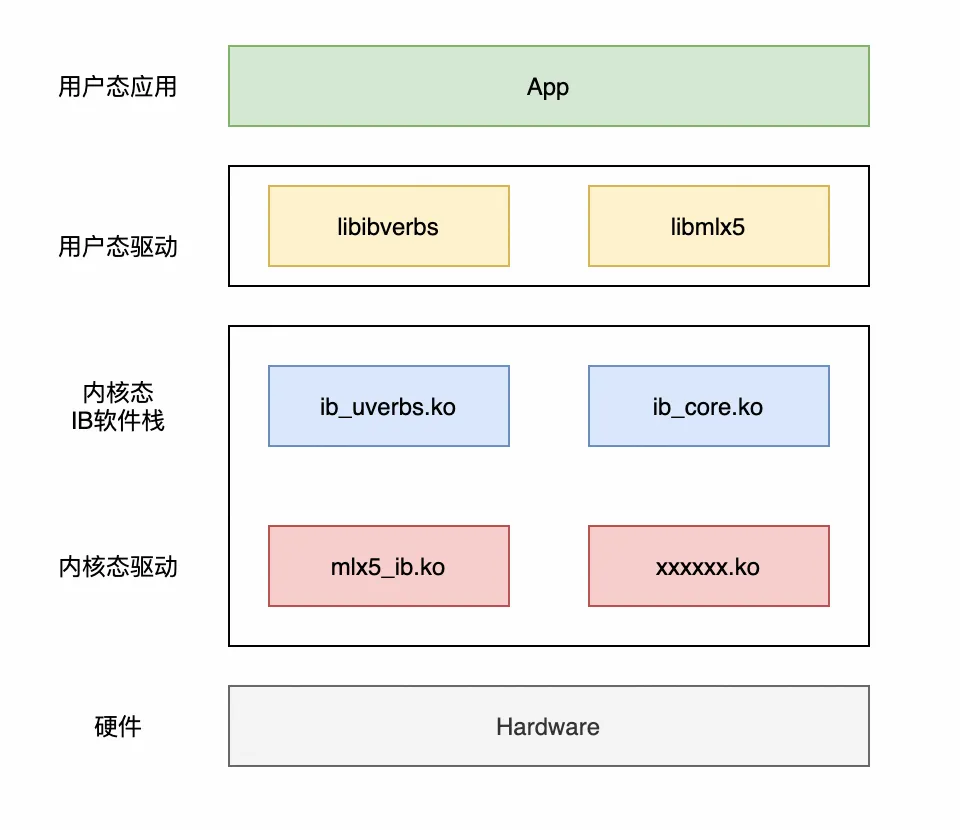
1)用户态驱动(libibverbs、libmlx5 等):这些库都属于 rdma-core 项目(https://github.com/linux-rdma/rdma-core)。为用户提供各种 Verbs API,另外也有一些厂商的特有 API。之所以这层被称为“用户态驱动”,是因为 RDMA 要在用户态直接和硬件打交道,传统在内核态实现 HAL 的方式不满足 RDMA 的需求,因此需要在用户态感知硬件细节。
2)内核态 IB 软件栈:内核态的一层抽象,对应用提供统一的接口。这些接口不仅用户态可以调用,内核态也可以调用。
3) 内核态驱动:各个厂商实现的网卡驱动,直接和硬件交互。
四、RDMA 的内存管理
由于 RDMA 要直接让硬件读写用户态程序的内存,这带来了很多问题:
1)安全问题:用户态程序能否利用网卡读写任意物理内存?
2)地址映射问题:用户态程序使用的是虚拟地址,实际的物理地址是操作系统管理的。网卡怎么知道虚拟地址和物理地址的映射关系?
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1182
1182

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









