




 介绍了一种基于Prompt的通用信息抽取框架,该框架在CCKS2022通用信息抽取竞赛中取得优异成绩。框架包括抽取、分类和组合三个模块,能够解决不同信息抽取任务。
介绍了一种基于Prompt的通用信息抽取框架,该框架在CCKS2022通用信息抽取竞赛中取得优异成绩。框架包括抽取、分类和组合三个模块,能够解决不同信息抽取任务。
作者:思宏、易相、乐慷、染冉、常龙
随着预训练模型的不断发展,深度学习的泛化和迁移能力得到了显著提升。这种能力不仅体现在同一任务的不同领域的数据上,还体现在模型对不同任务的统一解决能力上。本文将为大家介绍一种基于Prompt的通用信息抽取框架,使用相同的思想框架集来解决不同情况下的不同任务。
在CCKS2022通用信息抽取竞赛(业界首个通用的信息抽取评测)中,共有1049人报名,共计152支队伍参加,达摩院NLP应用算法团队在A榜和B榜中都取得了第一名,获得冠军和创新奖,下面本文将为大家分享CCKS2022冠军方案。
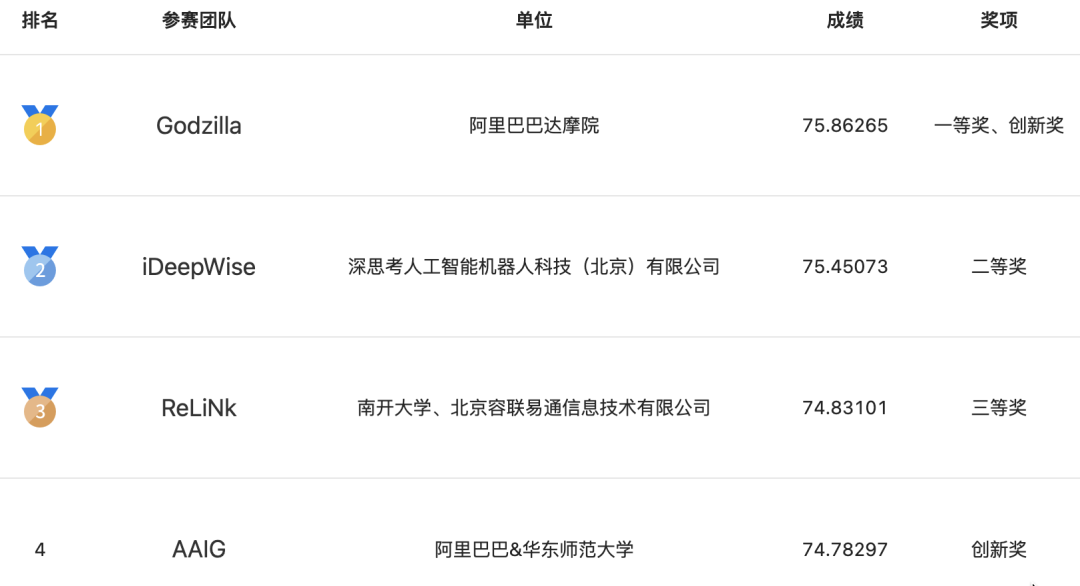
图:CCKS2022 通用信息抽取竞赛获奖榜单
一、背景介绍
多年来,随着预训练模型的不断发展,深度学习的泛化和迁移能力得到了显著提升。这种能力不仅体现在同一任务的不同领域的数据上,还体现在模型对不同任务的统一解决能力上。
信息提取是从非结构化文本中自动检索与选定主题相关的特定信息。一般来说,很多NLP任务都可以归类为信息抽取任务,例如命名实体抽取(NER)、关系抽取(RE)、事件抽取(EE)等。考虑到信息抽取任务的复杂性,经常使用不同的模型来进行信息抽取,处理不同的任务,即使这些任务之间有很多相似之处。为了缓解这一痛点,Y Lu [1] 提出了基于预训练机制和提示学习的统一文本到结构生成框架,即UIE。实验表明,UIE在有监督和低资源场景下均达到了SOTA。
Seq2Seq方案是一个自由度很高的模型,理论上所有的NLP问题都可以用这个方案解决。但是,这种自由度也导致了模型在实际应用中可能会输出一些意想不到的结果。为了增强UIE的可用性,基于提示学习和机器阅读理解提出了另一个版本的UIE [2]。根据我们的实验,我们发现这个版本的UIE确实具有更强的零样本学习能力,但同时也带来了推理时间成本的增加。
受上述工作的启发,我们提出了一种基于提示的UIE框架,使用相同的思想框架集来解决不同情况下的不同任务。
二、任务介绍
本次竞赛不局限于传统的单任务信息抽取的评测范式,而是将多种不同的信息抽取任务用统一的通用框架进行描述,着重考察相关技术方法在面对新的、未知的信息抽取任务与范式时的适应与迁移能力,从而满足当下信息抽取领域快速迭代、快速迁移的实际需求,更贴近实际业务应用。
评测的具体任务由以下两类组成:
Seen Schema 可根据平台数据构建模型,该赛道主要评测现有技术基于标记数据构建模型的能力。包含以下六个领域的抽取任务:
-
人生信息:抽取(关系类型,主体span,客体span)关系三元组、抽取(实体提及span,实体类型)实体二元组
-
机构信息:抽取(关系类型,主体span,客体span)关系三元组、抽取(实体提及span,实体类型)实体二元组
-
金融信息:抽取(事件类型,论元角色,论元span)事件论元三元组
-
体育竞赛:抽取(事件类型,论元角色,论元span)事件论元三元组
-
影视情感:抽取(情感极性,意见对象span,情感表达span)情感三元组
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 1146
1146



 到【灌水乐园】发言
到【灌水乐园】发言







