



 本文介绍了在Python中使用jieba库进行中文分词时遇到的标点符号问题,以及如何通过结合pandas库去除分词结果中的标点符号。提供的代码示例展示了如何定义文本,进行分词,然后利用pandas的条件筛选功能过滤掉标点符号,实现有效的中文文本预处理。
本文介绍了在Python中使用jieba库进行中文分词时遇到的标点符号问题,以及如何通过结合pandas库去除分词结果中的标点符号。提供的代码示例展示了如何定义文本,进行分词,然后利用pandas的条件筛选功能过滤掉标点符号,实现有效的中文文本预处理。
相对于英文文本,中文文本挖掘面临的首要问题就是分词,因为中文的词之间没有空格。在Python中可以使用jieba库来进行中文分词。
但是在中文中,标点符号出现的频率也是很高的,在使用jieba库对带有标点符号的汉语句子进行分词时,标点符号出现在分词结果中时,对于后续的文本数据挖掘是一个不利的因素。
本文介绍一段去除标点符号的Python代码。并在Anaconda3的Jupyter Notebook中展现代码的运行结果。
下面的代码,定义一段带有标点符号的文本,并使用jieba库进行分词。代码如下:
import jieba
text = "她说:“我爱死你了!”"
cutwords = list(jieba.cut(text))
cutwords运行结果如下图所示:

上图中,分词结果列表中有标点符号冒号、逗号、感叹号、左双引号、右双引号等。
使用下面这段代码即可从分词结果中去除标点符号。代码如下:
import jieba
import pandas as pd
text = "她说:“我爱死你了!”"
cutwords = list(jieba.cut(text))
cutwords = pd.Series(cutwords)[pd.Series(cutwords).apply(len)>0] #去除长度为0的词
stopwords=[':','“','!','”']
cutwords = cutwords[~cutwords.isin(stopwords)]
cutwords上面这段代码主要使用了pandas库中的函数,还定义了停用词列表stopwords,将想要去除的标点符号添加到该列表中。运行结果如下图所示:
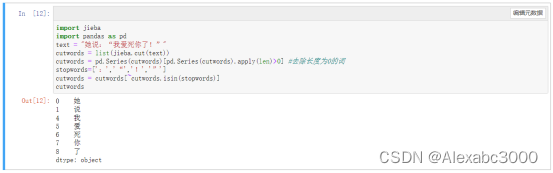
由程序运行结果可以看出,达到了目的,即去除了分词结果中的标点符号。
相关参考资料:
- Python手动安装Jieba库(Win11). https://www.toutiao.com/article/7162528424102789635/?log_from=20632270c7786_1668424596605 .
- 在Anaconda3使用Jupyter Notebook的简单例子. https://www.toutiao.com/article/7160267285184119333/?log_from=5da6ca35b0bd3_1668424881002 .
- Python在机器学习中的应用. 余本国, 孙玉林著. 中国水利水电出版社[北京], 2019年6月第一版.


















 2918
2918

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











