



 本文详细阐述了处理器中分支指令预测错误时的状态恢复策略。在解码阶段,分支指令被分配编号,若 jalr 预测错误,可提前停止流水线。在读取物理寄存器阶段,发现错误则清除发射队列中相关指令。执行阶段,ROB 用于恢复分支预测失败的处理器状态。当预测错误时,通过编号列表抹掉错误路径上的指令,并使用checkpoint恢复处理器状态,如寄存器映射表。该机制涉及复杂的编号管理和指令清除过程。
本文详细阐述了处理器中分支指令预测错误时的状态恢复策略。在解码阶段,分支指令被分配编号,若 jalr 预测错误,可提前停止流水线。在读取物理寄存器阶段,发现错误则清除发射队列中相关指令。执行阶段,ROB 用于恢复分支预测失败的处理器状态。当预测错误时,通过编号列表抹掉错误路径上的指令,并使用checkpoint恢复处理器状态,如寄存器映射表。该机制涉及复杂的编号管理和指令清除过程。
- 解码阶段:可得直接跳转指令的目标地址和jal/jalr跳转方向。如果jalr预测错误,但还没读到寄存器内容,可以简单停止流水线。
- 在读取物理寄存器阶段:发现目标地址错误,需要对发射队列的指令选择性清除,错误路径上的指令清除。
- 执行阶段:重排序缓存ROB对分支预测失败的处理器状态恢复。
基于ROB的状态恢复:停掉fetch,使br成为ROB中oldest的指令。
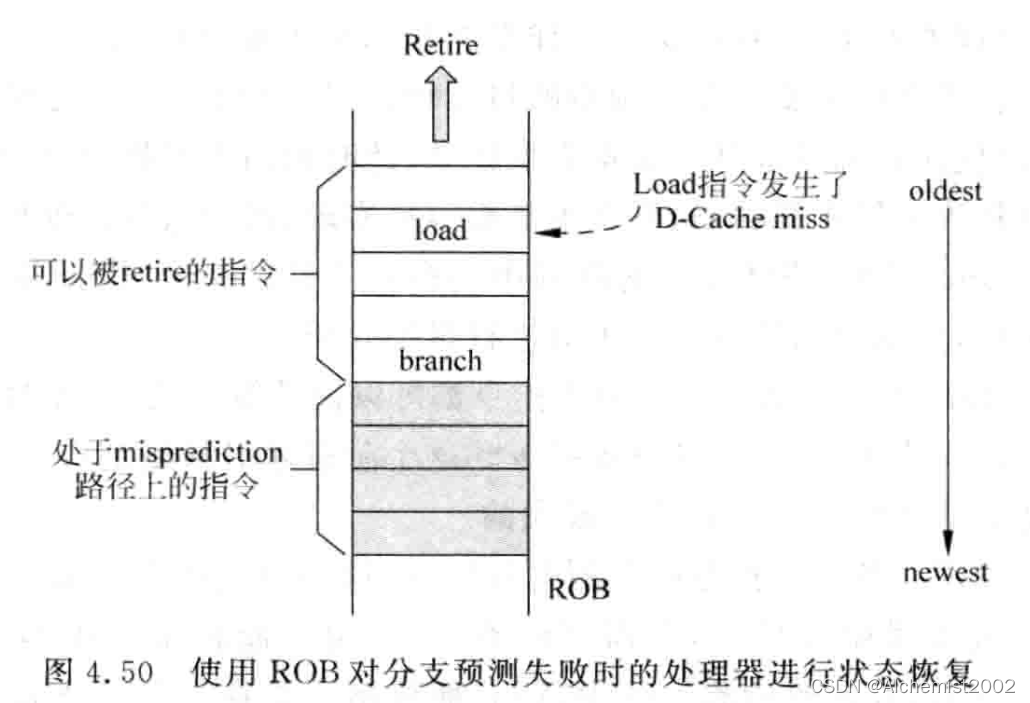
基于checkpoint状态恢复:checkpoint是指发现分支指令,保存处理器状态,如寄存器重命名中使用的映射表mapping table,预测的下条PC等。相比于ROB,这种方式消耗更多硬件资源,但是能快速将处理器状态恢复。在抹掉处于分支预测失败路径上的指令时,需要编号机制识别哪些指令处于错误的路径上。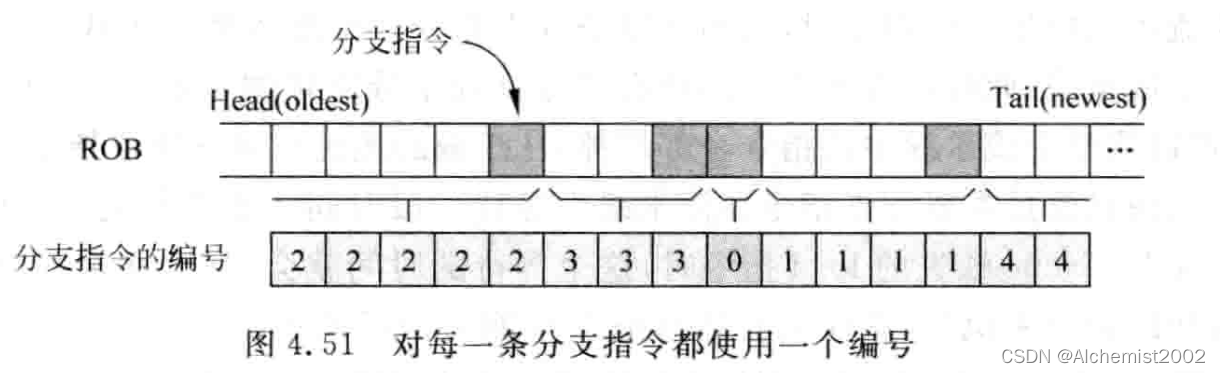
编号个数决定最多可在流水线中存在的分支指令个数。假设处理器支持128条指令存在于流水线中,按每五条指令一条分支指令,编号位数为5。
编号值被保存在FIFO中,称为编号列表(tag list)。容量等于处理器最多支持分支指令的个数。如果在解码出分支指令,会暂停解码之前的流水线。
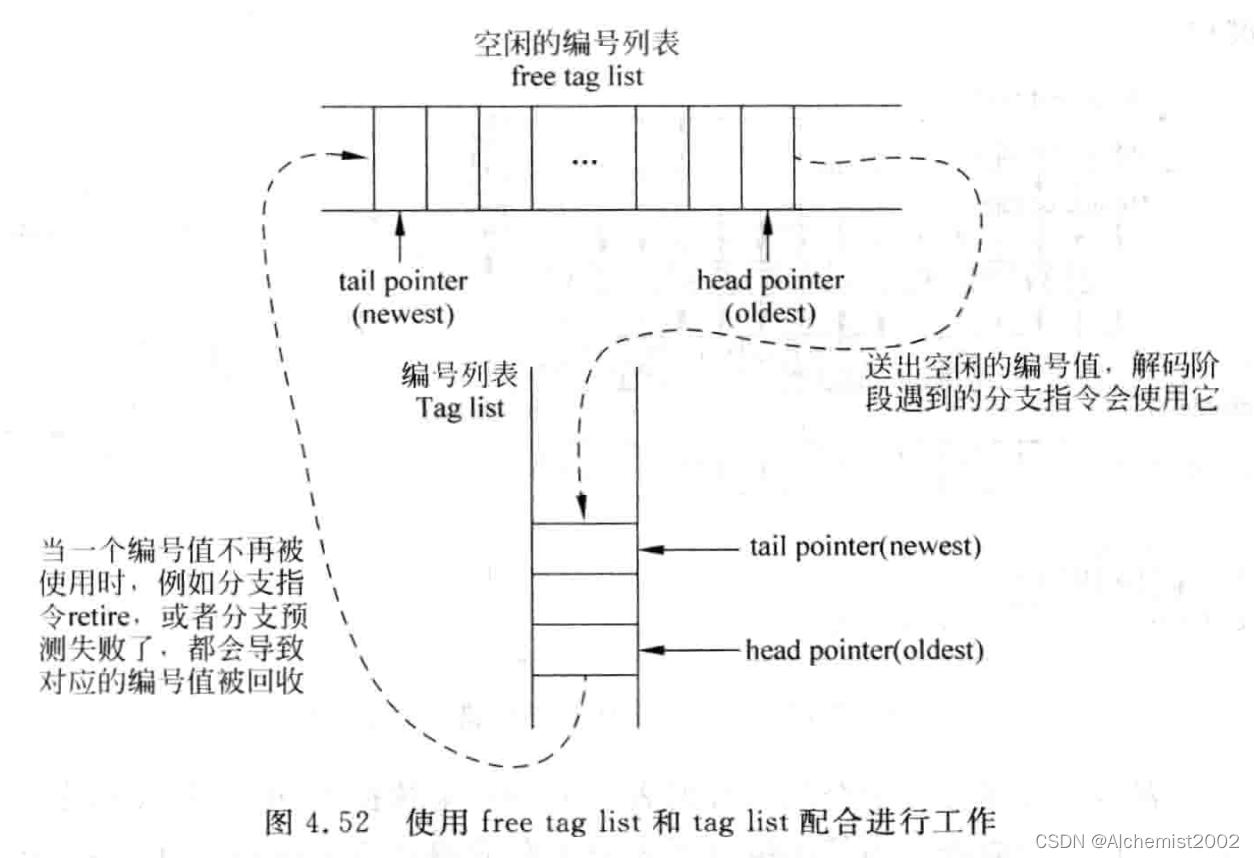
上面的方法只是给出了一种设计的思路,在具体实现时,有很多种方法都可以对分支指令的编号进行分配和回收,下面给出一种一般性的设计方法。这种方法使用两个表格,一个表格用来存放所有没有被使用的编号值,这个表格称为空闲的编号列表(free tag list);另一个表格用来存储所有被使用的编号值,即上面所说的编号列表(tag list)。每次在解码阶段发现一条分支指令时,就从空闲的编号列表(free tag list)中送出一个编号值,这个编号值会被写到编号列表(tag list)中,在此之后被解码的所有指令都被附上这个编号值,直到遇到下一条分支指令被解码为止。
这两个编号列表(free tag list和tag list)本质上都是FIFO,一旦在流水线的执行阶段
发现一条分支指令预测错误了,就会使用编号列表中这条分支指令对应编号值,以及它之后的所有编号值,将流水线中对应的指令进行抹掉,同时编号列表中这些用来抹掉流水线的编号值会被放回到空闲的编号列表中,供后续进入流水线的分支指令使用,它们的工作流程可以用图4.52来表示。
需要为解码阶段得到的每一条分支指令都分配一个编号值。
当一条分支指令在执行阶段发现预测错误时,需要将在它后面进入到流水线的所有指令都抹掉,根据超标量处理器流水线的特点,这个过程实际上包括两个部分。
(1) 在流水线的发射(issue)阶段之前的所有指令都需要全部被抹掉,因为在发射阶段之前指令依然维持着程序中原始的顺序(in-order),而在流水线中,执行阶段位于发射阶段之后,因此,当在执行阶段发现了一条预测错误的分支指令时,流水线的发射阶段之前的所有指令必然全部处于分支预测失败(mis-prediction)的路径上,它们都可以从流水线中被无差别地抹掉,这个过程在一个周期内就可以完成。
(2) 在流水线的发射阶段以及之后的流水段中,指令将按照乱序(out-of-order)的方式来执行,一部分指令可能处于分支预测失败(mis-prediction)的路径上,这就需要使用编号列表(tag list)中的编号值将它们找出来并抹掉,这个过程会比较复杂,在一个周期内很有可能无法完成。
在ROB中,将编号列表相关编号广播,ROB中所有指令都将自身编号值与广播编号值比较,如果相等,将ROB中对应指令设置为无效。
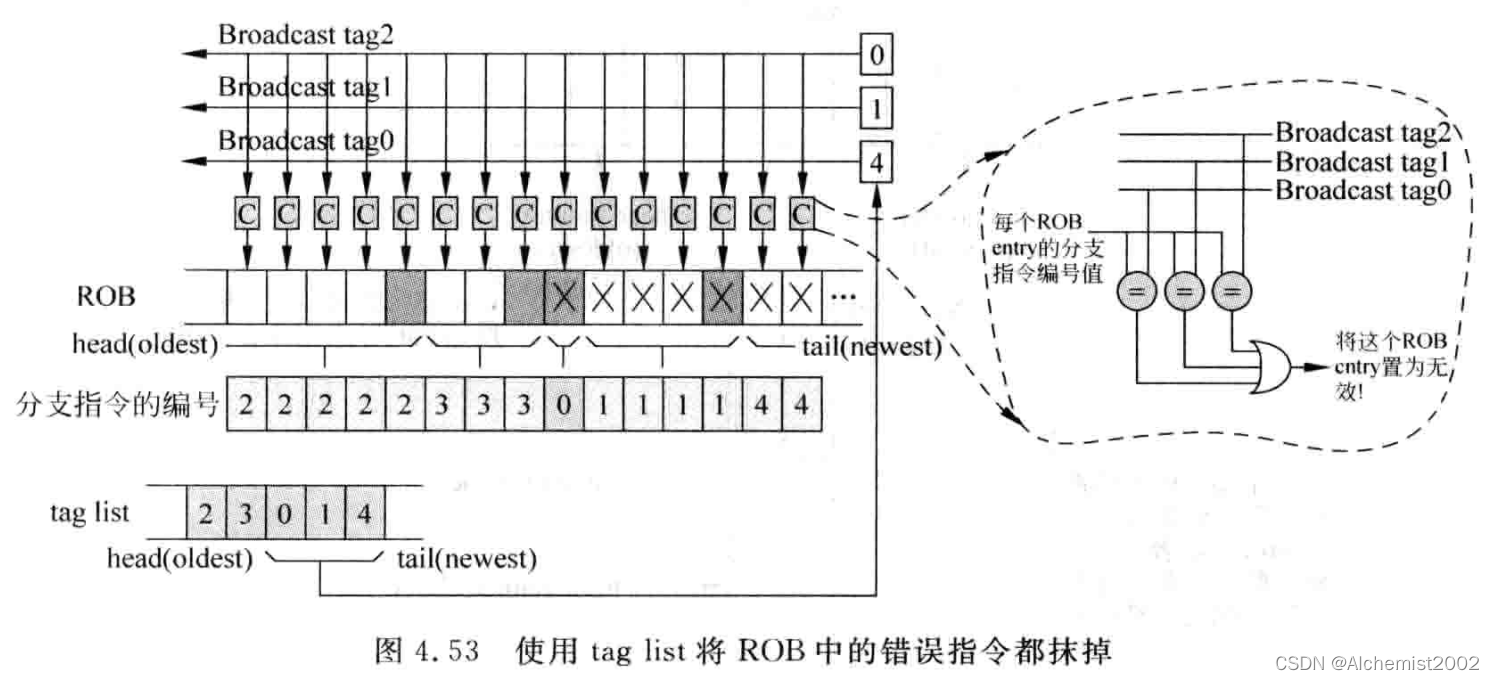
使用编号列表对流水线其他部件如发射队列抹掉指令的方法类似。
将流水线相关指令抹掉后,需要使用checkpoint对处理器状态恢复。主要是对寄存器重命名阶段的mapping table进行恢复。
在decode阶段,对分支指令进行编号分配。decode阶段每周期最多给一条分支指令分配编号。
想要知道分支指令的预测值,需要decode阶段保存在缓存中,只保存预测是跳转的分支指令。
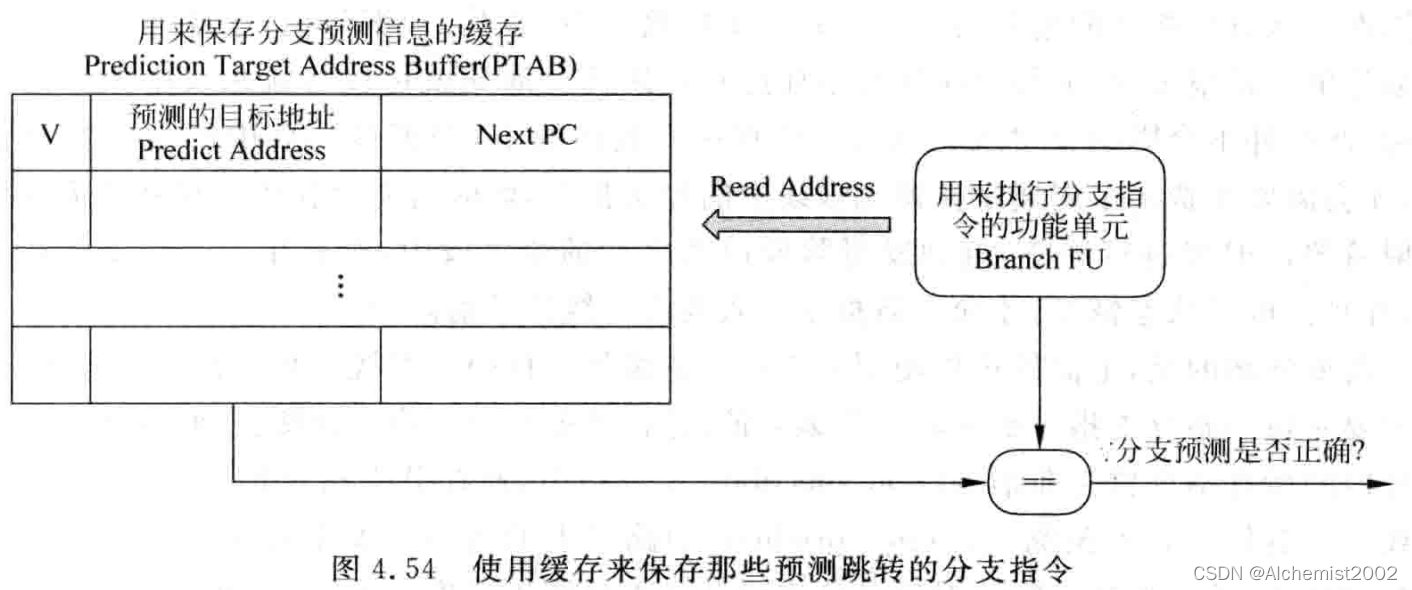
Next PC保存的是下一条,一旦预测错误,Next PC就作为正确的取指地址。

写PTAB的过程也可以发生在取指,只要在取指阶段预测到一条发生跳转的指令。
自修改代码的情况下,将非分支指令预测为跳转实际中不会有影响。
#----------------------------------------------------------------------------------------------------#
因为懒得打字使用了在线OCR,但是每日有免费次数,(穷)有点想知道能不能通过开发者模式emmm…

















 2152
2152

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









