 Hadoop集群故障排查与解决
Hadoop集群故障排查与解决




 本文介绍了Hadoop集群中Namenode启动失败和ResourceManager启动报错的问题及解决方案。Namenode启动失败可能由于配置不一致或tmp目录文件丢失,解决方法包括重新配置或使用SecondaryNameNode恢复。ResourceManager启动报错通常是由于端口占用,确保在正确机器上启动YARN服务。
本文介绍了Hadoop集群中Namenode启动失败和ResourceManager启动报错的问题及解决方案。Namenode启动失败可能由于配置不一致或tmp目录文件丢失,解决方法包括重新配置或使用SecondaryNameNode恢复。ResourceManager启动报错通常是由于端口占用,确保在正确机器上启动YARN服务。
1.namenode启动不了:使用hadoop-daemon.sh start namenode也没用
查看日志:
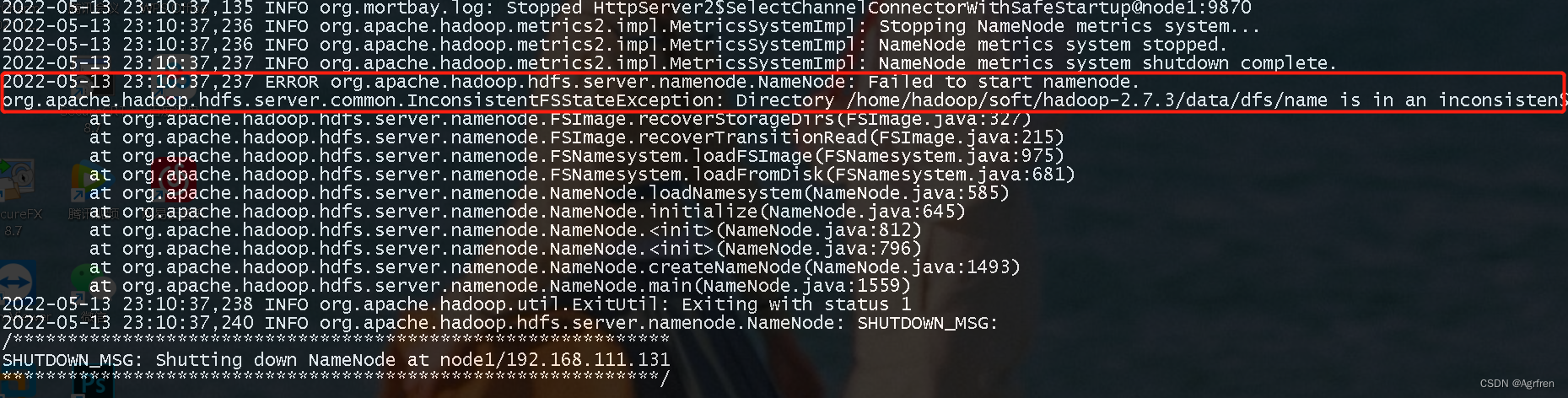
(1)第一种可能是配置的文件路径不一致导致出错,删除掉core-site.xml中的tmp.dir配置,统一配置到hdfs-site.xml中。
(2)第二种是因为断电关机等原因系统删除了tmp文件中的name,使得namenode不能启动。
解决办法1:如果secondnamenode安装在了另一台机器,可以使用secondnamenode恢复:
第一步删除 namenode主节点的metadata配置目录:rm -fr /data/dfs/name
第二步从起机器,第三步使用hadoop namenode -importCheckpoint恢复
解决办法2:使用hadoop namenode -format格式化namenode所在的机器
2.Resourcemanager启动报错
starting Resourcemanager, logging to /home/hadoop/soft/hadoop-2.7.3/logs/hadoop-hadoop-Resourcemanager-node2.out
Error: Could not find or load main class Resourcemanager查看日志信息
Caused by: java.net.BindException: Problem binding to [node2:8031] java.net.BindException: 无法指定被请求的地址; For more details see: http://wiki.apache.org/hadoop/BindException解决办法:对于完全分布式集群必须要在安装Resourcemanager的机器上启动yarn
侵删!
参考:hadoop集群崩溃,因为tmp下/tmp/hadoop-hadoop/dfs/name文件误删除 - 代码王子 - 博客园
java.net.BindException: Problem binding to [hadoop103:8031] java.net.BindException - 与君共舞 - 博客园


















 1332
1332

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









