






 本文介绍了一个使用Python实现的多线程爬虫,通过获取代理IP池来提升爬取速度。在爬取过程中,为了避免IP被封,通过time.sleep和随机策略控制爬取速度,并使用线程锁确保文件写入的同步。同时,代码中展示了如何处理HTTPS请求和设置代理。然而,由于网络波动和反爬策略,有时仍可能出现网络错误。
本文介绍了一个使用Python实现的多线程爬虫,通过获取代理IP池来提升爬取速度。在爬取过程中,为了避免IP被封,通过time.sleep和随机策略控制爬取速度,并使用线程锁确保文件写入的同步。同时,代码中展示了如何处理HTTPS请求和设置代理。然而,由于网络波动和反爬策略,有时仍可能出现网络错误。
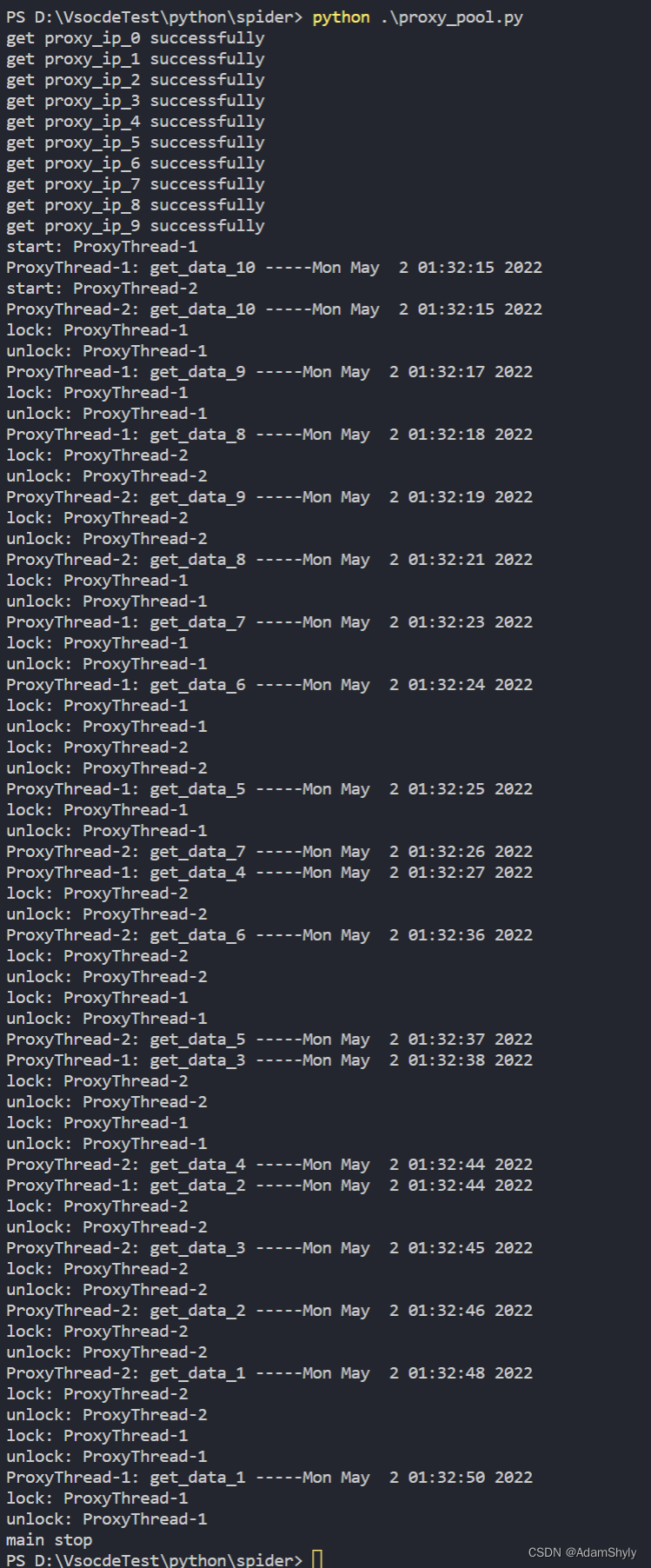
此次实验使用多线程获取proxy池来增加爬虫爬取下载数据的速度,顺便测试一下urllib handler代理
注意由于线程爬取数据过快可能会导致ip被封,要适当增加time.sleep否则会出现503错误,也可以改变获取proxy_ip的策略,我这里是采取random随机获取proxy列表下标,也可以试试轮询策略,但注意要加锁
from urllib import request as ure
import random
import threading
import time
import ssl
proxies_pool = []
# 全局取消证书验证,避免访问https网页报错
ssl._create_default_https_context = ssl._create_unverified_context
file_count = 0 # 文件现个数
def init_request():
# url = 'http://www.baidu.com/s?ie=UTF-8&wd=ip'
url = 'https://dev.kdlapi.com/testproxy'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.41 Safari/537.36 Edg/101.0.1210.32'
}
request = ure.Request(url=url, headers=headers)
return request
def init_proxy_ip(id):
global proxies_pool
# 提取代理API接口,获取1个代理IP
api_url = "http://dps.kdlapi.com/api/getdps/?orderid=xxxxxxx6&num=1&signature=xxxxx&pt=1&sep=1"
time.sleep(1)
proxy_ip = ure.urlopen(api_url).read().decode('utf-8')
username = '账号'
password = '密码'
proxies = {
"http": "http://%(user)s:%(pwd)s@%(proxy)s/" % {"user": username, "pwd": password, "proxy": proxy_ip},
"https": "http://%(user)s:%(pwd)s@%(proxy)s/" % {"user": username, "pwd": password, "proxy": proxy_ip}
}
proxies_pool.append(proxies)
print('get proxy_ip_%d successfully' % id)
def init_proxy_ips(count=10):
for ip in range(count):
init_proxy_ip(ip)
def get_proxy_ip():
proxies = random.choice(proxies_pool)
return proxies
def get_data(request, proxies):
handler = ure.ProxyHandler(proxies=proxies)
opener = ure.build_opener(handler)
response = opener.open(request)
content = response.read().decode('utf-8')
return content
def create_file(content):
filename = 'proxy_test_%d.html' % file_count
with open(filename, 'w', encoding='utf-8') as fp:
fp.write(content)
class ProxyThread(threading.Thread):
def __init__(self, thead_id, thread_name, delay):
threading.Thread.__init__(self)
self.thread_id = thead_id
self.name = thread_name
self.delay = delay
def run(self):
print('start: %s' % self.name)
# print_time(self.name, self.delay, 3)
fetch_data(self.name, self.delay, count=10)
def fetch_data(name, delay, count=5):
global file_count
while count:
print('%s: get_data_%d -----%s' % (name, count, time.ctime(time.time())))
proxies = get_proxy_ip()
res = get_data(request, proxies)
thread_lock.acquire() # 上锁
file_count += 1
print('lock: %s' % name)
create_file(content=res)
print('unlock: %s' % name)
thread_lock.release() # 解锁
time.sleep(delay) # 阻塞 0.5s
count -= 1
# def print_time(name, delay, counter):
# while counter:
# time.sleep(delay)
# print('%s: %s' % (name, time.ctime(time.time())))
# counter -= 1
request = init_request() # 获取 request
init_proxy_ips() # 初始化 proxy_ips 默认值为10个ip
threads = []
thread_lock = threading.Lock() # 初始化线程锁
thread1 = ProxyThread(1, "ProxyThread-1", 1)
thread2 = ProxyThread(2, "ProxyThread-2", 1)
thread1.start()
thread2.start()
threads.append(thread1)
threads.append(thread2)
# 主线程必须等所有线程执行完才能执行之后的语句
for thread in threads:
thread.join() # 主线程执行该join方法
print('main stop')
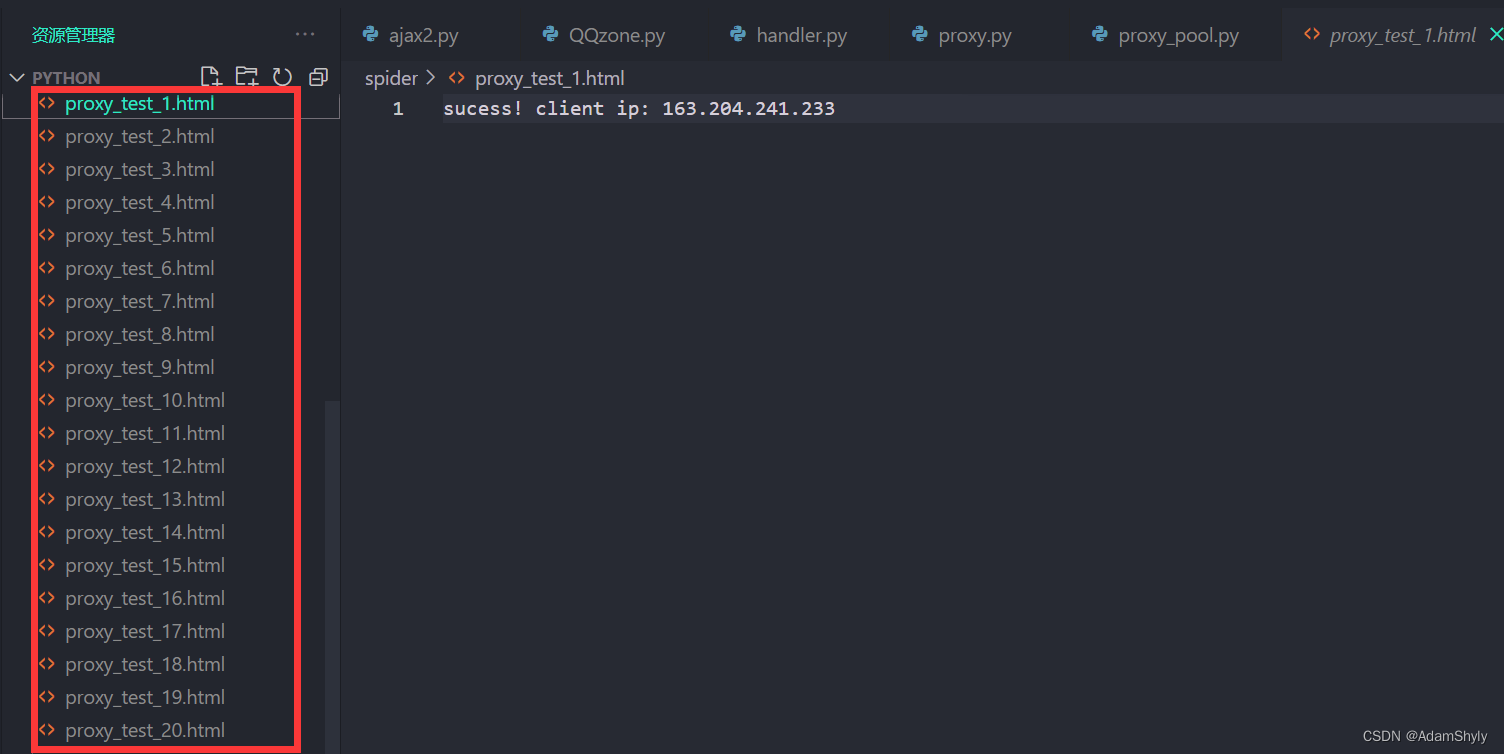
现在来测试一下爬取百度搜索引擎搜索ip页面的数据,发现https可以正常爬取
应该是由于百度的反爬,有时候能访问有时候又报网络错误,所以我在请求头加上了cookie等一堆参数
from urllib import request as ure, parse as upa
import ssl
# # 全局取消证书验证,避免访问https网页报错
ssl._create_default_https_context = ssl._create_unverified_context
# # 提取代理API接口,获取1个代理IP
api_url = "http://dps.kdlapi.com/api/getdps/?orderid=xxxxxx&num=1&signature=xxxx&pt=1&sep=1"
proxy_ip = ure.urlopen(api_url).read().decode('utf-8')
username = 'xxxx'
password = 'xxxx'
proxies = {
"http": "http://%(user)s:%(pwd)s@%(proxy)s/" % {"user": username, "pwd": password, "proxy": proxy_ip},
"https": "http://%(user)s:%(pwd)s@%(proxy)s/" % {"user": username, "pwd": password, "proxy": proxy_ip}
}
url = 'https://www.baidu.com/s?ie=UTF-8&wd=ip'
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
# 'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Cookie': 'xxxx',
'Host': 'www.baidu.com',
'sec-ch-ua': '" Not A;Brand";v="99", "Chromium";v="101", "Microsoft Edge";v="101"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.41 Safari/537.36 Edg/101.0.1210.32',
}
request = ure.Request(url=url, headers=headers)
# proxies = {
# 'http': '223.242.66.204:23401'
# }
handler = ure.ProxyHandler(proxies=proxies)
opener = ure.build_opener(handler)
response = opener.open(request)
# response = ure.urlopen(request)
content = response.read().decode('utf-8')
with open('ip.html', 'w', encoding='utf-8') as fp:
fp.write(content)

















 1735
1735

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









