




目录
数据血缘
这里是一段代码
public class Test01_Dep {
public static void main(String[] args) {
// 1.创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
// 2. 创建sparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
// 3. 编写代码
JavaRDD<String> lineRDD = sc.textFile("input/2.txt");
System.out.println(lineRDD.toDebugString());
System.out.println("-------------------");
JavaRDD<String> wordRDD = lineRDD.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String s) throws Exception {
List<String> stringList = Arrays.asList(s.split(" "));
return stringList.iterator();
}
});
System.out.println(wordRDD.toDebugString());
System.out.println("-------------------");
JavaPairRDD<String, Integer> tupleRDD = wordRDD.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) throws Exception {
return new Tuple2<>(s, 1);
}
});
System.out.println(tupleRDD.toDebugString());
System.out.println("-------------------");
JavaPairRDD<String, Integer> wordCountRDD = tupleRDD.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
System.out.println(wordCountRDD.toDebugString());
System.out.println("-------------------");
// 4. 关闭sc
sc.stop();
}
}
结果如下
| (2) input/2.txt MapPartitionsRDD[1] at textFile at Test01_Dep.java:29 [] | input/2.txt HadoopRDD[0] at textFile at Test01_Dep.java:29 [] (2) MapPartitionsRDD[2] at flatMap at Test01_Dep.java:32 [] | input/2.txt MapPartitionsRDD[1] at textFile at Test01_Dep.java:29 [] | input/2.txt HadoopRDD[0] at textFile at Test01_Dep.java:29 [] (2) MapPartitionsRDD[3] at mapToPair at Test01_Dep.java:42 [] | MapPartitionsRDD[2] at flatMap at Test01_Dep.java:32 [] | input/2.txt MapPartitionsRDD[1] at textFile at Test01_Dep.java:29 [] | input/2.txt HadoopRDD[0] at textFile at Test01_Dep.java:29 [] (2) ShuffledRDD[4] at reduceByKey at Test01_Dep.java:50 [] +-(2) MapPartitionsRDD[3] at mapToPair at Test01_Dep.java:42 [] | MapPartitionsRDD[2] at flatMap at Test01_Dep.java:32 [] | input/2.txt MapPartitionsRDD[1] at textFile at Test01_Dep.java:29 [] | input/2.txt HadoopRDD[0] at textFile at Test01_Dep.java:29 [] |
解读
(1)字段出现的规律是:你输入的完整路径、RDD类型、算子名称。
(2)程序执行是从最初的RDD一步步转换到最后的RDD,而血缘关系打印是从最后的RDD回溯到最初的RDD
(3)RDD类型转换之后,血缘关系就发生了变化。
(4)“+”,表示发生了shuffle操作;“+-”表示一个依赖关系,而且是一个宽依赖(ShuffleDependency)
(5)每个RDD都有一个编号(如[1],[2]等),这个编号在同一个SparkContext中是唯一的,可以用来区分不同的RDD。
(6)Spark的转换操作是惰性的,只有遇到行动操作才会执行。血缘关系使得Spark能够在出错时重新计算丢失的分区,而不需要从头开始。
(7)HadoopRDD[0] 是数据读取层,直接与HDFS交互(即使本地文件也用此名)
窄依赖
窄依赖表示每一个父RDD的Partition最多被子RDD的一个Partition使用(一对一or多对一),窄依赖我们形象的比喻为独生子女。
例如map、filter、union等操作都会产生窄依赖
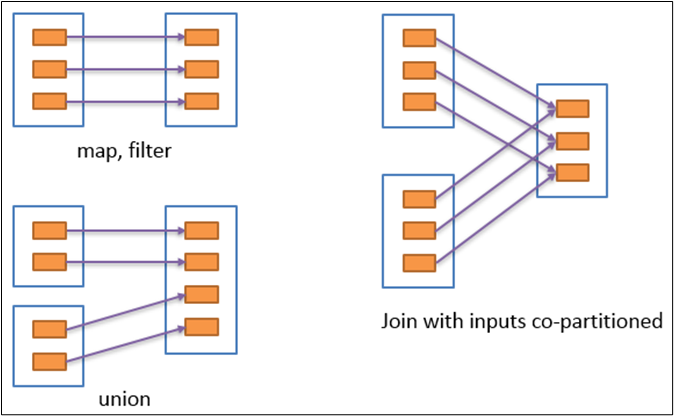
(箭头从父RDD指向子RDD)
宽依赖
宽依赖表示同一个父RDD的Partition被多个子RDD的Partition依赖(只能是一对多),会引起Shuffle,总结:宽依赖我们形象的比喻为超生。
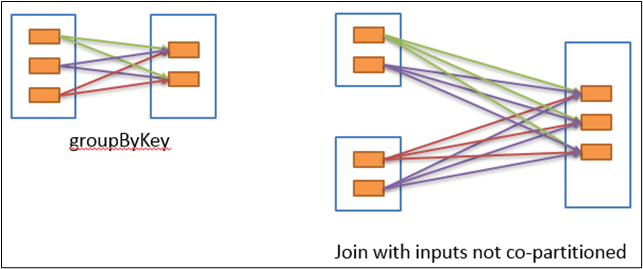
(箭头从父RDD指向子RDD)
作为小白应该注意
-
理解核心概念优先
-
掌握RDD的不可变性、血缘(Lineage)、惰性求值原理。
-
区分 转换(Transformation) 和 行动(Action):只有Action触发计算。
-
例子:
textFile(转换)、reduceByKey(转换)、collect(行动)。
-
-
动手实验血缘关系
-
尝试修改代码(如增加
filter),观察toDebugString输出变化。 -
查看DAG图(更直观的血缘可视化)。
-
-
避免常见坑
-
闭包序列化:匿名函数内勿引用不可序列化对象(如数据库连接)。
-
Shuffle代价:
groupByKey可能比reduceByKey慢10倍+(官方优化指南)。
-
作为大数据工程师应该注意
-
血缘关系的深层应用
-
故障恢复:Spark用血缘自动重建丢失的分区(无需手动备份)。
-
动态分区裁剪:利用血缘优化查询(如Spark SQL自动跳过无关分区)。
-
-
调优关键点
-
Shuffle优化:调整
spark.sql.shuffle.partitions(默认200)避免小文件。 -
数据倾斜处理:用
salting(加随机前缀)或map-side combine分散热点Key。 -
持久化策略:对复用RDD合理
cache()/persist(),避免重复计算。
-
-
监控血缘实战
-
通过Spark UI分析Stage边界,定位Shuffle瓶颈。
-
日志中血缘ID(如
MapPartitionsRDD[3])用于关联监控指标。
-
面试应该注意
-
必考知识点
-
RDD vs DataFrame vs Dataset:API优化(钨丝计划)、执行效率对比。
-
宽窄依赖:窄依赖(
map)、宽依赖(reduceByKey),如何影响Stage划分。 -
Spark内存管理:Execution Memory vs Storage Memory,OOM处理方案。
-
-
结合项目回答
-
举例:“我用
toDebugString分析血缘发现Shuffle数据倾斜,通过repartition+盐值解决”。
-
-
深入原理问题
-
DAGScheduler工作原理:如何根据血缘生成DAG图并划分Stage?
-
容错机制:如何用血缘+Checkpoint实现快速恢复?
-
小白部分
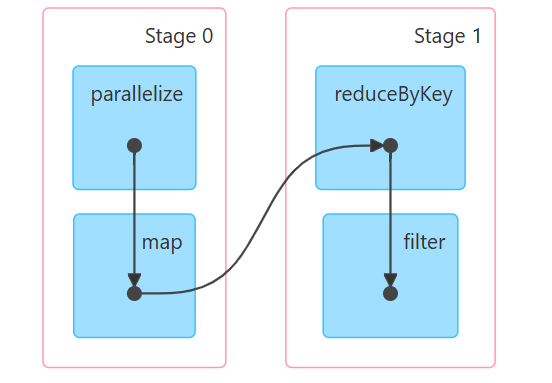
stage解释
stage是Spark作业的执行阶段,类似工厂的流水线:
-
一个Stage = 一组可以连续加工的任务(无需中断或重组数据)
-
Stage边界 = 需要数据重组的关卡(Shuffle操作,如
reduceByKey) -
你的DAG图解析:
-
Stage 0:
parallelize→map(窄依赖,流水线执行) -
Stage 1:
reduceByKey→filter(Shuffle后新阶段) -
箭头方向:Stage 0的输出经Shuffle后成为Stage 1的输入
-
从DAG图能看出什么?
-
性能瓶颈位置:Stage 1的
reduceByKey是Shuffle操作(红色虚线),通常最耗时 -
优化机会:
-
若
filter能提前到Shuffle前(如移到map后),可减少Shuffle数据量 -
检查
reduceByKey后的数据量是否被filter大量过滤(若是则需调整顺序)
-
(实操展示不展示)
开发/面试常见问题补充
1. **Shuffle原理**:为什么Shuffle操作昂贵?(网络传输+磁盘I/O) 2. **数据本地性**:如何查看Task的Locality Level?(NODE_LOCAL > RACK_LOCAL) 3. **内存管理**:执行内存和存储内存冲突时谁优先?(执行内存优先) 4. **广播变量**:什么时候该用广播变量?(小表JOIN大表) 5. **累加器**:累加器为什么会有"少加"问题?(Action重算导致)
🛠 给大数据工程师(生产环境):
-
血缘关系的深层应用
-
故障恢复:Spark用血缘自动重建丢失的分区(无需手动备份)。
-
动态分区裁剪:利用血缘优化查询(如Spark SQL自动跳过无关分区)。
-
-
调优关键点
-
Shuffle优化:调整
spark.sql.shuffle.partitions(默认200)避免小文件。 -
数据倾斜处理:用
salting(加随机前缀)或map-side combine分散热点Key。 -
持久化策略:对复用RDD合理
cache()/persist(),避免重复计算。
-
-
监控血缘实战
-
通过Spark UI分析Stage边界,定位Shuffle瓶颈。
-
日志中血缘ID(如
MapPartitionsRDD[3])用于关联监控指标。
-
工程师实操部分 (理论)
1. 血缘自动重建分区
// 示例:RDD血缘链
val rddA = sc.textFile("hdfs://data.log")
val rddB = rddA.filter(_.contains("ERROR")) // 血缘:HadoopRDD → FilteredRDD
val rddC = rddB.map(_.length)
// 当Executor节点宕机时:
// 1. Driver检查到rddC的分区2丢失
// 2. 回溯血缘:rddC ← rddB ← rddA
// 3. 从rddA的对应分区块重新计算:
// a. 读取hdfs://data.log的block3
// b. 执行filter操作
// c. 执行map操作
// 4. 重建分区22.利用血缘优化查询(分区剪枝)
Spark SQL实战
-- 创建分区表
CREATE TABLE logs (msg STRING) PARTITIONED BY (dt STRING);
-- 查询时自动跳过无关分区
EXPLAIN EXTENDED
SELECT * FROM logs WHERE dt = '2023-01-01';血缘优化效果:
== Physical Plan ==
*(1) ColumnarToRow
+- FileScan parquet [msg] Batched: true,
DataFilters: [],
Format: Parquet,
Location: InMemoryFileIndex[hdfs://nn/logs/dt=2023-01-01], -- 只扫描目标分区!
PartitionFilters: [isnotnull(dt), (dt = 2023-01-01)],
PushedFilters: [],
ReadSchema: struct<msg:string>3. Shuffle优化实战
问题场景:
-
200个分区处理10MB数据 → 产生200个小文件(每个50KB)
-
HDFS小文件灾难(NameNode内存压力)
解决方案:
// 动态调整Shuffle分区数
spark.conf.set("spark.sql.shuffle.partitions", 10) // 根据数据量调整
// 或在代码中重分区
df.repartition(10).write.parquet("output.parquet")
// 验证效果:查看输出文件
hdfs dfs -ls output.parquet | wc -l # 显示10个文件4.数据倾斜解决方案(Salting技巧)
热点Key处理流程:
// 原始数据倾斜的RDD
val skewedRDD: RDD[(String, Int)] = ...
// 第一步:给热点Key加随机前缀 (0-9)
val saltedRDD = skewedRDD.map {
case (key, value) =>
if (key == "hotkey") {
val salt = util.Random.nextInt(10)
(s"$salt-$key", value)
} else {
(key, value)
}
}
// 第二步:局部聚合
val partialAgg = saltedRDD.reduceByKey(_ + _)
// 第三步:去除盐值,全局聚合
val finalResult = partialAgg.map {
case (saltedKey, sum) =>
if (saltedKey.contains("-")) {
val realKey = saltedKey.split("-")(1)
(realKey, sum)
} else {
(saltedKey, sum)
}
}.reduceByKey(_ + _)5. 缓存优化策略
缓存决策树:
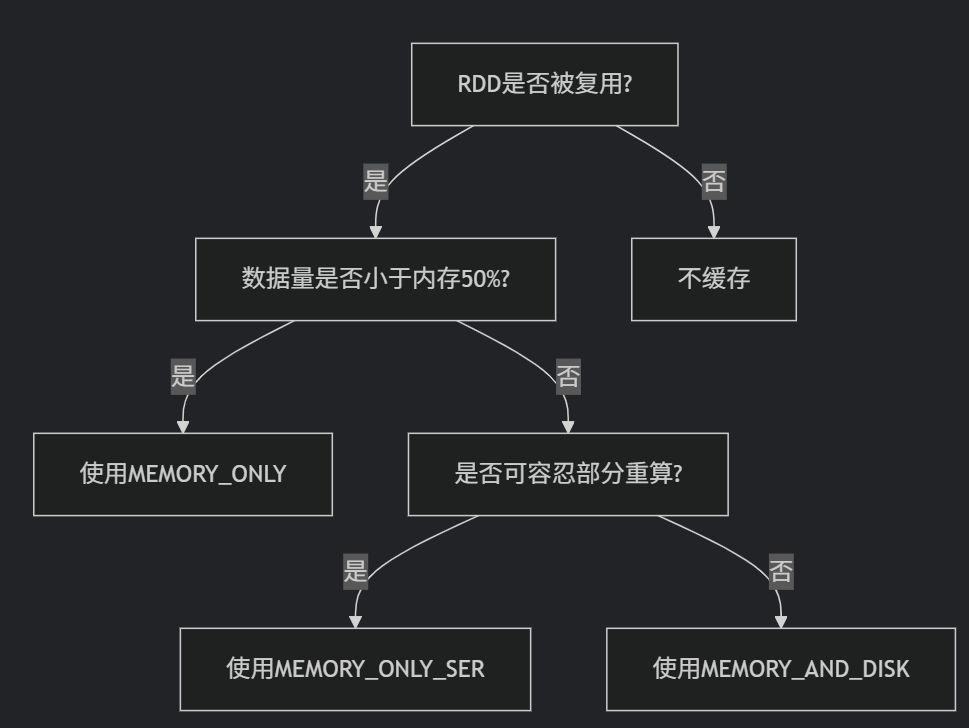
实战示例:
// 正确缓存姿势
val processed = sc.textFile("data")
.map(parse)
.filter(_.isValid)
.persist(StorageLevel.MEMORY_AND_DISK_SER) // 序列化节省空间
processed.count() // 触发缓存
// 后续操作直接使用缓存
val result1 = processed.map(...).saveAsTextFile(...)
val result2 = processed.filter(...).count()6. Spark UI分析Stage瓶颈
实战步骤:
-
访问
http://driver-node:4040 -
进入Jobs页 → 找到慢速Job → 点击Description
-
在Stages页分析:
-
Shuffle Write/Read Size:查看数据倾斜(某Task数据量远高于平均)
-
GC Time:若GC时间占比 > 10%,需优化内存
-
Scheduler Delay:高于200ms表示资源不足
-
Task 32:
Duration: 15min (其他Task平均1min)
Shuffle Read Size: 5GB (平均100MB)
GC Time: 45s
→ 结论:热点Key导致数据倾斜+频繁GC三、面试备战完美答案
问题4:DAGScheduler工作原理(标准答案)
DAGScheduler是Spark作业调度的核心引擎,其工作流程分为四步:
DAG构建:当Action触发时,根据RDD的血缘关系,反向遍历依赖链,构建有向无环图
Stage划分:以Shuffle操作为边界进行Stage切割(宽依赖切断,窄依赖合并)
Task生成:为每个Stage创建TaskSet(包含多个Task),提交给TaskScheduler
容错处理:监控Task执行状态,失败时根据血缘重新提交计算
示例:
rddD = rddC.reduceByKey().filter()的Stage划分:
rddB = rddA.join(rddB)← 宽依赖(Stage 1)
rddC = rddB.map()← 窄依赖(合并到Stage 1)
reduceByKey()← 宽依赖(Stage 2)
filter()← 窄依赖(Stage 2)
问题5:血缘+Checkpoint容错(标准答案)
Spark容错机制分为两层:
第一层:血缘重建(细粒度)
原理:记录RDD的转换序列(如
HadoopRDD → MapPartitionsRDD → ShuffledRDD)触发:Task失败时,从源头重新计算丢失分区
优点:无额外开销
缺点:长链路重算代价高
第二层:Checkpoint(粗粒度)
原理:将RDD物化到可靠存储(HDFS)
操作:
rdd.checkpoint()+ Action触发效果:
切断血缘:不再保留之前转换记录
故障时直接从Checkpoint点恢复
最佳实践:对迭代计算(如PageRank)每10次迭代做Checkpoint
协同工作:
转换1/2失败:用血缘重建
转换3/4失败:从Checkpoint恢复
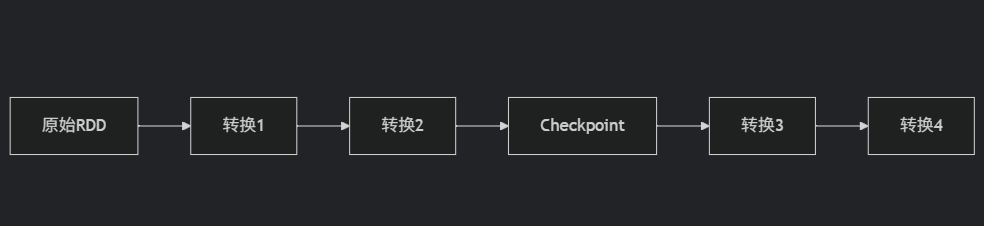
问题6:RDD核心特性(标准答案)
三大核心特性:
不可变性 (Immutability)
RDD一旦创建不可修改,只能通过转换生成新RDD
优势:避免并发冲突,天然容错
示例:
rddB = rddA.map()产生全新RDD血缘 (Lineage)
记录RDD的衍生谱系(父RDD + 转换函数)
实现方式:每个RDD存储
dependencies和compute函数示例:
FilteredRDD存储parent: MapPartitionsRDD和filterFunc惰性求值 (Lazy Evaluation)
Transformation不立即执行,只记录操作逻辑
Action触发时,根据血缘生成物理执行计划
优势:
优化执行计划(如合并多个map操作)
避免中间结果存储
示例:
textFile().map().filter().collect()直到collect才触发计算
项目案例模板(面试使用)
场景:电商用户行为分析(日活1亿+)
问题:
reduceByKey阶段卡在99%,部分Task耗时超1小时排查过程:
用
toDebugString确认血缘中存在ShuffledRDDSpark UI显示Task 127的Shuffle Read达5GB(平均200MB)
日志分析发现热点Key:某网红商品ID被点击1.2亿次
解决方案:
两阶段聚合:
scala
// 加盐分散热点Key val salted = rawData.map(k => (util.Random.nextInt(100) + "_" + k, 1)) val stage1 = salted.reduceByKey(_ + _) val stage2 = stage1.map(kv => (kv._1.split("_")(1), kv._2)) .reduceByKey(_ + _)结果:
作业时间从4小时降至25分钟
Shuffle数据量减少70%
优化原理:
盐值将1个热点Key分散为100个子Key
第一阶段在各Executor并行预聚合
避免单个Task处理过大数据

















 1026
1026

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









