



ko coredump调试
适用于kernel crash打印出backtrace stackframe情况的问题分析
1. 根据backtrace识别出大概问题的原因
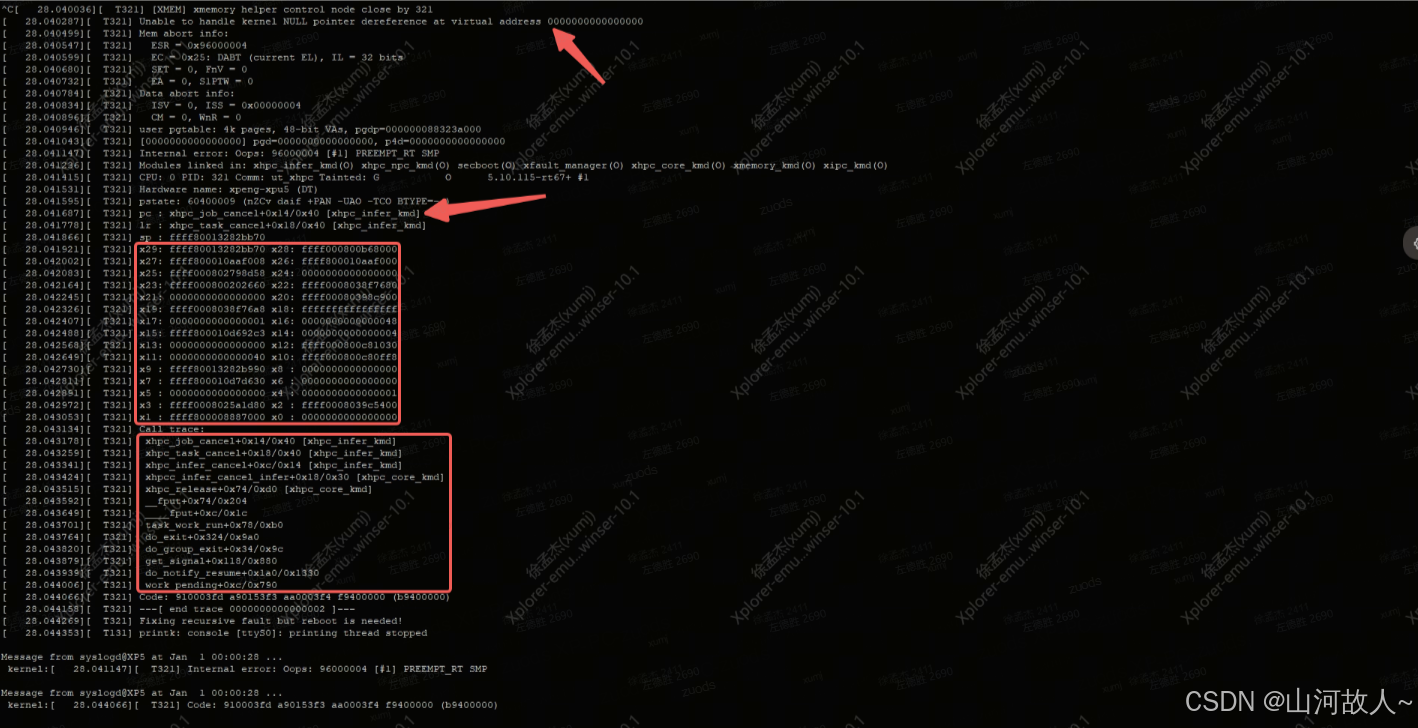 2. 反汇编引起错误的ko,如下
2. 反汇编引起错误的ko,如下
a. 查找ko文件
b. 反汇编ko文件
gcc-arm-11.2-2022.02-x86_64-aarch64-none-linux-gnu/bin/aarch64-none-linux-gnu-objdump -DS kmd.ko > log
3. 打开log文件中查看ko汇编代码,从中找到出问题的函数以及出问题的行
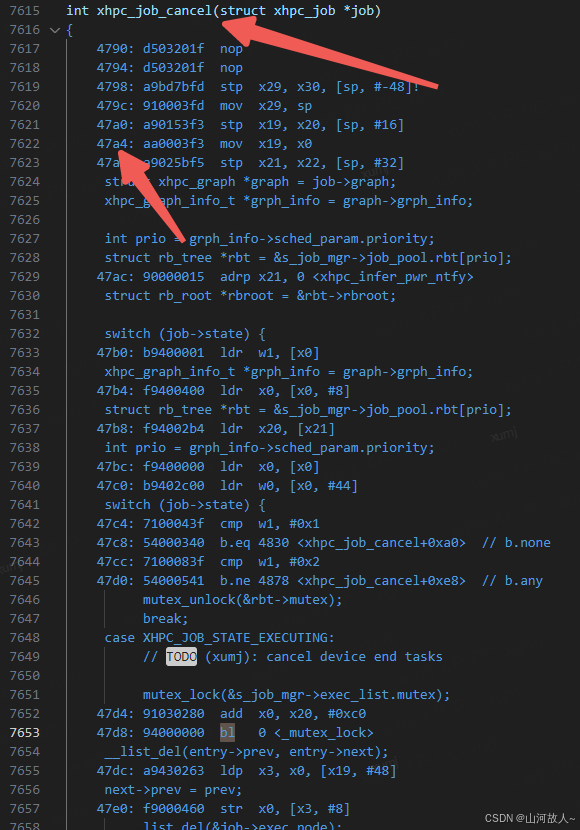
4. 定位源代码的行数
自动定位
gcc-arm-11.2-2022.02-x86_64-aarch64-none-linux-gnu/bin/aarch64-none-linux-gnu-addr2line -e kmd.ko 0x47dc -f -a -p -i -C
0x47dc为 address,输出如下
0x00000000000047dc: __list_del_entry at linux/kernel/linux-5.10/include/linux/list.h:135
(inlined by) list_del at linux/kernel/linux-5.10/include/linux/list.h:146
(inlined by) xhpc_job_cancel at xhpc_job/xhpc_job.c:246展示了对应的源代码位置
手动定位
查看汇编错误行前后的汇编代码推算对应的源代码位置,可以使用前后的 bl/ ld/ st/ mv 等指令辅助定位。
0x47d8 为 bl 0 <_mutex_lock>,则说明出问题的位置位于 _mutex_lock 函数调用前。
ld/ st/ mv 指令辅助定位的方法,如上图 0x47dc 指令 47dc: a9430263 ldp x3, x0, [x19, #48],代表对 x19 + 48 地址的寻址,可能是类似 s_job_mgr->exec_list 的指针寻址访问,需要手动计算 offsetof(typeof(s_job_mgr), exec_list) 是否等于 48 来确认是否为该行源代码
利用 ARM 函数调用规范定位位置,x0 ~ x3 依次存储函数的入参,可以用于辅助定位源码位置
其他的定位方式大家可以继续发掘...
5. 定位问题的根本原因
定位到源代码位置后再根据报错信息/ 寄存器状态推测问题的根本原因
用户态 coredump 分析方法
必现问题分析方法(gdb 在线调试)
注意:
需要替换带符号以及调试信息的 .so/ .bin 到目标环境下(可以使用 adb push 或者共享目录等方式),gdb backtrace 才能看到详细的调试信息。cst 的带符号产物位于 output/xp5/qemu/rdp/symbols/Debug/sysroot/ 目录,例如 output/xp5/qemu/rdp/symbols/Debug/sysroot/usr/bin/xhpcu_test。
将带符号的 lib/ bin 文件(xhpcu_test/ libxhpc.so/ libxhpc_ulayer.so/ ...)以及 gdb 推到板端,
gdb /usr/bin/xhpcu_test
set args -c sigl_frame_test -n /usr/bin/fisheye_4core_v3/
rcrash 后使用 gdb 的方法定位(bt/ info all-registers/ info locals/ info threads/ info frame/ up/ down/ p <var> ...)
偶现问题分析方法 1(Coredump 分析)
-
将 coredump 文件 (qemu: /blackbox/var/log_archive/log-2024-05-15-03:49:16/coredump/core-0_infer_thread-722-1715752384) 拉回 host machine
-
参考 Cornerstone Coredump指北 定位问题
aarch64-none-linux-gnu-gdb core core-HelloWorld-455-1703500560 file aarch64-buildroot-linux-gnu/sysroot/usr/bin/xhpcu_test info sharedlibrary show sysroot8 set sysroot output/xp5/qemu/rdp/symbols/Debug/sysroot/ info sharedlibrary bt
触发用户态程序 coredump 的方法
1. 确认目标环境允许产生coredump文件
1.1 cat /proc/sys/kernel/core_pattern 查看 coredump pattern,无内容表示 coredump disabled
![]()
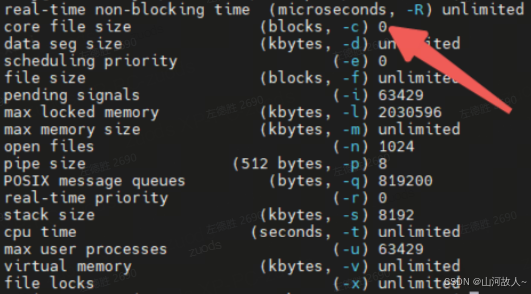
1.2 ulimit -a 显示如下,core file size 显示为 0 表示不产生 coredump 文件
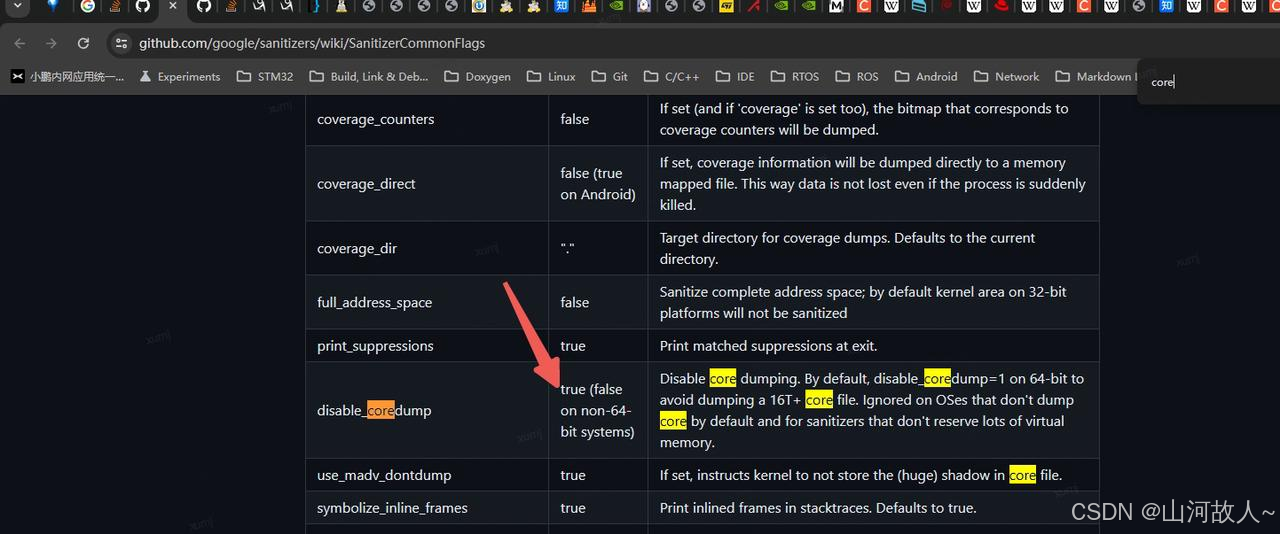
1.3 如果ASAN enabled,默认 disable core dump,export ASAN_OPTIONS=disable_coredump=0:abort_on_error=1 可以解决
2. 如果系统 disbale core dump,则可以通过下面的脚本 enable。qemu board 该脚本位于 qemu/rootfs-overlay/etc/init.d/S01rsyslogd(systemd 启动脚本,系统启动自动运行,声明在 buildroot/board/xp/xp5/qemu/rootfs-overlay/etc/init.d/rcS 文件内),X2 board 脚本位于 x2/rootfs-overlay/etc/init.d/rcS(source /path/to/rcS enbale coredump,注意必须要要 source,不能 .,. 只会在当前 shell 生效)
#!/bin/sh
# enable coredump default
/bin/mkdir -p /var/coredump
/bin/chmod 777 /var/coredump
/bin/echo 1 >/proc/sys/kernel/core_uses_pid
/bin/echo '/var/coredump/core-%e-%p-%t' > /proc/sys/kernel/core_pattern
ulimit -c unlimited
# enable coredump end3. 触发用户态程序产生 coredump
如果用户态程序卡死,就需要手动触发其产生 core dump,
3.1 对于多终端的系统,例如 qemu 自带终端还可以通过 adb shell 再开另外的终端,则可以直接新开终端,通过下面的命令触发 core dump
ps aux | grep <program> // 查看进程 pid
kill -6 <pid> // 触发 core dump
3.2 对于单终端系统,如 X2,需要在单终端内完成 coredump 触发
Ctrl-Z // 将进程 stop 并且 unbind terminal
jobs // 查看 shell 作业,可以看到 shell 上存在单个 job,job number 为 1
ps aux | grep <program> // 查看进程 pid
kill -6 <pid> // 触发 core dump
bg %1 // 唤醒进程到后台执行4. coredump 文件路径如下 /var/coredump/core-%e-%p-%t
偶现问题分析方法 2(backtrace 分析)
如果未生成 coredump 文件但是打印出了 backtrace stackframe 情况下的问题分析方法
打印出来的 backtrace 如下所示
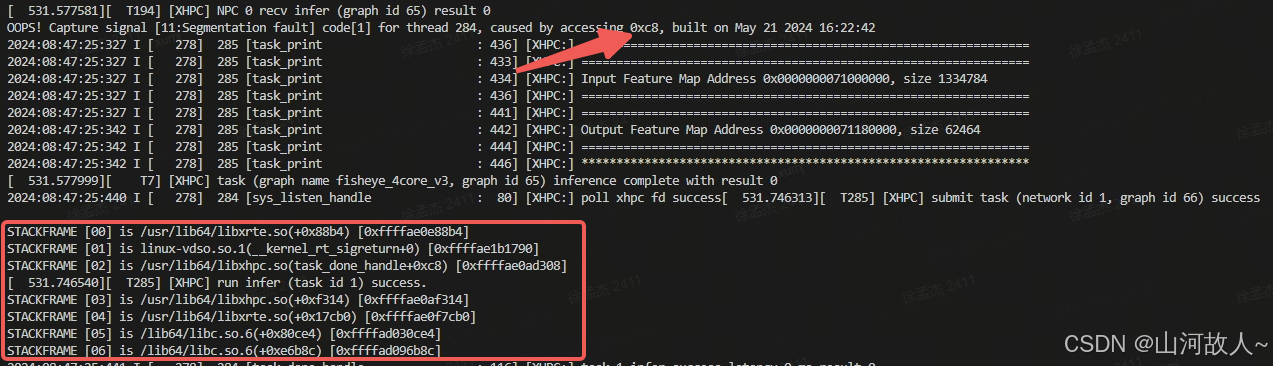
4.1 查找正确的so文件
选择正确的 Debug/ Release profile
cd /path/to/cornerstone
ll -t `find output/xp5/qemu/rdp/build/Debug/buildroot/output/xp5_qemu_virt_defconfig/ -name libxhpc.so`
file `find output/xp5/qemu/rdp/build/Debug/buildroot/output/xp5_qemu_virt_defconfig/ -name libxhpc.so`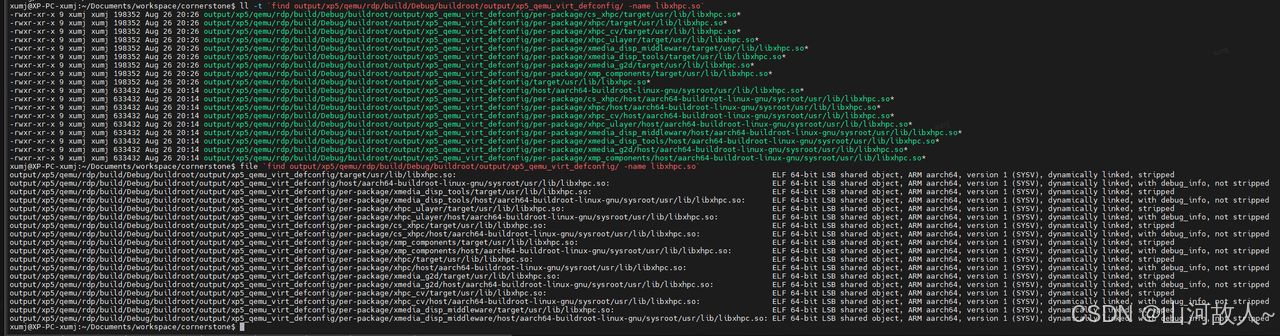
选择 with debug_info, not stripped 的编译产物
4.2 反汇编so 文件
4.3 打开汇编代码查找到问题函数以及问题汇编行
4.4 结合汇编定位到源代码位置
4.5 定位问题根本原因

















 1739
1739

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









