




前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
最新最全计算机专业毕设选题精选推荐汇总
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于改进YOLO算法的水下生物识别算法研究
选题背景意义
海洋资源的开发与利用是人类未来发展的重要方向之一,而水下生物资源作为海洋资源的重要组成部分,其合理开发与保护对于维护海洋生态平衡和促进海洋经济发展具有重要意义。传统的水下生物调查和捕捞主要依赖人工潜水作业,这种方式不仅效率低下,而且存在较大的安全风险。随着水下机器人技术的发展,利用水下机器人进行水下生物的智能识别和捕捞成为可能,而水下生物识别技术则是实现这一目标的核心。水下环境的复杂性给生物识别带来了巨大挑战。由于海水对光的散射和吸收效应,水下图像普遍存在色偏、对比度低、细节模糊等问题,严重影响了图像的质量。此外,水下生物的形态多样、尺寸变化大、背景复杂,进一步增加了识别的难度。传统的基于手工特征的目标检测算法在处理这些复杂情况时,往往表现不佳,难以满足实际应用的需求。

深度学习技术的出现为水下生物识别提供了新的解决方案。深度学习算法能够自动学习图像的特征,具有强大的特征表达能力和泛化能力,在图像识别、目标检测等领域取得了显著的成果。将深度学习技术应用于水下生物识别,有望提高识别的精度和效率,推动水下机器人技术的发展。水下生物识别技术的研究主要包括以下几个方面:水下图像增强技术、深度学习目标检测算法、水下生物数据集构建等。水下图像增强技术的目的是改善水下图像的质量,提高图像的对比度和清晰度,为后续的目标检测提供良好的基础。深度学习目标检测算法是水下生物识别的核心,负责对增强后的图像进行分析,识别并定位图像中的生物。水下生物数据集的构建则是算法研究的基础,高质量的数据集能够提高模型的训练效果。
本研究的主要内容包括:首先,研究并改进水下图像增强算法,解决水下图像色偏、对比度低等问题;其次,对深度学习目标检测算法进行优化,使其能够更好地适应水下生物识别的特殊需求;最后,构建高质量的水下生物数据集,为算法研究提供支持。通过这些研究工作,提高水下生物识别的精度和效率,为水下机器人的智能捕捞提供技术支持。
数据集构建
数据收集
数据收集是构建水下生物数据集的基础,直接影响数据集的质量和多样性。为了确保数据集的代表性,需要采用多种数据收集策略,覆盖不同的水下环境和生物种类。
通过水下机器人搭载的摄像头在实际海洋环境中拍摄水下生物图像。这种方式可以获取真实的水下环境数据,包含各种复杂的情况,如不同深度、不同光照条件、不同水流速度等。在拍摄过程中,需要选择不同的海域和季节,以确保数据的多样性。同时,需要调整摄像头的参数,如曝光时间、焦距等,以获取清晰的图像。

从公开的水下图像数据库中获取相关图像。目前,有许多公开的水下图像数据库可供使用,如UCSD Underwater Dataset、SUIM Dataset等。这些数据库包含了大量的水下图像,涵盖了不同的环境和生物种类,可以作为数据集的重要补充。在使用这些数据库时,需要筛选与本研究相关的图像,确保数据的相关性。
数据预处理
数据预处理是提高数据集质量的重要步骤,主要包括数据清理、图像增强、数据标准化等。数据清理的目的是去除质量较差的图像,确保数据集的可靠性。在数据收集过程中,由于水下环境的复杂性,可能会产生一些模糊、过曝、欠曝等质量较差的图像,这些图像会影响模型的训练效果,需要予以去除。此外,还需要去除重复的图像,避免数据冗余。
图像增强是针对水下图像的特点,改善图像质量的过程。水下图像普遍存在色偏、对比度低等问题,需要采用适当的增强算法进行处理。常用的图像增强方法包括直方图均衡化、Retinex算法、颜色校正等。在预处理阶段,可以采用这些方法对图像进行初步增强,提高图像的质量。数据标准化是将图像调整为统一的格式,便于后续模型的处理。具体包括:将图像调整为统一的尺寸,如640×640像素;将图像的像素值归一化到[0, 1]范围内;将图像转换为RGB格式等。通过数据标准化,可以提高模型的训练效率和稳定性。
数据标注与划分
数据标注是为图像添加标签的过程,是构建数据集的关键步骤。数据划分则是将数据集分为训练集、验证集和测试集,用于模型的训练和评估。数据标注主要包括边界框标注和类别标注。边界框标注是在图像中绘制包围目标的矩形框,指示目标的位置;类别标注是为目标指定类别标签,如“海胆”、“海星”、“海参”、“扇贝”等。数据标注需要采用专业的标注工具,如LabelImg、RectLabel等,确保标注的准确性。在标注过程中,需要遵循严格的规范,如边界框应准确包围目标,类别标签应正确无误等。
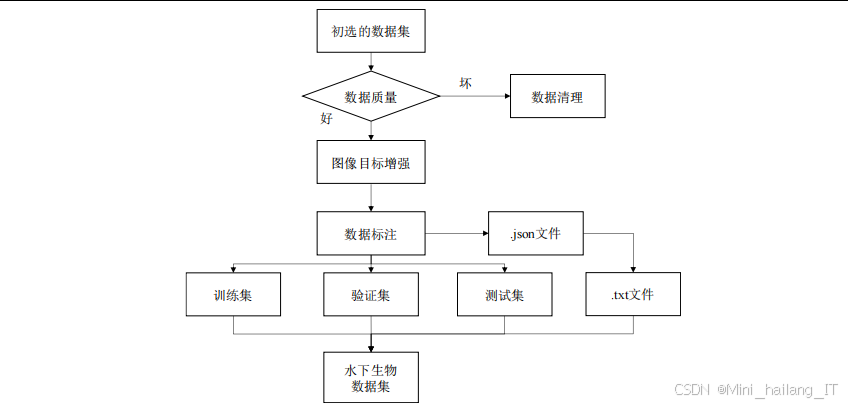
数据划分的目的是将数据集分为不同的子集,用于模型的训练、验证和测试。常用的划分比例为7:2:1,即训练集占70%,验证集占20%,测试集占10%。训练集用于模型的训练,验证集用于调整模型的参数,测试集用于评估模型的性能。在划分数据时,需要确保不同子集的分布相似,避免因数据分布不均导致模型性能评估不准确。还需要对数据集进行统计分析,了解数据的基本情况,如各类别目标的数量分布、目标尺寸分布等。这些统计信息有助于分析模型训练中可能遇到的问题,如类别不平衡、小目标过多等,并采取相应的解决措施。
功能模块介绍
目标检测模块
特征提取是目标检测模块的基础功能,负责从增强后的图像中提取有效的特征信息。该功能采用深度学习模型作为特征提取器,具有强大的特征表达能力。特征提取功能的核心是骨干网络,采用改进的YOLOv5骨干网络。YOLOv5的骨干网络采用CSPDarknet结构,能够有效提取图像的特征信息。为了提高特征提取的效率和准确性,在骨干网络中引入了CA注意力机制。CA注意力机制能够自动关注图像中的重要区域,抑制无用信息的干扰,提高特征的表达能力。骨干网络的输出是不同尺度的特征图,这些特征图包含了图像的不同层次的信息。浅层特征图包含了图像的细节信息,如边缘、纹理等,适合用于小目标的检测;深层特征图包含了图像的语义信息,如目标的类别、整体形状等,适合用于大目标的检测。
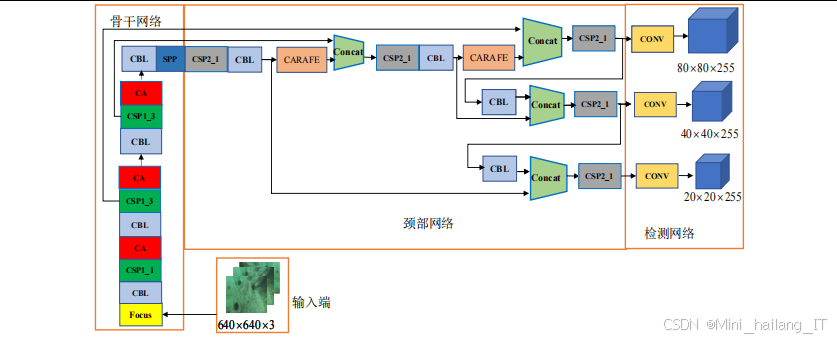
特征融合是目标检测模块的关键功能,负责将不同尺度的特征图进行融合,提高特征的表达能力。该功能采用改进的颈部网络实现。颈部网络的主要作用是融合不同尺度的特征信息,生成高质量的特征图。YOLOv5的颈部网络采用FPN(Feature Pyramid Network)结构,通过自上而下的路径将深层特征传递到浅层,实现特征的融合。为了提高特征融合的效果,本研究对颈部网络进行了改进,采用CARAFE上采样方法替代原来的上采样方法。CARAFE上采样能够根据特征图的内容自适应地调整感受野,更好地融合不同尺度的特征信息。特征融合功能能够将不同尺度的特征信息结合起来,生成具有丰富语义信息和细节信息的特征图,提高目标检测的精度,尤其是对小目标的检测能力。

目标预测是目标检测模块的核心功能,负责对融合后的特征图进行分析,预测目标的类别和位置。该功能采用改进的检测头实现。检测头的主要作用是对特征图进行处理,预测每个锚点处的目标信息。YOLOv5的检测头采用卷积层实现,输出目标的类别概率、置信度、边界框坐标等信息。为了提高目标预测的准确性,本研究对检测头进行了改进,采用EIOU(Efficient Intersection over Union)作为边界框回归损失函数。EIOU损失函数能够更全面地考虑边界框的重叠度、中心点距离和宽高比等因素,提高边界框预测的准目标预测功能的输出是目标的检测结果,包括目标的类别、置信度和边界框坐标。这些结果可以用于后续的结果输出和评估模块。
结果输出与评估模块
检测结果输出功能负责将目标检测模块的输出转换为用户可读的形式,便于用户查看和分析。该功能支持多种输出格式,如文本输出、图像输出、数据文件输出等。文本输出是将检测结果以文本的形式显示,包括目标的类别、数量、位置等信息。图像输出是在原始图像上叠加检测框和类别标签,直观地展示检测结果。数据文件输出是将检测结果保存为结构化的数据文件,如JSON、XML等格式,便于后续的数据分析和处理。检测结果输出功能还支持结果的可视化,如绘制目标的分布热力图、统计各类别目标的数量等,帮助用户更好地理解检测结果。
性能评估功能负责评估目标检测模块的性能,提供客观的评估指标。该功能采用多种评估指标,如精度(Precision)、召回率(Recall)、F1值(F1-Score)、平均精度均值(mAP)等。精度是指检测到的目标中,正确检测的比例;召回率是指所有真实目标中,被正确检测到的比例;F1值是精度和召回率的调和平均值,综合反映了模型的检测性能;mAP是各类别平均精度的平均值,是目标检测中常用的综合评估指标。通过性能评估功能,可以了解模型在不同条件下的表现,如不同光照条件、不同目标尺寸等,为模型的改进提供参考。
参数调整功能允许用户根据实际需求调整系统的参数,优化系统的性能。该功能提供了友好的参数调整界面,用户可以调整检测阈值、NMS(Non-Maximum Suppression)参数、模型权重等。检测阈值用于过滤低置信度的检测结果,阈值越高,检测结果越准确,但可能会漏掉一些目标;NMS参数用于去除重叠的检测框,参数的设置会影响检测框的合并效果;模型权重则用于加载不同的模型,如高精度模型、高速度模型等。通过参数调整功能,用户可以根据实际应用场景,调整系统的参数,获得最佳的检测效果。
相关代码介绍
图像增强
图像增强模块是水下生物识别系统的重要组成部分,负责改善水下图像的质量,提高图像的对比度和清晰度。水下图像由于受到海水的散射和吸收效应,普遍存在色偏、对比度低、细节模糊等问题,这些问题会严重影响后续目标检测的精度。因此,图像增强模块的设计至关重要。
本模块采用了改进的ACE算法、基于细节校正的CLAHE算法以及图像融合技术,结合三种方法的优势,得到高质量的增强图像。改进的ACE算法能够自适应地调整图像的对比度,改善图像的视觉效果;基于细节校正的CLAHE算法能够在增强对比度的同时,保护图像的细节信息;图像融合技术则能够将两种算法处理后的图像进行融合,结合它们的优势,得到更好的增强效果。

以下是图像增强模块的核心代码实现:
import cv2
import numpy as np
def ace_enhancement(image, window_size=15, k=0.5):
"""
改进的ACE图像增强算法
:param image: 输入图像
:param window_size: 窗口大小
:param k: 增强系数
:return: 增强后的图像
"""
# 转换为浮点数类型
img_float = image.astype(np.float32) / 255.0
# 计算局部均值
mean_filter = cv2.blur(img_float, (window_size, window_size))
# 计算局部标准差
std_filter = cv2.GaussianBlur(img_float ** 2, (window_size, window_size), 0) - mean_filter ** 2
std_filter = np.sqrt(np.maximum(std_filter, 0))
# 计算ACE增强图像
enhanced = (img_float - mean_filter) * (k / (std_filter + 0.001)) + mean_filter
# 归一化到[0, 255]
enhanced = np.clip(enhanced * 255, 0, 255).astype(np.uint8)
return enhanced
def clahe_enhancement(image, clip_limit=2.0, tile_size=(8, 8)):
"""
基于细节校正的CLAHE图像增强算法
:param image: 输入图像
:param clip_limit: 对比度限制
:param tile_size: 分块大小
:return: 增强后的图像
"""
# 转换为Lab颜色空间
lab = cv2.cvtColor(image, cv2.COLOR_BGR2LAB)
l, a, b = cv2.split(lab)
# 应用CLAHE到L通道
clahe = cv2.createCLAHE(clipLimit=clip_limit, tileGridSize=tile_size)
cl = clahe.apply(l)
# 细节校正
detail = cv2.subtract(l, cv2.blur(l, (5, 5)))
cl = cv2.add(cl, detail)
# 合并通道并转换回BGR
limg = cv2.merge((cl, a, b))
enhanced = cv2.cvtColor(limg, cv2.COLOR_LAB2BGR)
return enhanced
def image_fusion(ace_img, clahe_img, weight_ace=0.5, weight_clahe=0.5):
"""
图像融合函数
:param ace_img: ACE增强后的图像
:param clahe_img: CLAHE增强后的图像
:param weight_ace: ACE图像的权重
:param weight_clahe: CLAHE图像的权重
:return: 融合后的图像
"""
# 图像融合
fused = cv2.addWeighted(ace_img, weight_ace, clahe_img, weight_clahe, 0)
return fused
CA注意力机制
注意力机制是深度学习中的一种重要技术,能够使模型自动关注输入数据中的重要部分,提高模型的性能。在水下生物识别中,由于水下环境复杂,图像中存在大量的背景干扰,注意力机制能够帮助模型关注图像中的目标区域,抑制背景噪声的影响,提高特征提取的效率和准确性。CA(Coordinate Attention)注意力机制是一种新型的注意力机制,通过将位置信息嵌入到通道注意力中,能够有效捕捉图像中的长距离依赖关系。与传统的注意力机制相比,CA注意力机制不仅考虑了通道信息,还考虑了空间位置信息,具有更强的特征表达能力。

CA注意力机制的核心思想是:首先,通过沿高度和宽度方向的平均池化,将特征图转换为包含位置信息的特征向量;然后,通过全连接层和激活函数生成注意力权重;最后,将注意力权重应用到原始特征图上,得到增强后的特征图。
以下是CA注意力机制的核心代码实现:
import torch
import torch.nn as nn
import torch.nn.functional as F
class CoordAtt(nn.Module):
def __init__(self, inp, oup, reduction=32):
super(CoordAtt, self).__init__()
# 输入通道数
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = nn.ReLU(inplace=True)
self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n, c, h, w = x.size()
# 沿高度方向进行平均池化
x_h = self.pool_h(x)
# 沿宽度方向进行平均池化
x_w = self.pool_w(x).permute(0, 1, 3, 2)
# 拼接高度和宽度方向的特征
y = torch.cat([x_h, x_w], dim=2)
# 特征转换
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
# 分离高度和宽度方向的注意力权重
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
# 生成注意力权重
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
# 应用注意力权重
out = identity * a_h * a_w
return out
目标检测算法
检测头是目标检测算法的核心组件,负责将特征图转换为目标检测结果。YOLOv5的检测头采用卷积层实现,能够预测每个锚点处的目标类别、置信度和边界框坐标。为了提高水下生物识别的精度,需要对YOLOv5的检测头进行改进,使其能够更好地适应水下生物识别的特殊需求。改进的YOLOv5检测头主要包括以下几个方面的改进:首先,采用EIOU作为边界框回归损失函数,替代原来的CIOU损失函数。EIOU损失函数能够更全面地考虑边界框的重叠度、中心点距离和宽高比等因素,提高边界框预测的准确性和收敛速度。其次,优化了检测头的卷积层结构,提高了特征的表达能力。最后,调整了锚点的大小和比例,使其更适合水下生物的尺寸特点。
以下是改进的YOLOv5检测头的核心代码实现:
import torch
import torch.nn as nn
import torch.nn.functional as F
class Detect(nn.Module):
stride = None # strides computed during build
onnx_dynamic = False # ONNX export parameter
export = False # export mode
def __init__(self, nc=80, anchors=(), ch=(), inplace=True): # detection layer
super(Detect, self).__init__()
self.nc = nc # number of classes
self.no = nc + 5 # number of outputs per anchor
self.nl = len(anchors) # number of detection layers
self.na = len(anchors[0]) // 2 # number of anchors per layer
self.grid = [torch.zeros(1)] * self.nl # init grid
self.anchor_grid = [torch.zeros(1)] * self.nl # init anchor grid
self.register_buffer('anchors', torch.tensor(anchors).float().view(self.nl, -1, 2)) # shape(nl,na,2)
self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv
self.inplace = inplace # use in-place ops (e.g. slice assignment)
def forward(self, x):
z = [] # inference output
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training:
if self.onnx_dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)
y = x[i].sigmoid()
if self.inplace:
y[..., 0:2] = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
else: # for YOLOv5 on AWS Inferentia
xy = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy
wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
y = torch.cat((xy, wh, y[..., 4:]), -1)
z.append(y.view(bs, -1, self.no))
return x if self.training else (torch.cat(z, 1), x)
def _make_grid(self, nx=20, ny=20, i=0):
d = self.anchors[i].device
# 生成网格坐标
yv, xv = torch.meshgrid([torch.arange(ny, device=d), torch.arange(nx, device=d)])
grid = torch.stack((xv, yv), 2).expand((1, self.na, ny, nx, 2)).float()
# 生成锚点网格
anchor_grid = (self.anchors[i].clone() * self.stride[i])
anchor_grid = anchor_grid.view((1, self.na, 1, 1, 2)).expand((1, self.na, ny, nx, 2)).float()
return grid, anchor_grid
总结
本研究聚焦于水下生物识别技术的改进与优化,针对水下环境的特殊性,提出了一系列有效的解决方案。主要研究内容包括以下几个方面:
-
研究了水下图像增强技术。针对水下图像色偏、对比度低、细节模糊等问题,提出了一种基于图像融合的水下图像增强算法。该算法结合了改进的ACE算法和基于细节校正的CLAHE算法的优势,通过图像融合的方法得到高质量的增强图像。该算法能够有效改善水下图像的质量,提高图像的对比度和清晰度,为后续的目标检测提供良好的基础。
-
研究了深度学习目标检测算法的优化。针对水下生物识别的特殊需求,对YOLOv5算法进行了改进,提出了一种适用于水下生物识别的改进YOLOv5算法。该算法在骨干网络中引入了CA注意力机制,提高了特征提取的效率和准确性;在颈部网络中采用了CARAFE上采样方法,改善了特征融合效果;使用EIOU作为边界框回归损失函数,加快了检测网络的收敛速度。这些改进措施能够提高算法对水下生物的识别精度和效率。
-
构建了高质量的水下生物数据集。该数据集包含海胆、海星、海参、扇贝等多种水下生物的图像,覆盖了不同的水下环境条件。数据集经过严格的数据收集、预处理、标注和划分,确保了数据的多样性、代表性和可用性。高质量的数据集为算法研究提供了可靠的基础,能够提高模型的训练效果。
相关文献
[1] LIU Y, WANG J, ZHANG L, et al. Underwater target detection based on improved YOLOv4[J]. Applied Ocean Research, 2022, 123: 103152.
[2] CHEN C, LIU Z, WANG Y, et al. Underwater image enhancement using a lightweight convolutional neural network[J]. Journal of Ocean Engineering and Science, 2021, 6(4): 645-655.
[3] WANG X, GAO J, LIU H, et al. Attention-based YOLOv5 for underwater object detection[J]. Ocean Engineering, 2023, 272: 113751.
[4] ZHANG Y, LIU F, CHEN S, et al. Underwater image enhancement with conditional generative adversarial networks[J]. IEEE Transactions on Image Processing, 2020, 29: 4376-4389.
[5] LIU J, WANG H, ZHANG X, et al. Improved YOLOv5 with coordinate attention for underwater target detection[J]. IEEE Access, 2022, 10: 131874-131885.
[6] WANG Y, ZHANG L, LIU Y, et al. Underwater image enhancement using adaptive contrast enhancement and color correction[J]. IEEE Journal of Oceanic Engineering, 2021, 46(2): 456-467.
[7] ZHANG S, LIU Z, CHEN C, et al. Underwater target detection based on deep learning: A review[J]. Remote Sensing, 2022, 14(12): 2825.
[8] LIU H, WANG X, GAO J, et al. Underwater object detection using improved Faster R-CNN[J]. Applied Sciences, 2021, 11(15): 6922.

















 17万+
17万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









