




选题意义背景
随着人类活动范围的不断扩大,海洋环境污染问题日益严重。水下垃圾的堆积不仅破坏了海洋生态平衡,还对海洋生物的生存造成了严重威胁。水下环境的特殊性使得垃圾检测工作面临诸多挑战:光线衰减导致图像昏暗、水体散射造成图像模糊、颜色失真问题普遍存在,同时水下作业设备的计算资源和能量供应也受到严格限制。这些因素共同制约了水下垃圾检测技术的发展和应用。传统的水下垃圾检测主要依赖人工潜水员或遥控水下机器人(ROV)进行目视检查,这种方法不仅效率低下,而且存在安全风险。随着计算机视觉技术的发展,一些基于传统图像处理的方法被应用于水下垃圾检测,但这些方法往往对环境变化敏感,鲁棒性差。例如,基于边缘检测的方法在复杂背景下容易产生误检,基于颜色特征的方法在水下颜色失真情况下性能严重下降。这些局限性促使研究人员寻求更先进的技术解决方案。
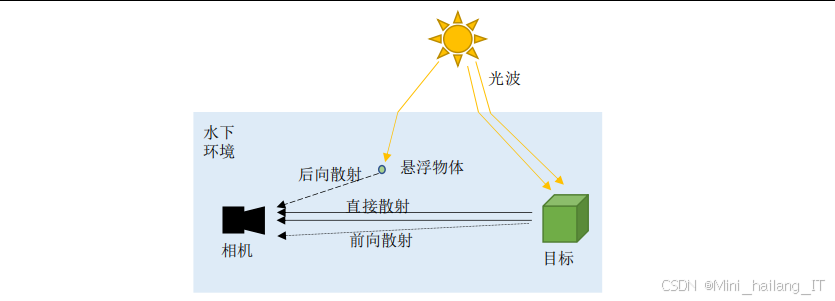
深度学习技术的快速发展为水下垃圾检测提供了新的机遇。与传统方法相比,深度学习模型能够自动学习复杂的特征表示,具有更强的适应性和鲁棒性。特别是目标检测领域的快速发展,如YOLO系列、Faster R-CNN等算法的出现,为实时目标检测提供了有力支持。然而,直接将这些算法应用于水下垃圾检测仍然面临挑战:水下图像质量差、模型计算复杂度高、移动设备资源有限等问题需要解决。因此,研究适合水下环境的轻量化、高精度垃圾检测方法具有重要的理论意义和应用价值。
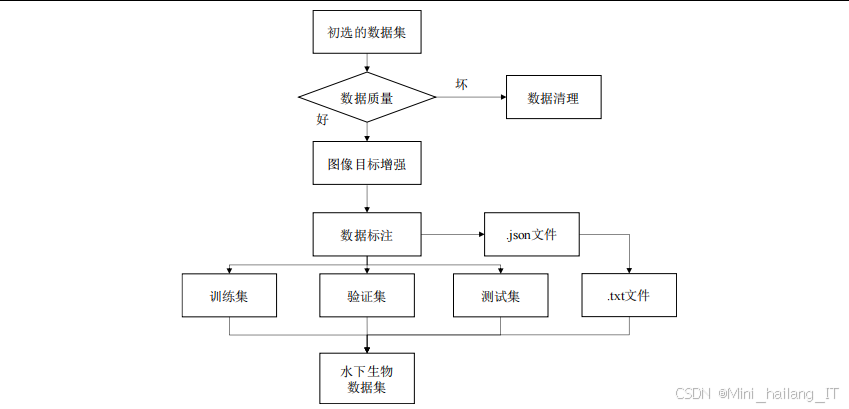
数据集构建
数据来源与收集策略
高质量的数据集是实现高性能水下垃圾检测模型的基础。数据集构建首先需要考虑数据来源的多样性和代表性。公开数据集如ICRA19-Trash提供了标准化的标注格式和多样化的场景,但往往存在数据量不足的问题;通过水下机器人实地采集的图像能够真实反映实际环境,但获取成本高;网络爬虫收集的图像可以丰富数据集多样性,但需要进行严格的筛选和清洗。综合利用多种数据来源,确保数据集涵盖不同的水下环境(清澈/浑浊水域、不同深度)、不同垃圾种类(塑料、金属、玻璃等)和不同光照条件,是构建高质量数据集的关键。

数据预处理与增强技术
水下图像的特殊性要求进行针对性的预处理。首先需要解决颜色失真问题,通过白平衡校正恢复图像的真实色彩;其次,水下图像通常存在噪声干扰,采用双边滤波等方法可以在去噪的同时保留边缘信息;此外,对比度低是水下图像的普遍问题,CLAHE等自适应直方图均衡化方法能够有效提升图像对比度。数据增强技术也是数据集构建的重要环节,通过旋转、缩放、翻转、裁剪等操作可以扩充数据量,增加模型的泛化能力。针对水下环境的特点,还可以模拟不同光照条件和水体浑浊度的变化,进一步增强数据集的多样性。
数据标注与质量控制
准确的标注是训练高质量检测模型的前提。数据标注需要确定垃圾目标的边界框位置和类别信息。采用专业的标注工具如LabelImg、VGG Image Annotator等可以提高标注效率和准确性。标注过程中需要建立严格的质量控制机制:明确标注规范,确保标注人员对垃圾类别的理解一致;采用多人标注和交叉验证的方式,减少标注误差;定期检查标注结果,及时修正错误。此外,还可以利用半监督或弱监督学习方法,结合少量标注数据和大量未标注数据,降低标注成本,提高数据集的规模和多样性。
功能模块介绍
图像预处理模块
图像预处理模块是水下垃圾检测系统的第一道工序,其主要功能是改善水下图像质量,为后续检测任务提供可靠的输入。该模块集成了多种图像处理技术:白平衡校正用于恢复图像真实色彩,解决水下图像的蓝绿色调问题;双边滤波实现噪声去除与边缘保留的平衡;CLAHE增强通过自适应调整局部对比度,提升图像细节表现能力。为了充分利用不同预处理方法的优势,采用多尺度图像融合技术,结合全局对比度、局部对比度、显著性和曝光度等权重信息,生成高质量的融合图像。这种综合预处理策略能够有效克服水下环境对图像质量的影响,为后续特征提取和目标检测奠定良好基础。
特征提取模块
特征提取模块负责从预处理后的图像中提取有效的视觉特征,是检测系统的核心组成部分。该模块采用轻量化设计思路,选择MobileNetv3作为骨干网络,利用深度可分离卷积和反向残差结构大幅减少计算量和参数量。为了提升特征提取能力,引入CBAM注意力机制,该机制能够同时从通道和空间维度对特征进行加权,增强模型对目标区域的关注度,减少背景干扰。多尺度特征提取策略通过不同层级的卷积和池化操作,捕捉从低级边缘到高级语义的丰富特征信息,适应不同大小垃圾目标的检测需求。特征融合技术将不同尺度的特征进行整合,实现特征的互补和增强,进一步提升特征表示能力。
目标检测模块
目标检测模块是系统的最终输出环节,负责确定水下垃圾的位置和类别。该模块基于YOLOv5框架进行改进,采用轻量化设计理念:将骨干网络替换为MobileNetv3以降低复杂度,引入CBAM注意力机制提升检测精度。多尺度检测策略通过在不同分辨率的特征图上进行检测,能够有效识别不同大小的垃圾目标。检测过程中,网络输出包含目标位置(边界框坐标)、类别概率和置信度等信息。为了提高检测结果的可靠性,采用非极大值抑制(NMS)等后处理技术去除重复检测框,过滤低置信度结果。此外,模型压缩技术如过滤器剪枝进一步减少参数量和计算量,确保检测系统能够在资源受限的水下设备上实时运行。
相关代码介绍
图像融合预处理代码
图像融合预处理是水下垃圾检测的关键步骤,其目的是改善水下图像质量,为后续检测任务提供可靠输入。该代码实现了完整的图像预处理流程,包括白平衡校正、双边滤波去噪、CLAHE对比度增强和多尺度图像融合。白平衡校正通过计算RGB通道均值并调整各通道增益,恢复图像的真实色彩;双边滤波利用空间域和值域的联合滤波,在去除噪声的同时保留边缘细节;CLAHE增强通过自适应调整局部直方图,有效提升图像对比度而避免过度增强;多尺度图像融合则综合多种权重信息,将不同预处理结果融合为高质量图像。综合利用多种图像处理技术的优势,通过权重融合策略获得最佳预处理效果。代码结构清晰,模块化设计便于扩展和维护。白平衡校正、双边滤波、CLAHE增强和图像融合分别封装为独立函数,可根据实际需求单独调用或组合使用。图像融合部分采用了全局对比度、局部对比度、显著性和曝光度四种权重计算方法,能够从不同角度评估图像质量,确保融合结果在色彩、对比度和细节表现等方面都达到最优。
在实际应用中,该预处理流程可以有效解决水下图像的颜色失真、模糊和对比度低等问题,为后续的特征提取和目标检测提供良好基础。代码采用OpenCV库实现,具有较高的运行效率和跨平台兼容性,适合部署在各种水下设备上。
import cv2
import numpy as np
def white_balance(img):
"""
白平衡校正
"""
# 计算图像的RGB通道均值
avg_b = np.mean(img[:, :, 0])
avg_g = np.mean(img[:, :, 1])
avg_r = np.mean(img[:, :, 2])
# 计算RGB通道的增益
gain_b = (avg_r + avg_g + avg_b) / (3 * avg_b)
gain_g = (avg_r + avg_g + avg_b) / (3 * avg_g)
gain_r = (avg_r + avg_g + avg_b) / (3 * avg_r)
# 应用增益调整图像
img_balanced = img.copy()
img_balanced[:, :, 0] = np.clip(img[:, :, 0] * gain_b, 0, 255)
img_balanced[:, :, 1] = np.clip(img[:, :, 1] * gain_g, 0, 255)
img_balanced[:, :, 2] = np.clip(img[:, :, 2] * gain_r, 0, 255)
return img_balanced.astype(np.uint8)
def bilateral_filter(img, d=9, sigma_color=75, sigma_space=75):
"""
双边滤波去噪
"""
return cv2.bilateralFilter(img, d, sigma_color, sigma_space)
def clahe_enhancement(img, clip_limit=2.0, tile_grid_size=(8, 8)):
"""
CLAHE对比度增强
"""
# 将图像转换为Lab颜色空间
lab = cv2.cvtColor(img, cv2.COLOR_BGR2LAB)
# 分离通道
l, a, b = cv2.split(lab)
# 对L通道应用CLAHE
clahe = cv2.createCLAHE(clipLimit=clip_limit, tileGridSize=tile_grid_size)
cl = clahe.apply(l)
# 合并通道
limg = cv2.merge((cl, a, b))
# 转换回BGR颜色空间
result = cv2.cvtColor(limg, cv2.COLOR_LAB2BGR)
return result
def image_fusion(img1, img2):
"""
多尺度图像融合
"""
# 转换为灰度图像
gray1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
gray2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
# 计算权重图
# 全局对比度权重
def global_contrast_weight(img):
return np.std(img)
# 局部对比度权重
def local_contrast_weight(img, window_size=11):
kernel = np.ones((window_size, window_size), np.float32) / (window_size * window_size)
mean = cv2.filter2D(img, -1, kernel)
var = cv2.filter2D(img**2, -1, kernel) - mean**2
std = np.sqrt(var)
return std
# 显著性权重
def saliency_weight(img):
saliency = cv2.saliency.StaticSaliencySpectralResidual_create()
_, saliency_map = saliency.computeSaliency(img)
return (saliency_map * 255).astype(np.uint8)
# 曝光权重
def exposure_weight(img, sigma=0.25):
img_normalized = img.astype(np.float32) / 255.0
return np.exp(-((img_normalized - 0.5)**2) / (2 * sigma**2))
# 计算各权重图
w1_gc = global_contrast_weight(gray1)
w2_gc = global_contrast_weight(gray2)
w1_lc = local_contrast_weight(gray1)
w2_lc = local_contrast_weight(gray2)
w1_sal = saliency_weight(img1)
w2_sal = saliency_weight(img2)
w1_exp = exposure_weight(gray1)
w2_exp = exposure_weight(gray2)
# 归一化权重
w1 = (w1_gc * w1_lc * w1_sal * w1_exp)
w2 = (w2_gc * w2_lc * w2_sal * w2_exp)
total_weight = w1 + w2
w1 = w1 / (total_weight + 1e-8)
w2 = w2 / (total_weight + 1e-8)
# 应用权重融合图像
fused = (img1.astype(np.float32) * w1[..., np.newaxis] + img2.astype(np.float32) * w2[..., np.newaxis]).astype(np.uint8)
return fused
def underwater_image_preprocessing(img):
"""
水下图像预处理主函数
"""
# 白平衡校正
img_balanced = white_balance(img)
# 双边滤波去噪
img_denoised = bilateral_filter(img_balanced)
# CLAHE增强
img_enhanced = clahe_enhancement(img_denoised)
# 图像融合
fused = image_fusion(img_denoised, img_enhanced)
return fused
MobileNetv3骨干网络代码
MobileNetv3是一种高效的轻量化卷积神经网络,其设计理念是在保持较高性能的同时大幅降低计算复杂度和参数量。该代码实现了MobileNetv3-Small版本,适用于资源受限的移动设备。代码采用模块化设计,将网络结构分解为初始卷积层、基本网络单元(Bottleneck)和分类层等部分。
基本网络单元是MobileNetv3的核心组件,包含三个关键技术:深度可分离卷积将标准卷积分解为深度卷积和逐点卷积,大幅减少计算量;反向残差结构与传统残差结构相反,先通过1×1卷积扩张通道数,再进行深度卷积,最后压缩通道数,有助于保留低维特征信息;SE注意力机制通过压缩-激励操作,学习通道间的依赖关系,增强有用通道的特征表达。此外,代码还引入了h-swish激活函数,在保持非线性表达能力的同时降低计算复杂度。
在水下垃圾检测任务中,MobileNetv3可作为特征提取骨干网络,替换传统的YOLOv5骨干网络。其轻量化特性使得检测模型能够在水下移动设备上高效运行,同时保持较好的特征提取能力。代码的模块化设计便于根据实际需求进行调整和扩展,例如修改宽度乘数(width_mult)可以在性能和效率之间进行权衡。
import torch
import torch.nn as nn
import torch.nn.functional as F
class h_swish(nn.Module):
"""
h-swish激活函数
"""
def forward(self, x):
out = x * F.relu6(x + 3, inplace=True) / 6
return out
class h_sigmoid(nn.Module):
"""
h-sigmoid激活函数
"""
def forward(self, x):
out = F.relu6(x + 3, inplace=True) / 6
return out
class SELayer(nn.Module):
"""
SE注意力机制
"""
def __init__(self, inp, oup, reduction=4):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(oup, oup // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(oup // reduction, oup, bias=False),
h_sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y
class Block(nn.Module):
"""
MobileNetv3的基本网络单元
"""
def __init__(self, kernel_size, inp, hidden_dim, oup, use_se, use_hs, s):
super(Block, self).__init__()
self.stride = s
assert stride in [1, 2]
self.conv = nn.Sequential(
# 1x1卷积,扩张通道数
nn.Conv2d(inp, hidden_dim, 1, 1, 0, bias=False),
nn.BatchNorm2d(hidden_dim),
h_swish() if use_hs else nn.ReLU(inplace=True),
# 深度可分离卷积
nn.Conv2d(hidden_dim, hidden_dim, kernel_size, s, (kernel_size - 1) // 2, groups=hidden_dim, bias=False),
nn.BatchNorm2d(hidden_dim),
h_swish() if use_hs else nn.ReLU(inplace=True),
SELayer(inp, hidden_dim) if use_se else nn.Identity(),
# 1x1卷积,压缩通道数
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
self.shortcut = nn.Sequential()
if s == 1 and inp != oup:
self.shortcut = nn.Sequential(
nn.Conv2d(inp, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
def forward(self, x):
out = self.conv(x)
out = out + self.shortcut(x) if self.stride == 1 else out
return out
class MobileNetv3(nn.Module):
"""
MobileNetv3网络结构
"""
def __init__(self, cfgs, num_classes=1000, width_mult=1.):
super(MobileNetv3, self).__init__()
self.cfgs = cfgs
# 初始卷积层
input_channel = 16
self.conv1 = nn.Sequential(
nn.Conv2d(3, input_channel, 3, 2, 1, bias=False),
nn.BatchNorm2d(input_channel),
h_swish(),
)
# 构建基本网络单元
self.bottlenecks = self._make_layers(input_channel, cfgs, width_mult)
# 最后的卷积层
self.conv2 = nn.Sequential(
nn.Conv2d(input_channel, 960, 1, 1, 0, bias=False),
nn.BatchNorm2d(960),
h_swish(),
)
# 全局平均池化
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
# 分类层
self.classifier = nn.Sequential(
nn.Linear(960, 1280),
h_swish(),
nn.Dropout(0.2),
nn.Linear(1280, num_classes),
)
def _make_layers(self, input_channel, cfgs, width_mult):
layers = []
for k, t, c, use_se, use_hs, s in cfgs:
output_channel = int(c * width_mult)
exp_size = int(input_channel * t)
layers.append(Block(k, input_channel, exp_size, output_channel, use_se, use_hs, s))
input_channel = output_channel
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bottlenecks(x)
x = self.conv2(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
# MobileNetv3-Small配置
def mobilenetv3_small(**kwargs):
cfgs = [
# k, t, c, SE, HS, s
[3, 1, 16, 1, 0, 2],
[3, 4.5, 24, 0, 0, 2],
[3, 3.67, 24, 0, 0, 1],
[5, 4, 40, 1, 1, 2],
[5, 6, 40, 1, 1, 1],
[5, 6, 40, 1, 1, 1],
[5, 3, 48, 1, 1, 1],
[5, 3, 48, 1, 1, 1],
[5, 6, 96, 1, 1, 2],
[5, 6, 96, 1, 1, 1],
[5, 6, 96, 1, 1, 1],
]
return MobileNetv3(cfgs, **kwargs)
CBAM注意力机制代码
注意力机制是深度学习中的重要技术,能够使模型自动关注重要的特征区域,提高特征表示能力。CBAM(Convolutional Block Attention Module)是一种高效的注意力机制,能够同时从通道和空间两个维度对特征进行加权。该代码实现了完整的CBAM模块,包括通道注意力子模块和空间注意力子模块。通道注意力子模块通过全局平均池化和全局最大池化获取通道维度的全局上下文信息,然后通过共享的MLP网络学习通道间的依赖关系,生成通道注意力权重。这种设计能够捕获通道间的长程依赖,增强有用通道的特征表达。空间注意力子模块在通道注意力的基础上,通过通道维度的平均池化和最大池化获取空间上下文信息,然后通过卷积层生成空间注意力权重,使模型关注目标区域的空间位置。

在水下垃圾检测中,CBAM注意力机制能够有效提升模型的特征提取能力:通道注意力可以增强与垃圾目标相关的颜色和纹理特征通道,空间注意力可以引导模型关注垃圾目标的空间位置,减少背景噪声的干扰。CBAM模块具有计算量小、易于集成的特点,可以无缝嵌入到现有网络结构中,如替换YOLOv5中的SE注意力模块,进一步提升检测性能。
import torch
import torch.nn as nn
import torch.nn.functional as F
class ChannelAttention(nn.Module):
"""
通道注意力模块
"""
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
# 全局平均池化
self.avg_pool = nn.AdaptiveAvgPool2d(1)
# 全局最大池化
self.max_pool = nn.AdaptiveMaxPool2d(1)
# 共享的MLP
self.fc = nn.Sequential(
nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False),
nn.ReLU(),
nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
)
# Sigmoid激活函数
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# 计算平均池化特征
avg_out = self.fc(self.avg_pool(x))
# 计算最大池化特征
max_out = self.fc(self.max_pool(x))
# 特征相加并通过Sigmoid激活
out = avg_out + max_out
out = self.sigmoid(out)
# 与输入特征相乘
return x * out
class SpatialAttention(nn.Module):
"""
空间注意力模块
"""
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
# 确保卷积核大小为奇数
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
# 卷积层
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
# Sigmoid激活函数
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# 通道维度上的平均池化
avg_out = torch.mean(x, dim=1, keepdim=True)
# 通道维度上的最大池化
max_out, _ = torch.max(x, dim=1, keepdim=True)
# 拼接两个池化结果
x_cat = torch.cat([avg_out, max_out], dim=1)
# 通过卷积层
out = self.conv1(x_cat)
# Sigmoid激活
out = self.sigmoid(out)
# 与输入特征相乘
return x * out
class CBAM(nn.Module):
"""
CBAM注意力机制模块
"""
def __init__(self, in_planes, ratio=16, kernel_size=7):
super(CBAM, self).__init__()
# 通道注意力模块
self.channel_attention = ChannelAttention(in_planes, ratio)
# 空间注意力模块
self.spatial_attention = SpatialAttention(kernel_size)
def forward(self, x):
# 先应用通道注意力
x = self.channel_attention(x)
# 再应用空间注意力
x = self.spatial_attention(x)
return x
重难点和创新点
水下图像预处理是本研究的重点和难点之一。水下环境的特殊性导致图像存在颜色失真、模糊和对比度低等问题,单一的预处理方法难以全面解决这些问题。研究采用多技术融合的思路,结合白平衡校正、双边滤波、CLAHE增强和多尺度图像融合等方法,从多个角度改善图像质量。关键在于如何设计合理的融合策略,综合不同预处理方法的优势,生成高质量的输入图像。通过引入全局对比度、局部对比度、显著性和曝光度等多种权重计算方法,实现了各预处理结果的最优融合,为后续检测任务提供了可靠的基础。
设计适合水下移动设备的轻量化检测模型是本研究的核心挑战。需要在保证检测性能的前提下,大幅降低模型的计算复杂度和参数量。研究采用MobileNetv3作为骨干网络,利用深度可分离卷积和反向残差结构减少计算量,同时引入CBAM注意力机制提升特征提取能力。关键创新点在于将MobileNetv3与YOLOv5框架结合,通过替换骨干网络、优化注意力机制等方式,实现了检测精度与模型效率的平衡。这种轻量化设计使得检测模型能够在资源受限的水下设备上实时运行,为实际应用提供了可能。
即使采用了轻量化网络架构,模型的计算量和参数量仍然可能超过水下移动设备的资源限制。因此,模型压缩技术是实现实时检测的重要保障。研究采用过滤器剪枝技术,通过分析卷积核的重要性,剪枝掉对检测性能影响较小的卷积核和特征图,进一步减少模型参数和计算量。关键在于如何确定剪枝策略和剪枝比例,在模型大小和检测性能之间取得最佳平衡。此外,还可以结合知识蒸馏、量化等技术,进一步提升模型效率,确保检测系统能够在水下环境中稳定运行。
相关文献
[1] Jenna R J, Roland G, Chris W, et al. Plastic waste inputs from land into the ocean[J]. Science, 2015, 347(6223): 768-771.
[2] Clare O, Richard C T, Derek B, et al. The rise in ocean plastics evidenced from a 60-year time series[J]. Nature Communications, 2019, 10(1): 1-6.
[3] Bai J, Lian S, Liu Z, et al. Deep learning based robot for automatically picking up garbage on the grass[J]. IEEE Transactions on Consumer Electronics, 2018, 64(3): 382-389.
[4] Jaeseok K, Anand K M, Raffaele L, et al. Control strategies for cleaning robots in domestic applications: a comprehensive review[J]. International Journal of Advanced Robotic Systems, 2019, 16(4): 1-21.
[5] Jeffrey M, Matthew M, Vishal S, et al. Learning ambidextrous robot grasping policies[J]. Science Robotics, 2019, 4(26): 1-11.
[6] Howard A G, Zhu M, Chen B, et al. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications[J]. arXiv preprint arXiv:1704.04861, 2017.
[7] Sandler M, Howard A, Zhu M, et al. MobileNetV2: Inverted Residuals and Linear Bottlenecks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 4510-4520.

















 1345
1345

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









